论文链接:https://arxiv.org/pdf/2303.17472
源码链接:https://github.com/QitaoZhao/PoseFormerV2
Abstract
本文提出了 PoseFormerV2,通过探索频率域来提高 3D 人体姿态估计的效率和鲁棒性。PoseFormerV2 利用离散余弦变换(DCT)将骨骼序列转换为低频系数,显著减少了计算量并提高了对噪声的抵抗力。实验表明,PoseFormerV2 在速度-精度权衡和鲁棒性方面显著优于 PoseFormer 和其他 Transformer 方法。
Introduction
-
目标:3D 人体姿态估计(HPE)旨在通过单目视频或 2D 关节序列估计人体关节的三维位置。
-
主流方法:随着 2D 姿态检测器的普及和 2D 表示的轻量性,2D-to-3D lifting 方法成为主流。
-
Transformer 的优势:Transformer 方法因其在建模离散关节和长时序依赖方面的优势,成为 3D 姿态估计的首选。
-
现有问题:
-
处理长序列时计算负担重。
-
对噪声 2D 检测缺乏鲁棒性。
-
-
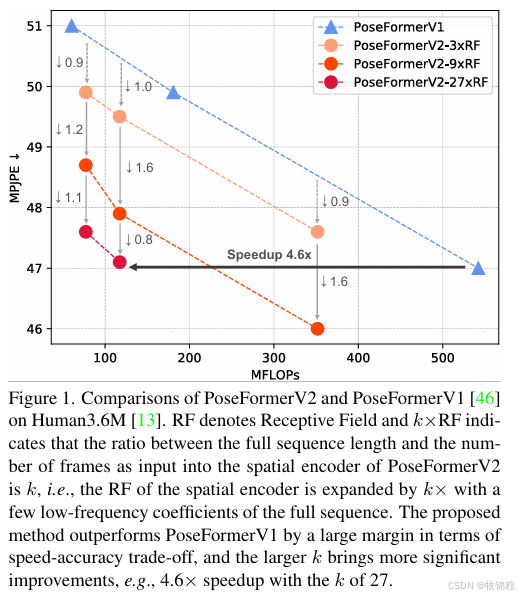
具体问题示例:PoseFormer 在 Human3.6M 数据集上使用真实 2D 检测时 MPJPE 为 31.3 mm,而使用 CPN 检测时性能下降至 44.3 mm。
-
解决方案:PoseFormerV2 引入频率域表示,通过离散余弦变换(DCT)将长序列压缩为低频系数,显著减少计算量并增强鲁棒性。
-
实验结果:PoseFormerV2 在速度和精度上优于其他方法,包括原始 PoseFormer 和其他 Transformer 变体。
Related Work
Transformer-based 3D Human Pose Estimation
-
oseFormer:首个将 Transformer 应用于 3D 人体姿态估计的方法,通过时空编码器提取特征,显著优于传统卷积方法。
-
效率问题:PoseFormer 在处理长序列时效率低下,计算负担随帧数增加而显著增加。
-
鲁棒性问题:PoseFormer 对噪声 2D 关节检测敏感,性能受 2D 检测质量影响较大。
-
后续改进:
-
MHFormer:引入多假设生成技术,模拟身体部位的深度模糊和 2D 检测器的不确定性,提升鲁棒性。
-
P-STMO:采用掩码关节建模技术,通过自监督学习提高性能。
-
StridedTransformer:通过步进卷积减少计算量,但牺牲了部分性能。
-
Einfalt et al.:通过下采样输入视频帧减少计算量,但可能影响精度。
-
-
现存问题:尽管有改进,但现有方法仍未同时解决效率和鲁棒性问题。
Frequency Representation in Vision
-
频率域表示:在计算机视觉中已有广泛应用,如 JPEG 图像压缩和基于 DCT 的特征提取。
-
低频系数的作用:
-
捕捉输入序列的主要特征。
-
过滤高频噪声,提升模型对噪声的抵抗力。
-
-
PoseFormerV2 的创新:
-
将频率域表示应用于 3D 人体姿态估计。
-
通过离散余弦变换(DCT)将骨骼序列转换为低频系数,显著减少计算量。
-
提出时间-频率特征融合模块,结合时间域和频率域特征,提升模型性能。
-
Method
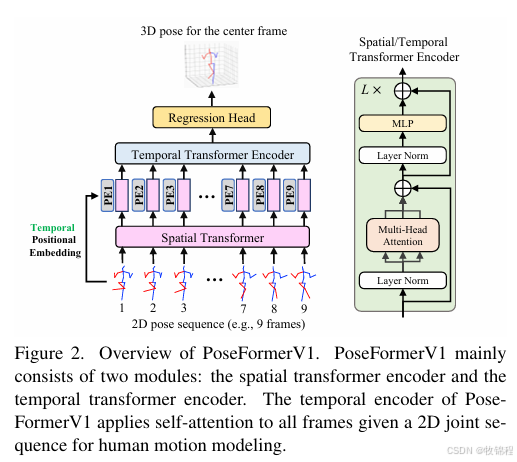
Preliminaries of PoseFormerV1
-
特征提取分阶段:PoseFormerV1 将 2D 关节序列的特征提取分为两个阶段:
-
空间编码器:用于建模单帧内关节关系,捕捉帧内关节的相互依赖。
-
时间编码器:用于建模跨帧人体运动,捕捉帧间的时间依赖。
-
-
计算复杂度:PoseFormerV1 在处理长序列时计算复杂度高,因为自注意力机制对所有帧进行密集建模。
-
对噪声敏感:PoseFormerV1 对 2D 关节检测噪声敏感,性能受输入质量影响较大。
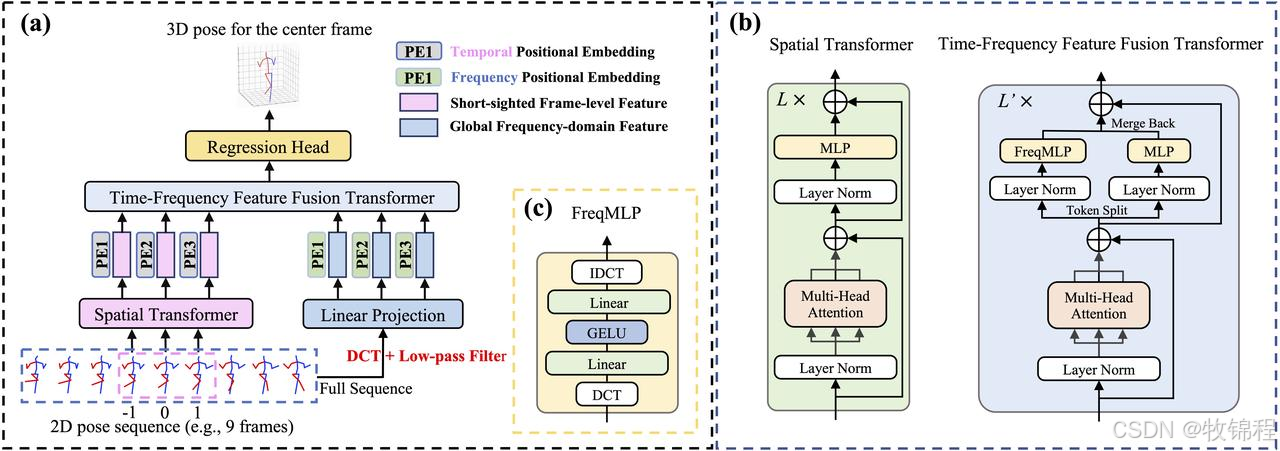
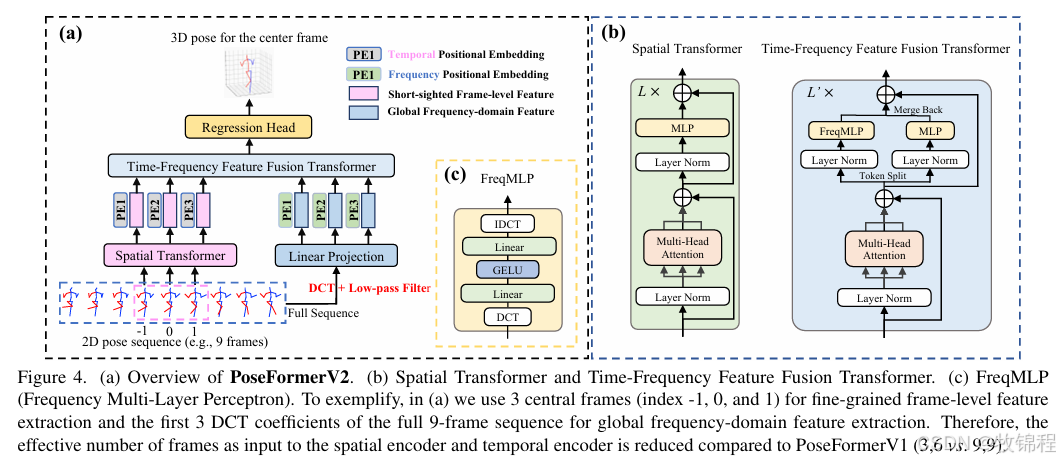
PoseFormerV2
Frequency Representation of Skeleton Sequence
-
离散余弦变换(DCT):PoseFormerV2 通过 DCT 将骨骼序列转换为低频系数,利用少量低频系数表示整个序列。
-
减少输入长度:低频系数显著减少了输入长度,降低了计算复杂度。
-
过滤高频噪声:低频系数过滤了高频噪声,增强了模型对噪声的抵抗力。
-
实验验证:实验表明,仅需少量低频系数即可捕捉序列的主要特征,同时保持较高的精度。

Architecture
-
空间 Transformer 编码器:
-
仅处理少量中心帧,减少计算量。
-
提取帧内关节的高维特征。
-
-
时间-频率特征融合模块:
-
结合时间域和频率域特征,增强模型对长序列的处理能力。
-
使用 FreqMLP 调整频率特征权重,补充时间域特征的细节信息。
-
-
回归头:
-
通过 1D 卷积层聚集时间信息。
-
输出中心帧的 3D 姿态。
-
-
整体优势:PoseFormerV2 在时间域和频率域之间进行有效的特征融合,显著减少了计算量,同时保持了更好的速度-精度权衡。
Experiments
Datasets and Evaluation Metrics
数据集
Human3.6M:最常用的室内 3D 姿态估计数据集,包含 11 名演员的 15 种动作,从 4 个不同视角拍摄,共 360 万帧。
MPI-INF-3DHP:更具挑战性的室内外场景数据集,包含复杂背景和多种动作,提供 6 个不同场景的测试集。
评价指标
MPJPE(Mean Per Joint Position Error):预测的 3D 姿态与真实值之间的平均欧几里得距离。
P-MPJPE(Procrustes Mean Per Joint Position Error):对预测的 3D 姿态进行刚性对齐后的 MPJPE。
PCK(Percentage of Correct Keypoints):在 150mm 范围内的正确关节点的百分比。
AUC(Area Under Curve):曲线下面积。
Implementation Details and Analysis
实现框架
基于 PyTorch,使用 AdamW 优化器,学习率设置为 8e-4,并采用指数衰减策略。
超参数调整
输入帧数(f)和 DCT 系数数量(n)是关键超参数,实验中通过调整这些参数展示了模型在速度和精度之间的灵活权衡。
例如,当 f = 3、n = 3 时,模型在 Human3.6M 数据集上达到了 47.9 mm 的 MPJPE,计算量为 117.3 MFLOPs。
硬件配置
实验在单个 NVIDIA RTX 3090 GPU 上进行,支持高效的训练和推理。
Comparisons with State-of-the-art Methods
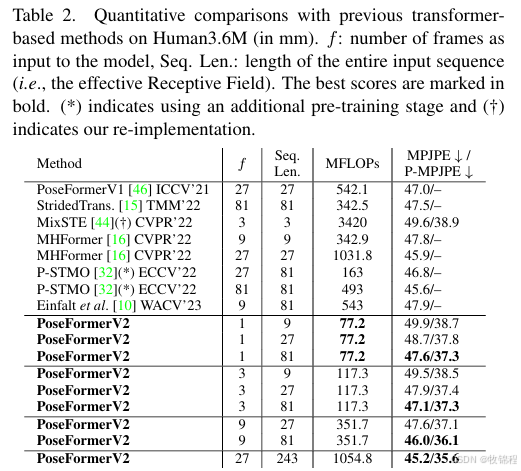
Human3.6M 数据集
PoseFormerV2
81 帧输入,77.2 MFLOPs,MPJPE 为 47.6 mm。
243 帧输入,1054.8 MFLOPs,MPJPE 为 45.2 mm。
其他方法
PoseFormerV1:81 帧输入,1.36 GFLOPs,MPJPE 为 47.0 mm。
MHFormer:81 帧输入,342.9 MFLOPs,MPJPE 为 47.8 mm。
P-STMO:243 帧输入,493 MFLOPs,MPJPE 为 45.6 mm。
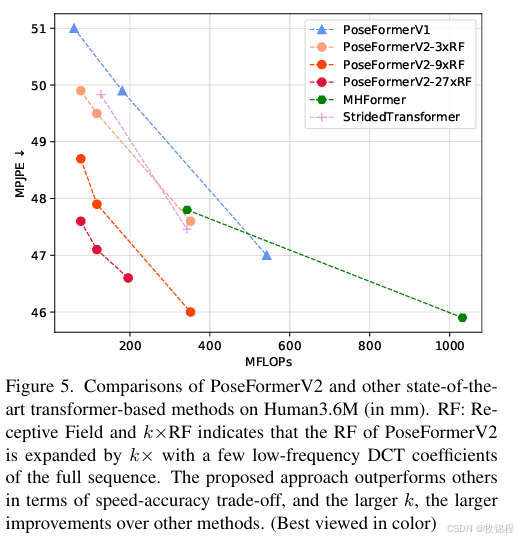
结论
PoseFormerV2 在速度和精度之间取得了更好的权衡,尤其是在处理长序列时表现出更高的效率。
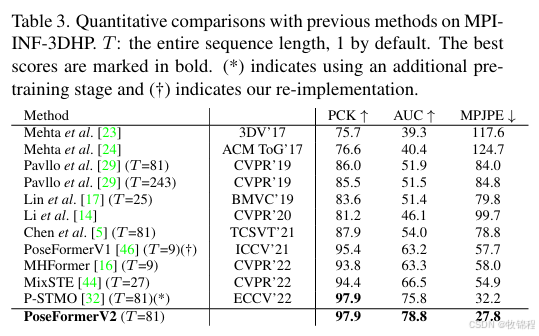
MPI-INF-3DHP 数据集
PoseFormerV2
PCK 为 97.9%,AUC 为 78.8%,MPJPE 为 27.8 mm。
其他方法
PoseFormerV1:PCK 为 95.4%,AUC 为 63.2%,MPJPE 为 57.7 mm。
P-STMO:PCK 为 97.9%,AUC 为 75.8%,MPJPE 为 32.2 mm。
结论
PoseFormerV2 在 MPI-INF-3DHP 数据集上也取得了最佳性能,验证了其在复杂场景下的鲁棒性和准确性。
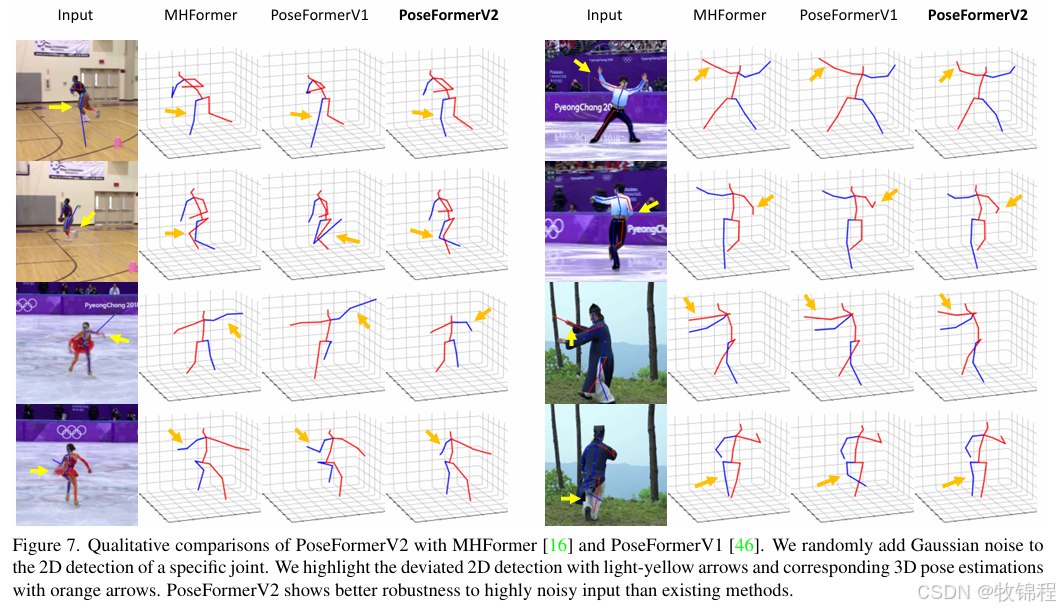
Ablation Study
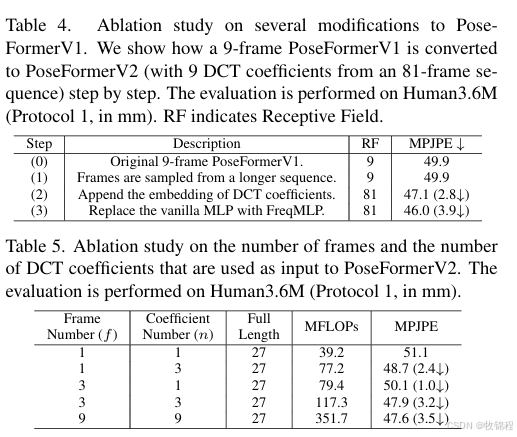
逐步改进
原始 PoseFormerV1:9 帧输入,MPJPE 为 49.9 mm。
引入低频 DCT 系数:81 帧输入,MPJPE 降低到 47.1 mm。
引入 FreqMLP:MPJPE 进一步降低到 46.0 mm。
输入帧数和 DCT 系数数量的影响
实验证明,增加输入帧数和 DCT 系数数量可以显著提高精度。例如,使用 3 个中心帧和 9 个 DCT 系数时,MPJPE 为 47.9 mm,计算量为 117.3 MFLOPs。
结论
仅需少量中心帧和低频系数即可显著提高精度和鲁棒性,同时保持较低的计算量。
Generalization Ability
推广到其他方法
MixSTE:引入低频 DCT 系数后,MPJPE 从 46.2 mm 降低到 45.3 mm,计算量从 30.8 GFLOPs 降低到 15.4 GFLOPs。
MHFormer:引入低频 DCT 系数后,鲁棒性显著提升,计算量减少。
结论
PoseFormerV2 的频率域表示方法可以推广到其他 Transformer 基方法,显著提升效率和鲁棒性。
Conclusion
PoseFormerV2 通过引入频率域表示,显著提高了 3D 人体姿态估计的效率和鲁棒性。具体贡献如下:
效率提升:PoseFormerV2 利用离散余弦变换(DCT)将长骨骼序列压缩为低频系数,显著减少了输入长度和计算量。实验表明,PoseFormerV2 在处理长序列时的计算效率远高于其他方法,例如在 81 帧输入下仅需 77.2 MFLOPs,而 MHFormer 需要 342.9 MFLOPs。
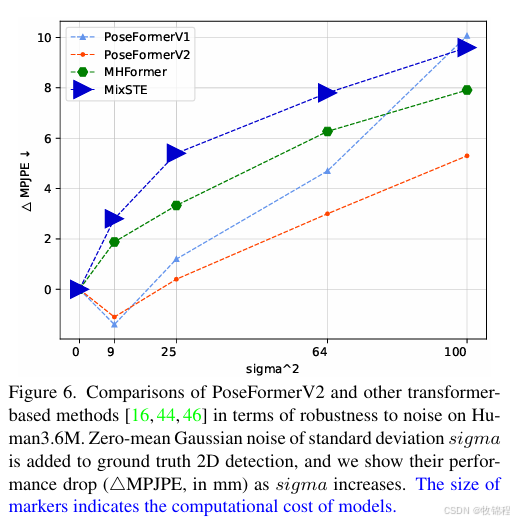
鲁棒性增强:低频系数过滤了高频噪声,增强了模型对噪声 2D 关节检测的抵抗力。实验表明,PoseFormerV2 在噪声环境下仍能保持较高的估计精度。
性能提升:在 Human3.6M 和 MPI-INF-3DHP 两个基准数据集上,PoseFormerV2 均取得了优于其他 Transformer 基方法的性能,验证了其在速度和精度之间的良好权衡。
通用性:PoseFormerV2 的方法可以推广到其他 Transformer 基方法,如 MixSTE 和 MHFormer,通过引入低频 DCT 系数,这些方法在效率和鲁棒性方面也得到了提升。
Future Work
自动优化超参数:目前,PoseFormerV2 的超参数(如输入帧数和 DCT 系数数量)是基于实验结果手动调整的。未来工作将探索如何将这些参数设置为可学习的,从而自动优化模型性能。
扩展到其他任务:PoseFormerV2 的频率域表示方法不仅适用于 3D 人体姿态估计,还可以推广到其他需要处理长序列的任务,如动作识别和行为分析。
理论分析:进一步理论分析频率域表示在 3D 姿态估计中的优势,为未来的研究提供更深入的理论支持。
PoseFormerV2 为 3D 人体姿态估计领域提供了新的视角,通过频率域表示解决了效率和鲁棒性问题,为实际应用提供了更强大的工具。
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!