应用cnn对kaggle上的图像数据集进行练习
数据集地址:Cat and Dog
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import torch.optim as optim# 设置随机种子确保结果可复现
# 在深度学习中,随机种子可以让每次运行代码时,模型初始化参数、数据打乱等随机操作保持一致,方便调试和对比实验结果
torch.manual_seed(42)
np.random.seed(42)# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")数据预处理
# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 调整图像大小为224x224transforms.Resize((224, 224)),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4867, 0.4527, 0.4135), (0.2600, 0.2519, 0.2547))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.Resize((224, 224)), # 调整图像大小为224x224transforms.ToTensor(),transforms.Normalize((0.4867, 0.4527, 0.4135), (0.2600, 0.2519, 0.2547))
])# 2. 加载数据集
train_dataset = datasets.ImageFolder(root='./test_set', # 训练集图像所在的根目录transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.ImageFolder(root='./training_set', # 测试集图像所在的根目录transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)CNN模型的定义
# 4. 定义CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(224x224→112x112)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:112x112→112x112(卷积后)→56x56(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:112x112→56x56# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:56x56→56x56(卷积后)→28x28(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:56x56→28x28# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 28x28尺寸 = 128×784=100352维self.fc1 = nn.Linear(in_features=128 * 28 * 28, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到2个类别(类别数)self.fc2 = nn.Linear(in_features=512, out_features=2)def forward(self, x):# 输入尺寸:[batch_size, 3, 224, 224](batch_size=批量大小,3=通道数,224x224=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 224, 224](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 112, 112](224→112是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 112, 112](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 56, 56]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 56, 56](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 28, 28]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*28*28] = [batch_size, 100352]x = x.view(-1, 128 * 28 * 28) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:100352→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→2,尺寸变为[batch_size, 2](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)训练模型
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 5 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")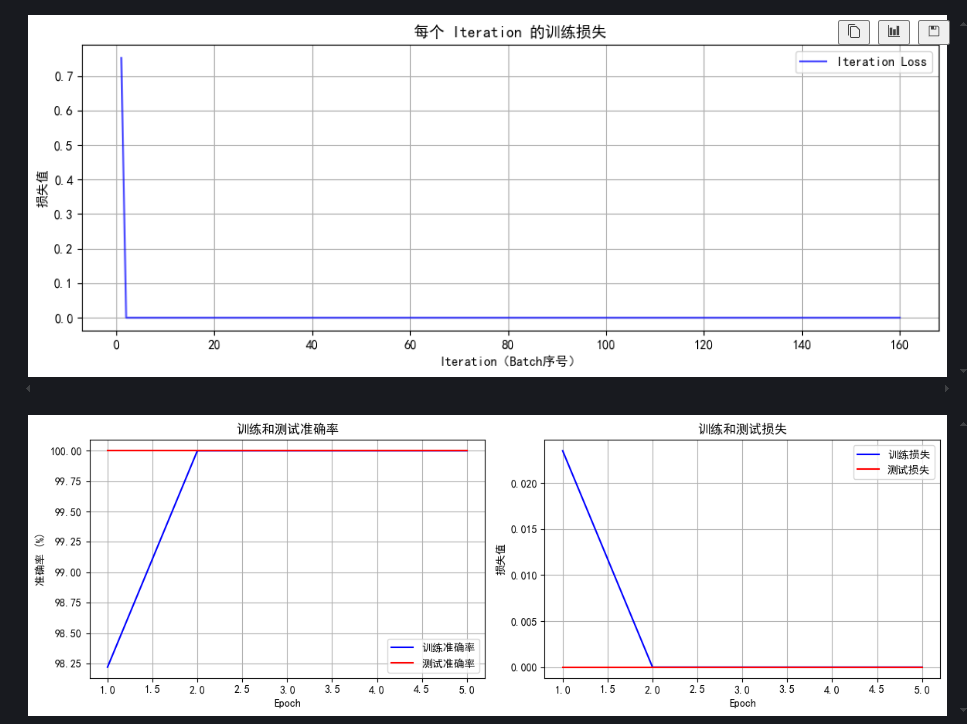
Grad-CAM实现
# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(32x32),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_class热力图
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 选择一个随机图像
idx = 50 # 选择测试集中的第101张图片 (索引从0开始)
image, label = test_dataset[idx]# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.4867, 0.4527, 0.4135])std = np.array([0.2600, 0.2519, 0.2547])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv3)# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可视化
plt.figure(figsize=(12, 4))# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像")
plt.axis('off')# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()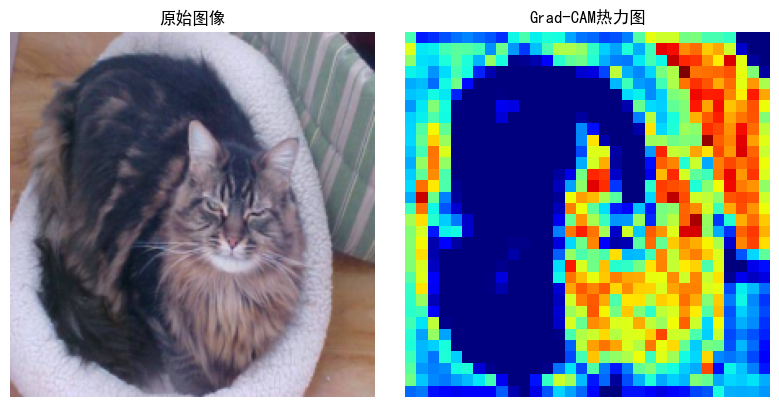
@浙大疏锦行