文章目录
- 1. 背景
- 2. 方法
- 2.1 GSU
- 2.1.1 Hard Search
- 2.1.2 Soft Search
- 2.2 ESU
这里来回顾一篇经典的文章 SIM(Search-based Interest Model),也是自己学习一下,虽然挺久了,但是业界都在使用这个,说明含金量还在提高!很多其他的模型比如 TWIN、MARM 也都是在此基础上做了改进,所以主要是抱着学习的心态来看一下,并不是最新的文章,只是比较经典,这篇文章是阿里提出来的。主要思路是不在试图用一个同一的结构编码所有行为,而是像搜索引擎一样,在海量行为中筛选出来与当前商品相关的那一小部分,进行建模。
论文地址:https://arxiv.org/pdf/2006.05639
1. 背景
用户行为数据(浏览、点击、购买)在 CTR 预测中极其重要,在推荐系统和广告系统这种工业级应用中,可以极大提高预测的精准性,所以很多研究都尝试建模长序列的用户行为数据。用户兴趣是多样且动态的,不同候选商品会触发用户不同的兴趣。就像我们在淘宝浏览商品一样,看电子产品时可能关注性能,看衣服时又会关注款式,DIN(Deep Interst Network)就是基于这个思想:不要一次性表示“整体兴趣”,而是根据当前商品,动态从历史行为中挑出相关的兴趣。但是 DIN 在面对“超长行为序列时”计算和存储代价太高,无法在真实的大规模系统中高效使用。
MIMN 是阿里提出的一个当时业界领先方案,可处理最多约1000条用户行为,通过将所有行为编码进一个固定大小的记忆矩阵来表达用户兴趣。但也存在问题就是,当序列行为更长(比如1万条以上,淘宝有23%用户,在过去5个月点击超过1000个商品)时,MIMN无法准确刻画用户当前对某个商品的兴趣,主要原因是:“固定大小的记忆矩阵引入大量噪声”,无法精准匹配候选商品相关的行为,并且计算和存储开销也顶不住。
所以本位提出 SIM,通过双阶段搜索机制:GSU(General Search Unit)通用搜索单元、ESU(Exact Search Unit)精准搜索单元。在精度和可扩展性之间取得平衡。
- GSU:通过简单有效的策略(类别匹配、内积搜索),从长序列中提取出 Top-K 条与候选商品相关的行为序列(SBS,Sub Behavior Sequence)将输入长度从几万减少到几百条。
- ESU:针对 SBS 序列和候选商品,用注意力机制建模其之间的精细关系,类似于 DIN、DIEN 的方式,用更复杂的模型去精确刻画兴趣。
SIM 借鉴了 DIN 的思想,设计了“先筛选后建模”的双阶段搜索框架,在精准建模用户兴趣的同时,还能高效处理几十倍甚至上百倍的数据量。
2. 方法

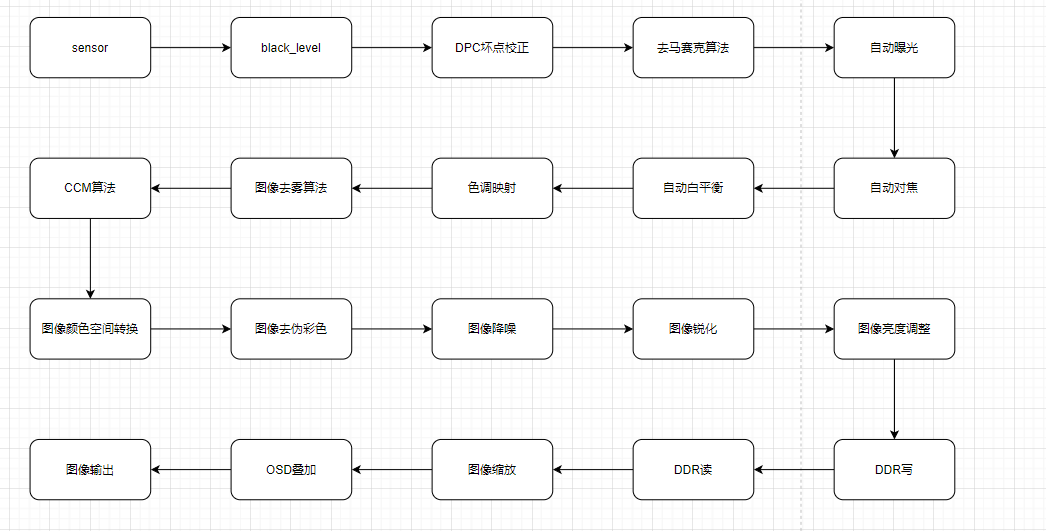
从左到右分别是 GSU(通用搜索单元,从长达上万条用户行为中,快速找出与当前候选商品最相关的前 K 条行为),ESU(精确搜索单元,建模 Top-K 和 当前候选商品之间的精确兴趣匹配关系)
2.1 GSU
并不是每一条历史行为都对当前候选商品有用,需要一个模块来筛选出与当前商品最相关的行为子序列,这是 GSU 的职责。
2.1.1 Hard Search
✅最终选择 Hard Search 模型部署在线系统中,达成更优的性能与可扩展性平衡。
-
非参数化方法:不依赖学习参数;
-
策略非常简单:
-
如果某条历史行为 b i b_i bi 所属类别 C i C_i Ci 与目标商品 C a C_a Ca 一致,那么它就被选入;
-
相关性分数计算公式是:
r i = Sign ( C i = C a ) r_i = \text{Sign}(C_i = C_a) ri=Sign(Ci=Ca)
-
-
优点:
- 快速、简单;
- 非常适合实际部署(如线上推荐系统);
-
缺点:
- 精度可能不如软搜索,因为它只考虑类别,而不考虑行为的具体语义相似度。
为了实现高效的 Hard Search,系统构建了一个两层索引结构,称为:
用户行为树(UBT),基于 Key-Key-Value 结构:
- 第一层 key:用户 ID;
- 第二层 key:行为所属类别(category ID);
- value:具体的行为序列;
实现形式是一个分布式系统,最大支持 22TB,具备高吞吐查询能力;查询时只需要知道候选商品的类别,即可查出与之同类的历史行为。
📌 UBT 的作用:
- 把超长行为序列从上万条压缩到数百条;
- 降低了线上系统对“长期行为存储和实时访问”的压力。
UBT 索引是 预先构建好的(offline pre-built);查询过程无需重新计算 embedding 或打分,只查类别索引即可;相比于 Soft Search 中的向量内积搜索,Hard Search 响应更快;同时,其他用户特征的计算也可与索引查询并行完成,进一步压缩延迟。
2.1.2 Soft Search
这是一个更复杂、基于神经网络参数的搜索方式,用于更精细地筛选行为。
操作流程如下:
-
每条行为 b i b_i bi 被编码成 embedding 向量 e i e_i ei;
-
目标商品也被编码成向量 e a e_a ea;
-
然后用如下公式计算每个行为对目标商品的相关性分数 r i r_i ri:
r i = ( W b e i ) ⊙ ( W a e a ) T r_i = (W_b e_i) \odot (W_a e_a)^T ri=(Wbei)⊙(Waea)T- 其中 W b , W a W_b, W_a Wb,Wa 是可训练的权重矩阵;
- ⊙ \odot ⊙ 表示向量的点积。
-
用最大内积搜索(MIPS)策略选出 Top-K 的行为:
- 使用加速算法如 ALSH 进行快速检索;
- 将十几万条历史行为降到几百条;
Soft Search的行为表示聚合:
-
把选出的行为向量 e i e_i ei 和它们的权重 r i r_i ri 做加权和:
U r = ∑ i = 1 T r i e i U_r = \sum_{i=1}^{T} r_i e_i Ur=i=1∑Triei -
得到一个统一的兴趣表示向量 U r U_r Ur,代表用户对当前商品的综合兴趣。
2.2 ESU
在 SIM 模型的第二阶段,Exact Search Unit(ESU)接收第一阶段 General Search Unit(GSU)筛选出的 Top-K 用户历史行为序列 B ∗ \mathbf{B}^* B∗,并对其进行精细建模,以捕捉用户在当前候选商品上的长期兴趣。由于这些行为可能跨越较长时间范围,不同行为对用户兴趣的贡献并不相同,因此 ESU 引入了时间间隔建模:每条被选中的行为与当前候选商品之间的时间差被表示为向量序列 D = [ Δ 1 , Δ 2 , . . . , Δ K ] \mathbf{D} = [\Delta_1, \Delta_2, ..., \Delta_K] D=[Δ1,Δ2,...,ΔK],并编码为时间嵌入向量 E t \mathbf{E}_t Et。最终,每条行为由两个向量拼接而成:行为内容 embedding e j ∗ e_j^* ej∗ 与时间 embedding e j t e_j^t ejt,形成 z j = concat ( e j ∗ , e j t ) z_j = \text{concat}(e_j^*, e_j^t) zj=concat(ej∗,ejt)。
随后,ESU 采用多头注意力机制(Multi-head Attention)对这些拼接后的行为表示进行加权建模。每个注意力头分别计算候选商品 embedding e a e_a ea 与每条行为表示 z j z_j zj 的注意力分数,再加权得到各自的兴趣表示 head i \text{head}_i headi。所有注意力头的输出被拼接,形成最终的长期兴趣表示向量 U l t U_{lt} Ult。
该向量随后与候选商品等特征一起输入到 MLP 层,用于完成最终的 CTR 预测任务。值得注意的是,SIM 模型的训练过程采用联合优化机制,GSU 和 ESU 同时在交叉熵损失下联合训练,其中 GSU 若使用 soft-search 会通过一个辅助的 CTR 预测任务(以 U r U_r Ur 为输入)来学习打分函数和 embedding;此时主损失和辅助损失分别加权控制。若 GSU 使用的是 hard-search(无参数),则辅助损失项权重 α 被设为 0,仅训练 ESU。通过这样的两阶段结构,SIM 有效结合了高效检索与深度建模的优势,提升了对用户兴趣的建模能力与CTR预测准确率。



![[AD] CrownJewel-1 Logon 4799+vss-ShadowCopy+NTDS.dit/SYSTEM+$MFT](https://i-blog.csdnimg.cn/img_convert/367fde968365cb24a6207e6f2dfa0292.jpeg)