HTTP/HTTPS 协议的区别及 HTTPS 加密过程
HTTP(超文本传输协议)是一种用于传输超文本的协议,它是明文传输的,这意味着数据在传输过程中容易被截取和篡改,存在较大的安全隐患。而 HTTPS(超文本传输安全协议)则是在 HTTP 的基础上加入了 SSL/TLS 协议,通过加密和身份验证机制,显著提升了数据传输的安全性。

HTTPS 的加密过程主要分为以下几个关键步骤:
首先是客户端向服务器发送请求,这个请求中包含了客户端支持的 SSL/TLS 版本以及加密算法等信息。服务器接收到请求后,会返回证书和选定的加密参数。这里的证书是由受信任的证书颁发机构(CA)签名的,用于证明服务器的身份。
接下来进行对称密钥的生成。客户端会验证证书的有效性,若证书有效,客户端会生成一个会话密钥,并使用服务器证书中的公钥对其进行加密,然后将加密后的会话密钥发送给服务器。服务器使用自己的私钥解密,从而获得会话密钥。
在对称加密通信阶段,客户端和服务器都使用这个会话密钥对数据进行加密和解密,以此保证数据在传输过程中的机密性和完整性。
HTTPS 的加密机制采用了对称加密和非对称加密相结合的方式。非对称加密(如 RSA)用于安全地交换会话密钥,而对称加密(如 AES)则用于高效地加密实际传输的数据。这种混合加密方式既保证了安全性,又兼顾了性能。
HTTP 1.x 与 HTTP 2.0 的主要区别
HTTP 1.x 是早期的 HTTP 版本,它在性能和功能上存在一定的局限性。而 HTTP 2.0 作为 HTTP 协议的新一代版本,在多个方面进行了重大改进。
二进制分帧是 HTTP 2.0 的核心特性之一。HTTP 1.x 是基于文本的协议,而 HTTP 2.0 将所有传输的信息分割为更小的帧,并采用二进制格式进行编码。这样做使得协议解析更加高效,也为多路复用提供了基础。
多路复用允许在同一个 TCP 连接上同时处理多个请求和响应。在 HTTP 1.x 中,一个 TCP 连接同一时间只能处理一个请求,这就导致了 "队头阻塞" 问题,即一个请求的处理延迟会影响后续请求。而 HTTP 2.0 通过多路复用,彻底解决了这个问题,显著提高了并发性能。
头部压缩也是 HTTP 2.0 的重要改进。HTTP 1.x 的头部信息通常比较庞大,而且每次请求都会重复发送相同的头部数据,造成了带宽的浪费。HTTP 2.0 采用 HPACK 算法对头部进行压缩,减少了头部数据的传输量,提高了传输效率。
服务器推送是 HTTP 2.0 提供的一项新功能。服务器可以在客户端请求之前,主动将客户端可能需要的资源推送给客户端,这样可以减少客户端的等待时间,提高页面加载速度。
TCP 协议三次握手和四次挥手的过程,为何需要三次握手
TCP 协议的三次握手是建立可靠连接的重要过程。第一次握手,客户端向服务器发送一个 SYN 包,其中包含客户端的初始序列号(ISN),表明客户端希望与服务器建立连接。
第二次握手,服务器收到 SYN 包后,会向客户端发送一个 SYN+ACK 包。这个包中包含服务器的初始序列号和对客户端 SYN 包的确认号,表示服务器同意建立连接。
第三次握手,客户端收到 SYN+ACK 包后,会向服务器发送一个 ACK 包,其中包含对服务器 SYN 包的确认号,表明客户端已经收到服务器的同意信息,连接建立成功。
三次握手的主要目的有两个。一是同步客户端和服务器的初始序列号,确保双方能够正确地识别和处理后续的数据传输。二是验证双方的发送和接收能力是否正常。通过三次握手,客户端和服务器都能确认自己和对方的发送和接收功能是正常的。
TCP 协议的四次挥手是关闭连接的过程。第一次挥手,客户端向服务器发送一个 FIN 包,表示客户端已经没有数据要发送了,请求关闭连接。
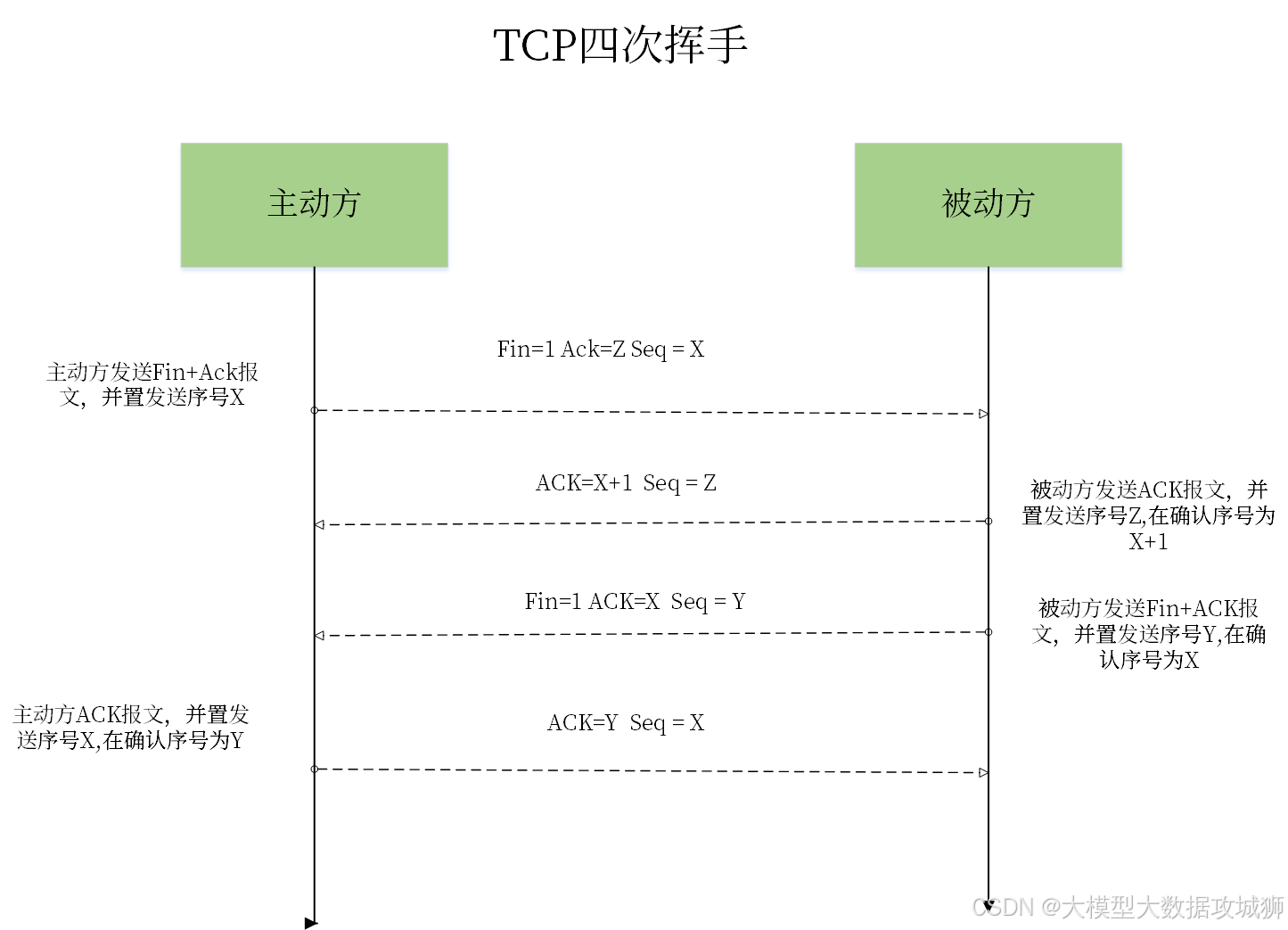
第二次挥手,服务器收到 FIN 包后,会向客户端发送一个 ACK 包,表示同意关闭客户端到服务器的连接。此时,客户端到服务器的连接已经关闭,但服务器到客户端的连接仍然开放,服务器还可以继续向客户端发送数据。
第三次挥手,服务器向客户端发送一个 FIN 包,表示服务器已经没有数据要发送了,请求关闭服务器到客户端的连接。
第四次挥手,客户端收到 FIN 包后,会向服务器发送一个 ACK 包,表示同意关闭服务器到客户端的连接。此时,服务器到客户端的连接也关闭了,整个 TCP 连接彻底关闭。
四次挥手中 TIME_WAIT 状态的作用和常见问题
在四次挥手过程中,客户端在发送最后一个 ACK 包后,会进入 TIME_WAIT 状态,并保持这个状态一段时间(通常是 2MSL,即两倍的最大段生存时间)。
TIME_WAIT 状态的主要作用有两个。一是确保最后一个 ACK 包能够到达服务器。如果服务器没有收到这个 ACK 包,它会重新发送 FIN 包,客户端在 TIME_WAIT 状态下可以接收这个重传的 FIN 包,并再次发送 ACK 包,从而避免连接无法正常关闭的情况。
二是防止旧的数据包干扰新的连接。在 TIME_WAIT 状态期间,该连接的所有数据包都会在网络中消失,这样可以确保后续使用相同源地址、目的地址和端口号建立的新连接不会受到旧数据包的影响。
然而,TIME_WAIT 状态也可能带来一些问题。过多的 TIME_WAIT 状态可能会占用系统资源,特别是在高并发的情况下,可能会导致系统无法创建新的连接。此外,TIME_WAIT 状态的存在也可能会影响服务器的性能,特别是在需要频繁建立和关闭连接的应用场景中。
为了解决这些问题,可以采取一些措施。例如,可以调整系统参数,缩短 TIME_WAIT 状态的保持时间,或者允许系统重用处于 TIME_WAIT 状态的端口。另外,优化应用程序的设计,减少频繁建立和关闭连接的操作,也可以有效减轻 TIME_WAIT 状态带来的影响。
七层网络模型(OSI)和四层网络模型(TCP/IP)的层级结构及对应协议
七层网络模型(OSI)和四层网络模型(TCP/IP)是两种常用的网络分层模型,它们从不同的角度对网络通信进行了抽象和分层。
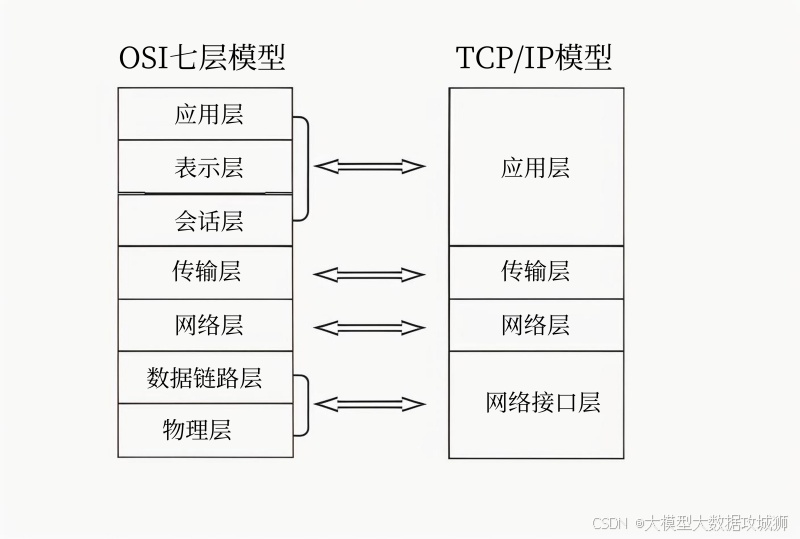
七层网络模型(OSI)从下到上依次为物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。
物理层是网络通信的基础,它负责传输比特流,处理物理介质(如电缆、光纤、无线等)上的信号传输,包括信号的编码、解码、传输速率等。常见的协议有 Ethernet、WiFi、USB 等。
数据链路层将物理层传输的比特流封装成帧,负责帧的传输和错误检测,包括 MAC 地址的处理、介质访问控制等。常见的协议有 Ethernet、PPP、HDLC 等。
网络层负责将帧从源节点传输到目标节点,处理网络中的路由和寻址,包括 IP 地址的处理、路由选择等。常见的协议有 IP、ICMP、IGMP 等。
传输层提供端到端的可靠通信,确保数据的可靠传输,包括流量控制、错误恢复等。常见的协议有 TCP、UDP 等。
会话层负责建立、维护和管理会话,包括会话的建立、拆除和同步等。常见的协议有 RPC、NetBIOS 等。
表示层负责数据的表示和转换,包括数据的加密、解密、压缩、解压缩等。常见的协议有 SSL/TLS、JPEG、ASCII 等。
应用层为用户提供应用程序接口,直接面向用户的应用程序,包括 HTTP、FTP、SMTP、DNS 等。
四层网络模型(TCP/IP)从下到上依次为网络接口层、网络层、传输层和应用层。
网络接口层对应 OSI 模型的物理层和数据链路层,负责网络的物理连接和帧的传输。
网络层对应 OSI 模型的网络层,负责 IP 数据包的传输和路由。
传输层对应 OSI 模型的传输层,负责端到端的通信,提供 TCP 和 UDP 协议。
应用层对应 OSI 模型的会话层、表示层和应用层,负责为用户提供应用程序接口,包括 HTTP、FTP、SMTP、DNS 等协议。
可以看出,TCP/IP 模型是一种更简化的模型,它将 OSI 模型中的会话层、表示层和应用层合并为应用层,将物理层和数据链路层合并为网络接口层。这种简化使得 TCP/IP 模型更加实用,也更容易实现。
视频直播常用的传输协议(如 RTMP、HTTP-FLV、WebRTC)及其选择依据
视频直播领域,传输协议的选择对直播效果起着至关重要的作用。不同的传输协议在延迟、兼容性、带宽利用率等方面存在差异,需要根据具体的应用场景进行选择。
RTMP(Real-Time Messaging Protocol)是一种基于 TCP 的实时消息传输协议,由 Adobe 公司开发。它最初用于 Flash 播放器与服务器之间的音视频传输,具有低延迟的特点,适合实时互动性强的场景,如在线直播、视频会议等。RTMP 协议采用二进制格式,支持音视频数据的实时传输,并且可以通过 RTSP 协议从摄像机等设备获取实时视频流。然而,随着移动互联网的发展,Flash 播放器的使用逐渐减少,RTMP 的应用也受到了一定的限制。
HTTP-FLV(HTTP Fluent Live Video)是一种基于 HTTP 协议的流媒体传输协议,它将 FLV 文件封装在 HTTP 请求中进行传输。HTTP-FLV 协议具有良好的穿透性,能够绕过防火墙的限制,并且可以利用 CDN 进行内容分发,提高视频的传输效率。与 RTMP 相比,HTTP-FLV 的延迟略高,但在大多数情况下仍然可以满足直播的需求。此外,HTTP-FLV 协议支持在浏览器中直接播放,无需安装额外的插件,具有较好的兼容性。
WebRTC(Web Real-Time Communication)是一种基于 Web 技术的实时通信协议,它允许浏览器之间直接进行音视频通信,无需中间服务器。WebRTC 协议具有极低的延迟,适合实时性要求极高的场景,如视频通话、在线游戏等。WebRTC 协议采用 UDP 作为传输层协议,通过 ICE(Interactive Connectivity Establishment)、STUN(Session Traversal Utilities for NAT)和 TURN(Traversal Using Relays around NAT)等技术实现穿越 NAT 设备,确保浏览器之间能够建立直接连接。然而,WebRTC 协议的实现较为复杂,需要处理网络抖动、丢包等问题,并且在网络状况不佳的情况下,视频质量可能会受到较大影响。
在选择视频直播传输协议时,需要考虑以下几个因素:
延迟要求是选择传输协议的重要因素之一。如果对延迟要求较高,如实时互动直播、视频会议等场景,建议选择 RTMP 或 WebRTC 协议。如果对延迟要求不是特别高,如在线教育、企业宣传等场景,可以选择 HTTP-FLV 协议。
兼容性也是需要考虑的因素。RTMP 协议需要 Flash 播放器的支持,在移动设备上的兼容性较差。HTTP-FLV 协议可以在大多数浏览器中直接播放,兼容性较好。WebRTC 协议是基于 Web 技术的,只要浏览器支持 WebRTC 接口,就可以直接使用,无需安装额外的插件。
带宽利用率也是选择传输协议的重要因素之一。RTMP 协议采用 TCP 作为传输层协议,具有较好的可靠性,但在网络状况不佳的情况下,可能会导致带宽利用率下降。HTTP-FLV 协议同样采用 TCP 作为传输层协议,带宽利用率与 RTMP 类似。WebRTC 协议采用 UDP 作为传输层协议,在网络状况不佳的情况下,可以通过丢包重传等技术提高带宽利用率,但实现较为复杂。
CDN 支持也是选择传输协议时需要考虑的因素。HTTP-FLV 协议可以很好地利用 CDN 进行内容分发,提高视频的传输效率和可靠性。RTMP 协议在 CDN 上的支持相对较少,需要选择支持 RTMP 分发的 CDN 服务提供商。WebRTC 协议由于是浏览器之间直接进行通信,一般不需要 CDN 支持,但在某些情况下,如需要进行媒体转码、录制等操作时,也可以结合 CDN 使用。
多级行政区划(省 - 市 - 区 - 街道)的数据库设计方案
多级行政区划的数据库设计是许多应用系统中常见的需求,合理的设计方案能够提高数据的查询效率和维护便捷性。
一种常见的设计方案是采用自引用表结构,即在一张表中存储所有级别的行政区划信息,通过父节点 ID 来建立层级关系。这种设计方案的优点是结构简单,查询和维护都比较方便。可以通过递归查询或使用 WITH RECURSIVE 语句来查询某一行政区划的所有子节点。然而,这种设计方案在处理大规模数据时,查询效率可能会受到影响,特别是在进行深层次的递归查询时。
另一种设计方案是为每个级别创建单独的表,如省份表、城市表、区县表和街道表。这种设计方案的优点是结构清晰,每个表只存储特定级别的行政区划信息,查询效率较高。可以通过外键关联来建立不同级别之间的关系。然而,这种设计方案在进行跨级别查询时,需要进行多个表的连接查询,可能会影响查询效率。
在设计多级行政区划数据库时,还需要考虑行政区划的编码规则。行政区划编码是一种对行政区划进行唯一标识的编码方式,常见的编码规则有国家标准 GB/T 2260 和国际标准 ISO 3166。在数据库中存储行政区划编码可以提高数据的查询效率和数据的一致性。
为了提高查询效率,可以在相关字段上创建索引。例如,在父节点 ID 字段上创建索引可以加快递归查询的速度,在行政区划名称字段上创建索引可以加快按名称查询的速度。
对于经常需要进行统计和分析的应用场景,可以考虑添加冗余字段来存储一些统计信息。例如,在省份表中添加一个字段来存储该省份的城市数量,在城市表中添加一个字段来存储该城市的区县数量等。这样可以避免在进行统计查询时进行复杂的计算,提高查询效率。
在设计多级行政区划数据库时,还需要考虑数据的导入和维护问题。行政区划数据通常是静态数据,但也会随着时间的推移而发生变化。因此,需要设计一个方便的数据导入和更新机制,确保数据的准确性和及时性。
单节点数据库性能优化的常见方法
单节点数据库性能优化是数据库管理中的重要任务,通过合理的优化措施,可以提高数据库的响应速度和吞吐量,减少用户等待时间。
查询优化是提高数据库性能的重要手段。通过分析查询语句的执行计划,找出执行效率低下的查询语句,并进行优化。可以通过添加合适的索引、优化查询条件、避免全表扫描等方式来提高查询效率。
索引优化也是关键的一环。索引可以加快数据的查询速度,但过多的索引会影响数据的插入、更新和删除操作的性能。因此,需要根据实际业务需求,合理创建和维护索引。定期对索引进行重建和统计信息收集,确保索引的有效性。
数据库参数调整对性能也有重要影响。根据数据库的硬件配置和业务特点,调整数据库的参数,如内存分配、缓冲区大小、并发连接数等,可以提高数据库的性能。不同的数据库系统有不同的参数配置,需要根据具体情况进行调整。
表结构优化同样不可忽视。合理的表结构设计可以提高数据的存储效率和查询效率。例如,避免表中出现过多的列和行,对大表进行分表分库,优化字段类型等。
硬件升级是提高数据库性能的最直接方法。如果数据库的性能瓶颈是由于硬件资源不足导致的,可以考虑升级硬件配置,如增加内存、更换更快的硬盘、升级 CPU 等。
查询缓存可以缓存查询结果,当相同的查询再次执行时,可以直接返回缓存的结果,减少查询的执行时间。但需要注意查询缓存的失效机制,避免缓存过期的数据。
定期对数据库进行维护,如清理无用数据、收缩数据库文件、重建索引等,可以提高数据库的性能和稳定性。
监控数据库的性能指标,如 CPU 使用率、内存使用率、IOPS、查询响应时间等,及时发现性能瓶颈,并采取相应的优化措施。
堆和栈的内存分配区别
在计算机内存管理中,堆和栈是两种重要的内存分配方式,它们在内存分配方式、内存管理、性能等方面存在明显的区别。
栈内存由操作系统自动分配和释放,而堆内存需要程序员手动分配和释放。当一个函数被调用时,操作系统会为该函数的局部变量在栈上分配内存,当函数执行完毕后,这些内存会被自动释放。而堆内存的分配和释放则需要程序员使用特定的函数(如 malloc、free 等)来完成。
栈内存的分配和释放速度非常快,因为它只需要移动栈指针即可。而堆内存的分配和释放则相对较慢,因为它需要进行内存的查找和管理。
栈内存的空间通常比较小,一般只有几兆到几十兆不等。而堆内存的空间则比较大,可以达到几 GB 甚至更大。
栈内存中的变量存储的是局部变量、函数参数、返回地址等,这些变量的作用域仅限于函数内部。而堆内存中存储的是程序员动态分配的内存,这些内存可以在程序的任何地方被访问和使用。
栈内存中的变量按照后进先出(LIFO)的顺序进行管理,而堆内存中的变量则没有特定的顺序,它们由操作系统的内存管理器进行管理。
栈内存的分配和释放是线程安全的,因为每个线程都有自己独立的栈空间。而堆内存的分配和释放则需要考虑线程安全问题,因为多个线程可能会同时访问和修改堆内存中的数据。
栈内存的使用效率高,因为它的分配和释放速度快,而且不会产生内存碎片。而堆内存的使用效率相对较低,因为它的分配和释放速度慢,而且容易产生内存碎片。
虚函数和纯虚函数的作用及实现机制
虚函数和纯虚函数是 C++ 中实现多态的重要机制,它们在面向对象编程中起着至关重要的作用。
虚函数是在基类中声明的,并且在派生类中可以被重写的函数。通过使用虚函数,可以实现时多态,即通过基类的指针或引用调用派生类的函数。虚函数的声明使用关键字 virtual,例如:
class Base {
public:virtual void print() {std::cout << "This is the Base class." << std::endl;}
};class Derived : public Base {
public:void print() override {std::cout << "This is the Derived class." << std::endl;}
};
虚函数的实现机制是通过虚函数表(VTable)和虚表指针(VPTR)来实现的。每个包含虚函数的类都有一个虚函数表,该表存储了该类的虚函数的地址。每个对象都有一个虚表指针,该指针指向该对象所属类的虚函数表。当通过基类的指针或引用调用虚函数时,程序会根据虚表指针找到对应的虚函数表,然后在虚函数表中查找并调用相应的函数。
纯虚函数是在基类中声明的,但没有具体实现的虚函数。纯虚函数的声明使用 = 0 语法,例如:
class Base {
public:virtual void print() = 0; // 纯虚函数
};
包含纯虚函数的类称为抽象类,抽象类不能被实例化,只能作为基类被派生类继承。派生类必须实现基类中的所有纯虚函数,否则派生类也会成为抽象类。
纯虚函数的作用是定义接口,强制派生类实现特定的功能。通过使用纯虚函数,可以实现接口与实现的分离,提高代码的可维护性和可扩展性。
虚函数和纯虚函数的主要区别在于:虚函数有默认的实现,派生类可以选择重写或不重写;而纯虚函数没有实现,派生类必须重写。虚函数用于实现时多态,而纯虚函数用于定义接口。
在实际应用中,虚函数和纯虚函数经常用于实现设计模式,如工厂模式、策略模式等。通过使用虚函数和纯虚函数,可以使代码更加灵活、可扩展和可维护。
C++ 常用容器(vector、list、map、unordered_map 等)的适用场景与底层结构
C++ 提供了多种容器,每种容器都有其独特的底层结构和适用场景。了解这些容器的特点有助于选择最合适的数据结构来解决问题。
vector 是动态数组,支持随机访问,底层是连续的内存空间。它的优点是随机访问速度极快,时间复杂度为 O(1),适用于需要频繁随机访问元素的场景。在尾部插入和删除元素的效率也很高,平均时间复杂度为 O(1),但在中间或头部插入删除元素时,需要移动大量元素,时间复杂度为 O(n)。当 vector 的容量不足时,会重新分配更大的内存空间,并将原有元素复制过去,这可能导致性能开销。vector 适用于存储需要快速访问且插入删除操作主要在尾部的元素,如动态数组、列表等。
list 是双向链表,由节点组成,每个节点包含数据和指向前驱和后继节点的指针。它不支持随机访问,访问元素需要从头或尾遍历,时间复杂度为 O(n)。但在任意位置插入和删除元素的效率极高,时间复杂度为 O(1),因为只需要调整指针的指向。list 适用于需要频繁在中间插入删除元素的场景,如实现链表、队列等数据结构。
map 是有序关联容器,基于红黑树(一种自平衡二叉搜索树)实现。它存储键值对,按键的升序排列。插入、删除和查找操作的时间复杂度均为 O(log n)。map 适用于需要按键有序存储和查找元素的场景,如字典、索引等。由于红黑树的平衡性,保证了操作的效率。
unordered_map 是无序关联容器,基于哈希表实现。它通过哈希函数将键映射到哈希桶中,平均情况下插入、删除和查找操作的时间复杂度为 O(1)。但在最坏情况下(哈希冲突严重),时间复杂度可能退化为 O(n)。unordered_map 适用于需要快速查找元素且不关心元素顺序的场景,如缓存、哈希表等。
set 和 multiset 是基于红黑树实现的有序集合,set 中不允许重复元素,而 multiset 允许。它们的插入、删除和查找操作的时间复杂度均为 O(log n)。适用于需要有序存储且快速查找元素的场景。
unordered_set 和 unordered_multiset 是基于哈希表实现的无序集合,同样 unordered_set 不允许重复元素,unordered_multiset 允许。平均情况下操作时间复杂度为 O(1),适用于快速查找且不关心顺序的场景。
deque(双端队列)是动态数组,但支持在头部和尾部高效插入和删除元素,时间复杂度为 O(1)。它结合了 vector 和 list 的部分优点,适用于需要在两端进行频繁插入删除操作的场景。
stack 和 queue 是适配器容器,stack 基于 deque 或 list 实现,遵循后进先出(LIFO)原则;queue 基于 deque 或 list 实现,遵循先进先出(FIFO)原则。它们适用于特定的算法和数据处理场景。
在选择容器时,需要考虑以下因素:访问模式(随机访问还是顺序访问)、插入删除操作的频率和位置、是否需要元素有序、元素的类型和大小等。例如,如果需要频繁随机访问且插入删除主要在尾部,vector 是不错的选择;如果需要在中间频繁插入删除,list 更合适;如果需要按键快速查找且有序,map 是首选;如果不关心顺序,unordered_map 效率更高。
字节对齐的规则和作用
字节对齐是计算机内存管理中的一个重要概念,它影响着数据在内存中的存储方式和访问效率。
字节对齐的规则通常由编译器和硬件平台共同决定。在大多数系统中,基本数据类型的对齐规则是:该类型的大小即为其对齐边界。例如,char 类型(1 字节)的对齐边界是 1 字节,short 类型(2 字节)的对齐边界是 2 字节,int 类型(通常 4 字节)的对齐边界是 4 字节,long long 类型(8 字节)的对齐边界是 8 字节。
结构体和类的对齐规则更为复杂。结构体的第一个成员的起始地址是结构体的起始地址。每个后续成员的起始地址必须是该成员类型对齐边界的整数倍。如果前一个成员结束后,剩余的空间不足以满足下一个成员的对齐要求,则会在它们之间填充字节。结构体的总大小必须是其最大成员对齐边界的整数倍,因此在结构体的末尾可能也会填充字节。
字节对齐的主要作用是提高内存访问效率。现代计算机的内存访问通常是以字为单位进行的,如果数据存储在对齐的地址上,处理器可以一次访问完成。例如,一个 4 字节的 int 变量,如果存储在 4 字节对齐的地址上,处理器可以一次读取 4 字节的数据。如果该变量没有对齐,可能需要两次访问才能获取完整的数据,这会降低访问效率。
此外,字节对齐还与平台兼容性有关。某些硬件平台要求特定类型的数据必须存储在对齐的地址上,否则会抛出异常或导致程序崩溃。为了保证程序在不同平台上的兼容性,编译器通常会遵循字节对齐规则。
然而,字节对齐也会带来一定的空间浪费。由于填充字节的存在,结构体的实际大小可能会大于其成员大小之和。例如,一个包含 char 和 int 的结构体,char 占 1 字节,int 占 4 字节,但由于对齐要求,结构体的总大小可能是 8 字节,其中有 3 字节是填充字节。
在某些情况下,程序员可以通过#pragma pack 指令或 alignas 关键字来调整对齐方式,以减少空间浪费或满足特定的内存布局要求。但这种做法可能会影响性能,需要谨慎使用。
C++ 内存管理方式(手动管理、智能指针)
C++ 提供了多种内存管理方式,主要包括手动管理和智能指针管理,每种方式都有其优缺点和适用场景。
手动内存管理是 C++ 最基本的内存管理方式,通过 new 和 delete 操作符来分配和释放内存。使用 new 操作符在堆上分配内存,返回一个指向该内存的指针;使用 delete 操作符释放该内存。例如:
int* ptr = new int(42); // 分配内存
// 使用 ptr
delete ptr; // 释放内存
手动管理内存的优点是灵活性高,程序员可以完全控制内存的分配和释放时机。但这种方式也存在明显的缺点,容易导致内存泄漏(忘记释放内存)和悬空指针(释放内存后仍然使用指针)等问题。特别是在复杂的程序中,手动管理内存的难度较大,容易出现错误。
为了解决手动内存管理的问题,C++ 引入了智能指针。智能指针是一种类模板,它封装了原始指针,并在适当的时候自动释放内存,从而避免内存泄漏。C++ 标准库提供了三种主要的智能指针:unique_ptr、shared_ptr 和 weak_ptr。
unique_ptr 是一种独占式智能指针,它确保同一时间只有一个智能指针指向该内存。当 unique_ptr 被销毁时,它所指向的内存也会被自动释放。unique_ptr 不能被复制,但可以通过 std::move 转移所有权。例如:
std::unique_ptr<int> ptr1 = std::make_unique<int>(42); // 创建 unique_ptr
// std::unique_ptr<int> ptr2 = ptr1; // 错误:不能复制 unique_ptr
std::unique_ptr<int> ptr2 = std::move(ptr1); // 转移所有权
shared_ptr 是一种共享式智能指针,它使用引用计数来管理内存。多个 shared_ptr 可以指向同一块内存,当最后一个 shared_ptr 被销毁时,内存才会被释放。引用计数会在每次复制 shared_ptr 时增加,在每次释放 shared_ptr 时减少。例如:
std::shared_ptr<int> ptr1 = std::make_shared<int>(42); // 创建 shared_ptr
std::shared_ptr<int> ptr2 = ptr1; // 复制 shared_ptr,引用计数加 1
weak_ptr 是一种弱引用智能指针,它不拥有内存的所有权,而是对 shared_ptr 所管理的内存的一种弱引用。weak_ptr 不会增加引用计数,主要用于解决 shared_ptr 可能出现的循环引用问题。例如:
std::shared_ptr<int> ptr1 = std::make_shared<int>(42);
std::weak_ptr<int> ptr2 = ptr1; // 创建 weak_ptr 指向 ptr1 管理的内存
智能指针的优点是自动管理内存,减少了内存泄漏和悬空指针的风险,提高了代码的安全性和可维护性。但智能指针也有一些开销,如引用计数的维护等,在性能敏感的场景中需要考虑。
在实际编程中,应尽量使用智能指针来管理动态内存,减少手动管理内存的使用。只有在特殊情况下,如需要精确控制内存分配和释放时机,或与不支持智能指针的代码交互时,才使用手动内存管理。
三种智能指针(unique_ptr、shared_ptr、weak_ptr)的区别与使用场景
C++ 标准库提供的三种智能指针 unique_ptr、shared_ptr 和 weak_ptr 各有特点,适用于不同的场景。
unique_ptr 是独占式智能指针,它禁止拷贝语义,确保同一时间只有一个智能指针指向该内存。当 unique_ptr 被销毁时,它所指向的内存会被自动释放。这种独占性使得 unique_ptr 非常适合管理资源,如文件句柄、网络连接等,确保资源的所有权清晰,避免资源泄漏。unique_ptr 的转移语义通过 std::move 实现,允许将所有权从一个 unique_ptr 转移到另一个。例如,在函数返回动态分配的对象时,可以使用 unique_ptr 安全地传递所有权。
shared_ptr 是共享式智能指针,它使用引用计数来管理内存。多个 shared_ptr 可以共享同一块内存,每当一个新的 shared_ptr 指向该内存时,引用计数加 1;当一个 shared_ptr 被销毁时,引用计数减 1。当引用计数变为 0 时,内存被自动释放。shared_ptr 适用于需要多个对象共享同一资源的场景,如在多个模块之间共享数据。但需要注意的是,shared_ptr 的循环引用问题,即两个对象通过 shared_ptr 互相引用,会导致引用计数永远不会变为 0,从而造成内存泄漏。
weak_ptr 是一种弱引用智能指针,它不拥有内存的所有权,而是对 shared_ptr 所管理的内存的一种弱引用。weak_ptr 不会增加引用计数,主要用于解决 shared_ptr 的循环引用问题。当需要访问 shared_ptr 管理的对象,但又不想影响其生命周期时,可以使用 weak_ptr。weak_ptr 可以通过 lock() 方法获取一个临时的 shared_ptr,从而安全地访问对象。如果对象已经被销毁,lock() 会返回一个空的 shared_ptr。
在使用场景方面,unique_ptr 适用于资源的独占式管理,如工厂模式返回对象的所有权。shared_ptr 适用于资源的共享场景,如在容器中存储对象的指针。weak_ptr 则主要用于打破 shared_ptr 的循环引用,如在观察者模式中,观察者对象持有被观察对象的弱引用,避免影响被观察对象的生命周期。
三种智能指针的性能也有所不同。unique_ptr 由于不需要维护引用计数,开销最小。shared_ptr 需要维护引用计数,有一定的性能开销。weak_ptr 虽然不增加引用计数,但 lock() 操作需要检查对象是否存在,也有一定的开销。
在选择使用哪种智能指针时,应根据资源的所有权需求和生命周期管理来决定。优先使用 unique_ptr 来管理资源,当需要共享资源时使用 shared_ptr,当需要解决循环引用问题时使用 weak_ptr。
malloc/free 与 new/delete 的区别
malloc/free 和 new/delete 是 C++ 中用于动态内存分配和释放的两种方式,它们有以下主要区别:
malloc/free 是 C 语言的标准库函数,而 new/delete 是 C++ 的操作符。这是它们最基本的区别。
new/delete 除了分配和释放内存外,还会调用对象的构造函数和析构函数。而 malloc/free 仅仅是分配和释放内存空间,不会进行对象的初始化和清理工作。例如,使用 new 创建对象时,会自动调用构造函数;使用 delete 释放对象时,会自动调用析构函数。而 malloc 只是分配一块内存,不会调用构造函数;free 也不会调用析构函数。
new 操作符返回的是对象类型的指针,无需进行类型转换。而 malloc 返回的是 void* 类型的指针,需要显式地将其转换为所需的类型。例如:
int* ptr1 = new int(42); // 正确,无需类型转换
int* ptr2 = (int*)malloc(sizeof(int)); // 需要显式类型转换
new/delete 可以被重载,用户可以自定义内存分配和释放的行为。而 malloc/free 是标准库函数,无法被重载。
new 有两种形式:普通的 new 和定位 new(placement new)。定位 new 允许在已分配的内存块上构造对象。而 malloc 没有类似的功能。
在内存分配失败时,new 会抛出 std::bad_alloc 异常,而 malloc 会返回 NULL 指针。因此,使用 new 时需要进行异常处理,而使用 malloc 时需要检查返回值是否为 NULL。
new/delete 可以与 C++ 的智能指针一起使用,方便内存管理。而 malloc/free 与智能指针不兼容,无法直接使用。
对于数组的分配,new 有专门的语法 new[] 来分配数组,对应的释放语法是 delete[]。而 malloc 分配数组时与分配单个对象没有区别,释放时也使用 free。需要注意的是,使用 new[] 分配的数组必须使用 delete[] 释放,否则会导致未定义行为。
在性能方面,new/delete 通常比 malloc/free 略慢,因为它们需要进行更多的操作,如构造函数和析构函数的调用。但这种性能差异在大多数情况下可以忽略不计。
在 C++ 中,建议优先使用 new/delete 来管理动态内存,因为它们更符合面向对象的编程理念,能够自动处理对象的构造和析构。只有在与 C 代码交互或需要精确控制内存分配时,才使用 malloc/free。
ptmalloc 和 tcmalloc 内存池的工作原理
ptmalloc(glibc 内存分配器)和 tcmalloc(Google 线程缓存内存分配器)是两种常见的内存池实现,它们在设计目标和工作原理上有显著差异。
ptmalloc 是 glibc 库的默认内存分配器,采用主分配区(main arena)和非主分配区(non-main arena)的多线程架构。每个进程有一个主分配区,支持多线程访问但需要加锁保护。当线程数增加时,会创建多个非主分配区,每个非主分配区与特定线程绑定,减少锁竞争。ptmalloc 将内存分为不同大小的 bins,小内存(小于 512B)从 fast bins 或 small bins 分配,大内存从 large bins 分配,更大的内存直接通过 mmap 向操作系统申请。这种设计平衡了内存分配速度和碎片化问题,但在高并发场景下锁竞争仍然是瓶颈。
tcmalloc 是 Google 开发的高性能内存分配器,专为多线程环境优化。它采用三级缓存结构:线程本地缓存(Thread Cache)、中央缓存(Central Cache)和页堆(Page Heap)。线程本地缓存为每个线程单独分配,无需加锁,大幅提高了分配速度。当本地缓存不足时,从中央缓存批量获取内存;中央缓存负责全局内存的分配和回收;页堆则管理大块内存,与操作系统交互。tcmalloc 通过减少锁竞争和优化内存布局,显著提升了多线程程序的性能,尤其在高并发场景下优势明显。
两种分配器的性能特点不同。ptmalloc 在单线程和低并发场景下表现良好,但在高并发场景下由于锁竞争性能下降明显。tcmalloc 通过线程本地缓存避免了大部分锁竞争,在高并发场景下性能远优于 ptmalloc,但内存碎片化问题可能更严重。
在内存管理策略上,ptmalloc 更注重内存利用率,采用复杂的内存合并和回收算法减少碎片化。tcmalloc 则更注重分配速度,允许一定程度的内存浪费以换取性能提升。例如,tcmalloc 的线程本地缓存可能会保留一些不再使用的内存,直到线程结束。
多线程编程的基本概念(线程同步、锁机制等)
多线程编程允许程序同时执行多个任务,提高了资源利用率和程序响应速度,但也引入了线程同步和数据竞争等挑战。
线程同步是确保多个线程安全访问共享资源的技术。当多个线程同时访问和修改共享数据时,可能会导致数据不一致或其他未定义行为,称为竞态条件。线程同步的主要目的是避免竞态条件,保证程序的正确性。
锁机制是最常用的线程同步技术之一。互斥锁(Mutex)是一种基本的锁,它提供排他性访问,同一时间只有一个线程可以获得锁并访问共享资源。C++ 标准库提供了 std::mutex 和 std::lock_guard 等工具来实现互斥锁。例如:
std::mutex mtx;
void shared_resource_access() {std::lock_guard<std::mutex> lock(mtx);// 临界区,访问共享资源
}
读写锁(Read-Write Lock)允许多个线程同时读取共享资源,但在写入时需要独占访问。这种锁适用于读多写少的场景,可以提高并发性能。C++17 引入了 std::shared_mutex 来实现读写锁。
条件变量(Condition Variable)用于线程间的等待-通知机制。当一个线程需要等待某个条件满足时,可以使用条件变量进入等待状态;另一个线程在条件满足时通知等待的线程。C++ 标准库提供了 std::condition_variable 来实现这一机制。
原子操作(Atomic Operations)是一种无锁的同步技术,通过硬件支持的原子指令实现。原子操作可以保证对共享变量的操作是不可分割的,避免了锁的开销。C++ 标准库提供了 std::atomic 模板类来实现原子操作。
死锁是多线程编程中的一个严重问题,当两个或多个线程互相等待对方释放资源时,就会发生死锁。避免死锁的方法包括按相同顺序获取锁、设置锁的超时时间等。
条件变量的使用场景和实现原理
条件变量是多线程编程中用于线程间同步的重要工具,它允许线程等待某个条件满足后再继续执行。
条件变量的典型使用场景包括生产者-消费者模型、任务队列、资源池等。在生产者-消费者模型中,当队列满时,生产者线程需要等待;当队列空时,消费者线程需要等待。条件变量可以有效地实现这种等待-通知机制。
条件变量的实现原理基于操作系统提供的底层机制。在 Linux 系统中,条件变量通常基于 futex(Fast Userspace Mutex)实现。futex 是一种用户态和内核态混合的同步机制,在大多数情况下不需要陷入内核,从而提高了性能。
C++ 标准库中的 std::condition_variable 提供了 wait() 和 notify_one()/notify_all() 等接口。当线程调用 wait() 时,它会释放关联的互斥锁并进入等待状态;当其他线程调用 notify_one() 或 notify_all() 时,等待的线程会被唤醒,并重新获取互斥锁。
条件变量的正确使用通常需要与互斥锁配合。例如:
std::mutex mtx;
std::condition_variable cv;
bool ready = false;void worker_thread() {std::unique_lock<std::mutex> lock(mtx);cv.wait(lock, []{ return ready; });// 执行任务
}void main_thread() {{std::lock_guard<std::mutex> lock(mtx);ready = true;}cv.notify_one(); // 通知等待的线程
}
需要注意的是,条件变量可能会出现虚假唤醒(spurious wakeup),即线程在没有收到通知的情况下被唤醒。因此,在调用 wait() 时通常需要提供一个谓词(如上述代码中的 lambda 表达式),以确保条件确实满足。
条件变量的实现还涉及线程队列的管理。当线程进入等待状态时,会被加入到条件变量的等待队列中;当通知发生时,线程会从队列中移除并被唤醒。
CAS(Compare-and-Swap)无锁算法的原理与应用
CAS(Compare-and-Swap)是一种无锁算法,用于实现多线程环境下的同步操作,避免了传统锁机制的开销和性能瓶颈。
CAS 操作包含三个参数:内存位置(V)、预期原值(A)和新值(B)。CAS 操作的原子性保证了只有当内存位置 V 的值等于预期原值 A 时,才会将该位置的值更新为新值 B;否则,操作失败。这个过程是原子的,不会被其他线程中断。
在 C++ 中,可以使用 std::atomic 模板类提供的 compare_exchange_weak() 和 compare_exchange_strong() 方法来实现 CAS 操作。例如:
std::atomic<int> value(0);
int expected = 0;
bool success = value.compare_exchange_weak(expected, 1);
if (success) {// CAS 操作成功
} else {// CAS 操作失败,expected 现在包含当前值
}
CAS 的原理基于硬件支持的原子指令,如 x86 架构上的 CMPXCHG 指令。这些指令确保了 CAS 操作的原子性,无需使用锁。
CAS 的应用场景包括实现无锁数据结构(如无锁队列、无锁栈)、原子计数器、自旋锁等。在高并发场景下,CAS 可以显著提高性能,因为它避免了锁带来的上下文切换和线程阻塞开销。
然而,CAS 也有一些局限性。ABA 问题是 CAS 的一个经典问题,即一个值从 A 变为 B,再变回 A,CAS 操作会认为值没有变化,但实际上已经发生了改变。解决 ABA 问题的一种方法是使用版本号,每次修改时增加版本号。
CAS 的另一个问题是在竞争激烈的情况下,可能会导致大量的重试操作,浪费 CPU 资源。因此,CAS 更适合于竞争不太激烈的场景。
阻塞队列的设计与实现
阻塞队列是一种特殊的队列,当队列为空时,获取元素的操作会被阻塞;当队列满时,插入元素的操作会被阻塞。这种特性使得阻塞队列非常适合实现生产者-消费者模型。
阻塞队列的设计需要考虑线程安全、阻塞和唤醒机制以及边界条件处理。在 C++ 中,可以使用 std::mutex 和 std::condition_variable 来实现线程安全和阻塞唤醒机制。
一个基本的阻塞队列实现如下:
#include <queue>
#include <mutex>
#include <condition_variable>template<typename T>
class BlockingQueue {
public:void enqueue(const T& value) {std::unique_lock<std::mutex> lock(mutex_);// 等待队列不满not_full_.wait(lock, [this]{ return queue_.size() < capacity_; });queue_.push(value);// 通知队列非空not_empty_.notify_one();}T dequeue() {std::unique_lock<std::mutex> lock(mutex_);// 等待队列非空not_empty_.wait(lock, [this]{ return !queue_.empty(); });T value = queue_.front();queue_.pop();// 通知队列不满not_full_.notify_one();return value;}private:std::queue<T> queue_;size_t capacity_;std::mutex mutex_;std::condition_variable not_empty_;std::condition_variable not_full_;
};
在这个实现中,enqueue() 方法用于向队列中插入元素,如果队列已满,则线程会被阻塞,直到队列中有空间。dequeue() 方法用于从队列中获取元素,如果队列为空,则线程会被阻塞,直到队列中有元素。
阻塞队列的容量可以根据需要设置。当容量为无限大时,enqueue() 操作永远不会被阻塞;当容量为 1 时,阻塞队列退化为同步队列,每次插入操作都需要等待对应的删除操作。
在设计阻塞队列时,还需要考虑异常安全和性能优化。例如,在上面的实现中,如果 T 的拷贝构造函数抛出异常,可能会导致队列状态不一致。可以通过使用移动语义和智能指针来提高性能和安全性。
阻塞队列的应用场景包括线程池、任务调度系统、消息队列等。在这些场景中,阻塞队列可以有效地解耦生产者和消费者,提高系统的并发性能和可扩展性。
线程池的设计思路与实现要点
线程池是一种多线程处理模式,通过预先创建一定数量的线程,避免了频繁创建和销毁线程带来的开销,提高了系统的性能和稳定性。
线程池的核心设计包括任务队列、工作线程集合和线程管理机制。任务队列用于存储待处理的任务,工作线程从任务队列中获取任务并执行。线程管理机制负责控制线程的创建、销毁和状态管理。
线程池的实现要点包括:
-
任务队列的设计:任务队列需要是线程安全的,支持多线程并发访问。可以使用阻塞队列实现,当队列为空时,线程会被阻塞;当有新任务加入时,线程会被唤醒。
-
线程的创建和管理:线程池通常会预先创建一定数量的线程,这些线程会一直,直到线程池被销毁。线程池需要根据系统负载动态调整线程数量,避免资源浪费。
-
拒绝策略:当任务队列已满且线程池中的线程都在忙碌时,需要有相应的拒绝策略来处理新提交的任务。常见的拒绝策略包括直接拒绝、丢弃最老的任务、丢弃当前任务等。
-
线程池的生命周期管理:线程池需要提供启动、停止和优雅关闭等操作。优雅关闭时,线程池会等待所有已提交的任务执行完毕,然后再关闭所有线程。
以下是一个简单的线程池实现示例:
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>class ThreadPool {
public:ThreadPool(size_t threads);template<class F, class... Args>auto enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>;~ThreadPool();
private:// 工作线程集合std::vector<std::thread> workers;// 任务队列std::queue<std::function<void()>> tasks;// 同步机制std::mutex queue_mutex;std::condition_variable condition;bool stop;
};// 构造函数,初始化线程池
inline ThreadPool::ThreadPool(size_t threads): stop(false)
{for(size_t i = 0; i < threads; ++i)workers.emplace_back([this]{while(true){std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);this->condition.wait(lock,[this]{ return this->stop || !this->tasks.empty(); });if(this->stop && this->tasks.empty())return;task = std::move(this->tasks.front());this->tasks.pop();}task();}});
}// 添加新任务到线程池
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>
{using return_type = typename std::result_of<F(Args...)>::type;auto task = std::make_shared< std::packaged_task<return_type()> >(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);// 不允许在线程池停止后添加新任务if(stop)throw std::runtime_error("enqueue on stopped ThreadPool");tasks.emplace([task](){ (*task)(); });}condition.notify_one();return res;
}// 析构函数,关闭线程池
inline ThreadPool::~ThreadPool()
{{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for(std::thread &worker : workers)worker.join();
}
线程池的应用场景包括高并发服务器、批处理任务、并行计算等。在实际应用中,需要根据系统负载和任务特性合理配置线程池的大小,避免线程过多导致上下文切换开销过大,或线程过少导致资源利用率不足。
分布式唯一 ID 生成的开源框架(如 UUID、Snowflake、Leaf 等)
在分布式系统中,生成全局唯一的 ID 是一个常见的需求。不同的场景对 ID 的要求不同,例如高性能、有序性、趋势递增等。目前,开源社区提供了多种分布式唯一 ID 生成方案。
UUID(Universally Unique Identifier)
UUID 是由一组 32 个 16 进制数字组成的字符串,标准形式包括 32 个字符,分为五段,形式为 8-4-4-4-12 的 36 个字符。UUID 的生成算法保证了在全球范围内的唯一性,不依赖于中央节点。常见的 UUID 版本有基于时间戳的版本 1、基于随机数的版本 4 等。
优点:实现简单,不依赖于任何服务;全局唯一,无重复风险;生成速度快。
缺点:字符串形式存储,占用空间大;无序性,不适合作为数据库主键;安全性较低,基于时间戳的 UUID 可能泄露系统信息。
Snowflake(雪花算法)
Snowflake 是 Twitter 开源的分布式 ID 生成算法,生成的 ID 是一个 64 位的长整型数字,结构为:1 位符号位 + 41 位时间戳 + 5 位数据中心 ID + 5 位机器 ID + 12 位序列号。
优点:生成的 ID 是趋势递增的,适合作为数据库主键;不依赖于数据库,性能高;可以根据实际需求调整各部分的位数。
缺点:强依赖机器时钟,如果时钟回拨,可能会生成重复 ID;需要分配和管理机器 ID 和数据中心 ID。
Leaf(美团开源框架)
Leaf 是美团开源的分布式 ID 生成系统,提供了两种生成方式:基于数据库的号段模式和类 Snowflake 模式。
-
号段模式:Leaf 从数据库中批量获取 ID 号段,在本地内存中分配,减少了对数据库的访问频率。每次获取一个号段(例如 1000 个 ID),用完后再从数据库获取下一个号段。
-
Snowflake 模式:Leaf 实现了类似 Snowflake 的算法,但解决了时钟回拨问题。当检测到时钟回拨时,会等待时钟恢复或切换到备用机器。
优点:支持高并发、高性能;号段模式不依赖于机器时钟,不存在时钟回拨问题;提供了 RESTful API,方便集成。
缺点:号段模式依赖于数据库,如果数据库不可用,可能会影响 ID 生成;需要维护数据库和相关配置。
UidGenerator(百度开源框架)
UidGenerator 是百度开源的分布式 ID 生成器,基于 Snowflake 算法,但进行了优化。它通过缓存未来时间的 ID 来解决时钟回拨问题,并支持自定义 ID 生成策略。
优点:高性能,每秒可生成百万级别的 ID;解决了时钟回拨问题;支持自定义 ID 结构。
缺点:需要依赖于机器时钟和 ZooKeeper 来分配工作节点 ID。
在选择分布式唯一 ID 生成方案时,需要根据具体的业务场景和需求来决定。如果对 ID 的有序性和性能要求较高,可以选择 Snowflake 或其变种;如果对 ID 的唯一性要求严格,不关心有序性,可以选择 UUID;如果需要简单易用且支持高并发,可以选择 Leaf 或 UidGenerator。
RPC(远程过程调用)的基本原理和实现方式
RPC(Remote Procedure Call)是一种允许程序调用远程服务器上的过程或函数的技术,使得调用远程函数就像调用本地函数一样简单。RPC 是构建分布式系统的基础技术之一。
RPC 的基本原理包括以下几个步骤:
-
客户端调用:客户端程序像调用本地函数一样调用一个远程函数,并传递参数。
-
客户端存根(Stub):客户端存根是一个本地函数,它接收客户端的调用,并将参数打包成消息。
-
网络传输:消息通过网络传输到服务器端。
-
服务器存根(Skeleton):服务器存根接收消息,并解包参数。
-
服务器调用:服务器存根调用实际的远程函数,并获取返回值。
-
返回结果:返回值被打包成消息,通过网络传输回客户端。
-
客户端接收结果:客户端存根接收返回消息,解包返回值,并返回给客户端程序。
RPC 的实现方式可以分为以下几个关键组件:
-
序列化/反序列化:将参数和返回值转换为字节流,以便在网络上传输。常见的序列化协议有 JSON、XML、Protobuf、Thrift 等。
-
网络传输:负责消息的传输,常见的传输协议有 TCP、UDP、HTTP 等。
-
服务发现:客户端需要知道服务器的地址和端口,服务发现机制可以帮助客户端动态获取服务器信息。
-
负载均衡:在多个服务器实例之间分配请求,提高系统的可用性和性能。
-
错误处理:处理网络异常、超时、服务器故障等问题。
以下是一个简单的 RPC 框架实现示例:
// 客户端代码
#include <iostream>
#include <string>
#include <rpc/client.h>int main() {// 创建 RPC 客户端,连接到服务器rpc::client client("127.0.0.1", 8080);// 调用远程函数 add,传递参数 4 和 5auto result = client.call("add", 4, 5);// 获取返回值int sum = result.as<int>();std::cout << "4 + 5 = " << sum << std::endl;return 0;
}// 服务器代码
#include <iostream>
#include <rpc/server.h>// 远程函数实现
int add(int a, int b) {return a + b;
}int main() {// 创建 RPC 服务器,监听 8080 端口rpc::server server(8080);// 注册远程函数server.bind("add", &add);// 启动服务器std::cout << "Server started on port 8080..." << std::endl;server.run();return 0;
}
常见的开源 RPC 框架包括:
-
gRPC:Google 开源的高性能 RPC 框架,使用 Protobuf 作为序列化协议,支持多种编程语言。
-
Thrift:Apache 开源的跨语言 RPC 框架,支持多种序列化协议和传输层协议。
-
Dubbo:阿里巴巴开源的高性能 Java RPC 框架,提供了服务发现、负载均衡、集群容错等功能。
-
gSOAP:一个开源的 C/C++ RPC 框架,支持 SOAP 和 RESTful 风格的 Web 服务。
RPC 的优点是简化了分布式系统的开发,使开发者可以像调用本地函数一样调用远程函数。缺点是增加了系统的复杂性,需要处理网络延迟、可靠性等问题。在选择 RPC 框架时,需要考虑性能、易用性、跨语言支持、生态系统等因素。
异步阻塞、异步非阻塞 I/O 的概念与区别
在计算机系统中,I/O 操作是一个常见的性能瓶颈。为了提高 I/O 效率,发展出了多种 I/O 模型,包括同步阻塞、同步非阻塞、异步阻塞和异步非阻塞 I/O。
同步阻塞 I/O
同步阻塞 I/O 是最基本的 I/O 模型。在这种模型中,当应用程序发起一个 I/O 请求时,线程会被阻塞,直到 I/O 操作完成。例如,在调用 read() 函数时,线程会一直等待,直到数据从磁盘或网络读取到缓冲区中。
优点:实现简单,代码逻辑清晰。
缺点:线程在等待 I/O 操作完成期间不能做其他事情,导致 CPU 资源浪费,系统吞吐量低。
同步非阻塞 I/O
同步非阻塞 I/O 中,应用程序发起 I/O 请求后,线程不会被阻塞,而是立即返回。应用程序需要不断轮询 I/O 操作的状态,直到操作完成。例如,在调用 read() 函数时,如果数据尚未准备好,函数会立即返回一个错误码,应用程序需要再次调用 read() 函数进行尝试。
优点:线程在等待 I/O 操作完成期间可以执行其他任务,提高了 CPU 利用率。
缺点:需要不断轮询 I/O 状态,增加了 CPU 开销;代码复杂度较高。
异步阻塞 I/O
异步阻塞 I/O 中,应用程序发起一个 I/O 请求后,线程会被阻塞,但 I/O 操作由操作系统在后台完成。当 I/O 操作完成后,操作系统会通知应用程序,线程才会恢复执行。例如,在 Windows 系统中的 Overlapped I/O 就是一种异步阻塞 I/O。
优点:应用程序不需要关心 I/O 操作的具体实现,只需要等待操作完成的通知。
缺点:线程在等待期间仍然被阻塞,不能执行其他任务。
异步非阻塞 I/O
异步非阻塞 I/O 是最高效的 I/O 模型。在这种模型中,应用程序发起一个 I/O 请求后,线程不会被阻塞,而是继续执行其他任务。I/O 操作由操作系统在后台完成,当操作完成后,操作系统会通过回调函数或事件通知应用程序。例如,Linux 系统中的 epoll 和 Windows 系统中的 IOCP 都是异步非阻塞 I/O 的实现。
优点:线程在等待 I/O 操作完成期间可以执行其他任务,提高了系统吞吐量;不需要轮询 I/O 状态,减少了 CPU 开销。
缺点:实现复杂,需要处理回调函数或事件通知;代码调试和维护难度较大。
四种 I/O 模型的主要区别在于同步/异步和阻塞/非阻塞两个维度:
-
同步/异步:同步 I/O 中,应用程序需要主动查询 I/O 操作的状态;异步 I/O 中,操作系统会在 I/O 操作完成后通知应用程序。
-
阻塞/非阻塞:阻塞 I/O 中,线程在等待 I/O 操作完成期间被阻塞;非阻塞 I/O 中,线程在等待期间可以继续执行其他任务。
在实际应用中,需要根据具体场景选择合适的 I/O 模型。对于 I/O 密集型应用,异步非阻塞 I/O 通常是最佳选择,可以充分利用系统资源,提高吞吐量;对于 CPU 密集型应用,同步阻塞 I/O 可能更合适,因为线程大部分时间都在执行计算任务,I/O 操作相对较少。
Reactor 模型的工作原理和应用场景
Reactor 模型是一种事件驱动的设计模式,用于处理多个客户端的并发请求。它通过将 I/O 事件的检测和处理分离,提高了系统的并发性能和可扩展性。
Reactor 模型的核心组件包括:
-
Reactor:负责监听和分发 I/O 事件,是整个模型的核心。它通常使用 select、poll、epoll 等系统调用进行 I/O 多路复用,检测多个文件描述符上的事件。
-
Handler:负责处理具体的 I/O 事件,实现业务逻辑。每个 Handler 对应一个特定的事件类型。
-
Demultiplexer:事件分离器,负责等待和检测 I/O 事件。在 Linux 系统中,通常使用 epoll 实现;在 Windows 系统中,使用 IOCP 实现。
Reactor 模型的工作流程如下:
-
注册事件:应用程序将 Handler 注册到 Reactor 中,并指定感兴趣的事件类型(如读事件、写事件)。
-
事件循环:Reactor 启动事件循环,不断调用 Demultiplexer 等待事件发生。
-
事件检测:Demultiplexer 检测到有事件发生时,将事件通知给 Reactor。
-
事件分发:Reactor 根据事件类型,将事件分发给对应的 Handler 处理。
-
事件处理:Handler 处理具体的 I/O 事件,完成业务逻辑。处理完成后,可能会注册新的事件。
Reactor 模型有几种变体:
-
单线程 Reactor 模型:所有的 I/O 操作和业务处理都在同一个线程中完成。这种模型实现简单,但在高并发场景下性能有限,因为一个 Handler 的长时间处理可能会阻塞整个线程。
-
多线程 Reactor 模型:在单线程 Reactor 模型的基础上,将业务处理放到线程池中执行,Reactor 线程只负责 I/O 事件的检测和分发。这种模型提高了并发性能,但 Reactor 线程仍然可能成为瓶颈。
-
主从 Reactor 模型:将 Reactor 分为主 Reactor 和从 Reactor。主 Reactor 负责接受客户端连接,并将连接分发给从 Reactor;从 Reactor 负责处理具体的 I/O 事件。这种模型进一步提高了并发性能,适用于大规模并发场景。
Reactor 模型的应用场景包括:
-
网络服务器:如高性能 Web 服务器、数据库服务器等,需要处理大量并发连接。
-
实时系统:如金融交易系统、游戏服务器等,需要快速响应客户端请求。
-
中间件:如消息队列、RPC 框架等,需要高效处理消息和请求。
-
分布式系统:如分布式文件系统、分布式计算框架等,需要处理节点间的通信。
Reactor 模型的优点是提高了系统的并发性能和可扩展性,缺点是实现复杂,需要处理多线程同步和资源竞争问题。在实际应用中,需要根据系统的负载和需求选择合适的 Reactor 模型变体。
Protobuf 序列化的实现原理
Protobuf(Protocol Buffers)是 Google 开发的一种高效的序列化机制,用于结构化数据的序列化和反序列化。它通过定义数据结构的 .proto 文件,生成对应的代码,将数据序列化为二进制格式,具有高效、跨语言、向后兼容等优点。
Protobuf 的实现原理基于以下几个核心组件:
- IDL(接口描述语言):使用 .proto 文件定义数据结构,包括消息(Message)、字段(Field)和类型。例如:
syntax = "proto3";message Person {string name = 1;int32 id = 2;bool has_children = 3;
}
-
编译器:protoc 编译器将 .proto 文件编译为特定语言的代码,生成的代码包含序列化和反序列化的实现。
-
标签(Tag)和类型编码:每个字段在序列化时会被分配一个唯一的标签(Tag),用于标识字段。标签和字段类型组合后进行编码,形成数据的头部信息。
-
数据编码:Protobuf 使用变长编码(Varint)来存储整数类型,根据数值大小动态调整占用的字节数,减少空间浪费。字符串和二进制数据使用长度前缀编码。
-
解析器:反序列化时,解析器根据标签和类型信息,从二进制数据中提取字段值,并重构出原始数据结构。
Protobuf 的序列化过程如下:
-
字段编码:将每个字段的标签和类型组合,编码为一个 Varint 值。
-
数据编码:根据字段类型,使用相应的编码方式将字段值转换为二进制数据。例如,整数使用 Varint 编码,字符串使用长度前缀编码。
-
拼接数据:将所有字段的编码结果按顺序拼接成一个二进制流。
反序列化过程则是序列化的逆过程:
-
解析头部:从二进制流中读取每个字段的标签和类型信息。
-
解析值:根据标签和类型信息,从二进制流中读取并解码字段值。
-
重构对象:将解析出的字段值填充到对象中,重构出原始数据结构。
Protobuf 的优点包括:高效(序列化后数据体积小、解析速度快)、跨语言支持、向后兼容(可以在不破坏现有数据的情况下添加或删除字段)。缺点是需要预先定义数据结构,不够灵活,不适合动态数据类型。
自定义序列化方案的设计思路与关键考虑因素
在某些场景下,标准的序列化方案可能无法满足需求,需要设计自定义的序列化方案。设计自定义序列化方案时,需要考虑以下关键因素:
-
数据格式选择:决定使用二进制格式、文本格式(如 JSON、XML)还是混合格式。二进制格式通常更高效,但可读性差;文本格式可读性好,但体积较大。
-
类型系统:确定如何表示数据类型,包括基本类型(如整数、浮点数、字符串)和复杂类型(如数组、对象、集合)。需要考虑类型信息是否需要显式存储,以及如何处理类型的继承和多态。
-
编码方式:选择合适的编码方式来表示数据。例如,整数可以使用定长编码或变长编码(如 Varint);字符串可以使用长度前缀编码或终止符编码。
-
版本控制:设计方案时需要考虑向后兼容和向前兼容的问题,以便在数据结构发生变化时能够正确解析旧版本或新版本的数据。
-
性能优化:考虑序列化和反序列化的性能,包括时间复杂度和空间复杂度。可以通过减少不必要的元数据、使用高效的编码方式等方法提高性能。
-
安全性:确保序列化方案不会引入安全漏洞,如反序列化漏洞(Deserialization Vulnerability)。避免在反序列化过程中执行任意代码。
-
扩展性:设计方案应具有良好的扩展性,能够方便地添加新的数据类型或特性。
-
跨平台支持:如果需要在不同平台或语言之间交换数据,需要确保序列化方案具有良好的跨平台支持。
-
错误处理:定义如何处理序列化和反序列化过程中的错误,如数据损坏、类型不匹配等。
-
工具支持:考虑是否需要开发相应的工具来辅助序列化和反序列化,如代码生成工具、调试工具等。
设计自定义序列化方案的一个示例流程:
-
定义数据模型:确定需要序列化的数据结构,包括基本类型和复杂类型。
-
设计编码规则:为每种数据类型定义编码规则,例如:
- 整数:使用 Varint 编码
- 字符串:使用长度前缀编码
- 对象:按字段顺序序列化每个字段
-
实现序列化逻辑:编写代码将数据对象转换为字节流。
-
实现反序列化逻辑:编写代码将字节流转换回数据对象。
-
添加版本控制:在序列化数据中添加版本信息,以便处理数据结构的变化。
-
测试和优化:对序列化方案进行全面测试,确保其正确性和性能。
自定义序列化方案的优点是可以根据具体需求进行优化,提供更高的性能和更好的灵活性。缺点是开发和维护成本较高,需要自己处理各种复杂问题。
查看系统端口占用情况的常用命令
在系统管理和网络故障排查中,查看端口占用情况是一项常见任务。不同操作系统提供了不同的命令来查看端口占用情况。
Linux 系统
-
netstat:经典的网络状态查看工具,可以显示网络连接、路由表和网络接口等信息。常用选项:
-t:显示 TCP 连接-u:显示 UDP 连接-l:显示监听状态的连接-p:显示进程信息-n:以数字形式显示地址和端口
示例:查看所有监听的 TCP 端口及其对应的进程
netstat -tulpn -
ss:新一代的网络状态查看工具,比 netstat 更高效,支持更多的选项。常用选项:
-t:显示 TCP 连接-u:显示 UDP 连接-l:显示监听状态的连接-p:显示进程信息-n:以数字形式显示地址和端口
示例:查看所有监听的 TCP 端口及其对应的进程
ss -tulpn -
lsof:列出打开文件(包括网络套接字)的工具,可以显示哪些进程正在使用哪些端口。常用选项:
-i:显示网络连接-P:不将端口号转换为服务名称-n:不将 IP 地址转换为域名
示例:查看占用 8080 端口的进程
lsof -i :8080 -
fuser:显示使用指定文件或套接字的进程。常用选项:
-n tcp:指定 TCP 协议-n udp:指定 UDP 协议
示例:查看占用 8080 端口的进程
fuser 8080/tcp
Windows 系统
-
netstat:Windows 系统也提供了 netstat 命令,用法与 Linux 类似。常用选项:
-a:显示所有连接和监听端口-n:以数字形式显示地址和端口-o:显示进程 ID
示例:查看所有监听的端口及其对应的进程 ID
batch
netstat -ano -
tasklist:结合 netstat 命令,可以查看具体的进程名称。示例:
batch
tasklist | findstr "PID" -
PowerShell:PowerShell 提供了更强大的网络管理命令。示例:
powershell
Get-NetTCPConnection | Where-Object {$_.State -eq "Listen"}
macOS 系统
macOS 基于 BSD Unix,使用的命令与 Linux 类似:
- netstat:与 Linux 用法相同。
- lsof:与 Linux 用法相同。
示例:查看占用 8080 端口的进程
lsof -i :8080
查看磁盘空间使用情况的常用命令
在系统管理和性能优化中,查看磁盘空间使用情况是一项基本任务。不同操作系统提供了不同的命令来查看磁盘空间使用情况。
Linux 系统
-
df:显示文件系统磁盘空间使用情况。常用选项:
-h:以人类可读的格式显示(如 KB、MB、GB)-T:显示文件系统类型-a:显示所有文件系统,包括虚拟文件系统-i:显示 inode 使用情况
示例:以人类可读的格式显示所有挂载的文件系统
df -hT -
du:估计文件空间使用情况,通常用于查看目录大小。常用选项:
-h:以人类可读的格式显示-s:只显示总计-c:显示总计和每个子目录的大小-d N:显示到第 N 层子目录的大小
示例:查看当前目录下每个子目录的大小
du -sh * -
ncdu:交互式的磁盘使用分析工具,可以直观地查看目录和文件的大小。如果系统未安装,可以使用包管理器安装。
示例:启动 ncdu 分析当前目录
ncdu -
lsblk:列出块设备信息,包括磁盘和分区。常用选项:
-f:显示文件系统信息-h:以人类可读的格式显示大小-p:显示完整的设备路径
示例:显示所有磁盘和分区信息
lsblk -f
Windows 系统
-
文件资源管理器:通过图形界面查看磁盘空间使用情况,右键点击磁盘驱动器,选择"属性"。
-
PowerShell:使用 PowerShell 命令查看磁盘空间。示例:
powershell
Get-PSDrive -PSProvider FileSystem -
wmic:Windows 管理规范命令行工具。示例:
batch
wmic logicaldisk get caption, freespace, size
macOS 系统
-
磁盘工具:通过图形界面查看磁盘空间使用情况,打开"应用程序"→"实用工具"→"磁盘工具"。
-
df:与 Linux 用法相同。示例:
df -h -
du:与 Linux 用法相同。示例:
du -sh *
信号量在并发编程中的作用与使用方法
信号量(Semaphore)是一种在并发编程中用于控制对共享资源访问的同步原语,由荷兰计算机科学家 Edsger Dijkstra 于 1965 年提出。信号量通过一个计数器来控制对共享资源的访问,允许指定数量的线程同时访问资源。
信号量的核心思想是维护一个计数器,该计数器表示可用资源的数量。线程在访问共享资源之前必须先获取信号量,如果计数器大于 0,则允许访问,计数器减 1;如果计数器为 0,则线程被阻塞,直到有其他线程释放信号量。释放信号量时,计数器加 1,如果有等待的线程,则唤醒其中一个。
信号量的分类:
-
二进制信号量:计数器只能取 0 和 1,相当于互斥锁(Mutex),用于实现互斥访问。
-
计数信号量:计数器可以取任意非负整数值,用于控制对有限资源的访问,允许多个线程同时访问资源。
信号量的操作:
-
P 操作(Proberen,荷兰语,意为"尝试"):也称为 wait() 或 acquire(),用于获取信号量。如果计数器大于 0,则计数器减 1 并继续执行;否则线程被阻塞。
-
V 操作(Verhogen,荷兰语,意为"增加"):也称为 signal() 或 release(),用于释放信号量。计数器加 1,如果有等待的线程,则唤醒其中一个。
信号量在并发编程中的作用:
-
资源限制:控制对有限资源的访问,例如数据库连接池、线程池等。
-
生产者-消费者问题:协调生产者和消费者线程的工作,确保缓冲区不会溢出或空。
-
读写锁实现:通过信号量实现读写锁,允许多个读者同时访问资源,但写者需要独占访问。
-
死锁避免:通过合理设计信号量的获取顺序,避免死锁的发生。
信号量的使用方法示例(C++):
#include <iostream>
#include <thread>
#include <vector>
#include <semaphore.h>// 定义一个信号量,初始值为 3,表示允许 3 个线程同时访问资源
sem_t resource_semaphore;// 共享资源
void shared_resource_access(int thread_id) {// 获取信号量sem_wait(&resource_semaphore);std::cout << "Thread " << thread_id << " is accessing the shared resource." << std::endl;// 模拟资源访问std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Thread " << thread_id << " has finished accessing the shared resource." << std::endl;// 释放信号量sem_post(&resource_semaphore);
}int main() {// 初始化信号量,初始值为 3sem_init(&resource_semaphore, 0, 3);// 创建 5 个线程std::vector<std::thread> threads;for (int i = 0; i < 5; ++i) {threads.emplace_back(shared_resource_access, i);}// 等待所有线程完成for (auto& t : threads) {t.join();}// 销毁信号量sem_destroy(&resource_semaphore);return 0;
}
在这个示例中,我们使用信号量控制对共享资源的访问,允许最多 3 个线程同时访问。当有 4 个或更多线程尝试访问时,多余的线程会被阻塞,直到有线程释放信号量。
信号量的优点是实现简单,功能强大,可以解决多种并发编程问题。缺点是如果使用不当,可能会导致死锁或活锁等问题。在实际应用中,需要根据具体场景合理设计信号量的初始值和操作顺序。
协程的概念及其在内存管理中的应用场景
协程是一种轻量级的线程,也被称为用户级线程或纤程。与传统线程相比,协程的调度由用户程序控制,而非操作系统内核,因此切换开销更小。协程允许在执行过程中暂停并保存当前状态,稍后再从暂停点恢复执行,这种特性使得协程特别适合处理异步操作和高并发场景。
在内存管理方面,协程的应用场景包括:
-
减少内存碎片:协程的栈空间通常比线程小得多,且可以按需分配,因此可以减少内存碎片。例如,在高并发服务器中,每个请求使用一个协程处理,而不是一个线程,可显著降低内存消耗。
-
高效内存池管理:协程可以与内存池结合使用,实现高效的内存分配和回收。当协程需要内存时,从内存池获取;协程结束时,将内存返回给池,避免频繁的系统调用。
-
异步内存操作:在处理大文件或网络数据时,内存分配和数据传输可能是耗时操作。协程可以在等待这些操作完成时暂停,让出执行权,提高整体效率。
-
延迟释放资源:协程可以实现资源的延迟释放,例如在对象不再使用时,不立即释放内存,而是将释放操作放入协程队列,在系统负载较低时执行。
-
内存预分配策略:对于已知内存需求模式的应用,可以使用协程预先分配内存,避免在关键路径上进行动态内存分配。
以下是一个协程与内存池结合的示例代码:
#include <iostream>
#include <memory>
#include <vector>
#include <coroutine>
#include <queue>// 简单的内存池实现
template<typename T>
class MemoryPool {
private:std::queue<T*> free_list;size_t chunk_size;public:MemoryPool(size_t chunk_size = 100) : chunk_size(chunk_size) {}T* allocate() {if (free_list.empty()) {// 批量分配内存T* chunk = static_cast<T*>(operator new(chunk_size * sizeof(T)));for (size_t i = 0; i < chunk_size; ++i) {free_list.push(&chunk[i]);}}T* ptr = free_list.front();free_list.pop();return ptr;}void deallocate(T* ptr) {free_list.push(ptr);}~MemoryPool() {// 释放所有内存while (!free_list.empty()) {T* ptr = free_list.front();free_list.pop();operator delete(ptr);}}
};// 协程任务类型
struct Task {struct promise_type {Task get_return_object() { return {}; }std::suspend_never initial_suspend() { return {}; }std::suspend_never final_suspend() noexcept { return {}; }void return_void() {}void unhandled_exception() {}};
};// 使用协程和内存池处理任务
Task process_request(MemoryPool<int>& pool) {// 从内存池分配内存int* data = pool.allocate();*data = 42;// 模拟耗时操作co_await std::suspend_always{};// 使用完后归还内存pool.deallocate(data);
}int main() {MemoryPool<int> pool;process_request(pool);return 0;
}
在这个示例中,MemoryPool 类实现了一个简单的内存池,用于管理 int 类型对象的分配和回收。process_request 函数是一个协程,它从内存池获取内存,处理数据,然后在协程结束时归还内存。这种方式避免了频繁的内存分配和释放操作,提高了性能。
unordered_map 的底层哈希表结构、扩容机制及线程安全问题
unordered_map 是 C++ 标准库中的关联容器,它使用哈希表实现,提供平均常数时间复杂度的插入、删除和查找操作。
底层哈希表结构
unordered_map 的底层通常采用链地址法(Separate Chaining)解决哈希冲突。具体结构如下:
-
哈希桶数组:unordered_map 维护一个数组,每个元素称为一个桶(Bucket),桶中存储哈希值相同的元素。
-
链表或红黑树:每个桶中可以存储多个元素,形成一个链表(或在元素数量较多时转换为红黑树,如 GCC 的实现)。当发生哈希冲突时,新元素会被添加到对应桶的链表或树中。
-
哈希函数:用于将键映射到桶的索引位置。理想情况下,哈希函数应均匀分布键,减少冲突。
-
负载因子:定义为元素数量与桶数量的比值。当负载因子超过某个阈值时,哈希表会进行扩容。
扩容机制
当哈希表的负载因子超过预设阈值(通常为 1.0)时,unordered_map 会进行扩容操作:
-
创建更大的数组:通常新数组的大小是原数组的两倍左右(具体取决于实现)。
-
重新哈希:将所有元素从旧数组迁移到新数组,每个元素根据新的哈希函数和数组大小重新计算桶索引。
-
更新元数据:更新哈希表的桶数量和负载因子。
扩容操作的时间复杂度为 O (n),其中 n 是元素数量。为了减少扩容带来的性能开销,unordered_map 通常会预留一定的空间,避免频繁扩容。
线程安全问题
unordered_map 本身不是线程安全的,在多线程环境下使用时需要注意以下问题:
-
并发修改:如果多个线程同时修改 unordered_map(插入、删除元素),会导致数据竞争和未定义行为。
-
迭代器失效:在扩容过程中,所有迭代器都会失效,因此在多线程环境下使用迭代器需要特别小心。
-
读写冲突:即使只有一个线程修改 unordered_map,其他线程同时读取也可能看到不一致的数据。
为了在多线程环境下安全使用 unordered_map,可以采取以下措施:
-
外部同步:使用互斥锁(如 std::mutex)保护 unordered_map 的访问。
-
使用线程安全容器:如果需要高并发性能,可以考虑使用专门的线程安全哈希表实现,如 TBB 的 concurrent_unordered_map。
-
读写分离:对于读多写少的场景,可以使用读写锁(如 std::shared_mutex)提高并发度。
以下是一个使用互斥锁保护 unordered_map 的示例:
#include <unordered_map>
#include <mutex>
#include <string>class ThreadSafeMap {
private:std::unordered_map<std::string, int> map;mutable std::mutex mutex;public:void insert(const std::string& key, int value) {std::lock_guard<std::mutex> lock(mutex);map[key] = value;}int get(const std::string& key) const {std::lock_guard<std::mutex> lock(mutex);auto it = map.find(key);if (it != map.end()) {return it->second;}return -1;}
};
在这个示例中,ThreadSafeMap 类封装了一个 unordered_map,并使用互斥锁保护对它的访问。insert 和 get 方法都通过锁来确保线程安全。
map 与 unordered_map 的性能对比及适用场景
map 和 unordered_map 是 C++ 标准库中两种常用的关联容器,它们都用于存储键值对,但底层实现和性能特点不同。
性能对比
-
插入操作:
- map:基于红黑树,插入操作的时间复杂度为 O (log n),需要维护树的平衡。
- unordered_map:基于哈希表,平均插入时间复杂度为 O (1),但在哈希冲突或扩容时性能可能下降。
-
查找操作:
- map:时间复杂度为 O (log n),需要从根节点开始比较。
- unordered_map:平均时间复杂度为 O (1),但在哈希冲突严重时可能退化为 O (n)。
-
删除操作:
- map:时间复杂度为 O (log n),需要调整树的结构。
- unordered_map:平均时间复杂度为 O (1),但可能需要处理链表或树的调整。
-
内存占用:
- map:每个节点需要额外存储父节点、左右子节点指针,内存占用较高。
- unordered_map:需要维护哈希表数组和链表 / 树结构,在负载因子较小时可能占用更多内存,但在元素分布均匀时内存利用率更高。
-
遍历效率:
- map:元素按键有序排列,中序遍历效率高。
- unordered_map:元素无序,遍历效率取决于哈希表的实现和负载因子。
适用场景
-
需要有序遍历:如果应用需要按键的顺序遍历元素,应选择 map。例如,实现字典、排行榜等功能。
-
对插入删除敏感:如果应用需要频繁插入和删除元素,且对单次操作的最坏时间复杂度有要求,map 可能更合适,因为它的操作时间复杂度稳定为 O (log n)。
-
需要高效查找:如果应用主要是进行查找操作,且元素数量较大,unordered_map 的平均 O (1) 时间复杂度通常更具优势。例如,缓存系统、数据库索引等。
-
键类型特性:如果键类型没有定义比较运算符(如自定义类),但可以定义哈希函数,则只能使用 unordered_map。反之,如果键类型没有定义哈希函数,但有比较运算符,则只能使用 map。
-
内存限制:在内存有限的情况下,如果元素分布均匀,unordered_map 可能更节省内存;但如果哈希冲突严重,可能导致内存碎片增加。
以下是一个对比 map 和 unordered_map 性能的示例代码:
#include <iostream>
#include <map>
#include <unordered_map>
#include <string>
#include <chrono>int main() {const int SIZE = 1000000;// 测试 map 插入性能auto start = std::chrono::high_resolution_clock::now();std::map<int, std::string> ordered_map;for (int i = 0; i < SIZE; ++i) {ordered_map[i] = "value";}auto end = std::chrono::high_resolution_clock::now();std::cout << "map insert time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()<< " ms" << std::endl;// 测试 unordered_map 插入性能start = std::chrono::high_resolution_clock::now();std::unordered_map<int, std::string> unordered_map;for (int i = 0; i < SIZE; ++i) {unordered_map[i] = "value";}end = std::chrono::high_resolution_clock::now();std::cout << "unordered_map insert time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()<< " ms" << std::endl;// 测试 map 查找性能start = std::chrono::high_resolution_clock::now();for (int i = 0; i < SIZE; ++i) {auto it = ordered_map.find(i);}end = std::chrono::high_resolution_clock::now();std::cout << "map find time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()<< " ms" << std::endl;// 测试 unordered_map 查找性能start = std::chrono::high_resolution_clock::now();for (int i = 0; i < SIZE; ++i) {auto it = unordered_map.find(i);}end = std::chrono::high_resolution_clock::now();std::cout << "unordered_map find time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()<< " ms" << std::endl;return 0;
}
在这个示例中,我们测试了 map 和 unordered_map 的插入和查找性能。通常情况下,unordered_map 在插入和查找操作上会比 map 快得多,但具体性能还取决于硬件环境、编译器优化以及元素分布情况。