每天输验证码耗掉50万小时 复杂验证码难倒人类
人类发明的验证码原本是为了防止AI滥用,但如今这些验证码变得如此复杂,以至于连人类自己都难以应对。陈祥在商场停车场付费准备离开时,遇到了一个让他几乎崩溃的验证码:画面中的文字歪歪扭扭,辨认起来非常费劲,再加上后面车辆的催促,让他更加焦虑。
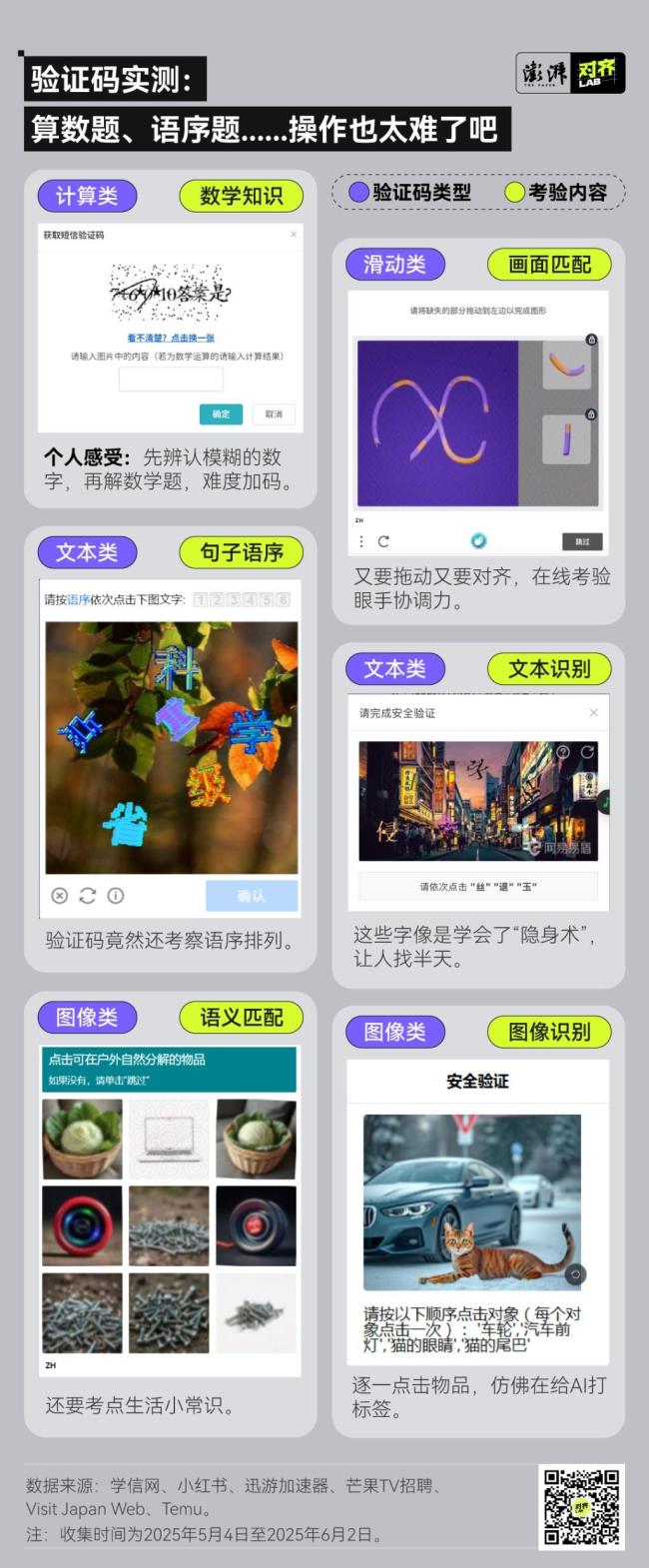
这种情况并非个例。一位网友表示:“每次评论都要验证一次,我真的受够了。”另一位网友则调侃道:“这个验证码设计得好像生怕有人能点对。”
我们测试了各大网站和APP,发现现在的验证码越来越复杂,考验的内容也五花八门。早在2010年,斯坦福大学的一项研究显示,普通用户平均需要9.8秒才能解决一个图像验证码,而语音验证码则需要28.4秒。到了2024年,一项关于用户对验证码感知的研究表明,在近150位被调查者中,只有35%的人总能一次性通过验证码,而46%的人会在多次失败后放弃使用网站。

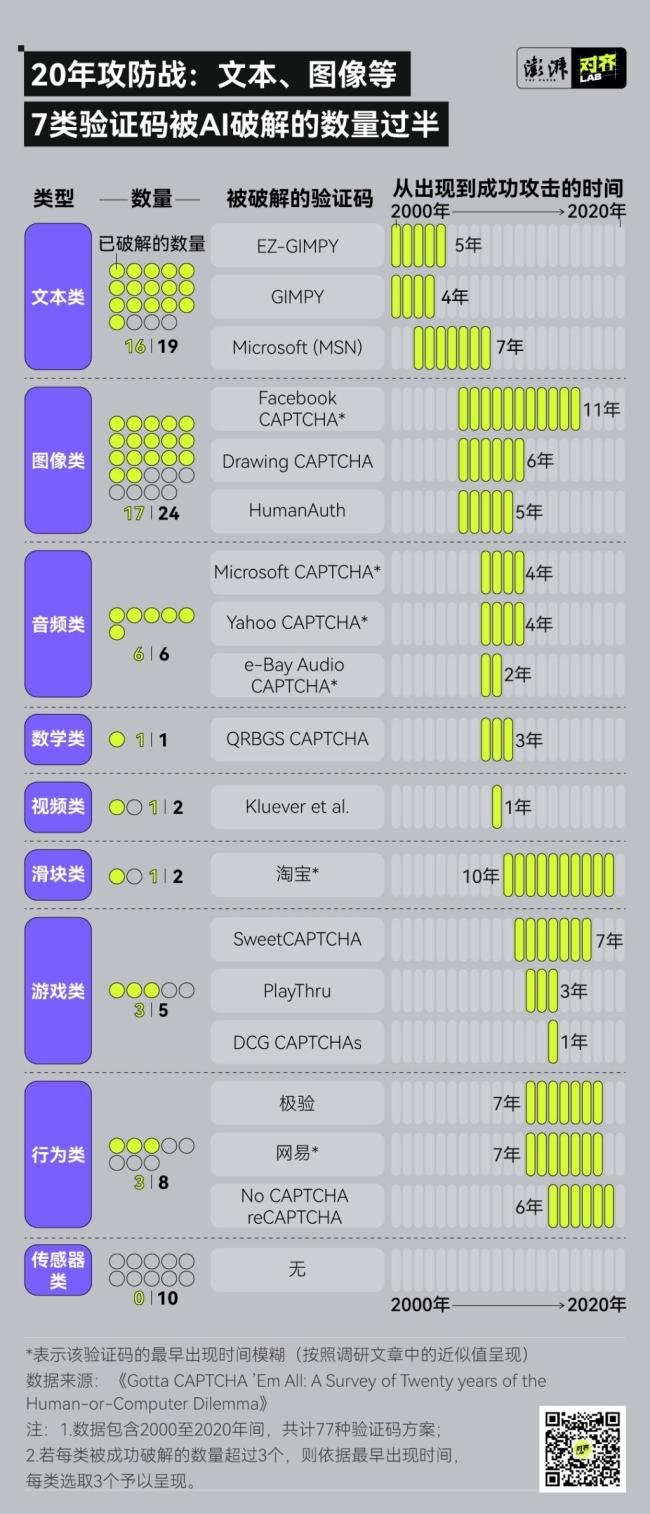
验证码为何越来越复杂?主要是因为绝大多数验证码都能被AI破解。验证码的设计初衷是基于一个人工智能问题,由多邻国创始人路易斯·冯·安及其团队在2000年为帮助雅虎抵御垃圾邮件攻击而设计。他们通过扭曲字符来区分人类与机器,这就是验证码的雏形。

然而,从扭曲字符到点击图像,从简单算术题到滑块拼图,再到近几年的行为验证,无论验证码如何变化,几乎都没扛过几年就被破解了。2023年的一项研究表明,无论是文本验证码、图像识别、点击任务还是滑动拼图,AI在破解速度和准确率上都全面碾压人类。例如,在处理文本类验证码时,人类耗时15.3秒,最高正确率为84%;而机器人仅需0.9秒,最高正确率便达99.8%。
面对这一挑战,部分验证码开始采用“AI对抗AI”的逻辑进行技术升级,另一些则转变底层逻辑,从过去的“看你有几分像机器”转向“看你有几分像人”。例如,Google于2018年推出的reCAPTCHA V3无需用户接受测试或主动操作,而是通过用户上网行为数据来判断访问者是否为人类。虽然验证码变得更加友好,但用户也不得不让渡个人数据。
验证码不仅用于安全防护,还在无形中训练了AI。路易斯·冯·安曾计算,全体人类每天约耗费50万小时输入验证码,而一个人80岁的人生总时长不过70万小时。为了使这些时间变得有价值,他在2007年创建了reCAPTCHA,利用验证码形式弥补光学字符识别(OCR)技术缺陷,并助力《纽约时报》完成了自1851年以来1300万篇文章的数字化。
2009年,谷歌以大约2780万美元收购了reCAPTCHA,支持其图书和新闻档案搜索等大型文本扫描项目。此后,谷歌进一步拓展技术应用场景,依托街景图像资源让用户识别门牌号等信息,相关数据也被用于训练Waymo自动驾驶技术等AI模型。
据研究人员估算,在2009年后的13年里,用户在输入谷歌验证码上共计消耗了8.19亿小时,按美国联邦最低工资7.5美元/时计算,这相当于谷歌省下了至少61亿美元的工资。此外,还有一些公司和研究机构公开了带有人工标注的验证码图像数据集,供开发者和研究人员训练、测试AI模型。
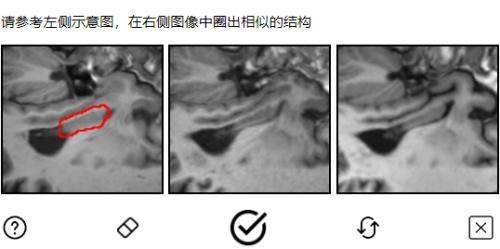
国内也有类似案例,如腾讯与深圳大学联合推出的“MedCAPTCHA医学图像验证码”,通过验证码形式将临床上真实的脱敏医学图像开放给公众标注,推动AI在医疗领域的应用发展。
20年前,路易斯·冯·安认为,验证码与AI的发展是一种“双赢”局面:如果验证码未被攻破,则有效保障了网站安全;反之,则意味着人工智能取得了进步。然而,如今在这场人与机器的博弈中,人的意愿在哪里体现?这真的是一举多得的好事吗?
相关文章

伊媒:哈梅内伊政治顾问“还活着” 伤情趋于稳定

多所高校已明确:不招复读生,引发热议

多人骑摩托在高速路飙车被抓 最高速度达304km/h

6月24日至26日,北京这些路段禁止通行 亚投行年会交通管制

9.9元和20元椰子水差在哪 配料与工艺揭秘

38岁抗癌博主离世 生前称不当网红 与病魔斗争9年终解脱

余承东给开发者体验Pura80 鸿蒙生态共创新天地

Labubu遭黄牛外挂血洗:30倍暴利下的法律困局

妻子怀孕后,北京男子买迷药被判八个月不服:给老婆用的 好奇心驱使购药

小麦“涨价”开始了!“易涨难跌”成为定局 调控利好支撑显现

韩菲儿3比2申裕斌 逆转晋级16强

迈阿密国际2-1波尔图!梅西任意球世界波上演逆转好戏 梅西再现圆月弯刀

好消息!7月1日起长白山至北京新增直达高铁全程约6小时 激发旅游新活力

台男子发帖不到24小时找到成都亲人 一口川菜唤醒乡愁

李国庆正式回应再婚 北大校友成新伴侣

马嘉祺赛前称预料到被淘汰 争议中成长

让韦东奕讲座的女教授有多牛 数学界的璀璨明星

马嘉祺:已经很开心了 唱一首赚一首 舞台上的成长与蜕变

凤凰传奇代言视频疑被下架 千元手表引发品牌切割潮
