笔者在前面的博文记一次pdf转Word的技术经历中有使用到mupdf库,该库是使用C语言写的一个操作PDF文件的库,同时提供了Python接口,Java接口和JavaScript接口。
在使用该库时,如果想要更高的性能,使用C语言接口是不二的选择。笔者在使用mupdf库C API时,遇到一个问题:调试它时不能看到数据结构,全部是一个地址,比如mupdf中的pdf_obj对象,它的API中只有一个typedef,参见mupdf/pdf/object.h:
typedef struct pdf_obj pdf_obj;
实际的结构定义是在库的pdf-object.c文件中,库使用者并不可见。它把整数(int)、浮点数(real)、字符串(string)、名字(name)、数组(array)、字典(dictinary)、间接引用(indirect reference)都抽象成pdf_obj:
typedef enum pdf_objkind_e
{PDF_INT = 'i',PDF_REAL = 'f',PDF_STRING = 's',PDF_NAME = 'n',PDF_ARRAY = 'a',PDF_DICT = 'd',PDF_INDIRECT = 'r'
} pdf_objkind;struct pdf_obj
{short refs;unsigned char kind;unsigned char flags;
};typedef struct
{pdf_obj super;union{int64_t i;float f;} u;
} pdf_obj_num;typedef struct
{pdf_obj super;char *text; /* utf8 encoded text string */size_t len;char buf[FZ_FLEXIBLE_ARRAY];
} pdf_obj_string;typedef struct
{pdf_obj super;char n[FZ_FLEXIBLE_ARRAY];
} pdf_obj_name;typedef struct
{pdf_obj super;pdf_document *doc;int parent_num;int len;int cap;pdf_obj **items;
} pdf_obj_array;typedef struct
{pdf_obj super;pdf_document *doc;int parent_num;int len;int cap;struct keyval *items;
} pdf_obj_dict;typedef struct
{pdf_obj super;pdf_document *doc; /* Only needed for arrays, dicts and indirects */int num;int gen;
} pdf_obj_ref;
然后API中全部使用pdf_obj*来操作上述数据结构:
// 创建API
pdf_obj *pdf_new_int(fz_context *ctx, int64_t i);
pdf_obj *pdf_new_real(fz_context *ctx, float f);
pdf_obj *pdf_new_name(fz_context *ctx, const char *str);
pdf_obj *pdf_new_string(fz_context *ctx, const char *str, size_t len);
pdf_obj *pdf_new_text_string(fz_context *ctx, const char *s);
pdf_obj *pdf_new_indirect(fz_context *ctx, pdf_document *doc, int num, int gen);
pdf_obj *pdf_new_array(fz_context *ctx, pdf_document *doc, int initialcap);
pdf_obj *pdf_new_dict(fz_context *ctx, pdf_document *doc, int initialcap);// 释放内存的API
void pdf_drop_obj(fz_context *ctx, pdf_obj *obj);// 检测API
int pdf_is_null(fz_context *ctx, pdf_obj *obj);
int pdf_is_bool(fz_context *ctx, pdf_obj *obj);
int pdf_is_int(fz_context *ctx, pdf_obj *obj);
int pdf_is_real(fz_context *ctx, pdf_obj *obj);
int pdf_is_number(fz_context *ctx, pdf_obj *obj);
int pdf_is_name(fz_context *ctx, pdf_obj *obj);
int pdf_is_string(fz_context *ctx, pdf_obj *obj);
int pdf_is_array(fz_context *ctx, pdf_obj *obj);
int pdf_is_dict(fz_context *ctx, pdf_obj *obj);
int pdf_is_indirect(fz_context *ctx, pdf_obj *obj);// pdf_obj转换C标准数据类型的API
int pdf_to_bool(fz_context *ctx, pdf_obj *obj);
int pdf_to_int(fz_context *ctx, pdf_obj *obj);
int64_t pdf_to_int64(fz_context *ctx, pdf_obj *obj);
float pdf_to_real(fz_context *ctx, pdf_obj *obj);
const char *pdf_to_name(fz_context *ctx, pdf_obj *obj);
const char *pdf_to_text_string(fz_context *ctx, pdf_obj *obj);
const char *pdf_to_string(fz_context *ctx, pdf_obj *obj, size_t *sizep);
char *pdf_to_str_buf(fz_context *ctx, pdf_obj *obj);
size_t pdf_to_str_len(fz_context *ctx, pdf_obj *obj);
int pdf_to_num(fz_context *ctx, pdf_obj *obj);
int pdf_to_gen(fz_context *ctx, pdf_obj *obj);
还有很多操作pdf_obj的API,就不一一列出了。这里想要说的是API的封装非常好,只是使用者在使用库时,想要更深入地查看数据,就很不友好了。
我们在C/C++语言中,经常会自定义数据结构,但是调试时调试器都会默认的按最原始的组织方式展示它们,很不直观。只有借助调试器的美化输出才能达到目的。比如C++中的STL库,定义了很多数据结构,如果不美化调试器的输出是很难查看其数据的,只是由于STL是标准库,编译器厂商已经帮我们做了相应的美化输出工作,所以可以直观地看数据。
下面笔者借调试研究mupdf库,介绍一下如何美化显示调试器的输出。目前主流的调试器有GDB、LLDB以及MS Debugger,以GDB的使用最广泛,跨Linux、MacOS、Windows、IOS、安卓等等,LLDB作为后起之秀,使用也越来越广泛,而MS Debugger本地调试器局限于Windows,但Windows使用广泛。所以笔者打算以mupdf库为例,介绍这三个调试器的美化输出。本文先介绍GDB的美化输出(Windows下的MinGW中的GDB)。
一、加载自定义脚本
GDB在启动时,会尝试加载~/.gdbinit文件(如果有就加载)。所以我们可以把一些基本设置放在这个文件中来,比如设置反汇编的格式为intel(GDB默认的反汇编格式为att)、调用自定义的python脚本。
需要注意的是在Windows下,假定用户名为admin,如果是Windows控制台,~/.gdbinit位于C:/Users/admin/.gdbinit;如果是MinGW的终端,则位于MinGW的/home/admin/.gdbinit。
比如笔者的~/.gdbinit文件如下:
# 设置反汇编格式为intel
set disassembly-flavor intel
# 设置自动加载GDB脚本的安全路径
set auto-load safe-path /
# 执行shell指令,Windows下执行chcp 65001修改控制台编码为UTF8
shell chcp 65001
# python脚本
python
import sys
# 添加python搜索模块的路径
sys.path.insert(0, 'C:/Users/admin/gdbscripts')
# 导入mupdf_printer模块
import mupdf_printer
end
在C:/Users/admin/gdbscripts中添加一个mupdf_printer.pdf文件,写一句:
print("MuPDF GDB pretty printers loaded.")
分别在Windows控制台以及MinGW终端执行GDB,看是否有输出:
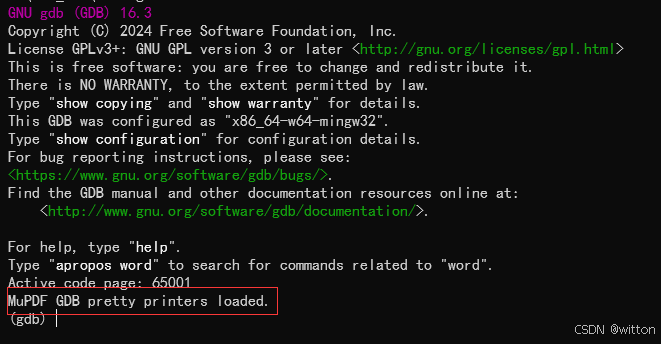
看到输出就说明自定义的脚本加载成功了。
二、写mupdf测试代码
#include <mupdf/fitz.h>
#include <mupdf/pdf.h>// 为GDB调试器使用,不能设置为static
// 这将使得GDB可以在运行时获取mupdf的版本信息
const char* mupdf_version = FZ_VERSION;int main(int argc, char* argv[]) {pdf_obj* nil = nullptr;fz_context* ctx = fz_new_context(nullptr, nullptr, FZ_STORE_UNLIMITED);pdf_document* doc = pdf_open_document(ctx, "t.pdf");pdf_obj* Int = pdf_new_int(ctx, 10);pdf_obj* Real = pdf_new_real(ctx, 3.14);pdf_obj* Str = pdf_new_text_string(ctx, "hello");pdf_obj* Name = pdf_new_name(ctx, "name");pdf_obj* ar = pdf_new_array(ctx, doc, 10);pdf_array_put(ctx, ar, 0, Int);pdf_array_put(ctx, ar, 1, Real);pdf_array_put(ctx, ar, 2, Str);pdf_array_push_bool(ctx, ar, 1);pdf_array_push_bool(ctx, ar, 0);pdf_array_push(ctx, ar, PDF_NULL);pdf_obj* dict = pdf_new_dict(ctx, doc, 10);pdf_dict_puts(ctx, dict, "int", Int);pdf_dict_puts(ctx, dict, "real", Real);pdf_dict_puts(ctx, dict, "str", Str);pdf_dict_puts(ctx, dict, "name", Name);pdf_dict_puts(ctx, dict, "array", ar);// 这里3633是笔者pdf文件中的Catalog对象pdf_obj* ref = pdf_new_indirect(ctx, doc, 3633, 0);pdf_drop_obj(ctx, Int);pdf_drop_obj(ctx, Real);pdf_drop_obj(ctx, Str);pdf_drop_obj(ctx, Name);pdf_drop_obj(ctx, ar);pdf_drop_obj(ctx, dict);pdf_drop_obj(ctx, ref);fz_drop_context(ctx);
}
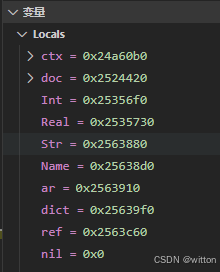
目前在VSCode下使用GDB调试时显示的变量值全部是地址:
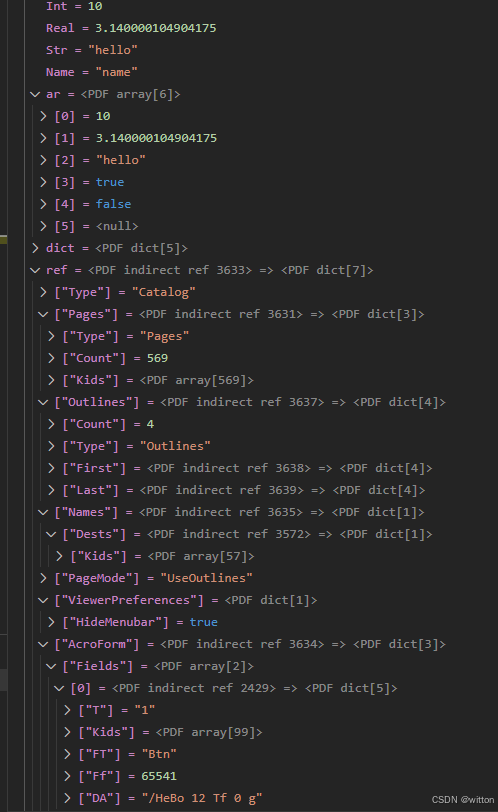
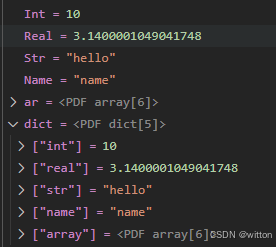
下面是笔者添加了美化显示后的效果:
三、写GDB的Python脚本
GDB的Python扩展可以参见Extending GDB using Python,我们目前只需要美化输出的API,参见Pretty Printing API,我主要使用到以下三个函数:
- pretty_printer.children (self):用于展示子节点,如果有子节点,需要实现此函数,如果没有则不写。
- pretty_printer.display_hint (self):用于提示该节点的类型,如果是字典返回
"map";如果是数组返回"array";如果是字符串,返回"string";其它情况返回None。 - pretty_printer.to_string (self):用于显示节点的值。
1. 向GDB注册pdf_obj类型
要让GDB以自定义的方式显示数据,需要先向GDB注册数据类型,这里需要注册的是pdf_obj类型。
import gdbdef pdf_obj_lookup(val):try:t = val.type.strip_typedefs()if t.code == gdb.TYPE_CODE_PTR:t = t.target()if t.name == "pdf_obj":print("<pdf_obj>")except:return Nonegdb.pretty_printers.append(pdf_obj_lookup)
print("MuPDF GDB pretty printers loaded.")
由于C语言中很多类型都是使用typedef方式定义过的,所以在解析类型时,可能需要调用strip_typedefs去掉typedef,最重要的是要去掉指针,这样方便只检测pdf_obj类型。
2. 写美化输出代码
在写美化输出的Python代码前,需要了解一下如何取值:
1. 直接使用C/C++中的字段名取字段值
如果是自己写的代码,或者使用库有调试信息,则可以直接使用字段名来取字段值,比如:
struct foo { int a, b; };
struct bar { struct foo x, y; };
则可以直接使用字段名"a"、“b”、“x”,"y"来取值:
class fooPrinter(gdb.ValuePrinter):"""Print a foo object."""def __init__(self, val):self.__val = valdef to_string(self):return ("a=<" + str(self.__val["a"]) +"> b=<" + str(self.__val["b"]) + ">")class barPrinter(gdb.ValuePrinter):"""Print a bar object."""def __init__(self, val):self.__val = valdef to_string(self):return ("x=<" + str(self.__val["x"]) +"> y=<" + str(self.__val["y"]) + ">")
2. 调用C/C++代码中的函数
如果是使用的别人编译的库,且没有调试信息,但有提供相应的API,则可以使用GDB调用API来取值。这里使用的mupdf库,在MinGW下就没有调试信息,但是提供了一系列的操作API,所以这里使用gdb.parse_and_eval来调用C/C++中的函数。需要注意的是在调用完成后需要强制转换成API对应的类型。比如,调用pdf_is_int,它的函数原型为:
int pdf_is_int(fz_context *ctx, pdf_obj *obj);
需要写成:
result = gdb.parse_and_eval(f"(int)pdf_is_int({ctx_addr}, {obj_addr}")
result中保存的就是调用的结果,如果GDB设置了set print address on,则字符串会返回地址和字符串内容:
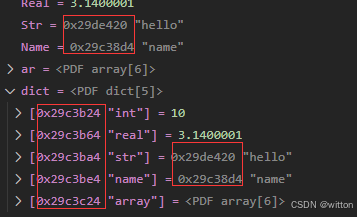
在字典显示中Key的显示会比较难看,所以需要对结果进行处理,GDB提供了string()函数去掉地址,判断到返回值是字符串,则调用result.string()去掉地址。
为了方便调用API,定义专门的函数来处理:
# 由于mupdf中的API都带有一个 fz_context* 参数,
# 为了提高性能,我们调用 fz_new_context_imp 来创建一个全局的pdf_ctx。
pdf_ctx = None# 由于fz_new_context_imp需要用到mupdf的版本号,但mupdf库并没提供这样的获取途径,
# 所以需要在C/C++代码中定义一个全局变量mupdf_version,且不能设置为静态变量
# const char* mupdf_version = FZ_VERSION;
# 然后在此写一个专门的函数来获取mupdf的版本号
def get_mupdf_version_from_symbol():try:version = gdb.parse_and_eval('(const char*)mupdf_version')return version.string()except gdb.error as e:return f"<symbol not found: {e}>"# 调用mupdf API的专用函数
# func_name是要调用的mupdf API名
# val是pdf_obj或者pdf_obj*
# retType是API的返回类型,支持int, float, str和object
# *args 是可能需要的参数,比如pdf_obj *pdf_array_get(fz_context *ctx, pdf_obj *array, int i)需要传一个索引i
def call_mupdf_api(func_name, val, retType, *args):try:# 获取地址,如果是指针,直接转成int# 如果是对象,需要取地址,再转成intif val.type.code == gdb.TYPE_CODE_PTR:addr = int(val)else:addr = int(val.address)cast = {int: "(int)",float: "(float)",str: "(const char*)",object: "(pdf_obj *)", # 转成pdf_obj指针}.get(retType, "(void)") # 根据Python传的参数,转成C/C++中的类型,默认强转为void# 如果pdf_ctx还没创建,则调用fz_new_context_imp创建global pdf_ctxif pdf_ctx is None:ver = get_mupdf_version_from_symbol()pdf_ctx = gdb.parse_and_eval(f"(fz_context*)fz_new_context_imp(0,0,0,\"{ver}\")")# 有额外参数的情况if args.__len__() > 0:args_str = ', '.join([str(arg) for arg in args])expr = f"{cast}{func_name}({pdf_ctx},{addr}, {args_str})"else: # 没额外参数的情况expr = f"{cast}{func_name}({pdf_ctx},{addr})"result = gdb.parse_and_eval(expr)# 使用全局 pdf_ctx 则此处不需要释放#gdb.parse_and_eval(f"(void)fz_drop_context({ctx})")# 根据返回类型进行处理,为了避免异常,使用cast转为C/C++中的类型if retType == int:return int(result.cast(gdb.lookup_type("int")))elif retType == float:return float(result.cast(gdb.lookup_type("float")))elif retType == str:# 去掉字符串中的地址return result.string()else:return resultexcept Exception as e:print(f"<error calling {func_name}: {e}>")return f"<error calling {func_name}: {e}>"
由于很多API的返回值都是int,为了方便,封装一下:
def call_pdf_api(func_name, val, rettype=int):return call_mupdf_api(func_name, val, rettype)def call_pdf_api_1(func_name, val, args, rettype=int):return call_mupdf_api(func_name, val, rettype, args)
3.检测pdf_obj的类型
pdf_obj可能是布尔(bool)、整数(int)、浮点数(real)、字符串(string)、名字(name)、数组(array)、字典(dictinary)、间接引用(indirect reference),在解析前,需要知道具体的类型:
def detect_pdf_obj_kind(val):try:if call_pdf_api("pdf_is_int", val):return "int"elif call_pdf_api("pdf_is_real", val):return "real"elif call_pdf_api("pdf_is_string", val):return "string"elif call_pdf_api("pdf_is_name", val):return "name"elif call_pdf_api("pdf_is_array", val):return "array"elif call_pdf_api("pdf_is_dict", val):return "dict"elif call_pdf_api("pdf_is_bool", val):return "bool"elif call_pdf_api("pdf_is_null", val):return "null"else:return "unknown"except Exception as e:print(f"<error detecting pdf_obj kind: {e}>")return "error"
4. 写各类型的美化输出
布尔(bool)、整数(int)、浮点数(real)、字符串(string)、名字(name)这些都是没有子节点的简单数据结构,所以不需要children函数:
class PDFObjIntPrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_int', self.val, int)def display_hint(self):return Noneclass PDFObjRealPrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_real', self.val, float)def display_hint(self):return Noneclass PDFObjStringPrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_text_string', self.val, str)def display_hint(self):return "string"class PDFObjNamePrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_name', self.val, str)def display_hint(self):return "string"class PDFObjBoolPrinter:def __init__(self, val):self.val = valdef to_string(self):ret = call_pdf_api("pdf_to_bool", self.val, int)return 'true' if ret else 'false'def display_hint(self):return Noneclass PDFObjNullPrinter:def __init__(self, val):self.val = valdef to_string(self):return "<null>"def display_hint(self):return None
而数组(array)、字典(dictinary)是需要展开子节点的数据结构,必须要有children函数,children函数需要返回的是一个Python的迭代器,迭代器中需要返回两个值,第一个值是名字name,第二个值则是显示内容;而字典是键值对,需要yield返回两次:
class PDFArrayPrinter:def __init__(self, val):self.val = valself.count = call_pdf_api("pdf_array_len", self.val)def to_string(self):return f"<PDF array[{self.count}]>"class _interator:def __init__(self, val, count):self.val = valself.count = countself.index = 0def __iter__(self):return selfdef __next__(self):if self.index >= self.count:raise StopIterationi = self.indexself.index += 1try:item = call_pdf_api_1("pdf_array_get", self.val, i, object)return f"{i}", itemexcept Exception:raise StopIterationdef children(self):return self._interator(self.val, self.count)def display_hint(self):return "array"class PDFDictPrinter:def __init__(self, val):self.val = valdef to_string(self):count = call_pdf_api("pdf_dict_len", self.val)return f"<PDF dict[{count}]>"def children(self):count = call_pdf_api("pdf_dict_len", self.val)for i in range(count):try:key = call_pdf_api_1("pdf_dict_get_key",self.val, i, object)val = call_pdf_api_1("pdf_dict_get_val",self.val, i, object)# 下面两个yield语句中,元组的第一个元素不能相同yield (f"{i}:k", key) # 返回键值对的键yield (f"{i}:v", val) # 返回键值对的值except Exception as e:print(f"PDFDictPrinter: error getting key {i} {e}")yield f"<key:{i}>", "<invalid>"def display_hint(self):return "map"
四、完整Python脚本:
import gdbpdf_ctx = Nonedef get_mupdf_version_from_symbol():try:version = gdb.parse_and_eval('(const char*)mupdf_version')return version.string()except gdb.error as e:return f"<symbol not found: {e}>"def call_mupdf_api(func_name, val, retType, *args):try:# 获取地址if val.type.code == gdb.TYPE_CODE_PTR:addr = int(val)else:addr = int(val.address)cast = {int: "(int)",float: "(float)",str: "(const char*)", # for functions returning const char*object: "(pdf_obj *)", # for pdf_obj pointers}.get(retType, "(void)")global pdf_ctxif pdf_ctx is None:ver = get_mupdf_version_from_symbol()pdf_ctx = gdb.parse_and_eval(f"(fz_context*)fz_new_context_imp(0,0,0,\"{ver}\")")if args.__len__() > 0:args_str = ', '.join([str(arg) for arg in args])expr = f"{cast}{func_name}({pdf_ctx},{addr}, {args_str})"else:expr = f"{cast}{func_name}({pdf_ctx},{addr})"result = gdb.parse_and_eval(expr)# 使用全局 pdf_ctx 则此处不需要释放#gdb.parse_and_eval(f"(void)fz_drop_context({ctx})") # Clean up contextif retType == int:return int(result.cast(gdb.lookup_type("int")))elif retType == float:return float(result.cast(gdb.lookup_type("float")))elif retType == str:return result.string()else:return resultexcept Exception as e:print(f"<error calling {func_name}: {e}>")return f"<error calling {func_name}: {e}>"def call_pdf_api(func_name, val, rettype=int):return call_mupdf_api(func_name, val, rettype)def call_pdf_api_1(func_name, val, args, rettype=int):return call_mupdf_api(func_name, val, rettype, args)def detect_pdf_obj_kind(val):try:if call_pdf_api("pdf_is_int", val):return "int"elif call_pdf_api("pdf_is_real", val):return "real"elif call_pdf_api("pdf_is_string", val):return "string"elif call_pdf_api("pdf_is_name", val):return "name"elif call_pdf_api("pdf_is_array", val):return "array"elif call_pdf_api("pdf_is_dict", val):return "dict"elif call_pdf_api("pdf_is_bool", val):return "bool"elif call_pdf_api("pdf_is_stream", val):return "stream"elif call_pdf_api("pdf_is_null", val):return "null"else:return "unknown"except Exception as e:print(f"<error detecting pdf_obj kind: {e}>")return "error"class PDFObjIntPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_int', self.val, int)}"def display_hint(self):return Noneclass PDFObjRealPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_real', self.val, float)}"def display_hint(self):return Noneclass PDFObjStringPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_text_string', self.val, str)}"def display_hint(self):return "string"class PDFObjNamePrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_name', self.val, str)}"def display_hint(self):return "string"class PDFObjBoolPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):ret = call_pdf_api("pdf_to_bool", self.val, int)return f"{self.ref}{'true' if ret else 'false'}"def display_hint(self):return Noneclass PDFObjNullPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}<null>"def display_hint(self):return Noneclass PDFArrayPrinter:def __init__(self, val, ref):self.val = valself.ref = refself.count = call_pdf_api("pdf_array_len", self.val)def to_string(self):return f"{self.ref}<PDF array[{self.count}]>"class _interator:def __init__(self, val, count):self.val = valself.count = countself.index = 0def __iter__(self):return selfdef __next__(self):if self.index >= self.count:raise StopIterationi = self.indexself.index += 1try:item = call_pdf_api_1("pdf_array_get", self.val, i, object)return f"{i}", itemexcept Exception:raise StopIterationdef children(self):return self._interator(self.val, self.count)def display_hint(self):return "array"class PDFDictPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):count = call_pdf_api("pdf_dict_len", self.val)return f"{self.ref}<PDF dict[{count}]>"def children(self):count = call_pdf_api("pdf_dict_len", self.val)for i in range(count):try:key = call_pdf_api_1("pdf_dict_get_key",self.val, i, object)val = call_pdf_api_1("pdf_dict_get_val",self.val, i, object)# 下面两个yield语句中,元组的第一个元素不能相同yield (f"{i}:k", key) # 返回键值对的键yield (f"{i}:v", val) # 返回键值对的值except Exception as e:print(f"PDFDictPrinter: error getting key {i} {e}")yield f"<key:{i}>", "<invalid>"def display_hint(self):return "map"def pdf_obj_lookup(val):try:t = val.typeif t.code == gdb.TYPE_CODE_PTR:t = t.target()if t.name == "pdf_obj":ref = ""if call_pdf_api("pdf_is_indirect", val):ref_num = call_pdf_api("pdf_to_num", val, int)ref = f"<PDF indirect ref {ref_num}> => "kind = detect_pdf_obj_kind(val)if kind == "int":return PDFObjIntPrinter(val, ref)elif kind == "real":return PDFObjRealPrinter(val, ref)elif kind == "string":return PDFObjStringPrinter(val, ref)elif kind == "name":return PDFObjNamePrinter(val, ref)elif kind == "array":return PDFArrayPrinter(val, ref)elif kind == "dict":return PDFDictPrinter(val, ref)elif kind == "bool":return PDFObjBoolPrinter(val, ref)elif kind == "null":return PDFObjNullPrinter(val, ref)else:print(f"<unknown pdf_obj kind: {kind}>")return Noneexcept:return Nonegdb.pretty_printers.append(pdf_obj_lookup)
print("MuPDF GDB pretty printers loaded.")不知道细心的读者有没发现,目前还有一点问题就是在VSCode中数组和字典的在展开过程中,如果已经没有可展开的项了,但是还是有一个箭头在前面。有解决办法的读者也可以在评论区讨论!
笔者可能会持续改进与补充,欲知后续版本,请移步:
https://github.com/WittonBell/demo/tree/main/mupdf/gdbscripts
如果对你有帮助,欢迎点赞收藏!







![[Windows] 摸鱼小工具:隐藏软件(重制版)](https://i-blog.csdnimg.cn/direct/287e5d77fbf64d69bd26aabde3e7dfea.png)