填空选择判断
第一章
一、填空题
1.Scala语言的特性包含____________、函数式编程的、____________、可扩展的、____________。
2.在Scala 数据类型层级结构的底部有两个数据类型,分别是____________和____________。
3.在Scala中,声明变量的关键字有____________和____________。
4.在Scala中,获取元组中的值是通过____________来获取的
5.在Scala中,模式匹配是由关键字____________和____________组成的。
答案
1.Scala语言的特性包含面向对象的、函数式编程的、静态类型的、可扩展的、可交互操作的。
2.在Scala 数据类型层级结构的底部有两个数据类型,分别是 Nothing 和 Null 。
3.在Scala中,声明变量的关键字有 var 和 val 。
4.在Scala中,获取元组中的值是通过 下划线加脚标 来获取的。
5.在Scala中,模式匹配是由关键字 match 和 case 组成的。
二、判断题
1.安装Scala之前必须配置JDK。 ( )
2.Scala语言是一种面向过程编程的语言。 ( )
3.在Scala中,使用关键字var声明的变量,值是不可变的。 ( )
4.在Scala中定义变长数组时,需要导入可变数组包。 ( )
5.Scala语言和Java语言一样,都有静态方法或静态字段。 ( )
答案
1.安装Scala之前必须配置JDK。 (√)
2.Scala语言是一种面向过程编程的语言。 (×)
3.在Scala中,使用关键字var声明的变量,值是不可变的。 (×)
4.在Scala中定义变长数组时,需要导入可变数组包。 (√)
5.Scala语言和Java语言一样,都有静态方法或静态字段。 (×)
解析
4. 在Scala中定义变长数组时,需要导入可变数组包 正确
Scala集合库分为:
不可变集合:默认导入,位于scala.collection.immutable
可变集合:需要显式导入,位于scala.collection.mutable
定义变长数组(ArrayBuffer)的示例:
import scala.collection.mutable.ArrayBufferval buffer = ArrayBuffer(1, 2, 3) // 可变数组
buffer += 4 // 可以添加元素而不可变数组(Vector或List)不需要额外导入:
val list = List(1, 2, 3) // 不可变列表
// list += 4 // 这会编译错误5. Scala语言和Java语言一样,都有静态方法或静态字段 错误
Scala与Java在静态成员处理上有显著区别:
Java:使用static关键字定义静态方法和字段
class Util {public static void helper() { ... }
}Scala:没有static关键字,而是通过伴生对象实现类似功能
object Util { // 伴生对象def helper(): Unit = { ... }
}class Util { // 伴生类// 实例成员
}Scala的这种设计更符合纯面向对象的原则,所有"静态"成员实际上都是伴生对象的实例成员。
伴生对象的概念:
伴生对象(Companion Object)是Scala中与类同名且定义在同一个文件中的单例对象。它是Scala用来替代Java静态成员的一种设计,同时保持了纯粹的面向对象特性。
伴生对象的特点:
与类同名:伴生对象必须与它伴随的类同名
单例性质:伴生对象是单例的,不需要实例化即可使用
同一文件:伴生对象和伴生类必须定义在同一个源文件中
互相访问特权:伴生对象和伴生类可以互相访问对方的私有成员
三、选择题
1.下列选项中,哪个是Scala编译后文件的扩展名?( )
A. .class
B. .bash
C. .pyc
D. .sc
答案:A
2.下列方法中,哪个方法可以正确计算数组arr的长度?( )
A. count()
B. take()
C. tail ()
D. length()
答案:D
3.下列关于List的定义,哪个是错误的?( )
A. val list = List(1,22,3)
B. val list = List(“Hello”,“Scala”)
C. val list : String = List(“A”,“B”)
D. val list = List[Int](1,2,3)
答案:D
第二章
一、填空题
1.Spark生态系统包含____________、Spark SQL、____________、MLlib、____________以及独立调度器组件。
2.Spark计算框架的特点是速度快、____________、通用性、____________。
3.Spark集群的部署模式有Standalone模式、____________和Mesos模式。
4.启动Spark集群的命令为_________________________________________。
5.Spark集群的运行架构由____________、Cluster Manager和____________组成。
答案
1.Spark生态系统包含 Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX 以及独立调度器组件。
2.Spark计算框架的特点是 速度快、易用性、通用性、兼容性。
3.Spark集群的部署模式有 Standalone模式、YARN模式和Mesos模式。
4.启动Spark集群的命令为 sbin / start-all.sh。
5.Spark集群的运行架构由Driver、Cluster Manager和Worker组成。
解析
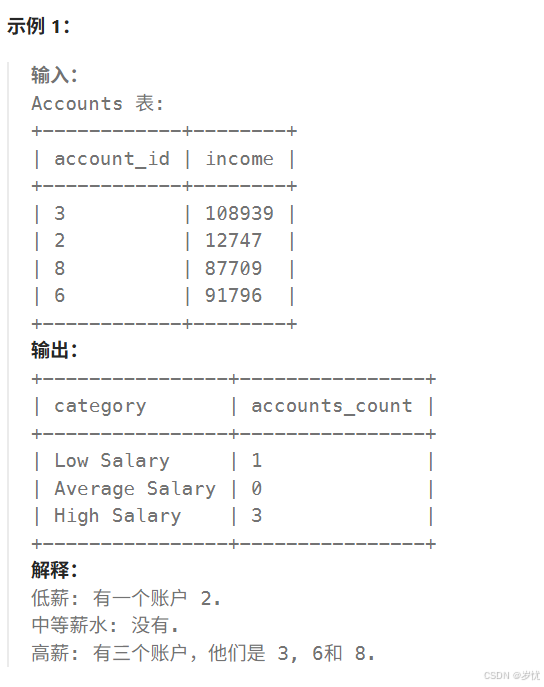
Spark Core:基础引擎,提供任务调度、内存管理、故障恢复等核心功能
Spark SQL:结构化数据处理模块,支持SQL查询
Spark Streaming:实时流数据处理
MLlib:机器学习库,包含常见算法实现
GraphX:图计算框架,用于社交网络分析等场景
Driver:运行应用main()函数,创建SparkContext
将用户程序转为任务
调度任务到Executor
Cluster Manager:资源分配管理
Standalone/YARN/Mesos
Worker:执行计算任务
运行Executor进程
存储RDD分区数据
RDD(弹性分布式数据集):
不可变的分布式对象集合
两种操作类型:
// 转换操作(惰性求值)
val rdd2 = rdd1.map(x => x*2)// 行动操作(触发计算)
rdd2.count()二、判断题
1.Spark诞生于洛桑联邦理工学院(EPFL)的编程方法实验室。 ( )
2. Spark比Hadoop计算的速度快。 ( )
3.部署Spark高可用集群不需要用到Zookeeper服务。 ( )
4. Spark Master HA主从切换过程不会影响集群已有的作业运行。 ( )
5.集群上的任务是由执行器来调度的。 ( )
答案
1.Spark诞生于洛桑联邦理工学院(EPFL)的编程方法实验室。 (×)
2.Spark比Hadoop计算的速度快。 (√)
3.部署Spark高可用集群不需要用到Zookeeper服务。 (×)
4.Spark Master HA主从切换过程不会影响集群已有的作业运行。 (√)
5.集群上的任务是由执行器来调度的。 (×)
解析
三、选择题
1.下列选项中,哪个不是Spark生态系统中的组件?( )
A. Spark Streaming
B. Mlib
C. Graphx
D. Spark R
答案:D
2.下面哪个端口不是Spark 自带服务的端口?( )
A. 8080
B. 4040
C. 8090
D. 18080
答案:C
3.下列选项中,针对Spark运行的基本流程哪个说法是错误的?( )
A. Driver端提交任务,向Master申请资源
B. Master与Worker进行TCP通信,使得Worker启动Executor
C. Executor启动会主动连接Driver,通过Driver->Master->WorkExecutor,从而得到Driver在哪里
D. Driver会产生Task,提交给Executor中启动Task去做真正的计算
答案:B
解析
A. Driver端提交任务,向Master申请资源
正确:Driver是整个应用的控制器,负责向资源管理器申请资源
B. Master与Worker进行TCP通信,使得Worker启动Executor
正确:Master通过RPC通信指挥Worker启动Executor容器
C. Executor启动会主动连接Driver,通过Driver->Master->WorkExecutor,从而得到Driver在哪里
错误:Executor是直接连接Driver,不需要通过Master中转。Worker在启动Executor时就已经知道Driver地址
D. Driver会产生Task,提交给Executor中启动Task去做真正的计算
正确:Driver将Job分解为TaskSet,直接调度到Executor执行
第三章
一、填空题
1.RDD(Resilient Distributed Dataset)是____________的一个抽象概念,也是一个____________、并行的数据结构。
2.RDD的操作主要分为____________和____________。
3.RDD的依赖关系有____________和____________。
4.RDD的分区方式有__________________和____________。
5.RDD的容错方式有____________和____________。
答案
1.RDD是 分布式内存 的一个抽象概念,也是一个 不可变、并行的 数据结构。
2.RDD的操作主要分为 转换算子操作 和 行动算子操作 。
3.RDD的依赖关系有 窄依赖(narrow dependencies) 和 宽依赖(wide dependencies)。
4.RDD的分区方式有 哈希分区(hash partitioning) 和 范围分区(range partitioning)。
5.RDD的容错方式有 血统方式(lineage) 和 设置检查点(checkpointing)方式。
2. RDD操作类型
(1) 转换操作(Transformations)
特点:
惰性执行
返回新RDD
常见操作:
val rdd2 = rdd1.map(_ * 2) // 映射
val rdd3 = rdd2.filter(_ > 10) // 过滤
val rdd4 = rdd3.union(rdd2) // 合并(2) 行动操作(Actions)
特点:
立即触发计算
返回非RDD结果
常见操作:
rdd4.count() // 计数
rdd4.collect() // 收集数据到Driver
rdd4.saveAsTextFile("hdfs://path") // 保存 5. RDD容错机制
(1) 血缘关系(Lineage)
记录RDD的转换历史
通过重新计算丢失的分区恢复数据
示例血缘:
TextFile -> MapRDD -> FilterRDD -> ReduceByKeyRDD
(2) 检查点(Checkpointing)
sc.setCheckpointDir("hdfs://checkpoint")
rdd.checkpoint() // 标记需要检查点
rdd.count() // 实际触发保存将RDD持久化到可靠存储
切断血缘关系
适用场景:迭代计算长血缘链
二、判断题
1.RDD是一个可变、不可分区、里面的元素是可并行计算的集合。( )
2.RDD采用了惰性调用,即在RDD的处理过程中,真正的计算发生在RDD的“行动”操作。( )
3.宽依赖是指每一个父RDD的Partition(分区)最多被子RDD的一个Partition使用。( )
4.如果一个有向图可以从任意顶点出发经过若干条边回到该点,则这个图就是有向无环图。( )
5.窄依赖是划分Stage的依据。( )
答案
1.RDD是一个可变、不可分区、里面的元素是可并行计算的集合。 (×)
2.RDD采用了惰性调用,即在RDD的处理过程中,真正的计算发生在RDD的"行动"操作。 (√)
3.宽依赖是指每一个父RDD的Partition(分区)最多被子RDD的一个Partition使用。 (×)
4.如果一个有向图可以从任意顶点出发经过若干条边回到该点,则这个图就是有向无环图。 (×)
5.窄依赖是划分Stage的依据。 (×)
解析
1. RDD的基本特性
正确的RDD特性:
不可变(Immutable):一旦创建就不能被修改,任何转换操作都会生成新的RDD
可分区的(Partitioned):数据被划分为多个分区分布在集群中
可并行计算:不同分区可以在不同节点上并行处理
2. RDD的惰性求值
执行模型:

转换操作(Transformations):记录元数据,不立即计算。例如:map(), filter(), flatMap()
行动操作(Actions):触发实际计算。例如:count(), collect(), saveAsTextFile()
3. RDD依赖关系
窄依赖 vs 宽依赖
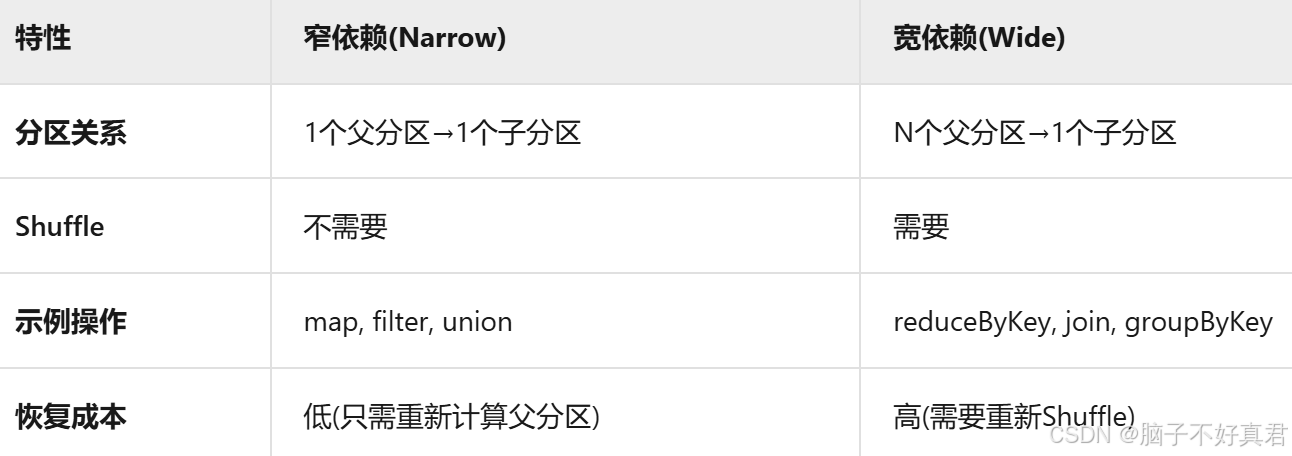
"宽依赖包含一对多和多对一(也就是说N可以为1),本质是需要Shuffle的跨分区依赖"
4. 有向无环图(DAG)
DAG的正确定义:
有向:边有方向性
无环:不能从任何顶点出发经过若干边回到该点
阶段(Stage)划分:
宽依赖是Stage划分的边界
每个Stage包含多个窄依赖的连续操作
5. Stage划分依据
正确的Stage划分规则:
宽依赖是划分Stage的依据
每个Stage内部只有窄依赖
三、选择题
1.下列方法中,用于创建RDD的方法是( )
A. makeRDD()
B. parallelize()
C. textFile()
D. testFile()
答案:C
2.下列选项中,哪个不属于转换算子操作?( )
A. filter(func)
B. map(func)
C. reduce(func)
D. reduceByKey(func)
答案:C
3.下列选项中,能使RDD产生宽依赖的是( )
A. map(func)
B. filter(func)
C. union
D. groupByKey()
答案:D
第四章
一、填空题
1. Spark SQL是Spark用来____的一个模块。
2.Spark要想很好地支持SQL,就需要完成_____、优化(Optimizer )、_____三大过程。
3.Spark SQL作为分布式SQL查询引擎,让用户可以通过____、DataFrames API 和____3种方式实现对结构化数据的处理。
4.Catalyst优化器在执行计划生成和优化工作时离不开它内部的五大组件,分别是SQLParse、_____、Optimizer、_____和CostModel。
5.Dataset是从_____版本中引入的一个新的数据抽象结构,最终在_____版本被定义成Spark新特性。
答案
1.Spark SQL是Spark用来 处理结构化数据 的一个模块。
2.Spark要想很好地支持SQL,就需要完成 解析(Parser)、优化(Optimizer)、执行(Execution) 三大过程。
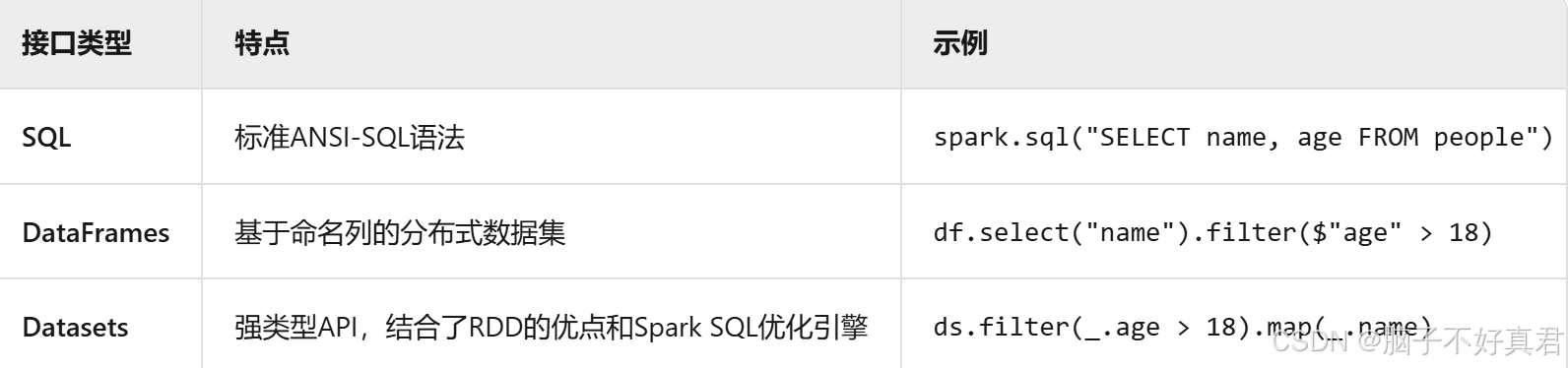
3.Spark SQL作为分布式SQL查询引擎,让用户可以通过 SQL、DataFrames API和Datasets API 三种方式实现对结构化数据的处理。
4.Catalyst优化器在执行计划生成和优化工作时离不开它内部的五大组件,分别是 SQLParse、Analyzer、Optimizer、Planner和CostModel 。
5.Dataset是从 Spark 1.6 Alpha 版本中引入的一个新的数据抽象结构,最终在 Spark 2.0 版本被定义成Spark新特性。
解析
1. Spark SQL模块定位
Spark SQL是Spark生态系统中专门用于结构化数据处理的核心模块,主要功能包括:
执行SQL查询
从结构化数据源(JSON/Hive/Parquet等)读取数据
与RDD/DataFrame/Dataset无缝集成
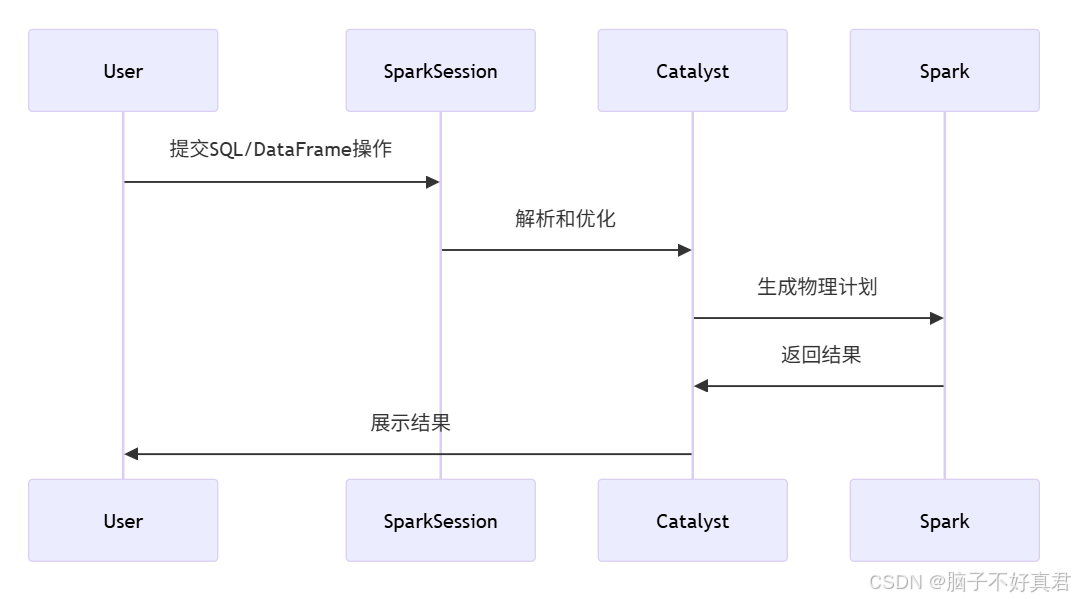
2. SQL处理三大阶段
Spark SQL查询处理流程:
解析:将SQL文本转为未解析的逻辑计划(Unresolved Logical Plan)
优化:应用Catalyst优化规则生成优化的逻辑计划
执行:转换为物理计划并生成RDD操作
3. 三种API接口
4. Catalyst优化器组件
核心组件功能:
SQLParse:语法解析,生成语法树
Analyzer:解析表和列,检查语义
Optimizer:应用优化规则(谓词下推/列剪枝等)
Planner:转换为物理执行计划
CostModel:基于代价选择最优计划
5. Dataset演进历史
版本演进:
Spark 1.3:引入DataFrame API
Spark 1.6:实验性引入Dataset API
Spark 2.0:统一DataFrame和Dataset,DataFrame = Dataset[Row]
二、判断题
1.Spark SQL的前身是Shark , Shark最初是瑞士洛桑联邦理工学院(EPFL)的编程方法实验室研发的Spark生态系统的组件之一。 ( )
2. Spark SQL与Hive不兼容。 ( )
3.在Spark SQL中,若想要使用SQL风格操作,则需要提前将DataFrame注册成一张临时表。 ( )
4.在Spark SQL中,可以利用反射机制来推断包含特定类型对象的Schema,从而将已知数据结构的RDD转换成DataFrame。 ( )
5.Spark SQL可以通过JDBC从关系数据库中读取数据的方式创建DataFrame,通过对DataFrame进行一系列的操作后,不可以将数据重新写入到关系数据库中。 ( )
答案
1.Spark SQL的前身是Shark,Shark最初是瑞士洛桑联邦理工学院(EPFL)的编程方法实验室研发的Spark生态系统的组件之一。 (×)
2.Spark SQL与Hive不兼容。 (×)
3.在Spark SQL中,若想要使用SQL风格操作,则需要提前将DataFrame注册成一张临时表。 (√)
4.在Spark SQL中,可以利用反射机制来推断包含特定类型对象的Schema,从而将已知数据结构的RDD转换成DataFrame。 (√)
5.Spark SQL可以通过JDBC从关系数据库中读取数据的方式创建DataFrame,通过对DataFrame进行一系列的操作后,不可以将数据重新写入到关系数据库中。 (×)
解析
5. JDBC数据源读写
完整JDBC集成流程:
(1) 从数据库读取
(2) 处理数据
(3) 写回数据库
Spark SQL核心架构执行流程
三、选择题
1.Spark SQL可以处理的数据源包括哪些?( )
A. Hive表
B. 数据文件、Hive表
C. 数据文件、Hive表、RDD
D. 数据文件、Hive表、RDD、外部数据库
答案:D
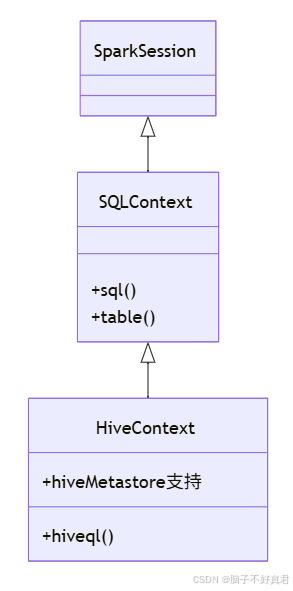
2.下列说法正确的是哪一项?( )
A . Spark SQL的前身是Hive
B . DataFrame其实就是RDD
C . HiveContext继承了SqlContext
D . HiveContext只支持SQL语法解析器
答案:C
3. Spark SQL中,mode函数可以接收的参数有哪些?( )
A . Overwrite、Append、Ignore、ErrorlfExists
B . Overwrite、Ignore
C . Overwrite、Append、Ignore
D . Append、Ignore、ErrorlfExists
答案:A
解析
1. Spark SQL数据源支持

2. Spark SQL架构理解
3. SaveMode参数详解

5.7课后习题
一、填空题
1.HBase是一个___、高性能、_____、可伸缩的分布式数据库。
2.HBase是构建在____之上,并为HBase提供了高可靠的底层存储支持。
3.HBase是通过_______协议与客户端进行通信。
4.HBase表的数据按照____的字典序进行排列。
5.当MemStore存储的数据达到一个阈值时,MemStore里面的数据就会被 flush 到StoreFile文件,这个阈值默认是_____。
答案
1.HBase是一个 高可靠、高性能、面向列、可伸缩 的分布式数据库。
2.HBase是构建在 HDFS 之上,并为HBase提供了高可靠的底层存储支持。
3.HBase是通过 RPC(远程过程调用) 协议与客户端进行通信。
4.HBase表的数据按照 行键(RowKey) 的字典序进行排列。
5.当MemStore存储的数据达到一个阈值时,MemStore里面的数据就会被flush到StoreFile文件,这个阈值默认是 128MB 。
解析
1. HBase基本特性
HBase的四大核心特性:

2. HBase与HDFS关系
HBase存储架构:
底层存储:依赖HDFS的分布式存储和冗余机制
数据文件:StoreFile最终以HFile格式存储在HDFS上
读写分离:
写入:先写WAL和MemStore
读取:合并MemStore和StoreFile数据
HDFS对HBase的支撑作用:
提供高可靠的数据存储
自动处理数据块复制
支持海量数据存储扩展
二、判断题
1. HBase 起源于2006年Google发表的BigTable论文。 ( )
2.HBase是基于行进行存储的。 ( )
3.HBase中,若有多个HMaster节点共存,则所有HMaster都提供服务。 ( )
4.StoreFile底层是以 HFile 文件的格式保存在 HDFS上。 ( )
5.在HBase中,往HBase写数据的流程就是一个寻址的流程。 ( )
答案
1.HBase起源于2006年Google发表的BigTable论文。 (√)
2.HBase是基于行进行存储的。 (×)
3.HBase中,若有多个HMaster节点共存,则所有HMaster都提供服务。 (×)
4.StoreFile底层是以HFile文件的格式保存在HDFS上。 (√)
5.在HBase中,往HBase写数据的流程就是一个寻址的流程。 (×)
三、选择题
1.下列选项中,哪个不属于 HBase 的特点?( )
A.面向列
B.容量小
C.多版本
D.扩展性
答案:B
2.下列选项中,HBase是将哪个作为其文件存储系统的?( )
A . MySQL
B . GFS
C . HDFS
D . MongoDB
答案:C
3.HBase官方版本不可以安装在什么操作系统上?( )
A . CentOS
B . Ubuntu
C . RedHat
D . Windows
答案:D
Scala——23道基础编程题
1. 输出素数
判断并输出101-200之间所有的素数,素数又叫质数,就是除了1和它本身之外,再也没有整数能被它整除的数。也就是素数只有两个因子。
// 定义一个名为 Prime 的单例对象
object Prime {// main 方法是程序的入口,接收命令行参数数组def main(args: Array[String]): Unit = {var n = 101 // 从 101 开始检查(题目要求找出 101~200 之间的素数)// 外层循环用于遍历 101 到 200 之间的所有整数while (n <= 200) {var isPrime = true // 假设当前数 n 是素数(初始设为 true)var i = 2 // 从 2 开始尝试是否能整除 n// 内层循环用于检测当前的 n 是否能被 2 到 n-1 的数整除while (i < n) {if (n % i == 0) { // 如果 n 能被 i 整除isPrime = false // 说明 n 不是素数}i += 1 // 检查下一个 i}// 如果 isPrime_sjl 仍然为 true,说明 n 是素数if (isPrime) {print(n + " ") // 输出该素数并加一个空格}n += 1 // 检查下一个数}println() // 换行,结束输出}
}
2. 输出“水仙花数”
打印出所有的"水仙花数",所谓"水仙花数"是指一个三位数,其各位数字立方和等于该数本身。例如:153是一个"水仙花数",因为153=1的三次方+5的三次方+3的三次方。
// 定义一个名为 shuixianhua 的单例对象
object shuixianhua {// main 方法是程序的入口def main(args: Array[String]): Unit = {var num = 100 // 从 100 开始,三位数的最小值// 外层循环,用于遍历 100 到 999 之间的所有三位数while (num <= 999) {// 提取百位、十位、个位数字val bai = num / 100 // 百位:例如 153 -> 1val shi = (num / 10) % 10 // 十位:例如 153 -> 5val ge = num % 10 // 个位:例如 153 -> 3// 计算每位数字的立方和val sum = bai*bai*bai + shi*shi*shi + ge*ge*ge// 如果立方和等于原数,说明是水仙花数if (sum == num) {println(num + "是水仙花数") // 输出水仙花数}num += 1 // 检查下一个数}}
}
3. 成绩等级输出
利用条件运算符的嵌套来完成此题:通过键盘输入某学生的学习成绩,如果学习成绩>=90分输出A,60-89分之间的输出B,60分以下的输出C。
import scala.io.StdInobject gradeChecker {def main(args: Array[String]): Unit = {println("请输入学生成绩:")val score = StdIn.readInt()val grade = if (score >= 90) "A"else if (score >= 60) "B"else "C"print("该学生的等级是:" + grade)}
}4. 求一个数的最大公约数和最小公倍数
输入两个正整数m和n,求其最大公约数和最小公倍数。
import scala.io.StdInobject gcdlcm {def main(args:Array[String]): Unit = {println("请输入第一个正整数:")val m = StdIn.readInt()println("请输入第二个正整数:")val n = StdIn.readInt()// 最大公约数var gcd = 1var i = if(m < n) m else n // 从较小的数开始while (i >= 1) {if (m % i == 0 && n % i == 0) {gcd = ii = 0 // 找到了就退出循环} else {i -= 1}}// 最小公倍数(用公式更高效)val lcm = (m * n) / gcdprintln("最大公约数是:" + gcd)println("最小公倍数是:" + lcm)}
}
5. 判断字符个数
输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数。
import scala.io.StdInobject charcounter {def main(args: Array[String]): Unit = {println("请输入一行字符:")val line = StdIn.readLine() // readLine()读取整行字符var letters = 0var spaces = 0var digits = 0var others = 0var i = 0while (i < line.length) {val ch = line.charAt(i) //charAt(i) 获取每个字符进行分类判断if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')) {letters += 1} else if (ch == ' ') {spaces += 1} else if (ch >= '0' && ch <= '9') {digits += 1} else {others += 1}i += 1}println("字母个数:" + letters)println("空格个数:" + spaces)println("数字个数:" + digits)println("其他字符个数:" + others)}
}
6. 求s=a+aa+aaa+aaaa+aa…a的值
求s=a+aa+aaa+aaaa+aa…a的值,其中a是一个数字。例如2+22+222+2222+22222,(此时共有5个数相加),几个数相加由键盘控制。
import scala.io.StdInobject SeriesSum {def main(args: Array[String]): Unit = {println("请输入一个数字 a:")val a = StdIn.readInt()println("请输入相加的项数 n:")val n = StdIn.readInt()var term = 0 // 每一项,例如 2, 22, 222...var sum = 0 // 总和var i = 1while (i <= n) {term = term * 10 + a // 生成下一项:2 → 22 → 222 ...sum += term // 累加到总和i += 1}println("最终结果是:" + sum)}
}
7. 求完数
一个数如果恰好等于它的因子之和,这个数就称为"完数"。例如6=1+2+3.编程 找出100以内的所有完数,并输出。
object PerfectNumber {def main(args: Array[String]): Unit = {// 输出提示信息println("100以内的完数有:")// 从 2 开始遍历到 100(1 不是完数)var num = 2while (num <= 100) {var sum = 0 // 用于累加因子的和var i = 1 // 因子从 1 开始判断// 遍历 num 之前的所有正整数,判断是否为 num 的因子while (i < num) {if (num % i == 0) { // 如果 i 能整除 num,说明 i 是 num 的因子sum += i // 将因子 i 累加到 sum 中}i += 1 // 继续判断下一个数}// 判断当前 num 是否为完数(因子和是否等于自身)if (sum == num) {println(num) // 如果是完数,输出这个数}num += 1 // 继续检查下一个数}}
}
8. 物理
一球从100米高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在第10次落地时,共经过多少米?
object BallBounce {def main(args: Array[String]): Unit = {var height = 100.0 // 初始高度var total = 0.0 // 总共经过的距离var i = 1while (i <= 10) {// 下落total += height// 第10次落地后不再反弹if (i != 10) {// 反弹一半height /= 2total += height}i += 1}println("第10次落地时共经过的距离是:" + total + " 米")}
}
9. 物理
一球从100米高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在第10次落地时的反弹多高?
object BallBounceHeight {def main(args: Array[String]): Unit = {var height = 100.0var i = 1while (i <= 10) {height /= 2 // 每次落地后反弹到原来的一半i += 1}println("第10次落地后的反弹高度是:" + height + " 米")}
}
10. 组合
有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?输出所有的可能。
object UniqueThreeDigitNumbers {def main(args: Array[String]): Unit = {var count = 0 // 用于统计符合条件的三位数个数// a 表示百位,取值 1~4var a = 1while (a <= 4) {// b 表示十位,取值 1~4var b = 1while (b <= 4) {// c 表示个位,取值 1~4var c = 1while (c <= 4) {// 判断三个数字是否互不相同if (a != b && b != c && a != c) {// 如果三个数字互不相同,则组成一个三位数并输出println(a * 100 + b * 10 + c)count += 1 // 每找到一个符合条件的数,计数加一}c += 1 // 个位数字递增}b += 1 // 十位数字递增}a += 1 // 百位数字递增}// 输出总共能组成的三位数数量println("总共可以组成 " + count + " 个不重复的三位数")}
}
11. 求一个数
一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?
object FindSpecialNumber {def main(args: Array[String]): Unit = {var x = 1 // 从 1 开始依次尝试所有可能的整数// 因为题目没有给出范围,这里设置一个较大的上限 100000,保证能找到解while (x <= 100000) {val a = math.sqrt(x + 100) // 计算 (x + 100) 的平方根val b = math.sqrt(x + 268) // 计算 (x + 100 + 168) 的平方根// 判断 a 和 b 是否均为整数// a == a.toInt 判断 a 是否是整数(没有小数部分)if (a == a.toInt && b == b.toInt) {println("这个数是:" + x) // 如果两个平方根都是整数,说明找到符合条件的数,输出结果}x += 1 // 尝试下一个整数}}
}
12. 判断某一天是这一年的第几天
输入某年某月某日,判断这一天是这一年的第几天?设一年有365天。
import scala.io.StdInobject DayOfYear {def main(args: Array[String]): Unit = {println("请输入年份:")val year = StdIn.readInt()println("请输入月份:")val month = StdIn.readInt()println("请输入日:")val day = StdIn.readInt()// 每月天数(默认非闰年)val daysInMonth = Array(31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31)//符合以下任一条件的是闰年:// (1)能被 4 整除且不能被 100 整除;(2)或者能被 400 整除。// 判断是否为闰年if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)) {daysInMonth(1) = 29 // 二月为29天}var sum = 0var i = 0while (i < month - 1) {sum += daysInMonth(i)i += 1}sum += dayprintln("这是这一年的第 " + sum + " 天")}
}
13. 三个数由小到大输出
输入三个整数x,y,z,请把这三个数由小到大输出。
import scala.io.StdInobject SortThreeNumbers {def main(args: Array[String]): Unit = {println("请输入第一个整数:")val x = StdIn.readInt()println("请输入第二个整数:")val y = StdIn.readInt()println("请输入第三个整数:")val z = StdIn.readInt()// 放入数组,排序val arr = Array(x, y, z)val sorted = arr.sorted // 排序好的数组println("从小到大的顺序是:")println(sorted.mkString(" "))}
}
14. 输出9*9口诀
输出9*9口诀。
object NineNineTable {def main(args: Array[String]): Unit = {var i = 1 // 外层循环控制行(乘法表的被乘数,从 1 到 9)while (i <= 9) {var j = 1 // 内层循环控制列(乘法表的乘数,从 1 到 i)while (j <= i) {// 输出乘法表达式,使用 \t 实现列对齐print(j + "×" + i + "=" + (i * j) + "\t")j += 1 // 内层乘数加 1}println() // 每完成一行,换行i += 1 // 外层被乘数加 1}}
}
15. 猴子吃桃
猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个 第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第10天早上想再吃时,见只剩下一个桃子了。求第一天共摘了多少。
object MonkeyPeach {def main(args: Array[String]): Unit = {var peach = 1 // 已知第10天早上只剩下1个桃子var day = 9 // 从第9天开始往前推,直到第1天while (day >= 1) {// 根据题目描述:每天剩下的桃子数 = (后一天的桃子数 + 1) * 2// 因为每天吃掉一半再多吃一个,所以倒推:peach = (peach + 1) * 2day -= 1 // 继续往前推前一天}// 输出结果:第一天摘的桃子总数println("第一天共摘了:" + peach + " 个桃子")}
}
16. 打印菱形图案
打印出如下图案(菱形),及其余各种典型图形。
*
***
******
********
******
***
*
object DiamondPattern {def main(args: Array[String]): Unit = {val n = 4 // 控制菱形上半部分的行数(中心行在第 n 行)// 打印菱形的上半部分(包括中间的最长一行)var i = 1 // i 表示当前行号,从 1 到 nwhile (i <= n) {val spaces = n - i // 每行前面的空格数(左侧补齐,控制居中)val stars = 2 * i - 1 // 每行要打印的星号数量print(" " * spaces) // 打印空格println("*" * stars) // 打印星号并换行i += 1}// 打印菱形的下半部分i = n - 1 // 下半部分从 n-1 行开始,逐行递减到 1 行while (i >= 1) {val spaces = n - i // 每行前面的空格数val stars = 2 * i - 1 // 每行的星号数量print(" " * spaces) // 打印空格println("*" * stars) // 打印星号并换行i -= 1}}
}
17. 斐波那契数列
有一分数序列:2/1,3/2,5/3,8/5,13/8,21/13…求出这个数列的前20项之和。
object FractionSeriesSum {def main(args: Array[String]): Unit = {var a = 2.0 // 分子起始var b = 1.0 // 分母起始var sum = 0.0var i = 1while (i <= 20) {sum += a / b// 下一项:斐波那契更新val temp = aa = a + b // 新的分子b = temp // 新的分母(原来的分子)i += 1}println("前20项的和是:" + sum)}
}
18. 求1+2!+3!+…+20!的和
求1+2!+3!+…+20!的和。
object FactorialSum {def main(args: Array[String]): Unit = {var sum = 0L // 总和(用 Long 防止溢出)var fact = 1L // 当前阶乘值var i = 1while (i <= 20) {fact *= i // 计算当前阶乘sum += fact // 累加到总和i += 1}println("1 + 2! + 3! + ... + 20! 的和是:" + sum)}
}// i = 1:
// fact = fact × 1 = 1
// sum = sum + fact = 0 + 1 = 1
// i = 2:
// fact = fact × 2 = 1 × 2 = 2
// sum = sum + fact = 1 + 2 = 3
// i = 3:
// fact = fact × 3 = 2 × 3 = 6
// sum = sum + fact = 3 + 6 = 9
// i = 4:
// fact = fact × 4 = 6 × 4 = 24
// sum = sum + fact = 9 + 24 = 33
// i = 5:
// fact = fact × 5 = 24 × 5 = 120
// sum = sum + fact = 33 + 120 = 153
// i = 6:
// fact = fact × 6 = 120 × 6 = 720
// sum = sum + fact = 153 + 720 = 87319. 递归求5!
利用递归方法求5!。
object FactorialRecursive {def main(args: Array[String]): Unit = {val result = factorial(5) // 调用递归函数计算 5!,结果赋值给 resultprintln("5! = " + result) // 输出结果}// 定义阶乘递归函数def factorial(n: Int): Int = {if (n == 1) 1 // 终止条件:当 n 等于 1 时,阶乘为 1(即 1! = 1)else n * factorial(n - 1) // 递归调用:n! = n × (n-1)!}
}// factorial(5)
// = 5 * factorial(4)
// = 5 * (4 * factorial(3))
// = 5 * (4 * (3 * factorial(2)))
// = 5 * (4 * (3 * (2 * factorial(1))))
// = 5 * 4 * 3 * 2 * 1
// = 120
20. 逆序输出
键盘输入一个不多于5位的正整数,输出其是几位数,并逆序打印出各位数字。
import scala.io.StdInobject ReverseDigits {def main(args: Array[String]): Unit = {println("请输入一个不多于5位的正整数:")val num = StdIn.readInt() // 从键盘读取一个整数// 判断输入是否合法(必须是 1 ~ 99999 范围内的正整数)if (num <= 0 || num > 99999) {println("输入不合法,请输入 1~99999 范围内的正整数。")return // 不合法则直接结束程序}// 先将整数转为字符串,再通过字符串长度计算出数字的位数val length = num.toString.length println("这是一个 " + length + " 位数")print("逆序输出:")var i = length - 1 // 从字符串的最后一位开始逆序遍历while (i >= 0) {print(numStr.charAt(i) + " ") // 取出当前位的字符并输出(中间加空格)i -= 1 // 继续往前一位}println() // 最后换行}
}
21. 判断回文数
键盘输入一个5位数,判断它是不是回文数。即12321是回文数,个位与万位相同,十位与千位相同。
import scala.io.StdInobject PalindromeCheck {def main(args: Array[String]): Unit = {println("请输入一个5位正整数:")val num = StdIn.readInt()if (num < 10000 || num > 99999) {println("输入不合法,请输入一个5位正整数")return}val numStr = num.toStringif (numStr.charAt(0) == numStr.charAt(4) && numStr.charAt(1) == numStr.charAt(3)) {println(num + " 是回文数")} else {println(num + " 不是回文数")}}
}
22. 字母判断星期几
请输入星期几的第一个字母来判断一下是星期几,如果第一个字母一样,则继续 判断第二个字母。
import scala.io.StdInobject WeekdayChecker {def main(args: Array[String]): Unit = {println("请输入星期的第一个字母:")val ch1 = StdIn.readLine().toUpperCase()ch1 match {case "M" => println("星期一")case "W" => println("星期三")case "F" => println("星期五")case "T" =>println("请输入第二个字母:")val ch2 = StdIn.readLine().toLowerCase()if (ch2 == "u") println("星期二")else if (ch2 == "h") println("星期四")else println("无法判断")case "S" =>println("请输入第二个字母:")val ch2 = StdIn.readLine().toLowerCase()if (ch2 == "a") println("星期六")else if (ch2 == "u") println("星期日")else println("无法判断")case _ =>println("无法判断")}}
}
23. 10个数排序
对键盘输入的10个数进行排序。
import scala.io.StdInobject SortNumbers {def main(args: Array[String]): Unit = {val numbers = new Array // 预先分配长度为10的数组,用于存储输入的10个数字var i = 0 // 循环控制变量,表示当前输入的是第几个数字// 使用 while 循环输入10个数字while (i < 10) {print(s"请输入第 ${i+1} 个数字: ") // 提示用户输入numbers(i) = StdIn.readDouble() // 读取一个 Double 类型的数字并存入数组i += 1 // 计数器加 1,准备输入下一个数字}// 对输入的数字进行排序val sortedNumbers = numbers.sortedprintln("排序后的数字:")sortedNumbers.foreach(println) // 遍历排序后的数组并输出每个数字}
}







![Could not get unknown property ‘mUser‘ for Credentials [username: null]](https://i-blog.csdnimg.cn/direct/0852140394b54004b03e5156941ddecd.png)

![[yolov11改进系列]基于yolov11引入空间通道系统注意力机制SCSA的python源码+训练源码](https://i-blog.csdnimg.cn/direct/b7c581c3983d4e458b1bf362aa181962.jpeg)