锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

pivot_table() 是 pandas 中最强大的数据透视工具,它不仅能重塑数据,还能进行复杂的数据聚合分析。与简单的 pivot() 不同,pivot_table() 可以处理重复值并执行多种聚合计算,是数据分析师的核心工具之一。
基本语法
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, margins_name='All', dropna=True, observed=False)参数详解
| 参数 | 说明 | 默认值 |
|---|---|---|
| data | 输入的 DataFrame | 必填 |
| values | 要聚合的数值列 | None |
| index | 行分组键(可以是单个列或多个列) | None |
| columns | 列分组键(可以是单个列或多个列) | None |
| aggfunc | 聚合函数(mean, sum, count 等) | 'mean' |
| fill_value | 用于替换缺失值的值 | None |
| margins | 是否添加总计行/列 | False |
| margins_name | 总计行/列的名称 | 'All' |
| dropna | 是否删除全为 NaN 的列 | True |
| observed | 是否仅显示分类中的观察值 | False |
示例一,基本透视表
import pandas as pd
import numpy as np
# 创建销售数据
data = {'Region': ['East', 'East', 'West', 'West', 'North', 'North', 'East', 'West'],'Product': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A'],'Sales': [12000, 15000, 18000, 14000, 9000, 11000, 13000, 16000],'Month': ['Jan', 'Jan', 'Jan', 'Jan', 'Jan', 'Jan', 'Feb', 'Feb']
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)创建基本透视表:
# 按区域和产品计算平均销售额
pivot_avg = pd.pivot_table(df, values='Sales', index='Region', columns='Product', aggfunc='mean')
print("\n区域-产品平均销售额透视表:")
print(pivot_avg)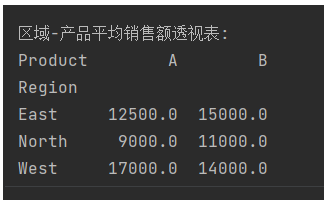
示例二,多维度透视表
# 添加月份维度
pivot_multi = pd.pivot_table(df, values='Sales', index=['Region', 'Product'], columns='Month', aggfunc='sum')
print("\n区域-产品-月度销售额透视表:")
print(pivot_multi)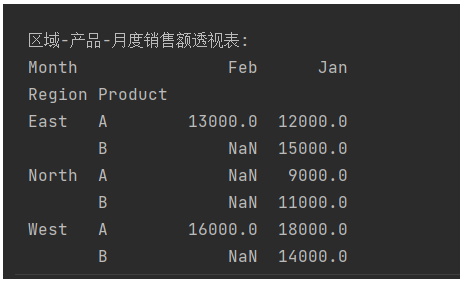






![[AD] Reaper NBNS+LLMNR+Logon 4624+Logon ID](https://i-blog.csdnimg.cn/img_convert/f637a972eb11fa5b163f1a2fdfd5f98a.jpeg)