一、元组
元组(Tuple)是 Python 中一种不可变的序列数据类型。元组一旦创建,其元素不能被修改、删除或添加。这一特性使得元组在需要保护数据不被意外更改的场景中非常有用,比如作为字典的键或在多线程环境中共享数据。
1、元组的创建
使用括号创建:可以通过在括号内放置元素,以逗号分隔来创建元组。例如:
my_tuple1 = (1, 2, 3)
my_tuple2 = ('a', 'b', 'c')
my_tuple3 = (1, 'hello', 3.14, [4, 5])
元组可以包含不同类型的元素,如
my_tuple3中同时包含了整数、字符串、浮点数和列表。
省略括号创建:在创建元组时,括号是可选的,只要使用逗号分隔元素即可。例如:
my_tuple4 = 10, 20, 'thirty' # 逗号是关键
print(my_tuple4)
print(type(my_tuple4)) # 看看它的类型
# 输出:
(10, 20, 'thirty')
<class 'tuple'>创建空元组:可以使用空括号 () 或 tuple() 函数来创建空元组。例如:
empty_tuple = ()
empty_tuple2 = tuple()
2、元组的索引
正向索引:元组的索引从 0 开始,通过索引值可以访问元组中的单个元素。例如:
my_tuple = ('P', 'y', 't', 'h', 'o', 'n')
print(my_tuple[0]) # 输出 'P',访问第一个元素
print(my_tuple[2]) # 输出 't',访问第三个元素
反向索引:也可以使用负数进行反向索引,从 -1 开始表示最后一个元素。例如:
print(my_tuple[-1]) # 输出 'n',访问最后一个元素
3、元组的切片
基本切片:切片操作允许从元组中获取一个子元组。切片语法是 my_tuple[start:stop:step],其中 start 是起始索引(包含),stop 是结束索引(不包含),step 是步长(可选,默认为 1)。例如:
my_tuple = (0, 1, 2, 3, 4, 5)
print(my_tuple[1:4]) # 输出 (1, 2, 3),从索引 1 到 3 (不包括 4)
省略起始或结束索引:如果省略 start,切片将从元组开头开始;如果省略 stop,切片将一直到元组末尾。例如:
print(my_tuple[:3]) # 输出 (0, 1, 2),从开头到索引 2
print(my_tuple[3:]) # 输出 (3, 4, 5),从索引 3 到结尾
指定步长:通过指定 step,可以每隔一定数量的元素获取一个。例如:
print(my_tuple[::2]) # 输出 (0, 2, 4),每隔一个元素取一个
当
step为负数时,可以实现反向切片,例如my_tuple[::-1]将返回元组的反转版本。
二、pipeline
1、输入的结构
在 scikit - learn 库中,pipeline类用于构建机器学习工作流程,将多个数据处理步骤和机器学习模型按顺序连接起来。pipeline类接收的是一个包含多个小元组的列表作为输入:
from sklearn.pipeline import Pipeline
Pipeline(steps, memory=None, verbose=False)
steps:关键参数,是一个包含多个元组的列表。- 列表 []: 定义了步骤执行的先后顺序(因为列表是有序的数据结构)。Pipeline 会按照列表中的顺序依次处理数据。并且由于列表的可修改性,可以灵活调整数据处理步骤。
- 元组 (): 用于将步骤的名称和实际执行数据转换或模型训练的处理对象捆绑在一起,步骤名称(字符串)用于标识该步骤,方便后续引用和参数设置。
memory:可选参数,用于缓存Pipeline中步骤的计算结果,以提高计算效率。可传入一个目录路径字符串,Pipeline将在该目录下缓存数据。None(默认值)则不进行缓存。如:
pipeline = Pipeline(steps, memory='cache_dir')
verbose:可选参数,布尔值。如果设置为True,Pipeline在执行每个步骤时会打印详细信息,有助于调试和监控流程执行情况;默认值为False,不打印详细信息。
2、代码框架
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 构建管道
pipeline = Pipeline([('scaler', StandardScaler()),('logreg', LogisticRegression())
])# 4. 训练模型
pipeline.fit(X_train, y_train)# 5. 预测
y_pred = pipeline.predict(X_test)# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型在测试集上的准确率: {accuracy:.2f}")3、为什么设计为类而不是函数?
1. 封装与状态管理
封装性:类能将数据(属性)和操作(方法)捆绑在一起。Pipeline 类封装了多个数据处理步骤和机器学习模型以及执行逻辑。而函数通常只专注于执行任务,不太容易实现综合性的封装。
状态管理:Pipeline 类可以通过内部属性(如 mean_ )来管理状态(例如,StandardScaler 类在 fit 过程中计算的均值和标准差)。而调用函数是独立操作,难以在多个步骤间共享和维护。
2. 面向对象编程与代码复用
面向对象:scikit - learn 库整体采用面向对象编程范式,Pipeline 作为其中的一部分,设计为类与整个库的架构保持一致,这样 Pipeline 类可以很方便地进行集成。
代码复用:类可以通过继承和组合的方式实现代码复用。Pipeline 类可以组合多个不同的处理类(如数据预处理类和模型类)使得它具有很高的灵活性和复用性。
3. 方法和接口的统一
统一接口:Pipeline 类定义了一系列统一的方法,如 fit、transform、fit_transform、predict 等,这些方法与 scikit - learn 中其他模型和转换器类的接口保持一致。
链式调用:作为类,Pipeline 对象支持方法的链式调用,能清晰表达数据从训练到预测的整个流程。如pipeline.fit(X_train, y_train).predict(X_test)。而函数实现需要额外设计处理。
4. 参数管理与灵活性
参数设置与管理:Pipeline 类提供了方便的参数设置和管理机制。通过 set_params 方法可以轻松设置 Pipeline 中各步骤的参数,并且(如 step_name__param_name)参数名通过步骤名称和参数名称的组合来指定的方式非常直观且易理解。
动态调整:在实际应用中,可能需要根据不同的情况动态调整 Pipeline 的结构或参数。作为类,Pipeline 对象可以在运行时根据条件进行修改,例如添加或删除步骤、调整参数等。
三、可迭代对象
可迭代对象是能一次返回其成员,可在循环(如 for 循环)中遍历的对象。
例如,对于列表my_list = [1, 2, 3],可以通过for num in my_list:这样的循环来遍历其中的元素。Python中有很多内置的可迭代对象:
序列类型:list、tuple、str、range,它们的元素有序且可通过索引访问。
集合类型:set集合中的元素无序且唯一,遍历集合时会按某种内部顺序依次返回元素。
字典类型:在默认情况下,迭代字典时返回键(keys)。不过字典也可以通过my_dict.values()迭代值,通过my_dict.items()迭代键值对。
文件对象:例如,打开一个文件file = open('example.txt', 'r'),可以使用for line in file:逐行读取文件内容。读取完毕后,记得关闭文件file.close()。
生成器:生成器是一种特殊的可迭代对象,它并不立即生成所有的值,而是按需生成,从而节省内存。比如使用生成器表达式(i for i in range(5))。
迭代器:迭代器本身也是可迭代对象。迭代器遵循迭代器协议,具有__next__方法,可逐个返回元素,当没有元素可返回时引发StopIteration异常。
四、OS模块
# os是系统内置模块,无需安装
import os# 获取当前工作目录的绝对路径(get current working directory )
os.getcwd() # 获取当前工作目录下的文件列表(list directory )
os.listdir() # 使用 r'' 原始字符串就不需要写双反斜杠 \\,因为\会涉及到转义问题
path_a = r'C:\Users\YourUsername\Documents'
path_b = 'MyProjectData'
file = 'results.csv'# os.path.join用于将多个路径组件拼接成完整的路径并会根据当前操作系统自动使用合适的路径分割符
file_path = os.path.join(path_a , path_b, file)
file_path
# 输出:'C:\\Users\\YourUsername\\Documents\\MyProjectData\\results.csv'# 返回环境变量名和对应的值,形式像字典中的键值对
os.environ
# os.environ是可迭代对象
for variable_name, value in os.environ.items():print(f"{variable_name}={value}")
print(f"\n--- 总共检测到 {len(os.environ)} 个环境变量 ---")
OS.walk()
os.walk() 是 Python os 模块里用于遍历目录树的强大函数:
1. 函数定义与参数
os.walk(top, topdown=True, onerror=None, followlinks=False):
top:必选参数,指定要开始遍历的目录路径,可以是绝对路径或相对路径。topdown:可选参数,默认为True。当topdown=True时,函数会先遍历顶层目录,然后递归遍历子目录;若设为False,则先遍历子目录,最后才遍历顶层目录。onerror:可选参数,默认值为None。如果在遍历过程中发生错误,且你提供了一个错误处理函数给onerror,那么该函数会被调用。若设为None,遇到错误时会直接引发异常中断遍历。followlinks:可选参数,默认为False。在遍历目录树时,如果遇到符号链接(类似快捷方式),followlinks=False时,符号链接指向的目录不会被遍历。
2. 返回值
os.walk()是一个生成器函数,不会一次性返回整个目录树的所有信息,而是按需逐目录生成包含三个元素的元组(dirpath, dirnames, filenames):
dirpath:一个字符串,表示当前正在访问的目录的完整路径。dirnames:一个列表,包含dirpath目录下所有子目录的名称,但不包括表示当前目录的.和表示上级目录的..。filenames:一个列表,包含dirpath目录下所有非目录文件的名称。
3. 深度优先遍历策略
先复习一下深度优先遍历:
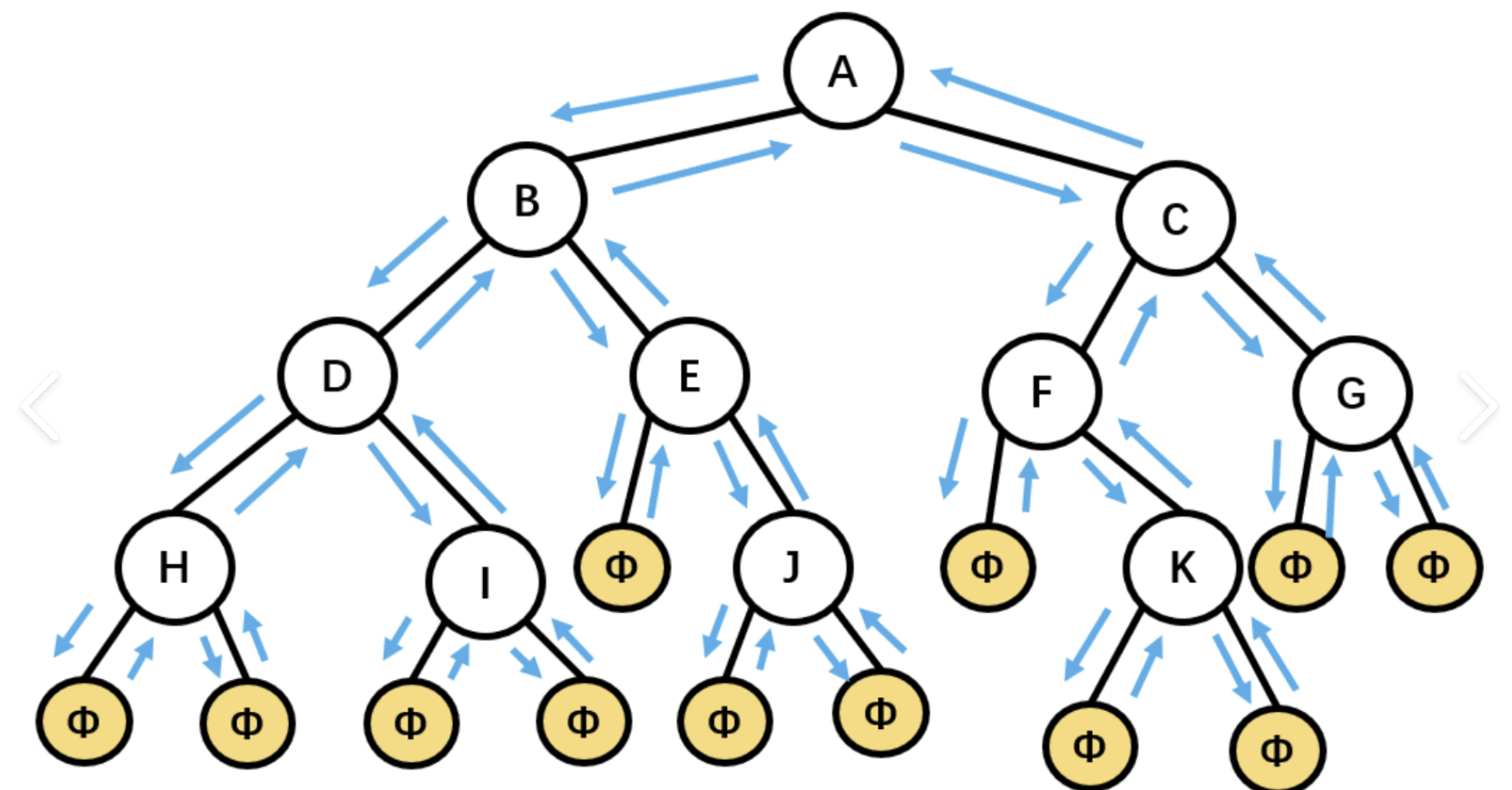



import osstart_directory = os.getcwd()
print(f"--- 开始遍历目录: {start_directory} ---")
for dirpath, dirnames, filenames in os.walk(start_directory):print(f" 当前访问目录 (dirpath): {dirpath}")print(f" 子目录列表 (dirnames): {dirnames}")print(f" 文件列表 (filenames): {filenames}")# 打印文件完整路径
print("--- 文件完整路径: ---")full_path = os.path.join(dirpath, filename)print(f" - {full_path}")
为什么学这个嘞?
在云服务器(通常基于 Linux 系统)上运行代码时,不像 Windows 系统有图形化界面能直观查看目录结构,但借助 Python 的 os 模块,就可以很方便地在代码中获取相关信息啦
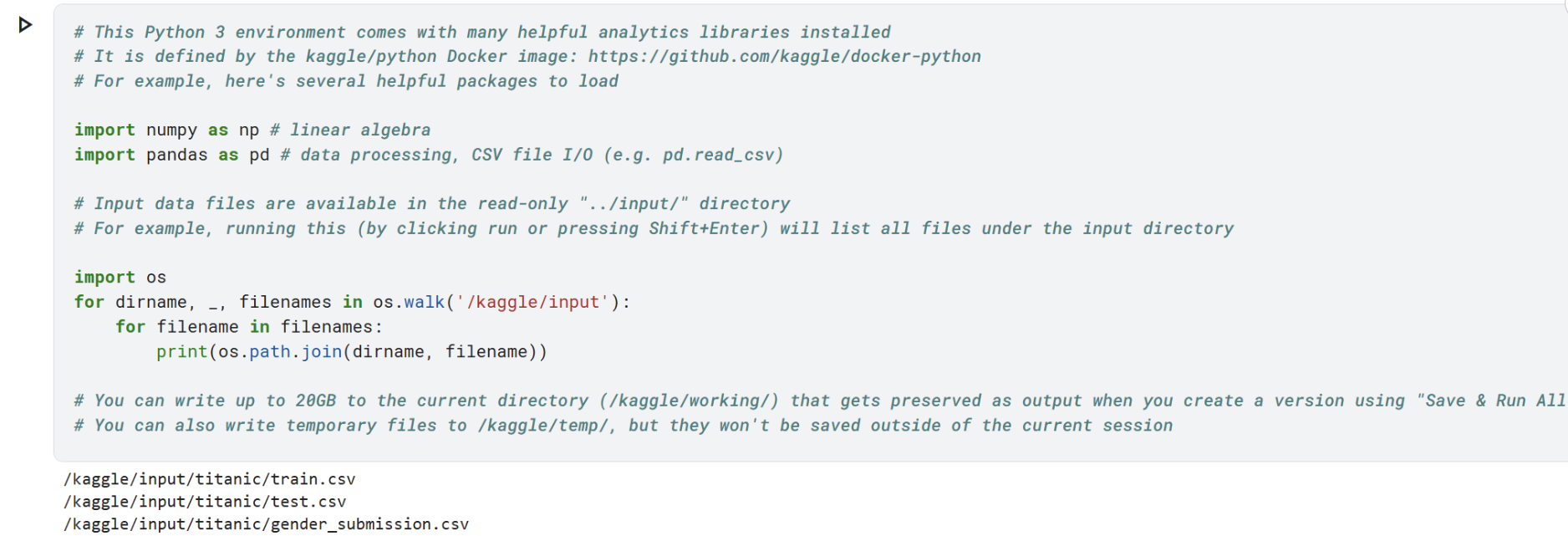
这是kaggle平台官方提供的代码头,就是方便查看文件情况。
@浙大疏锦行