作者:蔡文睿(清素)、汪诚愚(熊兮)、严俊冰(玖烛)、黄俊(临在)
前言
近年来,自然语言处理(NLP)领域以大语言模型(LLM)的出现为标志,发生了深刻变革,引领了语言理解、生成和推理任务的进步。其中,进步尤其显著的是深度推理模型的发展,如 OpenAI 的 o1、DeepSeek-R1 和 QwQ-32B 等,它们在数学问题、代码生成等复杂推理任务中表现突出。这些模型的成功很大程度上得益于使用思维链(Chain-of-Thought, CoT)的推理方式,能够模拟人类的渐进思考过程,将复杂问题化繁为简。然而,对于不同的推理任务,使用长思考的推理模式并不能提升模型在所有推理任务上的精度,反而容易引发“过度思考”的问题,既降低了模型响应速度,又导致推理过程中频繁出错。
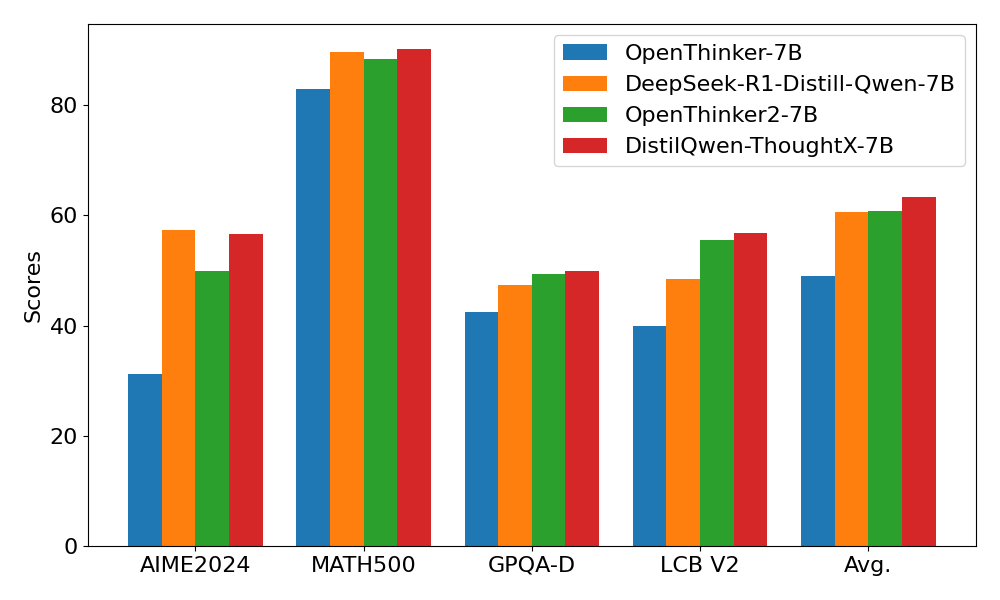
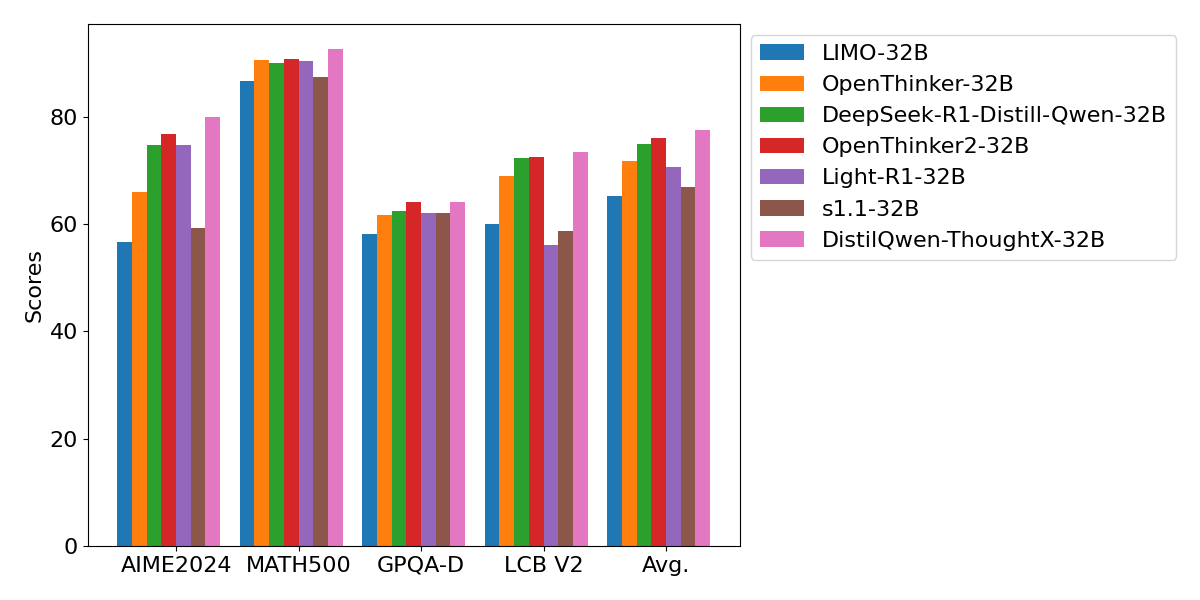
为了解决这一问题,阿里云人工智能平台PAI团队对于思维链的特性,提出了推理冗余度(Reasoning Verbosity, RV)和认知难度(Cognitive Difficulty, CD)分数两种度量方式,并且构建了包括200万思维链的数据集 OmniThought ,对于 OmniThought 的每个思维链都进行了标注。基于 RV 和 CD 分数,我们可以根据不同的任务和模型底座要求,训练根据任务进行自适应的变长思维链推理模型。因此,基于这一新提出的 OmniThought 数据集,我们训练并发布了一系列具有更强推理能力、具备最佳思维链长度和难度水平的模型(DistilQwen-ThoughtX系列),这些模型的性能甚至超越借助专有数据集训练的 DeepSeek-R1-Distill 系列。具体效果的比较见下图。
|
|
|
|
为了便于社区用户使用 DistilQwen-ThoughtX 系列模型,以及蒸馏适合自身场景的推理模型,我们在 EasyDistill(GitHub - modelscope/easydistill: a toolkit on knowledge distillation for large language models)的框架中开源了 OmniThought 的全部数据,以及所有 DistilQwen-ThoughtX 系列模型的权重。在下文中,我们将介绍 OmniThought 数据集的构建流程和 DistilQwen-ThoughtX 系列模型的效果。
OmniThought数据集构建
OmniThought 数据集的构建框架如下所示:
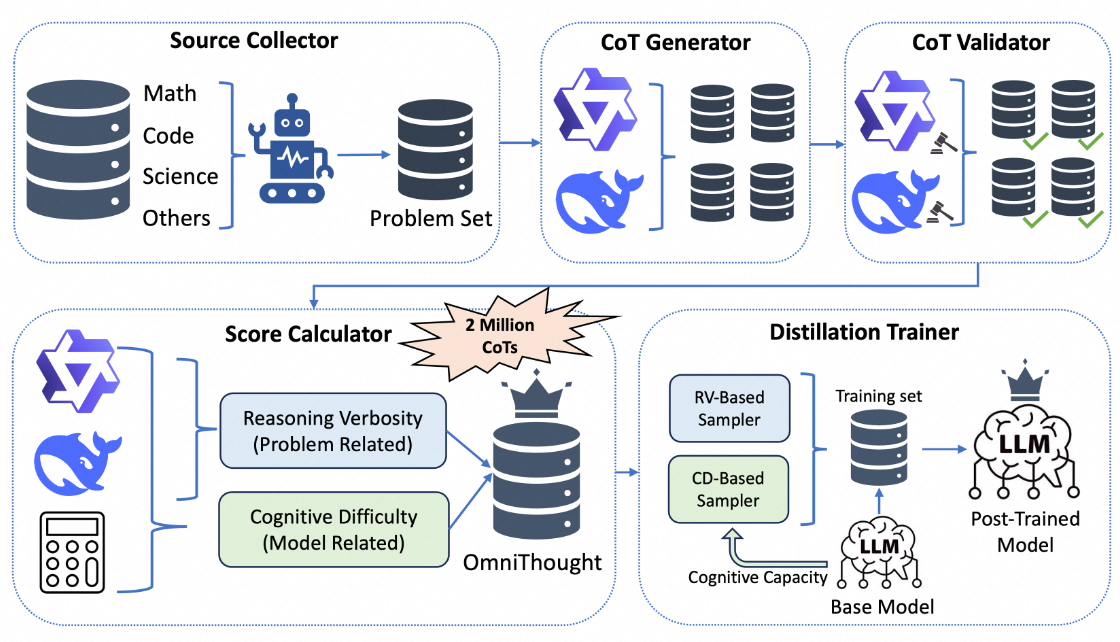
基础数据搜集和正确性验证
首先,由于开源社区中存在许多高质量的推理问题集,OmniThought 采用了 OpenThoughts2-1M 和 DeepMath-103K 两个数据集作为数据源。其中,OpenThoughts2-1M 包含约64万个跨数学、编码、科学及谜题等多个领域的推理问题,而 DeepMath-103K 则包括10.3万道难度不一的数学问题。
接下来,我们使用 DeepSeek-R1 和 QwQ-32B 作为教师模型,为问题集合生成多个思维链推理过程。为了确保生成的思维链过程的高质量,我们进一步采用“LLM-as-a-judge”方法,对生成的思维链进行多个方面的验证,其中包括逻辑正确性及推导出正确答案的能力,模版如下所示:
You are a rigorous logical validator analyzing problem-solving components.
Your task is to separately assess the validity of the reasoning process and final solution.
Given a problem, the correct answer, a candidate reasoning process, and a candidate solution, you will:For SOLUTION VALIDITY: Directly comparing it to the correct answer.For REASONING PROCESS VALIDATION: a. Verify stepwise logical coherence and soundnessb. Confirm all critical problem constraints are properly addressedc. Check for self-contradictions or unsupported leaps in logicd. Verify the process can actually derive the proposed solutionEvaluation Protocol:
- Solution validity MUST be FALSE for any numerical mismatch or missing units
- Reasoning process validity requires ALL validation criteria (a-d) satisfied
- Both assessments must be independent: correct answer with flawed reasoning gets (False, True)
- Return STRICT BOOLEAN assessments for both componentsProblem: {problem}
Correct Answer: {answer}
Candidate Reasoning Process: {reasoning process}
Proposed Solution: {solution}Output Format: reasoning_valid: bool, solution_valid: bool 由于 OpenThoughts2-1M 和 DeepMath-103K 数据集已包含部分来自 DeepSeek-R1 的思维链,我们同样验证了这些思维链的正确性,并将验证结果作为元数据添加。最终,OmniThought 数据集包含超过200万思维链,对应于70.8万道推理问题。我们确保数据集中的每个问题至少拥有两个经过验证的正确思维链。
推理冗余度(Reasoning Verbosity)
思维链本质上涉及自我反思,促使模型在推理过程中进行多轮反思和修正。这种机制在模型处理复杂问题时有助于降低错误率,却可能导致在简单问题上陷入“过度思考”的情况,例如对“1 + 1 = ?”问题回答进行过度检查。这样的过度思考不仅浪费计算资源,还可能降低推理准确度。因此,对于特定问题,其思维链的长度应与问题的难度相匹配,这反映了思维链的“推理冗余度(Reasoning Verbosity,RV)”,我们对RV分级标准进行了正式定义,采用0到9的评分,具体用于评估RV的模版详见相关论文。
0-1: 最低冗余度,直接输出结果,几乎没有详细说明。
2-3: 较低冗余度,有清晰简洁的推理过程,包含必要的解释。
4-5: 中等冗余度,提供详细解释并进行充分推理。
6-7: 较高冗余度,全面的论证,进行复杂的探索。
8-9: 高冗余度,深入、详尽的推理;涉及详细论述、嵌套论证及考虑反对论点的讨论。为进一步验证 RV 在推理模型训练中的有效性,我们在 OmniThought 随机抽取包含1万个问题的子集,每个问题的三个思维链属于三个不同RV级别。在这个子集内,相邻级别之间的 RV 差异超过3。因此,我们获得了三个训练数据集,包含相同的问题但不同的 RV 分数级别。然后,我们以 Qwen2.5-7B-Instruct 为初始化模型,在每个数据集上进行 SFT 训练,以产生三个模型:短思维链(Short)、中等思维链(Medium)和长思维链(Long),结果如下(其中,蓝色代表在特定任务上的分数,红色折线代表平均输出 token 数):
|
GSM8K |
MATH500 |
AIME24 |
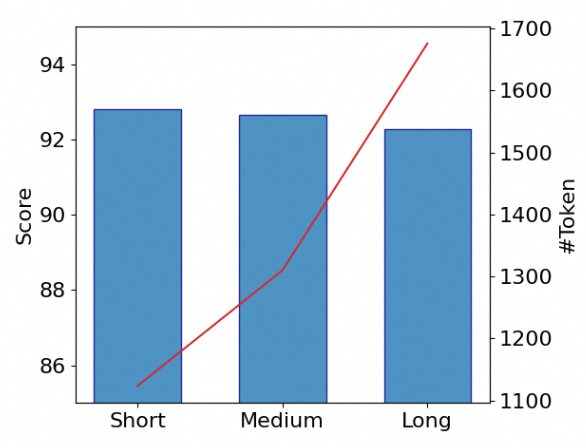
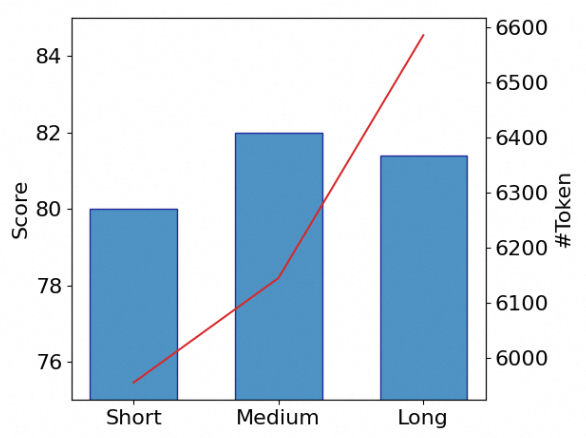
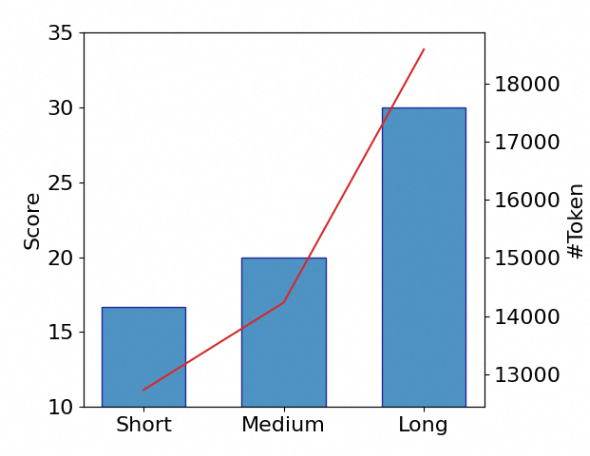
由上图可见,在相对简单的 GSM8K 任务中,所有模型表现出相似的性能;输出 token 的增加没有提高准确性,甚至导致轻微下降。在中等难度的 MATH500 任务上,准确度随着 token 数的增加而提高,随后下降,其中中等模型在产生适量 token 数时达到最高的准确度。在最具挑战的AIME24问题中,长模型获得最高分;模型的准确性随着 token 数的增加而提高。因此,对于难度较大的问题,较长的思维链能够纠正模型自身错误,从而有效提高准确性。然而,在简单任务中,思维链中的过度推理和验证不仅增加了计算资源的消耗,还可能降低问题解决的准确性。所以,我们可以根据任务难度构建具备相应 RV 级别思维链的训练集,从而最大化计算资源利用,同时确保高准确性。
认知难度(Cognitive Difficulty)
在构建合适的思维链训练数据集时,我们认为思维链的难度应与目标模型的认知能力相适应。由于模型参数规模的显著差异,大模型和小模型之间的认知和推理轨迹并不总是一致。小模型在其参数限制下,往往依赖更简单的方式解决问题,而大模型由于具备更高级的认知能力,可能应用更高水平的技术。例如,对于一个计算给定坐标的三角形面积问题,小型模型可能采用简单的几何公式,而大型模型可能使用更复杂的方法,如基于向量的代数求解。
为验证这一假设,我们使用 DeepSeek-R1-Distill 系列的三个模型进行实验:DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B,以及 DeepSeek-R1-Distill-Qwen-32B。我们在 MATH500 数据集上评估这些模型。对于每个模型的思维链过程,我们利用 DeepSeek-R1 根据方法的复杂性和整体推理难度进行0到9的难度评分(评分标准参见下文),结果如下表所示。
| 模型 | 平均评分 |
| DS-R1-Distill-Qwen-1.5B | 4.5 |
| DS-R1-Distill-Qwen-7B | 6.2 |
| DS-R1-Distill-Qwen-32B | 7.3 |
实验结果显示,随着模型参数量的增加,思维链的难度也在上升,这表明较大的模型拥有更强的推理和认知能力。因此,困难的思维链可能不适合训练认知能力较低的模型。因此,使用与模型认知能力一致的思维链来提升其推理能力是至关重要的,这类似于“因材施教”的策略。在我们的工作中,认知难度(Cognitive Difficulty,CD)分数分级标准如下所示,具体用于评估 CD 的模版详见相关论文:
0-1: 小学、入门级知识,或者单一简单思考模式。
2-3: 多步算术,枚举,基于基本规则的推理。
4-5: 初级逻辑/代数知识;非显而易见的推理。
6-7: 使用高级技术(行列式,动态规划,代码推理等)。
8-9: 高度抽象的方法,包括嵌套证明、复杂算法分析等。在 OmniThought 中,我们对所有验证正确的思维链进行评分,CD 分布如图所示:
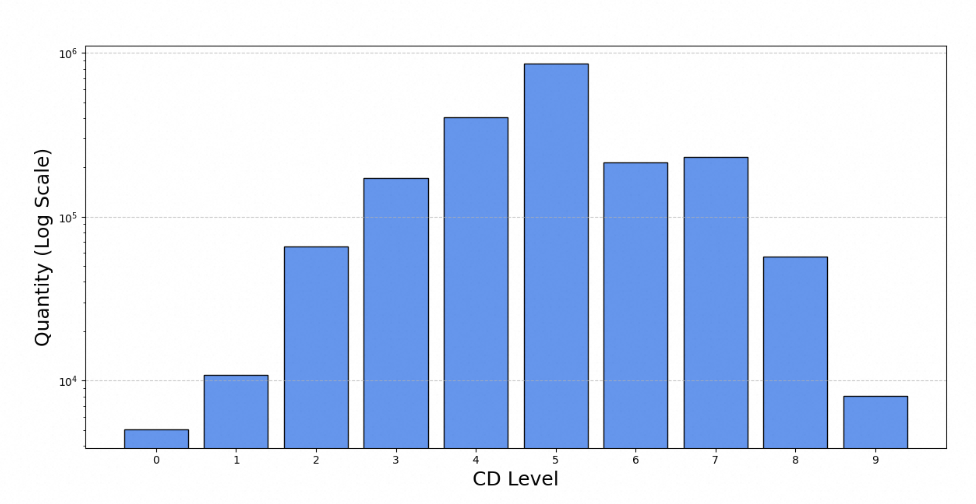
可以观察到,CD 评分峰值在4-5级,并逐渐向两端减少。这一发现也表明,例如 DeepSeek-R1 或 QwQ-32B 的能力较强的推理模型,有不小的可能性生成难度极高的思维链。在进行知识蒸馏时,认知能力有限的模型不太可能有效理解这些过程。因此,给定 OmniThought 集和基础模型,可以根据基础模型的认知能力过滤训练数据集,从而有效提升模型的推理能力。
DistilQwen-ThoughtX:变长思维链推理模型
基于我们提出的 OmniThought 数据集,我们训练了 DistilQwen-ThoughtX 系列模型,由于我们可以通过 RV 和 CD 分数对思维链进行筛选,训练得到的模型获得根据问题和本身的认知能力,生成变长思维链的能力。具体地说,我们设置目标模型的认知能力为 μCD ,即模型一般对于 CD 评分小于等于 μCD 的思维链具有比较好的认知能力。从经验角度,我们 μCD 的选择一般与模型的参数量有关(具体的分析实验参见论文)。对于某推理问题,我们可以根据如下设置采样合适的思维链:
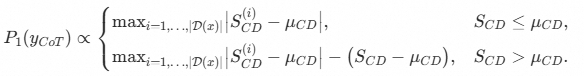
从上面可以看出,我们假设对于 CD 级别小于等于 μCD 的思维链,采样概率都比较大,如果 CD 级别大于 μCD 的思维链,采样概率比较小。这可以保证模型训练数据集中大部分思维链的难度都不会过大,而少部分思维链的难度会偏高,从而能在训练时尽量推高模型推理能力的上限。
对于RV分数,我们有如下采样规则:
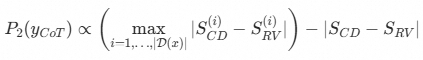
这使得采样得到的思维链的 RV 分数和 CD 分数差别不会太大。显然,对于难度高的思维链,一般都需要比较长的推理长度,模型才能有效理解;反之亦然。同样的,我们也容易看出,如果对于难度低的思维链进行冗长推理,一般对模型推理效果有反作用;如果难度高的思维链进行非常精简的推理,参数规模较小的模型可能无法理解。
基于上述采样方法,对于 OmniThought 中的 708K 个问题,我们抽样出合适的思维链以通过 SFT 训练模型。我们从 Qwen2.5 系列(7B和32B)初始化,训练两个模型,分别命名为 DistilQwen-ThoughtX-7B 和 DistilQwen-ThoughtX-32B。我们将我们的模型与开源社区中的知名蒸馏推理模型进行比较,结果汇总见表格。我们观察到,基于 OmniThought 数据集和我们基于 RV-CD 的思维链选择策略,我们模型效果优异,表现甚至优于 DeepSeek 官方采用闭源数据集蒸馏的模型。其中,DistilQwen-ThoughtX (Full) 指使用全量思维链数据训练的模型,可以看出使用我们提出的评分和筛选方法训练的模型效果有明显提升。
下表展示了 DistilQwen-ThoughtX 的性能表现:
| Model | AIME2024 | MATH500 | GPQA Diamond | LiveCodeBench V2 | Avg. |
| 7B量级 | |||||
| OpenThinker-7B | 31.3 | 83.0 | 42.4 | 39.9 | 49.1 |
| DeepSeek-R1-Distill-Qwen-7B | 57.3 | 89.6 | 47.3 | 48.4 | 60.6 |
| OpenThinker2-7B | 50.0 | 88.4 | 49.3 | 55.6 | 60.8 |
| DistilQwen-ThoughtX-7B (Full) | 43.3 | 88.2 | 45.4 | 45.4 | 55.5 |
| DistilQwen-ThoughtX-7B | 56.7 | 90.2 | 50.0 | 56.8 | 63.4 |
| 32B量级 | |||||
| LIMO-32B | 56.7 | 86.6 | 58.1 | 60.0 | 65.3 |
| OpenThinker-32B | 66.0 | 90.6 | 61.6 | 68.9 | 71.7 |
| DeepSeek-R1-Distill-Qwen-32B | 74.7 | 90.0 | 62.4 | 72.3 | 74.8 |
| OpenThinker2-32B | 76.7 | 90.8 | 64.1 | 72.5 | 76.0 |
| Light-R1-32B | 74.7 | 90.4 | 62.0 | 56.0 | 70.7 |
| s1.1-32B | 59.3 | 87.4 | 62.0 | 58.7 | 66.8 |
| DistilQwen-ThoughtX-32B (Full) | 70.0 | 91.8 | 59.6 | 70.1 | 72.8 |
| DistilQwen-ThoughtX-32B | 80.0 | 92.6 | 64.0 | 73.4 | 77.5 |
开源模型和数据集下载和使用
DistilQwen-ThoughtX 在开源社区的下载
我们在 Hugging Face 和 Model Scope 上开源了我们蒸馏后的模型,分别为 DistilQwen-ThoughtX-7B、DistilQwen-ThoughtX-32B。以 Hugging Face 为例,用户可以使用如下代码下载这两个模型:
from huggingface_hub import snapshot_downloadmodel_name = "alibaba-pai/DistilQwen-ThoughtX-7B"
snapshot_download(repo_id=model_name, cache_dir="./DistilQwen-ThoughtX-7B/")model_name = "alibaba-pai/DistilQwen-ThoughtX-32B"
snapshot_download(repo_id=model_name, cache_dir="./DistilQwen-ThoughtX-32B/")OmniThought 数据集在开源社区的下载
我们在 Hugging Face 和 Model Scope 上开源了我们的数据集 OmniThought。以 Hugging Face 为例,用户可以使用如下代码下载这两个模型:
from datasets import load_datasetOmniThought = load_dataset("alibaba-pai/OmniThought")本文小结
近年来,随着大语言模型的出现,自然语言处理领域发生了重要变革,其中深度推理模型在复杂推理任务中表现尤为突出。然而,长思维链推理可能导致“过度思考”,影响模型性能。为解决此问题,阿里云 PAI 团队开发了 OmniThought 数据集,其中包含200万思维链,并标注了推理冗余度(RV)和认知难度(CD)分数。这使得模型能够根据任务自适应选择思维链长度,从而提升其推理能力。基于此数据集,我们推出了 DistilQwen-ThoughtX 系列模型,这些模型在性能上超过了 DeepSeek-R1-Distill 系列。为了支持社区用户使用及优化这些模型,我们在 EasyDistill 框架中开源了 OmniThought 数据集和 DistilQwen-ThoughtX 模型的全部权重。在未来,我们将进一步基于 EasyDistill 框架开源更多 DistilQwen 模型系列和相应资源。欢迎大家加入我们,一起交流大模型蒸馏技术!
参考工作
本文对应论文
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations. arXiv preprint
DistilQwen 系列相关论文
- Chengyu Wang, Junbing Yan, Wenrui Cai, Yuanhao Yue, Jun Huang. EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models. arXiv preprint
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Training Small Reasoning LLMs with Cognitive Preference Alignment. arXiv preprint
- Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang. DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models. ACL 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024
DistilQwen 系列技术介绍
- DistilQwen2:通义千问大模型的知识蒸馏实践
- DistilQwen2.5发布:通义千问蒸馏小模型再升级
- DistilQwen2.5-R1发布:知识蒸馏助推小模型深度思考
- 人工智能平台 PAI DistilQwen2.5-DS3-0324发布:知识蒸馏+快思考=更高效解决推理难题
- 基于多轮课程学习的大语言模型蒸馏算法TAPIR
欢迎大家在评论区留言互动!