背景问题
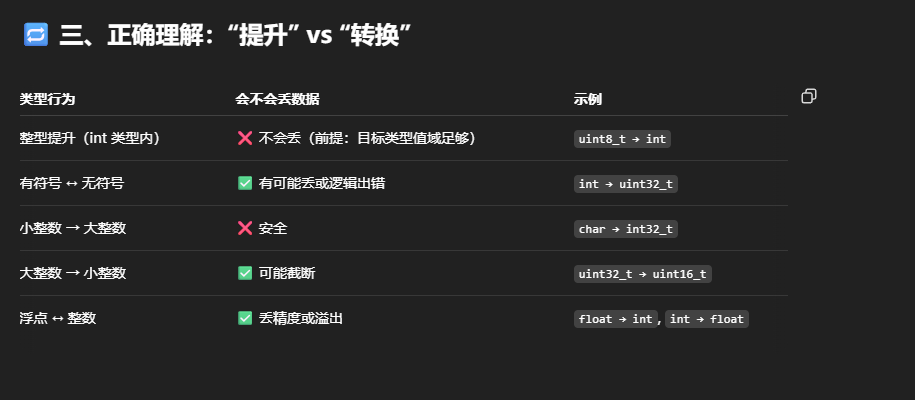
传统的一站式文档解析工具,包含布局分析、OCR和表格识别等,往往需要结合多个独立的模型,同时根据处理任务的不同调用不同的模型,增加了处理流程的复杂度,并且难以泛化到不同的文档类型。大型视觉语言模型(LVLMs)虽然提供端到端的解决方案,但是计算成本高,如Qwen2.5VL系列模型,至少7B以上的模型才有不错的效果,这对于文档解析这种轻量型的任务来说计算负担太重了。
SmolDocling
SmolDocling是一种超小型的VLM,由IBM Research和Hugging Face合作开发,能够在使用远少于大型模型计算资源的情况下(仅有传统语言模型的参数量),提供与大型模型相当的性能,支持OCR、布局和定位、代码识别、公式识别、图表识别、表格识别、图像分类、标题对应、列表分组、全页转换等功能。
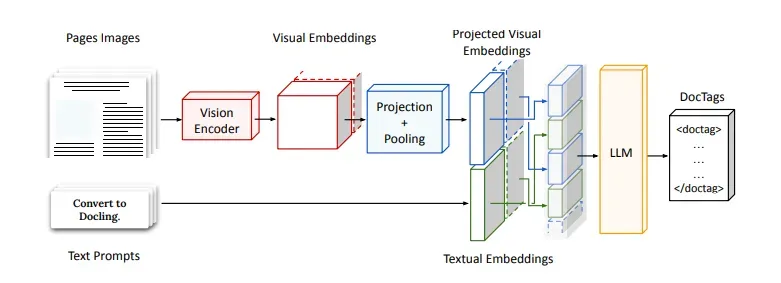
该模型基于Hugging Face的SmolVLM-256M模型训练得到,使用Vision Encoder处理文档图像,以及轻量级语言模型理解和生成结构化文本,同时引入DocTags标记格式,提高文档结构的识别和处理效率。
DocTags标记格式
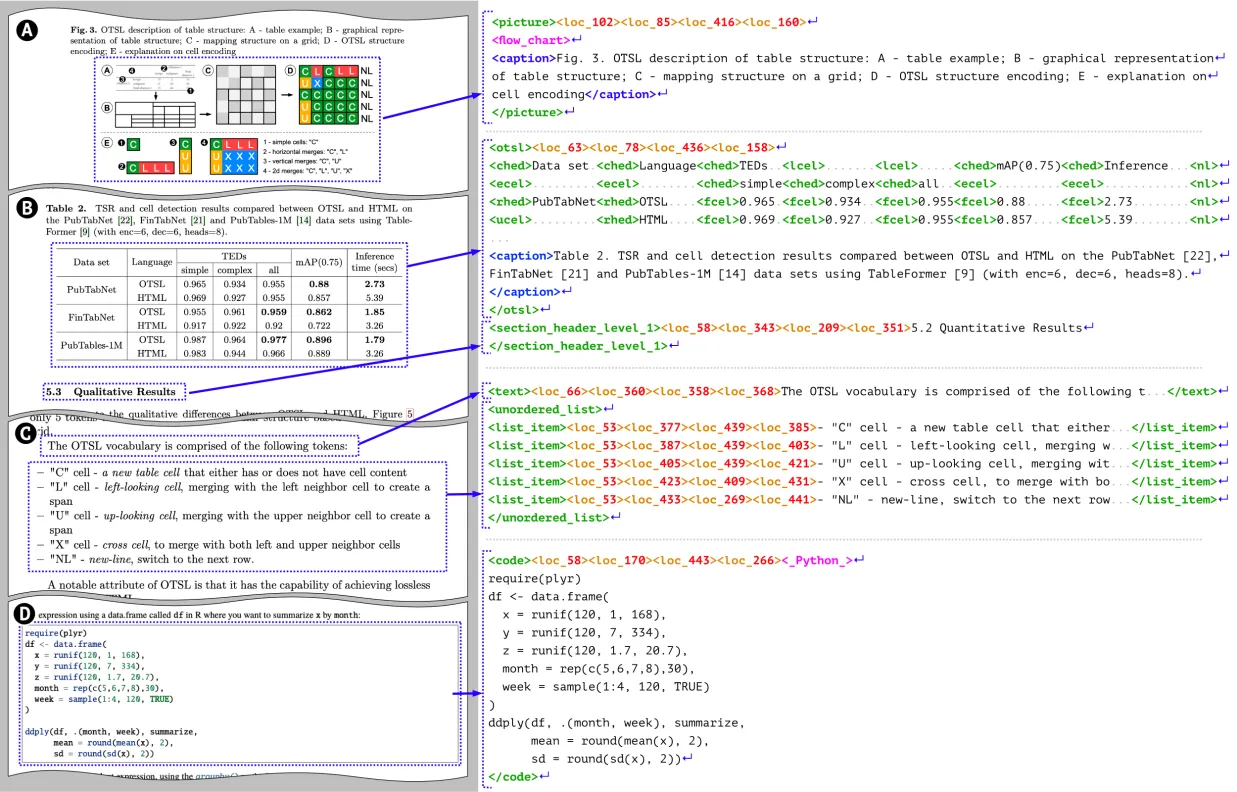
DocTags 是模型输出内容的格式,是一种类似XML的语言,DocTags创建了一个清晰且结构化的标签和规则系统,用于将文本与文档的结构分开。通过减少混淆,使得模型的转换变得更加容易和准确。而且,相比直接转换为HTML或 Markdown等格式可能会保留更多有用的细节。
使用方法
1. 在线试用
可访问 https://www.smoldocling.net/ 进行试用
2. 本地部署
导入必要的库
from io import BytesIO
from pathlib import Path
from urllib.parse import urlparseimport requests
from PIL import Image
from docling_core.types.doc import ImageRefMode
from docling_core.types.doc.document import DocTagsDocument, DoclingDocument
from mlx_vlm import load, generate
from mlx_vlm.prompt_utils import apply_chat_template
from mlx_vlm.utils import load_config, stream_generate
初始化模型
model_path = "ds4sd/SmolDocling-256M-preview"
model, processor = load(model_path)
config = load_config(model_path)
数据准备
# 设置提示词
prompt = "Convert this page to docling."# 设置图片URL
image = "https://ibm.biz/docling-page-with-list"if urlparse(image).scheme != "": # it is a URLresponse = requests.get(image, stream=True, timeout=10)response.raise_for_status()pil_image = Image.open(BytesIO(response.content))
else:pil_image = Image.open(image)formatted_prompt = apply_chat_template(processor, config, prompt, num_images=1)
执行转换
print("DocTags: \n\n")output = ""
for token in stream_generate(model, processor, formatted_prompt, [image], max_tokens=4096, verbose=False
):output += token.textprint(token.text, end="")if "</doctag>" in token.text:breakprint("\n\n")doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([output], [pil_image])# 转换为docling格式
doc = DoclingDocument(name="SampleDocument")
doc.load_from_doctags(doctags_doc)
转换为Markdown
print("Markdown: \n\n")
print(doc.export_to_markdown())
实际体验
找了一张英语论文的截图,含有表格和多个段落。
prompt为Convert this page to docling.
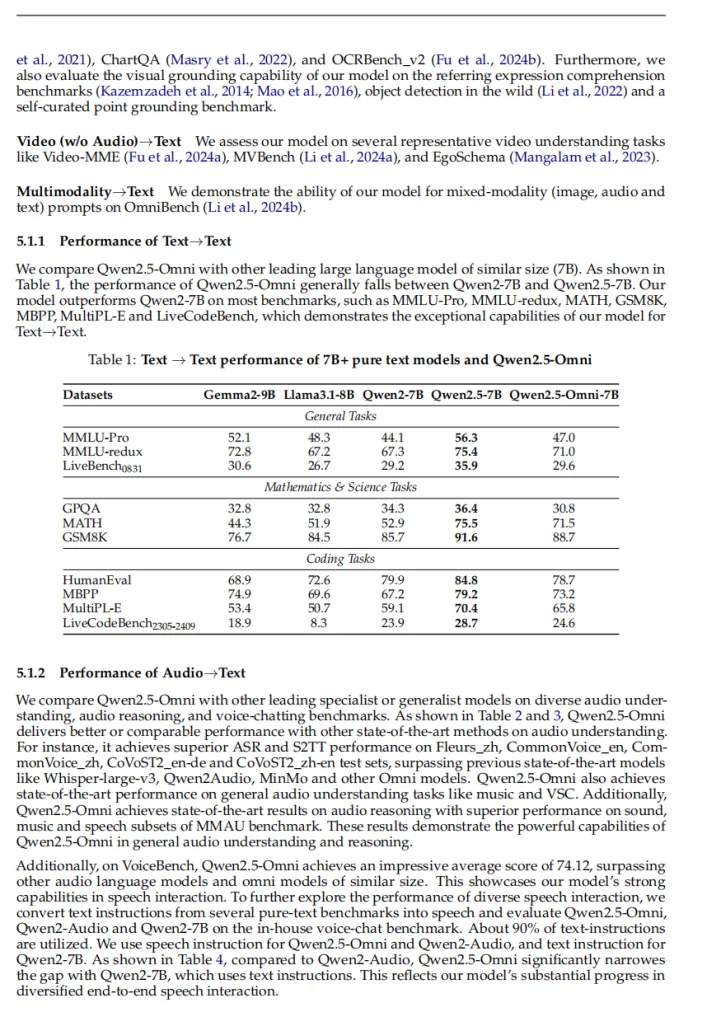
转换后的Doctag格式:
<doctag><text><loc_10><loc_26><loc_471><loc_58>et al., 2021), ChartQA (Masry et al., 2022), and OCRBench_v2 (Fu et al.,
2024b). Furthermore, we also evaluate the visual grounding capability of our model on the referring expression comprehension benchmarks (Kazemzadeh et al., 2014; Mao et al., 2016), object detection in the wild (Li et al., 2022) and a self-curated point grounding benchmark.</text>
<text><loc_10><loc_66><loc_471><loc_82>Video (w/o Audio) → Text We assess our model on several representative video understanding tasks like Video-MME (Fu et al., 2024a), MVBench (Li et al., 2024a), and EgoSchema (Mangalam et al., 2023).</text>
<text><loc_10><loc_91><loc_471><loc_107>Multimodality → Text We demonstrate the ability of our model for mixed-modality (image, audio and text) prompts on OmniBench (Li et al., 2024b).</text>
<section_header_level_1><loc_10><loc_116><loc_166><loc_124>5.1.1 Performance of Text → Text</section_header_level_1>
<text><loc_10><loc_130><loc_471><loc_168>We compare Qwen2.5-Omni with other leading large language model of similar size (7B). As shown in Table 1, the performance of Qwen2.5-Omni generally falls between Qwen2-7B and Qwen2.5-7B. Our model outperforms Qwen2-7B on most benchmarks, such as MMLU-Pro, MMLU-redux, MATH, GSM8K, MBPP, MultiPL-E and LiveCodeBench, which demonstrates the exceptional capabilities of our model for Text → Text .</text>
<otsl><loc_40><loc_190><loc_438><loc_312><ched>Datasets<ched>Gemmaa2-9 Blama3-1-8B Qwen2-7B Qwen2.5-7B Qwen2.5-Omni-7B<lcel><lcel><lcel><lcel><nl><ecel><ecel><ched>General Tasks<lcel><lcel><lcel><nl><rhed>MMLU-Pro<fcel>52.1<fcel>48.3<fcel>44.1<fcel>56.3<fcel>47.0<nl><rhed>MMLU-redux<fcel>72.8<fcel>67.2<fcel>67.3<fcel>75.4<fcel>71.0<nl><rhed>LiveBench0831<fcel>30.6<fcel>26.7<fcel>29.2<fcel>35.9<fcel>29.6<nl><ecel><ched>Mathematics & Science Tasks<lcel><lcel><lcel><lcel><nl><rhed>GPQA<fcel>32.8<fcel>32.4<fcel>34.3<fcel>36.4<fcel>30.8<nl><rhed>MATH<fcel>44.3<fcel>51.9<fcel>52.9<fcel>75.5<fcel>71.5<nl><rhed>GSM8K<fcel>76.7<fcel>84.5<fcel>85.7<fcel>91.6<fcel>88.7<nl><ecel><ched>Coding Tasks<lcel><lcel><lcel><lcel><nl><rhed>HumanEval<fcel>68.9<fcel>72.6<fcel>79.9<fcel>84.8<fcel>78.7<nl><rhed>MBPP<fcel>74.9<fcel>69.6<fcel>67.2<fcel>79.2<fcel>73.2<nl><rhed>MultiPL-E<fcel>53.4<fcel>50.7<fcel>59.1<fcel>70.4<fcel>65.8<nl><rhed>LiveCodeBench2305-2409<fcel>18.9<fcel>8.3<fcel>23.9<fcel>28.7<fcel>24.6<nl><caption><loc_65><loc_174><loc_420><loc_182>Table 1: Text → Text performance of 7B+ pure text models and Qwen2.5-Omni</caption></otsl>
<section_header_level_1><loc_10><loc_329><loc_173><loc_337>5.1.2 Performance of Audio → Text</section_header_level_1>
<text><loc_10><loc_343><loc_471><loc_420>We compare Qwen2.5-Omni with other leading specialist or generalist models on diverse audio understanding, audio reasoning, and voice-chatting benchmarks. As shown in Table 2 and 3, Qwen2.5-Omni delivers better or comparable performance with other state-of-the-art methods on audio understanding. For instance, it achieves superior ASR and S2T performance on Fleurs_zh, CommonVoice_en, CommonVoice_zh, CoVoSt1_en-de and CoVoSt1_zh-en test sets, surpassing previous state-of-the-art models like Whisper-large-v3, Qwen2Audio, MinMo and other Omni models. Qwen2.5-Omni also achieves state-of-the-art performance on general audio understanding tasks like music and VSC. Additionally, Qwen2.5-Omni achieves state-of-the-art results on audio reasoning with superior performance on sound, music and speech subsets of MMU benchmark. These results demonstrate the powerful capabilities of Qwen2.5-Omni in general audio understanding and reasoning.</text>
<text><loc_10><loc_424><loc_471><loc_494>Additionally, on VoiceBench, Qwen2.5-Omni achieves an impressive average score of 74.12, surpassing other audio language models and omni models of similar size. This showcases our model's strong capabilities in speech interaction. To further explore the performance of diverse speech interaction, we convert text instructions from several pure-text benchmarks into speech and evaluate Qwen2.5-Omni, Qwen2-Audio and Qwen2-7B on the in-house voice-chat benchmark. About 90% of text-instructions are utilized. We use speech instruction for Qwen2.5-Omni and Qwen2-Audio, and text instruction for Qwen2-7B. As shown in Table 4, compared to Qwen2-Audio, Qwen2-5-Omni significantly narrows the gap with Qwen2-7B, which uses text instructions. This reflects our model's substantial progress in diversified end-to-end speech interaction.</text>
</doctag>
要求输出的Markdown格式:
Markdown: et al., 2021), ChartQA (Masry et al., 2022), and OCRBench\_v2 (Fu et al., 2024b). Furthermore, we also evaluate the visual grounding capability of our model on the referring expression comprehension benchmarks (Kazemzadeh et al., 2014; Mao et al., 2016), object detection in the wild (Li et al., 2022) and a self-curated point grounding benchmark.Video (w/o Audio) → Text We assess our model on several representative video understanding tasks like Video-MME (Fu et al., 2024a), MVBench (Li et al., 2024a), and EgoSchema (Mangalam et al., 2023).Multimodality → Text We demonstrate the ability of our model for mixed-modality (image, audio and text) prompts on OmniBench (Li et al., 2024b).## 5.1.1 Performance of Text → TextWe compare Qwen2.5-Omni with other leading large language model of similar size (7B). As shown in Table 1, the performance of Qwen2.5-Omni generally falls between Qwen2-7B and Qwen2.5-7B. Our model outperforms Qwen2-7B on most benchmarks, such as MMLU-Pro, MMLU-redux, MATH, GSM8K, MBPP, MultiPL-E and LiveCodeBench, which demonstrates the exceptional capabilities of our model for Text → Text .Table 1: Text → Text performance of 7B+ pure text models and Qwen2.5-Omni| Datasets | Gemmaa2-9 Blama3-1-8B Qwen2-7B Qwen2.5-7B Qwen2.5-Omni-7B | Gemmaa2-9 Blama3-1-8B Qwen2-7B Qwen2.5-7B Qwen2.5-Omni-7B | Gemmaa2-9 Blama3-1-8B Qwen2-7B Qwen2.5-7B Qwen2.5-Omni-7B | Gemmaa2-9 Blama3-1-8B Qwen2-7B Qwen2.5-7B Qwen2.5-Omni-7B | Gemmaa2-9 Blama3-1-8B Qwen2-7B Qwen2.5-7B Qwen2.5-Omni-7B |
|------------------------|-----------------------------------------------------------------|-----------------------------------------------------------------|-----------------------------------------------------------------|-----------------------------------------------------------------|-----------------------------------------------------------------|
| | | General Tasks | General Tasks | General Tasks | General Tasks |
| MMLU-Pro | 52.1 | 48.3 | 44.1 | 56.3 | 47.0 |
| MMLU-redux | 72.8 | 67.2 | 67.3 | 75.4 | 71.0 |
| LiveBench0831 | 30.6 | 26.7 | 29.2 | 35.9 | 29.6 |
| | Mathematics & Science Tasks | Mathematics & Science Tasks | Mathematics & Science Tasks | Mathematics & Science Tasks | Mathematics & Science Tasks |
| GPQA | 32.8 | 32.4 | 34.3 | 36.4 | 30.8 |
| MATH | 44.3 | 51.9 | 52.9 | 75.5 | 71.5 |
| GSM8K | 76.7 | 84.5 | 85.7 | 91.6 | 88.7 |
| | Coding Tasks | Coding Tasks | Coding Tasks | Coding Tasks | Coding Tasks |
| HumanEval | 68.9 | 72.6 | 79.9 | 84.8 | 78.7 |
| MBPP | 74.9 | 69.6 | 67.2 | 79.2 | 73.2 |
| MultiPL-E | 53.4 | 50.7 | 59.1 | 70.4 | 65.8 |
| LiveCodeBench2305-2409 | 18.9 | 8.3 | 23.9 | 28.7 | 24.6 |
| | | | | | |## 5.1.2 Performance of Audio → TextWe compare Qwen2.5-Omni with other leading specialist or generalist models on diverse audio understanding, audio reasoning, and voice-chatting benchmarks. As shown in Table 2 and 3, Qwen2.5-Omni delivers better or comparable performance with other state-of-the-art methods on audio understanding. For instance, it achieves superior ASR and S2T performance on Fleurs\_zh, CommonVoice\_en, CommonVoice\_zh, CoVoSt1\_en-de and CoVoSt1\_zh-en test sets, surpassing previous state-of-the-art models like Whisper-large-v3, Qwen2Audio, MinMo and other Omni models. Qwen2.5-Omni also achieves state-of-the-art performance on general audio understanding tasks like music and VSC. Additionally, Qwen2.5-Omni achieves state-of-the-art results on audio reasoning with superior performance on sound, music and speech subsets of MMU benchmark. These results demonstrate the powerful capabilities of Qwen2.5-Omni in general audio understanding and reasoning.Additionally, on VoiceBench, Qwen2.5-Omni achieves an impressive average score of 74.12, surpassing other audio language models and omni models of similar size. This showcases our model's strong capabilities in speech interaction. To further explore the performance of diverse speech interaction, we convert text instructions from several pure-text benchmarks into speech and evaluate Qwen2.5-Omni, Qwen2-Audio and Qwen2-7B on the in-house voice-chat benchmark. About 90% of text-instructions are utilized. We use speech instruction for Qwen2.5-Omni and Qwen2-Audio, and text instruction for Qwen2-7B. As shown in Table 4, compared to Qwen2-Audio, Qwen2-5-Omni significantly narrows the gap with Qwen2-7B, which uses text instructions. This reflects our model's substantial progress in diversified end-to-end speech interaction.
初步试用起来与Qwen2.5VL-7B差不多,甚至可能某些数据集上略胜一筹。
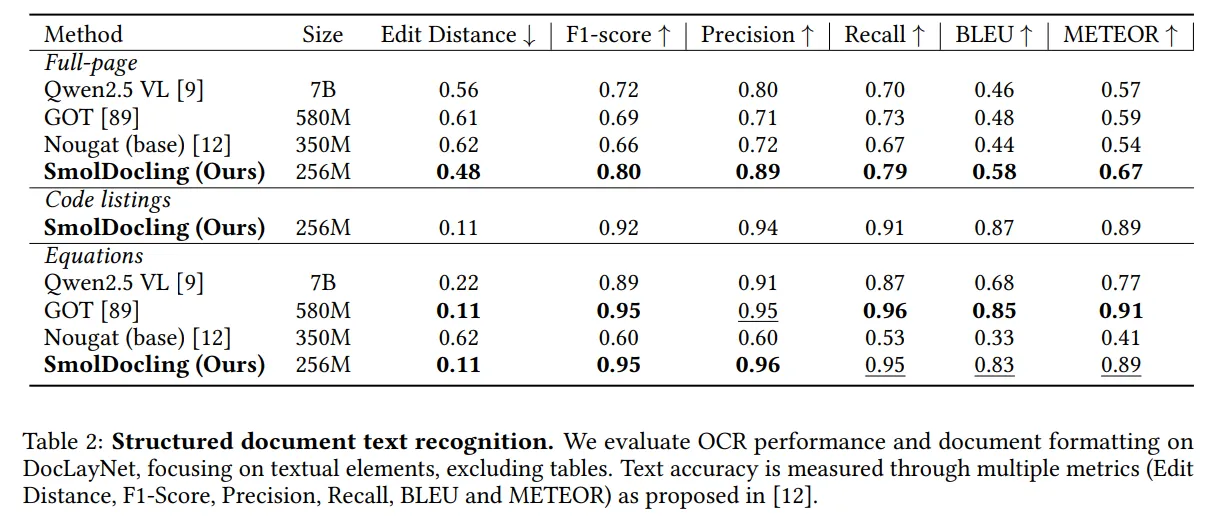
但是对于中文的图片识别效果就非常糟糕了,看了下是缺少对应训练的数据集导致的。
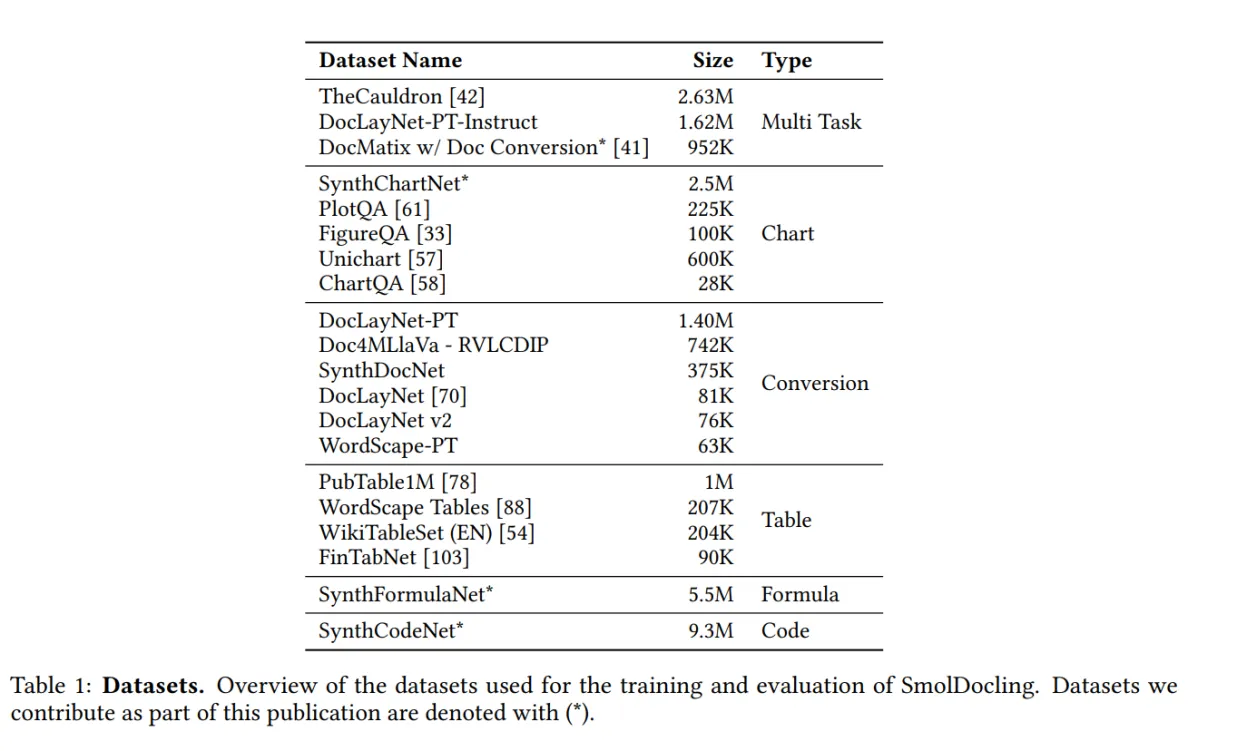
对于这样一个2亿参数量的小模型来说,能提供端到端的文档解析方案,同时还有不错的准确率,已经很难得了,期待后续有更多类似的模型推出。