目录
引言:AI的"甜蜜烦恼"与"长文之痒"
一、AI的"长文阅读障碍"
二、"屠龙勇士"登场:阿里通义千问QwenLong横空出世
三、揭秘"屠龙技":QwenLong如何驯服长文本"巨兽"?
3.1 招式一:循序渐进的"健身房"——渐进式上下文扩展技术
3.2 招式二:明察秋毫的"裁判团"——混合奖励机制
四、实力见真章:QwenLong的"成绩单"有多亮眼?
五、不止于模型:QwenLong的开放"生态圈"
六、大处着眼:QwenLong将如何改变我们的世界?
七、道阻且长,行则将至:长文本AI的星辰大海
八、结语:开启AI阅读新纪元

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 QwenLong-L1-32B
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:AI的"甜蜜烦恼"与"长文之痒"
人工智能(AI)如今已像一位无所不能的魔法师,绘画、写诗、编程、对话样样精通,带给我们源源不断的惊喜。然而,这位魔法师也有自己的"甜蜜烦恼"。当我们兴冲冲地丢给它一篇几万甚至十几万字的鸿篇巨著,比如一份复杂的法律文件、一本厚厚的学术专著,或者一段长长的历史档案,希望它能帮我们提炼精华、解答疑惑时,AI却可能挠挠头,露出"臣妾做不到啊"的窘态。这就是AI在"长文本理解"上遇到的瓶颈——"长文之痒"。不过,正如武侠小说中的江湖总有奇人异士,AI领域也从不缺乏破局者。最近,来自阿里巴巴通义实验室的QwenLong-L1,便如一位新晋的武林高手,誓要攻克这"长文阅读"的难关。


一、AI的"长文阅读障碍"
要理解AI为何对长文本"头大",我们得先聊聊"上下文窗口"(Context Window)这个概念。你可以把它想象成AI的"短期记忆"。对于窗口内的信息,AI能轻松把握;可一旦内容超出了这个范围,AI就可能像得了"健忘症"一样,忘记了开头或中间的重要细节。这就好比让一个人背诵一部长篇小说,同时还要回答其中各种千丝万缕的联系,难度可想而知。
具体来说,AI在处理长文本时面临几大挑战:
(1)信息"长途马拉松"中的遗忘:文本越长,信息点就越多。AI需要在浩如烟海的文字中保持专注,追踪关键信息的来龙去脉,这对其记忆力和注意力都是极大的考验。
(2)"隔山打牛"式的推理难题:很多时候,理解长文本需要将相隔遥远的不同段落、不同章节甚至不同文档的信息联系起来,进行"多跳推理"。这对AI的逻辑链构建能力要求极高。
(3)算力与内存的"双重烤问":处理长文本意味着更大的计算量和内存消耗,这无疑给硬件资源带来了巨大压力,也限制了模型的应用范围。
(4)高质量"教材"的稀缺:训练AI理解长文本,需要大量优质的、标注了复杂推理关系的长文本数据。这类"教材"的稀缺,也制约了AI"长进"。
这些挑战使得AI在处理诸如法律文书分析、科研文献综述、大型项目代码理解等现实任务时,常常显得力不从心。
二、"屠龙勇士"登场:阿里通义千问QwenLong横空出世
就在大家为AI的"长文阅读障碍"一筹莫展之际,阿里巴巴通义实验室的QwenLong团队带着他们的创新成果——QwenLong-L1框架,向这一难题发起了有力挑战。这不仅仅是一个新模型那么简单,更是一套专门为长上下文推理任务量身打造的强化学习"组合拳"。
QwenLong-L1系列中的QwenLong-L1-32B模型,凭借其高达13万token的上下文长度处理能力,以及在多个长文档问答基准测试中媲美甚至超越业界顶尖模型的表现,一时间声名鹊起。更令人瞩目的是,它以320亿的参数量,达到了以往可能需要数千亿参数模型才能企及的性能,展现了惊人的"参数效率"。这无疑为AI攻克长文本理解难题,照亮了一条充满希望的道路。
三、揭秘"屠龙技":QwenLong如何驯服长文本"巨兽"?
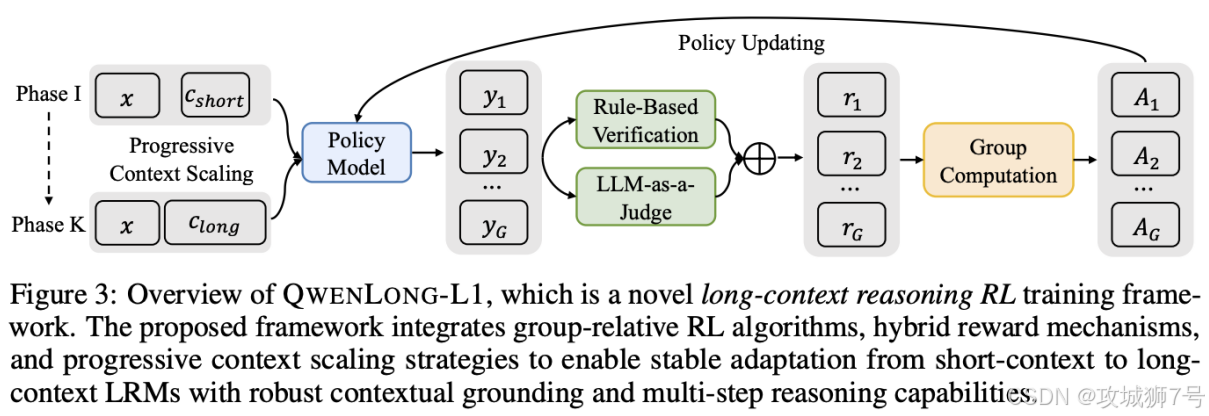
QwenLong之所以能成为"屠龙勇士",并非依靠蛮力,而是凭借其精心设计的"独门绝技"。其核心技术主要包含两大方面:**渐进式上下文扩展技术**和**混合奖励机制**。
3.1 招式一:循序渐进的"健身房"——渐进式上下文扩展技术
面对长文本这座"大山",QwenLong没有选择一步登顶,而是像一位经验丰富的健身教练,为模型设计了一套循序渐进的"训练计划":
(1)"热身运动":稳健的监督微调预热 (Warm-up SFT)
在正式开始高强度的强化学习"魔鬼训练"之前,先用一批高质量的、包含长上下文推理的问答数据对模型进行"热身"式的监督微调。这就像运动员比赛前的拉伸,能让模型先适应长文本的环境,为后续的强化学习打下坚实的基础,避免"训练翻车"。
(2)"分级课程":课程引导的分阶段强化学习 (Curriculum-guided Staged RL)
这是QwenLong最具创新性的地方。它没有粗暴地将超长文本一次性塞给模型,而是将训练过程分为几个阶段。比如,第一阶段先让模型处理2万token长度的文本,让它熟悉"中等难度";待模型适应后,第二阶段再逐步扩展到6万token甚至更长的文本,挑战"高难度"。这种"分级教学"的模式,如同让学生从小学读到大学,逐步提升认知能力,大大提高了训练的稳定性和效率,避免了模型因难度过大而"消化不良"。
(3)"错题本":难度感知的回顾采样 (Difficulty-aware Retrospective Sampling)
在学习过程中,聪明学生总会把做错的、难度高的题目记录在"错题本"上,反复练习。QwenLong也借鉴了这一思路。系统会根据模型在训练样本上的表现(比如奖励得分)来动态评估样本的"难度"。那些模型回答得不好、奖励低的"高难度"样本,会被优先保留下来,在后续的训练阶段中反复"回味",从而迫使模型持续攻克自己的薄弱环节,不断提升处理复杂问题的能力。
3.2 招式二:明察秋毫的"裁判团"——混合奖励机制
强化学习好比训练宠物,做对了给奖励,做错了给惩罚。但在开放域的长文本问答中,答案往往多种多样,如何评价模型输出的好坏,设计一个公正有效的"裁判"(奖励函数)至关重要。
以往的奖励机制,要么像个"铁面判官",要求答案与标准答案一字不差,过于严苛,可能扼杀模型生成多样化优质答案的潜力;要么像个"好好先生",只要意思相近就给高分,又可能导致模型"投机取巧",生成一些看似正确但实际有误的答案(即"Reward Hacking")。
QwenLong为此设计了一套"混合裁判团":
(1)"规则裁判":基于规则的奖励 (Rule-based Rewards)
通过正则表达式等方法,从模型输出中提取关键信息,并与标准答案进行严格匹配。这位"裁判"确保了答案在格式和关键点上的准确性,如同检查作业是否符合基本规范。
(2)"专家裁判":基于模型的评判 (Model-based Evaluation)
引入另一个轻量级的AI模型(如Qwen2.5-1.5B-Instruct)作为"专家裁判",来评估模型生成的答案与标准答案之间的语义等价性。这位"裁判"更注重理解和内涵,能够识别那些表述不同但意思相同的优质答案。
(3)"综合裁决":取长补短的组合策略
最终的奖励,综合了"规则裁判"和"专家裁判"的评分(通常取两者中的最大值)。这种机制既保证了答案的精确性,又鼓励了答案的多样性和召回率,如同一个既看重基础知识又欣赏灵活变通的考官,从而更全面地引导模型向正确的方向进化。
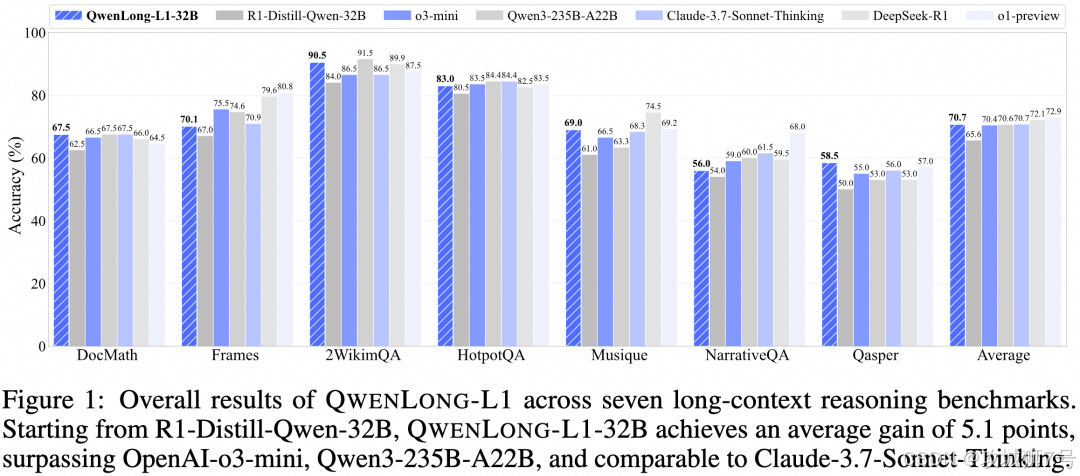
四、实力见真章:QwenLong的"成绩单"有多亮眼?
凭借这两大"屠龙技",QwenLong-L1-32B在各大长文本理解基准测试中交出了一份令人惊艳的"成绩单"。它不仅在平均表现上显著超越了像OpenAI o3-mini、阿里巴巴自家的Qwen3-235B-A22B(一个参数量远大于它的模型)等强劲对手,甚至与以长文本处理见长的Claude-3.7-Sonnet-Thinking模型达到了旗鼓相当的水平。
这其中,"参数效率"的提升尤为引人注目。320亿参数的QwenLong-L1-32B能够匹敌甚至超越参数量数倍于己的模型,这意味着更低的算力需求、更快的推理速度和更环保的AI应用,对于推动大模型技术的普及具有重要意义。
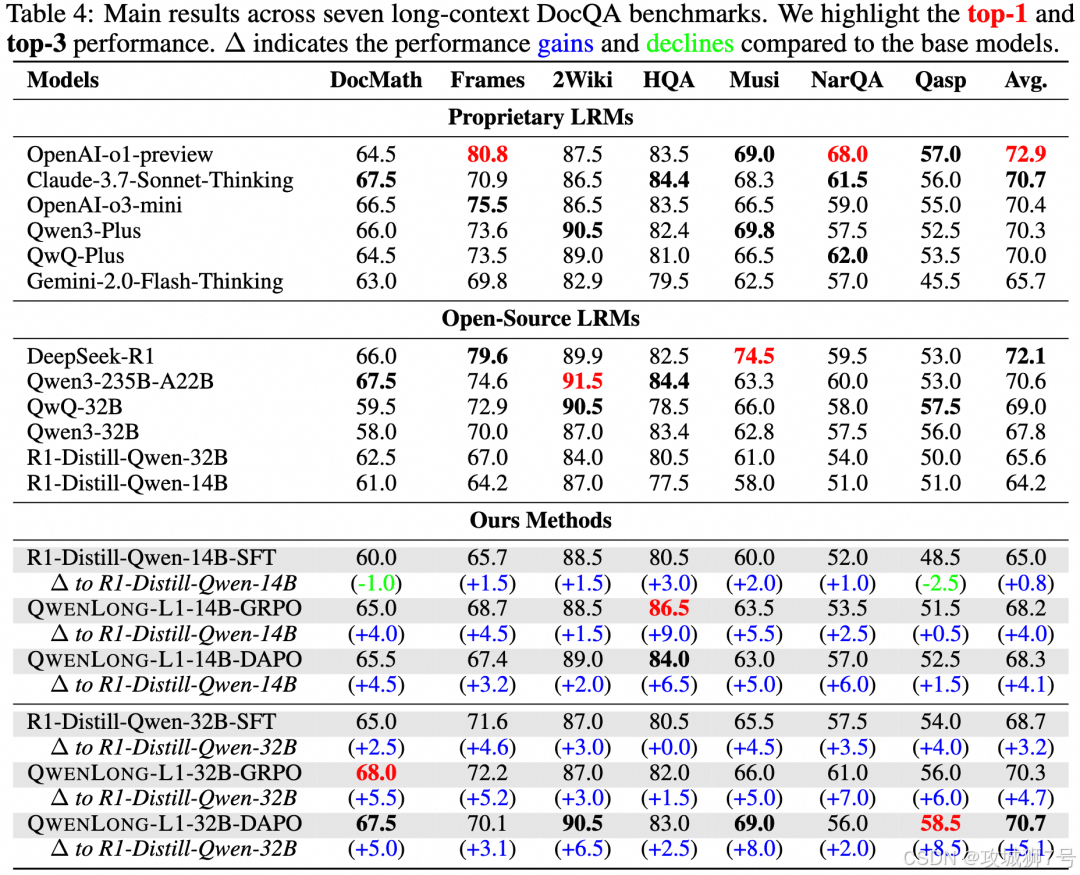
实验还揭示了监督微调(SFT)和强化学习(RL)在长文本推理中的互补关系。SFT能够以较低的成本让模型达到一个可接受的性能水平,好比打下基础;而RL则是冲击顶尖性能、实现"质变"的关键,好比进行强化特训。过度依赖SFT反而可能让模型陷入局部最优,限制了RL的提升空间。这启示我们,要培养出真正的"长文阅读高手",强化学习这块"磨刀石"必不可少。
更有趣的是,研究人员发现,在强化学习的训练过程中,模型内部与长上下文推理相关的能力(如信息定位、跨段落关联等)会自发地涌现并不断增强,最终转化为实实在在的性能提升。这仿佛AI在"刻苦修炼"中,逐渐打通了"任督二脉",领悟了长文阅读的"内功心法"。
五、不止于模型:QwenLong的开放"生态圈"
阿里巴巴深知,AI的进步离不开开放与协作。因此,QwenLong不仅带来了强大的模型,更致力于构建一个开放的"生态圈":
(1)"武功秘籍"全公开:QwenLong-L1-32B的模型代码及权重均已在GitHub、Hugging Face和ModelScope等主流开源平台开放。这意味着全球的开发者和研究者都可以免费获取、使用和改进这个模型,极大地降低了长文本AI技术的门槛。
(2)配套"练功材料":团队还发布了专门用于长文本推理强化学习的训练数据集DocQA-RL-1.6K,包含1600个覆盖数学、逻辑及多跳推理的高质量问题,为其他研究者训练自己的长文本模型提供了宝贵的"教材"。
(3)高效"轻功身法":针对长文本推理的实际应用,团队还提供了优化的推理框架。例如,通过稀疏注意力等技术,处理百万级Token的响应速度得到数倍提升,而成本却大幅降低。这使得在实际场景中部署和使用QwenLong这类长文本模型变得更加可行。
这种开放共享的姿态,无疑将加速整个长文本AI领域的技术创新和应用落地。
六、大处着眼:QwenLong将如何改变我们的世界?
QwenLong-L1的出现,其意义远不止于技术本身的突破,它更像一把钥匙,将为我们打开通往更智能未来的大门:
(1)AI普惠化的助推器:更低的成本、更高的效率、开放的生态,使得以往高不可攀的尖端AI技术能够"飞入寻常百姓家"。正如李飞飞团队基于Qwen系列模型仅用50美元就复现出顶尖推理能力的故事所揭示的,QwenLong有望进一步加速AI技术的民主化进程。
(2)行业智能化的"新引擎":
科研领域:帮助科学家快速梳理海量文献,加速知识发现和科研创新。
法律行业:高效分析复杂的合同条款、案例卷宗,提升法律服务的效率和准确性。
金融领域:精准解读冗长的财务报表、市场分析报告,辅助投资决策。
医疗健康:整合分析病人长期的医疗记录,助力精准诊断和个性化治疗。
教育培训:打造能够理解整本教材、提供深度辅导的智能导师。
内容创作:辅助作家构思和撰写长篇小说、剧本,或为用户生成更连贯、更有深度的长篇内容。
(3)中国AI力量的彰显:QwenLong的成功,是中国在人工智能核心技术领域取得自主突破的重要体现,也为中国在全球AI竞争中赢得了关键一席。
七、道阻且长,行则将至:长文本AI的星辰大海
尽管QwenLong取得了令人振奋的进展,但长文本AI的探索之路依然漫长。未来,我们还需要应对更长(甚至无限长)上下文的处理、模型真正"理解"与"记忆"能力的提升、以及如何防范长文本生成可能带来的信息偏见或误导等挑战。
但无论如何,QwenLong已经为我们指明了方向。随着技术的不断迭代和开源社区的共同努力,我们有理由相信,AI阅读"万卷书"的能力将越来越强,它们将不再仅仅是冰冷的机器,而是能够与人类进行深度知识交流、协同解决复杂问题的得力助手。
八、结语:开启AI阅读新纪元
从ComfyUI的漏洞警示我们要关注AI工具的底层安全,到QwenLong-L1在长文本理解上取得的辉煌成就,我们看到了AI技术发展的两面性:挑战与机遇并存,风险与希望同在。QwenLong的出现,无疑为AI的"阅读"能力开启了一个全新的纪元。它让我们有理由期待,一个AI能够真正"博览群书、学富五车"的时代,正向我们加速走来。而这,终将深刻改变我们获取信息、创造知识以及与世界互动的方式。让我们拭目以待,并积极拥抱这场由长文本AI引领的智能革命吧!
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!