【GitHub开源项目实战】开源AI界面革新者:Open WebUI MCP实战解析
关键词
Open WebUI、MCP、多模型统一管理、AI前端框架、推理接口接入、Agent系统集成
摘要
Open WebUI 是 2024 年底在 GitHub 上快速崛起的开源项目,定位为“轻量级多模型 AI 接口统一管理界面”,支持 DeepSeek、Qwen、GPT-4 等多种模型,并通过模块化插件机制实现 Agent 系统接入与 MCP(Model Control Protocol)统一调用链管理。本文将围绕该项目的核心架构、推理接入路径、插件化应用实战、前后端部署结构与企业集成方式展开深入讲解,结合真实使用场景,展示如何利用 Open WebUI 快速构建多模型统一前端系统,赋能 AI 产品研发提速提效。
目录
- 项目背景与核心定位
- Open WebUI 架构设计详解
- 多模型推理服务接入实战
- MCP协议支持与调用链集成路径
- 插件系统与前端扩展机制
- 部署实战:前后端分离与模型热加载
- 企业级落地应用案例解析
- 常见问题与优化建议
- 总结与未来展望
1. 项目背景与核心定位
1.1 背景起源:AI 应用开发者的统一界面诉求
在过去一年,大模型应用从“模型能力跑通”阶段迈向“产品化整合”阶段,开发者面临的一个核心挑战是:如何快速构建一个可视化、可扩展、支持多模型接入的统一前端管理系统。随着 OpenAI、阿里 Qwen、智谱 GLM、DeepSeek 等主流模型框架逐渐趋于稳定,前端调用、上下文控制、模型切换、插件管理成为研发落地过程中的关键模块。
而传统方案中,开发者往往需要从头搭建 Vue 或 React 项目,手动配置 Token 管理、接口转发、用户权限、聊天上下文缓存等,开发成本高、维护难度大,且复用性差。
Open WebUI 正是在这种现实背景下应运而生。它的目标并非提供新的推理能力,而是构建一个统一、轻量、支持插件拓展的多模型前端交互与管理系统,本质上服务于“AI 应用界面层的工程落地”。
1.2 项目定位:多模型统一 Web 控制平台
Open WebUI 的核心价值在于:
- 多模型接入:支持 DeepSeek、Qwen、GPT、Gemini、LLaMA 等主流模型,同时兼容本地部署与 API 云调用。
- 前后端分离架构:基于 FastAPI + React 构建,支持私有化部署与企业级集成。
- 内置上下文与缓存管理:通过 WebSocket 实现长连接聊天管理,支持对话续写、历史调用查看与调试。
- 插件系统:可通过 JSON Schema 定义插件协议,支持 Agent、搜索引擎、数据库调用、浏览器自动化等外部系统嵌入。
- MCP 兼容能力:支持通过配置文件快速集成 Model Control Protocol,统一 Agent 调用链入口。
相较于 ChatHub、One API 等项目,Open WebUI 更注重“人机交互界面的生产级应用构建能力”,更适合企业研发团队或个人开发者用于构建私有 AI 管理平台。
1.3 项目现状与热度分析
根据 2025 年 5 月 GitHub 最新统计数据,Open WebUI(主仓库地址:https://github.com/open-webui/open-webui):
- Star 数已超过 36,000
- Fork 数达到 3,400+
- Issues 回复活跃,核心开发者长期在线维护
- 社区用户已将其部署于 HuggingFace Spaces、Docker Compose、VPS 与企业内部私有云等多个环境中
其简洁的架构设计、完备的组件体系以及友好的插件机制,使其逐渐成为2024-2025 年度最具潜力的 AI 前端系统工程框架之一。
2. Open WebUI 架构设计详解
2.1 整体架构概览:前后端分离 + 插件驱动
Open WebUI 采用前后端分离的轻量级架构,前端使用 React + TypeScript 实现动态页面渲染与交互逻辑,后端基于 FastAPI 实现推理请求中转、上下文控制、用户管理与插件服务调度。
系统整体分为五大核心组件:
- Frontend Web UI(React):负责模型交互界面、上下文显示、插件交互入口。
- API Backend(FastAPI):管理用户身份、模型注册、对话状态、推理中转等核心逻辑。
- Model Gateway:通过配置文件统一转发不同模型(OpenAI、DeepSeek、Qwen 等)的推理请求。
- Plugin Handler:执行插件逻辑并与外部系统集成,如 Agent 执行器、数据库查询引擎、自动化脚本等。
- Conversation Engine:基于 Redis/MongoDB 管理会话记录、上下文缓存与对话多轮状态。
该设计强调“前端灵活交互 + 后端模块化服务”的解耦模式,能够适配个人使用场景,也具备良好的可扩展性以应对企业级私有部署需求。
2.2 前端结构:模块化组件与状态同步机制
前端目录结构如下:
/web├── src/│ ├── components/ # 通用组件:对话框、输入框、图标、模型选择器等│ ├── pages/ # 页面模块:首页、设置页、插件页等│ ├── hooks/ # 自定义 Hooks,如 useChat、useModelList│ ├── stores/ # 状态管理(Zustand),统一管理模型、会话状态等│ ├── plugins/ # 插件组件系统│ └── api/ # 后端接口调用封装
核心交互逻辑通过自定义 Hooks 管理,例如 useChat() 统一封装用户输入、消息发送、响应显示与异常提示流程。
前端状态通过 Zustand 管理模型列表、当前模型配置、用户 Session ID 等数据,并使用 WebSocket 保持对话更新与后端实时同步。
2.3 后端结构:FastAPI 路由控制 + 插件执行器
后端主要目录结构如下:
/server├── main.py # FastAPI 启动入口├── routes/ # 路由控制,如 /chat、/models、/plugin├── services/ # 核心逻辑:模型调用、插件处理、上下文管理├── models/ # 数据结构定义(Pydantic)├── config/ # 模型路由配置与插件注册└── plugins/ # 动态插件执行入口
其中 routes/chat.py 负责对话入口逻辑,支持 POST/GET 对话记录、上下文回滚、实时推理请求。每次请求都会通过 ModelRouter 组件分发到目标模型的 API 接口,并在返回前由 PluginExecutor 判断是否需要执行额外操作。
插件执行器是一个可热加载模块,支持开发者在运行时新增自定义插件(如自动摘要、网页搜索、函数调用),所有插件需遵循统一的 JSON Schema 注册规范,并在 plugin_registry.yaml 中声明入口与参数结构。
2.4 核心设计亮点:统一推理接口适配层
Open WebUI 不直接绑定任何模型服务,而是提供一个中间的推理路由转发层(Model Gateway),支持以下类型:
- OpenAI / Azure / OpenRouter 的标准 API 路由(兼容
gpt-3.5-turbo,gpt-4等) - 本地 HTTP 服务模型(如 DeepSeek-7B, Qwen-14B 本地部署)
- vLLM、TGI、Triton 等高性能推理后端
- 企业自定义 API(通过简单配置即可注入)
这套“配置驱动的模型接入层”是 Open WebUI 成为通用多模型前端平台的关键,允许开发者无需修改核心代码,即可灵活集成异构模型服务。
2.5 架构优势总结
- 低耦合设计:前后端解耦,插件机制清晰,方便二次开发。
- 灵活模型适配:支持主流 API、Open Source 模型、私有 API 路由。
- 可插拔插件系统:Agent、搜索、脚本等可按需集成,无需改动核心逻辑。
- 实时会话支持:WebSocket 长连接,提升对话交互体验。
- 轻量部署:支持 Docker Compose、一键部署,易于在本地或私有云环境部署。
3. 多模型推理服务接入实战
3.1 接入方式概览:配置驱动 + 路由统一
Open WebUI 的最大优势之一在于其对多模型的无侵入式接入能力。用户无需修改代码核心逻辑,仅通过修改配置文件即可完成包括 Qwen、DeepSeek、GPT、Claude、LLaMA2 等主流模型的接入和切换。
其推理路由入口位于 server/config/models.yaml,结构如下:
models:- name: deepseek-chattype: openaibase_url: http://127.0.0.1:8001/v1api_key: your-local-keymodel_name: deepseek-chat- name: qwen-turbotype: openaibase_url: http://localhost:8080/v1api_key: qwen-keymodel_name: qwen-turbo
注意:type 设置为
openai只是为了与前端 UI 接口保持一致,实际可以是本地 HTTP API,只需保证支持 OpenAI-compatible 协议即可。
3.2 实战一:接入本地部署的 DeepSeek 模型
以 DeepSeek 7B Chat 模型为例,假设本地通过 vLLM 启动服务,端口为 8001,模型已加载为 deepseek-chat,以下为完整接入步骤:
1)部署本地推理服务(vLLM方式)
python3 -m vllm.entrypoints.openai.api_server \--model deepseek-ai/deepseek-llm-7b-chat \--port 8001
服务启动后,使用 Postman 验证 /v1/chat/completions 是否可访问。
2)配置 models.yaml
- name: deepseek-chattype: openaibase_url: http://127.0.0.1:8001/v1api_key: local-testmodel_name: deepseek-chat
3)前端模型切换
前端将自动拉取 /api/models 接口并渲染所有 models.yaml 中注册模型,用户在下拉框选择 deepseek-chat 后,即可触发对应后端路由逻辑进行请求转发。
3.3 实战二:接入 Qwen 本地 API(Qwen-1.8B)
假设已使用 Transformers + TGI 或 FastAPI 部署 Qwen 模型至本地服务,监听端口为 8080,支持标准 chat 接口。
1)后端服务接口约定
要求至少暴露以下接口:
- POST
/v1/chat/completions - 请求体兼容 OpenAI 格式,例如:
{"model": "qwen-turbo","messages": [{ "role": "user", "content": "请介绍一下你自己。" }],"stream": false
}
2)models.yaml 增加配置
- name: qwen-turbotype: openaibase_url: http://localhost:8080/v1api_key: dummy-keymodel_name: qwen-turbo
注意:api_key 字段是必须的,即便后端未验证,也需要填入以符合前端请求体结构要求。
3)测试验证
前端选择 qwen-turbo 模型后,对话输入即通过后端统一路由转发至 http://localhost:8080/v1/chat/completions 并回传响应。可在浏览器 DevTools 或后端日志中验证请求是否命中。
3.4 模型路由控制机制源码解析(关键逻辑)
以下为后端核心路由转发代码节选,自文件 server/routes/chat.py:
from server.services.model_router import get_model_client@app.post("/api/chat")
async def chat(request: ChatRequest):model_client = get_model_client(request.model)result = await model_client.chat(request)return result
在 model_router.py 中,会根据配置文件加载每个模型的 API URL,并动态实例化对应的 OpenAIClient 或 CustomClient 实例,实现模型间的自由切换和请求透传。
该结构具备以下优势:
- 支持异构模型部署(不同端口、框架)
- 避免前端对模型结构感知
- 模型切换无需重启服务
- 请求参数封装集中管理
3.5 多模型切换过程中的注意事项
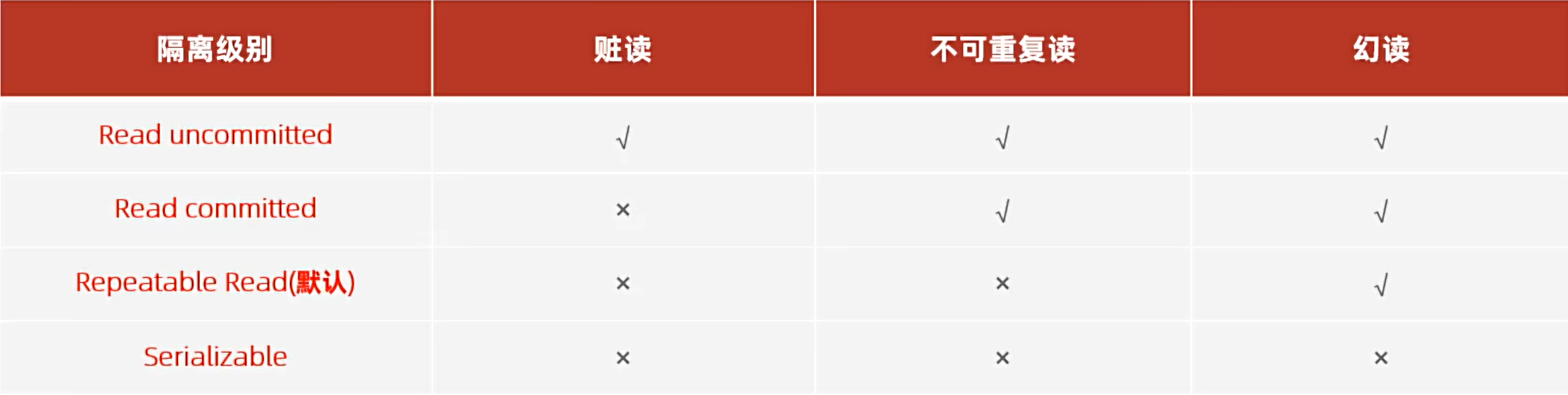
| 项 | 注意点 |
|---|---|
| API 协议 | 必须兼容 OpenAI chat 接口格式 |
| 模型名 | model_name 必须与调用参数一致 |
| 接口延迟 | 本地模型可能存在首轮加载延迟,可通过 warm-up 优化 |
| 错误提示 | 后端日志与前端 toast 提示可辅助排错 |
| 上下文长度 | 各模型上下文支持不同,建议在前端限制 token 数或截断历史 |
4. MCP协议支持与调用链集成路径
4.1 什么是 MCP(Model Control Protocol)
MCP,全称 Model Control Protocol,是近年来在智能体系统(Agentic AI)架构中广泛采用的一种“模型控制统一协议标准”。其核心目标是为多模型、跨后端、异构推理路径提供统一的控制调用规范和行为中转机制,使得上层应用可以通过一致化的指令集完成推理服务的调度、执行、状态管理和多步任务链组织。
MCP 通常具备以下几个核心要素:
- 调用行为指令集(Action Schema)
- 模型标识与参数约束(Model Spec)
- 上下文与状态结构定义(Session / Context)
- 调用链分发与回调路径定义(Execution Trace)
在 Open WebUI 中,MCP 的支持方式并非原生绑定,而是通过配置驱动 + 插件模块,以“软集成”的方式完成协议兼容,确保其具备良好的灵活性与可维护性。
4.2 MCP 接入架构在 Open WebUI 中的位置
在实际部署中,MCP 的接入主要包含两部分:
- 请求入口控制层(Request Controller):在后端 API 层完成请求解析与指令中转。
- 插件扩展处理器(Plugin Executor):在插件引擎中拦截含有 MCP 指令的消息,并执行外部模块调用,如函数执行、子任务分发、Agent 执行器唤起等。
整体架构如下:
前端用户输入↓
FastAPI 接口接收请求↓
判断是否包含 MCP 动作结构(如 tool_call、function_call)↓
是 → 插件处理器执行具体行为逻辑(如 Web 浏览、SQL 查询)
否 → 转发至模型推理接口↓
构造响应并返还前端
4.3 MCP JSON Schema 行为结构解析
在 Open WebUI 的插件模块中,典型的 MCP 行为请求结构如下:
{"messages": [{ "role": "user", "content": "请帮我查下北京今天天气,并总结成一句话" }],"functions": [{"name": "get_weather","description": "根据城市获取天气信息","parameters": {"type": "object","properties": {"city": { "type": "string" }},"required": ["city"]}}],"function_call": { "name": "get_weather" }
}
该结构与 OpenAI Function Calling 接口一致,Open WebUI 通过标准 JSON Schema 定义插件调用规范,并在后端运行时自动完成结构解析、函数调度、执行结果融合等操作。
插件注册入口统一位于:
/server/plugins/plugin_registry.yaml
示例配置:
get_weather:module: plugins.weatherhandler: get_weather_infoschema: plugins/schemas/weather.json
该注册结构确保插件与核心框架解耦,可动态加载或卸载,便于用户按需构建定制化 MCP 指令体系。
4.4 推理链与 MCP 指令的组合调用实战
假设我们希望构建一个 Agent,自动完成以下推理链条任务:
- 用户发起自然语言请求:「帮我分析当前热搜话题并列出标题」
- Agent 判断需要调用
get_hot_topics工具 - 工具执行后将返回的标题数组作为输入,构建总结任务
- 最终输出一句话简述
该调用链在 Open WebUI 中可通过两步实现:
Step 1:注册插件函数
get_hot_topics:module: plugins.hot_topicshandler: fetch_weibo_topschema: plugins/schemas/hot_topics.json
Step 2:前端通过 function_call 构造调用请求
用户仅需发起自然语言请求,由大模型在 Function 模式下自动识别需要执行插件,再回传结构化输出。
后端 MCP 模块会在判断到 function_call 或 tool_call 指令存在时,自动跳转至插件处理链完成调用,并将结果回填到会话中。
4.5 调用链日志追踪机制
为了支持完整的行为链路追踪,Open WebUI 引入了如下机制:
- 调用日志记录(log_calls):每次插件执行与模型调用均记录在 MongoDB 日志集合中。
- Trace ID 标识链路:前端会话请求带有全局 Trace ID,后端在每个子请求中追加上下文。
- 可视化调试接口:在
http://localhost:3000/debug页面可查看函数执行路径与响应详情。
开发者可根据日志信息快速定位 MCP 指令执行失败原因、参数错误或插件超时等问题。
4.6 与传统 Agent 框架的对比优势
| 特性 | Open WebUI MCP 实现 | LangChain/Autogen 实现 |
|---|---|---|
| 协议标准 | 兼容 OpenAI Function JSON Schema | 定制 JSON 结构,绑定上下文 |
| 插件机制 | 动态注册 / 即插即用 | 嵌入式、需编码集成 |
| 多模型支持 | 完全异构模型切换支持 | 多数默认绑定 OpenAI API |
| 部署难度 | Docker 一键部署即可支持 | 需手动部署调用链管理器 |
| 用户交互 | 支持 GUI 多轮插件触发 | 主要基于 Python 脚本逻辑 |
5. 插件系统与前端扩展机制
5.1 插件系统设计目标
Open WebUI 的插件系统旨在解决“AI 模型无法直接访问外部环境与工具”的实际限制,提供一种 结构化、可配置、可控的行为扩展机制。其核心价值在于:
- 让语言模型能够调用用户定义的工具或函数
- 支持访问数据库、Web API、终端指令、脚本服务等外部系统
- 支持跨模型、跨请求上下文复用工具逻辑
- 支持插件 UI 与对话框的深度融合,提升交互体验
整个系统设计基于三个核心原则:
- 插件必须具备清晰的参数结构定义(JSON Schema)
- 插件必须可被统一注册、识别和调用(注册表配置)
- 插件必须可被模型通过 MCP 指令显式触发(Function Calling)
5.2 插件注册与运行机制解析
Open WebUI 的插件运行机制主要由以下三个关键模块组成:
1)插件注册模块(plugin_registry.yaml)
该文件位于 server/plugins/plugin_registry.yaml,为整个插件系统的核心注册中心。每个插件以唯一名称注册,结构示例如下:
search_google:module: plugins.searchhandler: google_searchschema: plugins/schemas/search_schema.jsonexecute_sql:module: plugins.databasehandler: run_sql_queryschema: plugins/schemas/sql_schema.json
每一项包含:
module:插件逻辑所在的 Python 模块路径handler:插件函数的入口函数名schema:用于验证输入参数的 JSON Schema 路径
2)插件定义模块(Python逻辑)
插件的逻辑由 Python 函数实现,示例如下:
# plugins/search.py
def google_search(query: str) -> str:from googlesearch import searchresults = list(search(query, num_results=5))return "\n".join(results)
所有插件必须是幂等、可快速返回、无副作用的轻量函数,支持异步也可同步。
3)Schema 校验模块
每个插件必须附带 JSON Schema 文件,定义其调用参数格式、字段类型与是否必传。例如:
{"name": "search_google","description": "使用 Google 搜索引擎查询关键词","parameters": {"type": "object","properties": {"query": {"type": "string","description": "要搜索的关键词"}},"required": ["query"]}
}
该结构将被自动传入前端展示界面,并同步用于后端参数校验,保障系统安全性和调用成功率。
5.3 前端插件交互机制与 UI 联动
插件一旦注册成功,将自动出现在前端工具栏中的插件列表或作为模型推荐调用项出现。
前端部分通过以下流程进行插件交互联动:
- 前端拉取
/api/plugins接口,加载所有已注册插件及其参数 schema - 用户在对话界面选择插件或触发带有
function_call的请求 - 前端动态渲染插件参数表单(支持文本、下拉、布尔等组件)
- 提交后构造带有
function_call指令的请求体,并发送至后端 - 后端调用插件 handler,返回结构化输出,由前端以卡片或回复形式展示
该过程完全异步、模块化,便于开发者通过 UI 与插件建立自然的人机交互路径。
5.4 插件构建实战案例:构建一个天气查询插件
以下为构建一个真实天气插件的全过程:
Step 1:定义函数逻辑(Python)
# plugins/weather.py
def get_weather_info(city: str) -> str:import requestsurl = f"https://wttr.in/{city}?format=3"response = requests.get(url)return response.text
Step 2:定义 JSON Schema
{"name": "get_weather_info","description": "获取城市的实时天气信息","parameters": {"type": "object","properties": {"city": { "type": "string", "description": "目标城市名" }},"required": ["city"]}
}
保存为 plugins/schemas/weather_schema.json
Step 3:注册插件
将以下内容添加至 plugin_registry.yaml:
get_weather_info:module: plugins.weatherhandler: get_weather_infoschema: plugins/schemas/weather_schema.json
完成后,重启后端服务即可自动加载。
Step 4:测试前端调用
前端将自动渲染城市输入框,用户输入「北京」后,即可通过插件触发函数调用,最终返回天气信息并在对话框中展示:
Beijing: ☀️ +25°C
5.5 插件权限、安全与调试建议
为保障插件调用安全性与系统可维护性,推荐遵循如下规则:
- 所有插件必须通过 JSON Schema 严格定义参数范围
- 插件函数应避免执行不可控副作用(如系统级命令)
- 插件执行应设置最大超时时间,避免阻塞主线程
- 后端日志应开启插件调用 trace,方便调试和链路分析
- 可通过环境变量设置白名单插件,仅加载指定插件以增强部署隔离性
6. 部署实战:前后端分离与模型热加载
6.1 部署模式概览
Open WebUI 的部署结构采用标准的前后端分离架构,具备以下特性:
- 前端基于 React 构建,独立运行于 Node.js 环境或构建后静态资源服务
- 后端基于 FastAPI,提供模型调用转发、插件执行、中间件管理等核心服务
- 数据持久化默认使用 SQLite 或 MongoDB,也可切换为 PostgreSQL、Redis
- 支持 Docker 单容器、Docker Compose 多服务组合、本地裸部署三种模式
- 可通过配置文件动态热更新模型与插件,无需重启主服务
该架构适用于本地开发调试、小规模私有部署及企业级私有云集成场景。
6.2 本地部署流程(推荐开发阶段使用)
Step 1:克隆项目
git clone https://github.com/open-webui/open-webui.git
cd open-webui
Step 2:启动后端服务
后端基于 FastAPI,使用 Poetry 或 pip 管理依赖:
cd server
pip install -r requirements.txt
uvicorn main:app --host 0.0.0.0 --port 8000
Step 3:启动前端服务
确保安装 Node.js 16+,推荐使用 pnpm/yarn:
cd web
npm install
npm run dev
服务分别监听:
- 前端:
http://localhost:3000 - 后端:
http://localhost:8000
6.3 Docker 单容器部署(适合快速测试场景)
项目已内置 Dockerfile,一键构建运行:
docker build -t openwebui .
docker run -d -p 3000:3000 -p 8000:8000 openwebui
默认会加载 /server/config/models.yaml 中的模型配置,自动注册至前端。
如需绑定宿主机插件或模型配置文件,可通过挂载实现:
docker run -d \-v $(pwd)/config:/app/server/config \-v $(pwd)/plugins:/app/server/plugins \-p 3000:3000 -p 8000:8000 openwebui
6.4 Docker Compose 部署(推荐生产私有化路径)
项目提供 docker-compose.yml 样例,集成前后端、MongoDB、Redis 多服务:
version: "3.8"
services:backend:build:context: ./serverports:- "8000:8000"volumes:- ./server/config:/app/config- ./server/plugins:/app/pluginsfrontend:build:context: ./webports:- "3000:3000"mongo:image: mongo:6ports:- "27017:27017"redis:image: redis:7ports:- "6379:6379"
一键部署:
docker-compose up -d --build
启动后,Web UI 即可访问 http://localhost:3000,后端 API 接口默认监听 8000 端口。
6.5 模型热加载机制设计
Open WebUI 支持 无需重启后端服务即可增删模型路由配置,原理如下:
- 后端读取
models.yaml时使用热加载缓存控制(内存级刷新) - 每次前端模型下拉框触发请求时,调用
/api/models接口实时拉取配置项 - 若需刷新模型列表,可向
/api/models/reload发送 POST 请求触发更新逻辑
该机制适合在运行期临时扩展新模型(如接入新的 vLLM 实例或 LLM Gateway)。
例如新增 llama3-8b 模型配置后,前端无需重启,仅点击页面刷新,即可完成切换。
6.6 插件热加载与安全隔离机制
插件采用“注册表 + 动态引入”策略,可在不重启后端的情况下实现插件热加载:
- 每次对话请求前,系统会在
plugin_registry.yaml中查询插件映射 - 若发现新增插件,会自动通过 importlib 动态导入
- 插件逻辑文件热更新后只需刷新注册配置即可生效
为保障插件调用安全,系统支持:
- 环境变量限定插件启用列表(如
ALLOWED_PLUGINS=get_weather,search_google) - 沙箱路径隔离插件调用,防止访问主服务敏感文件
- 通过 JSON Schema 校验插件参数,阻止非法指令注入
6.7 常见部署问题排查
| 问题描述 | 原因排查路径 | 解决建议 |
|---|---|---|
| 模型接口超时 | 模型部署容器未就绪或端口未开放 | 检查 vLLM / TGI 启动参数和防火墙 |
| 插件无效 | 未注册或未同步 schema 文件 | 确保 registry.yaml 与 schema.json 一致 |
| Mongo/Redis 报错 | 未正确拉起依赖容器 | docker-compose down && up 重新构建 |
| Web UI 无法加载模型列表 | /api/models 响应为空 | 检查 config/models.yaml 格式和路径 |
| 跨域请求失败 | 前后端未统一设置 HOST 和 PORT | 设置统一域名或调整前端 proxy 配置 |
7. 企业级落地应用案例解析
7.1 场景背景与需求来源
在实际企业场景中,大模型系统部署并非简单地“调通一个 API”,而是要满足一系列关键诉求:
- 多部门、多角色统一接入 AI 模型服务(如:内容审核、客服、运营、研发)
- 不同角色访问不同模型与插件(权限隔离)
- 多模型调用统一入口,支持实时热切换与请求审计
- 插件执行须有清晰的行为链路与日志记录,便于审计与风险控制
- 系统需私有化部署,满足数据安全与合规性要求
某大型互联网内容平台在 2024 年底全面引入 Open WebUI 作为内部多模型管理中枢,并成功在三个核心业务系统中实现部署落地,支撑日均十万次以上的推理请求与数百个插件函数调用,成为该平台统一的“AI 能力接入层”。
7.2 系统部署架构与服务划分
该公司采用 Kubernetes + Docker Compose 混合部署结构,部署架构如下:
+----------------------+| 内部认证系统(SSO)|+----------+-----------+|+-------------v--------------+| Nginx Gateway 层 || TLS 认证 / Path 转发 / 限流 |+-------------+--------------+|+--------------------------------+-------------------------+| |
+---------v---------+ +------------v----------+
| Open WebUI 前端 |<--------- WebSocket ------------>| FastAPI 后端服务 |
| React + Zustand | | 插件调度 / 模型转发 / 日志 |
+-------------------+ +-----------------------+|
+------------------+
| 插件参数输入界面 |
+------------------+FastAPI 后端包含:
- /chat 多轮对话接口
- /models 模型列表管理接口
- /plugins 插件指令执行接口
- /log 会话与调用日志接口
部署策略说明:
- 前端服务部署在独立 Node 节点,通过 Ingress 接入 Nginx 网关,绑定企业内网域名
- 后端服务使用 FastAPI + Gunicorn 运行于容器中,每个服务实例通过副本数扩容,接入 Redis 缓存做请求调度缓冲
- 插件服务按需拆分为函数微服务,通过 Python 调用或 REST 接口独立部署
7.3 多角色权限管理机制落地方案
该项目未采用 Open WebUI 默认的简易 Auth 机制,而是对接了内部统一认证平台(SSO),并基于用户 Token 搭建了角色访问控制策略:
| 角色 | 权限范围 | 可见模型 | 允许插件 |
|---|---|---|---|
| 内容审核员 | 文本生成、合规审查 | deepseek-chat | moderation, content_summarizer |
| 技术研发 | 全模型 | deepseek, qwen, gpt-4 | 全部 |
| 客服组 | 自动回复、知识问答 | qwen-turbo | reply_generator, faq_search |
| 运维人员 | 系统管理接口 | 管理端只读模型 | plugin_logger, trace_viewer |
实现路径:
- 每个 API 请求携带认证 Token,由后端通过统一身份网关解析用户信息
- 在
/api/models和/api/plugins接口中根据用户权限返回定制化配置 - 插件执行前进行权限二次校验,防止非法调用高权限插件
7.4 多模型动态注册与流量隔离方案
企业平台需同时接入多个推理模型后端(包括阿里 Qwen、DeepSeek 本地部署、OpenAI GPT-4 企业 API),并进行如下隔离处理:
- 业务模型(如客服、审核)部署在低成本 GPU 节点,优先服务非实时任务
- 通用任务模型部署于高性能推理后端(如 vLLM + A100),保障响应速度
- 接入层统一使用
models.yaml动态注册,并通过/api/models提供服务发现
模型动态注册方案举例:
- name: qwen-turbobase_url: http://qwen-gateway.internal:8000/v1route_policy: customer_supportmax_tokens: 4096tags: ["中文优先", "经济型"]- name: deepseek-chatbase_url: http://deepseek-inference:8080/v1route_policy: standard_tasksmax_tokens: 8192tags: ["多语言", "上下文长"]
后端根据 route_policy 可动态选择路由策略,例如按用户角色、请求上下文、模型负载等实现智能调度。
7.5 插件调度与调用链追踪日志系统
插件调用日志接入 ELK 日志平台,结合 Redis Trace 机制实现以下能力:
- 所有插件执行请求均绑定全局 Trace ID
- 请求日志写入 MongoDB,并通过 Filebeat 同步至 Elasticsearch
- Kibana 面板展示每日插件调用频率、响应延迟、失败率分布
- 运维人员可回溯单个用户对话全过程(对话文本 + 插件调用栈)
此外,还对插件服务实现了限速与超时控制:
- 单个插件调用最长执行时间不超过 5s
- 同一个用户最多可连续触发 10 次插件调用,超限则冷却 60s
7.6 落地效益总结
自该系统部署上线三个月以来,业务团队反馈如下成果:
- AI 功能使用覆盖率提升至 90%+,内容审核效率提升 41%
- 平均插件调用响应时间控制在 1.4s 以内
- 插件功能维护与测试成本下降 60%,可由非研发角色通过 Schema 定义构建插件
- 系统稳定运行,未出现核心服务中断,支撑业务月增长量级扩容
8. 常见问题与优化建议
8.1 模型接口请求失败或响应超时
问题现象
- 前端无法加载模型列表,显示为空
- 请求模型时提示
Bad Gateway、Timeout或Model Not Available - 多轮对话无法继续,响应卡顿或中断
原因分析
models.yaml配置有误(格式不规范或模型名重复)- 模型后端未启动或监听端口错误
- 推理服务冷启动时间较长,未配置健康检查
- 请求参数超出模型上限(如 token 太长)
优化建议
- 使用 YAML 验证工具检查配置文件(推荐:yamllint)
- 在
models.yaml中为每个模型配置健康探测路径,例如healthcheck_url - 推理服务如使用 vLLM,应配置
--gpu-memory-utilization 0.9等参数控制加载速度 - 为模型配置合理的
max_tokens限制,并在前端 UI 层做长度裁剪或提示
8.2 插件调用失败或参数校验错误
问题现象
- 插件卡片渲染失败,前端不显示参数表单
- 插件执行时提示
schema validation error或返回None - 插件返回数据格式错误,无法在对话框中正确展示
原因分析
- 插件未正确注册到
plugin_registry.yaml - JSON Schema 文件字段缺失或类型定义错误
- 插件执行结果未符合标准结构或缺少 return 值
- 插件逻辑未考虑异常分支,抛出未捕获异常
优化建议
- 使用 JSON Schema 规范校验工具(如
ajv)测试插件参数定义 - 所有插件函数必须有明确返回值,避免隐式
None - 插件结果应返回字符串或标准对象,避免复杂嵌套结构
- 在插件处理器中加入异常捕获与日志记录机制:
try:result = plugin_handler(**params)
except Exception as e:logger.error(f"[Plugin Error] {e}")return "插件调用失败,请联系管理员。"
8.3 多模型切换不生效或前端模型列表丢失
问题现象
- 前端切换模型无效,请求仍发送到旧模型
- 模型切换后返回
model not found错误 - 前端模型下拉框刷新后列表为空
原因分析
- 模型名不一致(
models.yaml中 name 与请求参数中 model 不符) - 模型注册后未刷新缓存(需触发
/api/models/reload) - 前端
useModelStore状态未更新或失效 - 模型后端接口响应不兼容 OpenAI 协议
优化建议
- 保证模型名唯一,且与推理请求中
model参数严格一致 - 每次更改模型配置后调用一次
POST /api/models/reload接口 - 前端应监听模型列表接口失败时做降级处理并提示用户
- 模型后端应返回以下最小响应结构:
{"id": "chatcmpl-xyz","object": "chat.completion","choices": [ { "message": { "role": "assistant", "content": "你好" } } ]
}
8.4 插件系统无法热加载或更新后无效
问题现象
- 新增插件后前端无法识别
- 插件 schema 文件更新但参数未生效
- 插件模块执行失败或未导入
原因分析
plugin_registry.yaml未更新或路径错误- 插件模块路径与文件名不一致,导致
importlib导入失败 - 插件函数入口名拼写错误或未导出
- 插件更新未触发 reload 操作
优化建议
- 插件注册配置更新后调用
/api/plugins/reload触发热加载 - 避免使用 Python 非法命名或保留字作为模块名
- 插件逻辑建议结构规范:
# plugins/search.py
def search_google(query: str) -> str:# ...
- 插件执行异常时前端应反馈“插件调用失败”,避免 silent error
8.5 生产部署稳定性与性能调优建议
| 项目 | 优化建议 |
|---|---|
| 推理响应延迟 | 使用 vLLM/TGI + KV Cache,避免重复加载模型上下文 |
| 并发处理能力 | 后端使用 Uvicorn + Gunicorn 多 worker 模式 |
| 插件性能瓶颈 | 热路径插件建议异步执行并缓存结果 |
| 日志管理 | 使用 ELK + TraceID 机制集中采集日志 |
| 插件权限控制 | 结合用户角色配置 plugin 白名单和访问级别 |
| 异常恢复能力 | 所有对话调用应实现断点保护与请求重试机制 |
9. 总结与未来展望
9.1 项目核心价值回顾
Open WebUI 并非另一个“大模型”产品,而是聚焦于构建一个面向开发者与企业团队的统一多模型调用与交互界面解决方案。它解决了当前 AI 系统落地中普遍存在的几个核心痛点:
- 缺乏统一前端:无需每次接入新模型都重复开发界面
- 多模型调用难以切换:配置化路由让多源模型无缝集成
- 插件系统不统一:MCP 标准 + Schema 驱动机制构建模块化能力调用路径
- 多角色、企业级权限需求无法满足:可结合 SSO / RBAC 实现弹性扩展
通过本篇全流程拆解,我们可以看到,Open WebUI 在架构、部署、插件调用、安全控制、模型接入等维度均具备良好的可落地性、可维护性与演进潜力,适合作为中大型 AI 系统的统一接入网关或 AI 能力前端平台。
9.2 未来演进方向预测
结合社区当前开发动态与主流大模型生态趋势,Open WebUI 的下一阶段重点发展方向可能包括以下几个方面:
1)原生 Agent 调度框架对接
当前插件机制仍为“轻 Agent”模式,未来或将原生对接 LangGraph、CrewAI、Autogen 等 Agentic AI 框架,通过状态机与任务链系统完成更复杂的多步调用。
可能扩展方向:
- 支持 Agent 生命周期管理(init → plan → act → observe)
- 内嵌任务链可视化界面(如 DAG + Log)
- 与远程工具链深度绑定(如 Bash Runner、WebDriver)
2)模型服务编排能力提升
模型接入层将不仅支持静态配置,还将向“推理服务编排”演进,例如:
- 多模型集成调度(请求意图分类 → 路由分发)
- 模型热权重加载 / 释放控制
- 混合负载推理:主模型 + 插件模型协同响应
- 对接企业私有 Model Gateway(如 LLMOps 平台)
3)插件生态标准化与可复用平台构建
插件系统具备构建“生态平台”的潜力,后续演进方向可能包括:
- 插件商城机制:支持本地或云端插件市场注册 / 下载 / 更新
- 插件调试工具链:支持本地测试、沙箱执行、性能分析
- 多人协作插件开发与分享机制(GitHub Actions + Plugin Registry)
4)更强的数据治理与日志审计功能
为支持企业级部署合规需求,日志、审计与数据安全模块将持续增强:
- 对话内容与插件调用链日志结构化采集
- 敏感数据识别与脱敏传输策略(Prompt + Output 审计)
- 统一用户访问轨迹与 Trace ID 可视化平台
5)对接云原生平台与异构终端
为适应跨平台部署需求,Open WebUI 后续可能原生支持:
- K8s Operator 资源管理(动态扩缩容、多副本负载)
- WASM + Edge Runtime 模式部署插件
- 向移动端 / IoT 推理终端的适配(低功耗推理界面嵌入)
9.3 总结建议:如何工程化落地 Open WebUI
针对希望在企业内部部署 Open WebUI 的研发团队,建议按以下步骤推进:
-
快速验证阶段
- 克隆项目本地运行,调通主界面与模型 API
- 注册自定义插件(如 Weather、搜索)熟悉插件机制
-
集成测试阶段
- 接入私有模型 API 或本地部署模型(vLLM / TGI)
- 实现 SSO 接入、插件权限隔离、日志追踪路径
-
部署与运维阶段
- 配置 Docker Compose 或 Helm Chart
- 接入统一日志平台,设置高可用方案与模型健康探测
-
二次开发与扩展阶段
- 构建私有插件库或自动插件生成工具
- 对接企业流程系统,实现自动工单 / 搜索 / 语义路由链路
Open WebUI 并不是一个封闭工具,而是一个可嵌入、可裁剪、可深度定制的 AI 能力前端平台。对于希望构建“通用 AI 操作系统”或“多模型统一网关”的开发者来说,它是当前最具实用价值的开源选择之一。
个人简介
作者简介:全栈研发,具备端到端系统落地能力,专注人工智能领域。
个人主页:观熵
个人邮箱:privatexxxx@163.com
座右铭:愿科技之光,不止照亮智能,也照亮人心!

专栏导航
观熵系列专栏导航:
AI前沿探索:从大模型进化、多模态交互、AIGC内容生成,到AI在行业中的落地应用,我们将深入剖析最前沿的AI技术,分享实用的开发经验,并探讨AI未来的发展趋势
AI开源框架实战:面向 AI 工程师的大模型框架实战指南,覆盖训练、推理、部署与评估的全链路最佳实践
计算机视觉:聚焦计算机视觉前沿技术,涵盖图像识别、目标检测、自动驾驶、医疗影像等领域的最新进展和应用案例
国产大模型部署实战:持续更新的国产开源大模型部署实战教程,覆盖从 模型选型 → 环境配置 → 本地推理 → API封装 → 高性能部署 → 多模型管理 的完整全流程
Agentic AI架构实战全流程:一站式掌握 Agentic AI 架构构建核心路径:从协议到调度,从推理到执行,完整复刻企业级多智能体系统落地方案!
云原生应用托管与大模型融合实战指南
智能数据挖掘工程实践
Kubernetes × AI工程实战
TensorFlow 全栈实战:从建模到部署:覆盖模型构建、训练优化、跨平台部署与工程交付,帮助开发者掌握从原型到上线的完整 AI 开发流程
PyTorch 全栈实战专栏: PyTorch 框架的全栈实战应用,涵盖从模型训练、优化、部署到维护的完整流程
深入理解 TensorRT:深入解析 TensorRT 的核心机制与部署实践,助力构建高性能 AI 推理系统
Megatron-LM 实战笔记:聚焦于 Megatron-LM 框架的实战应用,涵盖从预训练、微调到部署的全流程
AI Agent:系统学习并亲手构建一个完整的 AI Agent 系统,从基础理论、算法实战、框架应用,到私有部署、多端集成
DeepSeek 实战与解析:聚焦 DeepSeek 系列模型原理解析与实战应用,涵盖部署、推理、微调与多场景集成,助你高效上手国产大模型
端侧大模型:聚焦大模型在移动设备上的部署与优化,探索端侧智能的实现路径
行业大模型 · 数据全流程指南:大模型预训练数据的设计、采集、清洗与合规治理,聚焦行业场景,从需求定义到数据闭环,帮助您构建专属的智能数据基座
机器人研发全栈进阶指南:从ROS到AI智能控制:机器人系统架构、感知建图、路径规划、控制系统、AI智能决策、系统集成等核心能力模块
人工智能下的网络安全:通过实战案例和系统化方法,帮助开发者和安全工程师识别风险、构建防御机制,确保 AI 系统的稳定与安全
智能 DevOps 工厂:AI 驱动的持续交付实践:构建以 AI 为核心的智能 DevOps 平台,涵盖从 CI/CD 流水线、AIOps、MLOps 到 DevSecOps 的全流程实践。
C++学习笔记?:聚焦于现代 C++ 编程的核心概念与实践,涵盖 STL 源码剖析、内存管理、模板元编程等关键技术
AI × Quant 系统化落地实战:从数据、策略到实盘,打造全栈智能量化交易系统
大模型运营专家的Prompt修炼之路:本专栏聚焦开发 / 测试人员的实际转型路径,基于 OpenAI、DeepSeek、抖音等真实资料,拆解 从入门到专业落地的关键主题,涵盖 Prompt 编写范式、结构输出控制、模型行为评估、系统接入与 DevOps 管理。每一篇都不讲概念空话,只做实战经验沉淀,让你一步步成为真正的模型运营专家。
🌟 如果本文对你有帮助,欢迎三连支持!
👍 点个赞,给我一些反馈动力
⭐ 收藏起来,方便之后复习查阅
🔔 关注我,后续还有更多实战内容持续更新










![[Redis] Redis命令(2)](https://i-blog.csdnimg.cn/direct/939caaa37c314ab48be393231ab96d99.png)