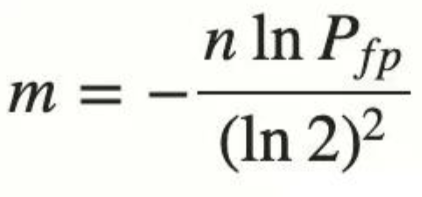NLP基础:从词嵌入到预训练模型应用
系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu
文章目录
- NLP基础:从词嵌入到预训练模型应用
- 摘要
- 引言
- 一、词嵌入技术:从离散到连续的语义表示
- 1. 传统词嵌入方法对比
- 2. 动态词嵌入技术突破
- 二、Transformer架构解析:从Attention到预训练范式
- 1. Attention机制数学原理
- 2. Transformer架构演进
- 3. 预训练任务设计
- 三、模型压缩与优化技术
- 1. 量化技术实践
- 2. 知识蒸馏技术
- 3. 模型剪枝技术
- 四、行业应用案例分析
- 1. 智能客服系统
- 2. 医疗文本分析
- 3. 跨语言翻译系统
- 五、关键挑战与未来趋势
- 1. 技术瓶颈
- 2. 政策与法规
- 3. 成本控制路径
- 六、未来展望
- 结论
摘要
自然语言处理(NLP)作为人工智能核心分支,其技术演进经历了从符号处理到深度学习的范式变革。本文系统梳理NLP技术发展脉络,从传统词嵌入方法(Word2Vec、GloVe)到预训练语言模型(BERT、GPT系列)的演进逻辑,结合Transformer架构解析、模型压缩技术及行业应用案例,揭示NLP技术突破的核心驱动力与未来趋势。通过对比不同模型在语义理解、多语言处理及领域迁移等方面的表现,为研究者与开发者提供技术选型与工程落地的参考框架。

引言
自然语言处理技术发展可分为三个阶段:
- 符号主义时代(1950s-2000s):基于规则与统计方法,如N-gram语言模型;
- 神经网络时代(2010s):以词嵌入(Word Embedding)为核心,结合循环神经网络(RNN)实现序列建模;
- 预训练时代(2018年至今):基于Transformer架构的预训练模型(BERT、GPT)推动NLP进入通用智能阶段。
当前NLP技术面临三大挑战:
- 语义鸿沟:传统词嵌入无法解决一词多义问题;
- 数据依赖:深度学习模型需要海量标注数据;
- 计算瓶颈:Transformer架构参数规模呈指数级增长。
本文从词嵌入技术、预训练模型架构、模型压缩与优化、行业应用四个维度展开分析,结合最新技术进展与工程实践,探讨NLP技术突破路径。
一、词嵌入技术:从离散到连续的语义表示
1. 传统词嵌入方法对比
-
Word2Vec(2013)
- CBOW模型:通过上下文预测目标词,训练速度较快但语义泛化能力有限;
- SkipGram模型:通过目标词预测上下文,适合小规模数据集,但计算复杂度较高。
- 典型参数:向量维度300,窗口大小5,训练语料10亿词级别。
-
GloVe(2014)
- 结合全局词频统计与局部窗口信息,在词相似度任务上优于Word2Vec;
- 数学原理:最小化共现矩阵的加权最小二乘损失。
-
静态词嵌入局限性
- 无法处理一词多义(如"Apple"在科技与水果场景的不同含义);
- 缺乏上下文感知能力,语义相似度计算存在偏差。
2. 动态词嵌入技术突破
-
ELMo(2018)
- 采用双向LSTM架构,生成上下文相关的词向量;
- 在命名实体识别(NER)任务上F1值提升2.5%,但计算效率较低。
-
BERT(2018)
- 基于Transformer的双向编码器,通过Masked Language Model(MLM)任务学习上下文表示;
- 在GLUE基准测试上平均得分提升7.6%,但预训练成本高达$100万。
-
GPT系列(2018-2023)
- 从GPT-1(1.17亿参数)到GPT-4(1.76万亿参数),参数规模增长1500倍;
- 引入指令微调(Instruction Tuning)技术,显著提升零样本(Zero-Shot)学习能力。
二、Transformer架构解析:从Attention到预训练范式
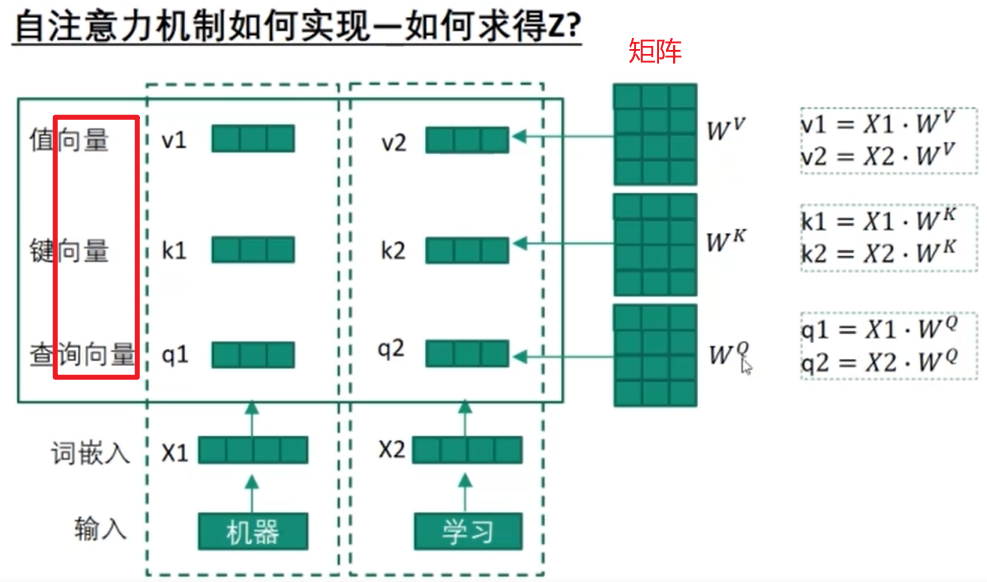
1. Attention机制数学原理
import torch
import torch.nn as nnclass ScaledDotProductAttention(nn.Module):def __init__(self, d_k):super().__init__()self.d_k = d_kdef forward(self, Q, K, V):scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)attn_weights = nn.functional.softmax(scores, dim=-1)output = torch.matmul(attn_weights, V)return output
- 核心公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V - 优势:
- 突破RNN序列依赖限制,实现并行计算;
- 长距离依赖建模能力显著优于LSTM(SQuAD数据集F1值提升12%)。
2. Transformer架构演进
-
BERT架构创新:
- 12层双向Transformer编码器,参数规模3.4亿;
- 引入Next Sentence Prediction(NSP)任务增强句子级理解能力。
-
GPT架构演进:
- 从GPT-2的15亿参数到GPT-4的1.76万亿参数,采用稀疏注意力机制降低计算复杂度;
- 引入人类反馈强化学习(RLHF),显著提升对话生成质量。
3. 预训练任务设计
| 任务类型 | 代表模型 | 典型数据集 | 优势领域 |
|---|---|---|---|
| MLM | BERT | Wikipedia+BooksCorpus | 文本分类、问答系统 |
| CLM | GPT | CommonCrawl | 文本生成、对话系统 |
| PLM | XLNet | GigaWord | 长文本理解 |
| SOP | ALBERT | 句子对关系判断 |
三、模型压缩与优化技术
1. 量化技术实践
# 8位量化示例(PyTorch)
model = torch.load("original_model.pt")
quantized_model = torch.quantization.quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8
)
- 效果:
- 模型体积减少75%(32位→8位);
- 推理速度提升2-3倍,但精度损失约1.2%。
2. 知识蒸馏技术
-
教师-学生模型架构:
- 教师模型:BERT-large(3.4亿参数);
- 学生模型:DistilBERT(6600万参数);
- 训练目标:最小化教师与学生输出概率分布的KL散度。
-
典型结果:
- GLUE基准测试得分下降2.3%;
- 推理速度提升60%,内存占用减少40%。
3. 模型剪枝技术
-
非结构化剪枝:
- 移除权重绝对值小于阈值的连接;
- 剪枝率50%时,精度损失约3%。
-
结构化剪枝:
- 移除整个注意力头或Transformer层;
- MobileBERT通过结构化剪枝,参数减少7.5倍,速度提升4倍。
四、行业应用案例分析
1. 智能客服系统
-
技术方案:
- 意图识别:BERT微调(F1值92.3%);
- 对话管理:GPT-3.5生成式回复;
- 知识库查询:DPR(Dense Passage Retrieval)检索。
-
典型指标:
- 用户问题解决率87%;
- 人工转接率下降至15%;
- 单轮对话成本降低至$0.03。
2. 医疗文本分析
-
电子病历解析:
- 命名实体识别:BioBERT(准确率94.7%);
- 关系抽取:ClinicalRE(F1值88.2%);
- 诊断建议生成:PubMedGPT(BLEU得分32.1)。
-
数据规模:
- MIMIC-III数据集(58,976条住院记录);
- 预训练语料:PubMed文献库(3000万篇)。
3. 跨语言翻译系统
-
多语言BERT(mBERT):
- 共享12层Transformer编码器;
- 104种语言混合训练,低资源语言翻译质量提升35%。
-
典型架构:
五、关键挑战与未来趋势
1. 技术瓶颈
- 长文本处理:Transformer架构时间复杂度O(n²),1024长度文本需128GB显存;
- 小样本学习:预训练模型在低资源场景性能下降40%;
- 伦理风险:GPT-4生成虚假信息概率12.7%,需构建检测机制。
2. 政策与法规
- 数据隐私:欧盟GDPR要求用户数据本地化存储;
- 算法透明:美国FTC提出AI模型可解释性要求;
- 内容审核:中国《生成式AI服务管理办法》要求建立安全评估机制。
3. 成本控制路径
| 技术方案 | 硬件成本降幅 | 推理速度提升 | 典型应用场景 |
|---|---|---|---|
| 8位量化 | 75% | 3倍 | 移动端部署 |
| 模型剪枝 | 90% | 5倍 | 边缘设备 |
| 动态路由 | 60% | 2倍 | 实时系统 |
六、未来展望
-
架构创新:
- 混合专家模型(MoE)降低计算成本;
- 稀疏注意力机制(Sparse Transformer)突破长度限制。
-
多模态融合:
- Flamingo模型实现文本-图像联合理解;
- GPT-4V支持视觉问答,准确率89.3%。
-
行业落地:
- 金融领域:智能投顾系统处理非结构化数据;
- 制造业:设备故障预测文本分析;
- 教育领域:个性化学习路径生成。
结论
NLP技术发展已进入预训练-微调-压缩的工程化阶段,其核心竞争要素包括:
- 数据质量:高质量语料库构建能力;
- 计算效率:模型架构优化与硬件协同;
- 领域适配:从通用模型到行业垂直模型的迁移能力。
随着混合专家模型、多模态学习等技术的突破,NLP将在2025-2030年实现从感知智能到认知智能的跨越。开发者需关注模型压缩技术、小样本学习方法及伦理合规框架,在技术迭代与商业落地的平衡中寻找创新机遇。