文章目录
- 前言
- 一、Windows11+CPU算法环境搭建
- 1. 安装pycharm
- 2. 安装python 3.8.10
- 3. 安装pytorch 1.13.0
- 4. 安装mingw64 14.2.0
- 5. 安装cmake 3.31.6
- 6. 安装 Visual Studio 2022
- 二、运行YOLO模型并转换为ONNX文件
- 1. 下载yolo11源码和 ultralytics-8.3.31-py3-none-any.whl 文件
- 2. 下载yolo11n.pt权重文件
- 3. 配置train.py文件,执行 python train.py(自动下载数据集)
- 4. 配置test.py文件,成功推理图片并存储结果
- 5. 转换成onnx文件
- 三、OpenCV静态库生成与链接
- 1.下载 opencv-4.11.0-windows
- 2. 静态库编译
- 3. 检查编译好的OpenCV静态库文件
- 4. 编译过程中可能存在的问题
- 四、DDL动态库封装Yolo11n
- 1. 新建Yolo动态库项目
- 2. 配置OpenCV静态库
- 3. 使用OpenCV加载YOLO模型进行推理预测
- 五、DDL动态库验证
- 1. 创建新项目
- 2. Yolo动态库配置
- 3. 动态库调用
- 总结
前言
本文详细记录了博主在 Windows 平台下将 YOLO11n 模型封装为动态库DDL的完整流程与踩坑经历,内容涵盖:在 Windows 上搭建算法环境(基于 CPU)、编译 OpenCV 为静态库、使用 OpenCV 加载并推理 YOLO 模型文件、最终完成动态库的封装与调用验证。如果你也有类似的部署需求,或者在封装过程中遇到过各种问题,相信这篇“保姆级教程”能为你提供实用的参考和帮助!
一、Windows11+CPU算法环境搭建
1. 安装pycharm
参考文章:PyCharm下载、安装及相关配置(Windows11)详细教程
2. 安装python 3.8.10
参考文章:Windows 系统上如何安装 Python环境(详细教程)
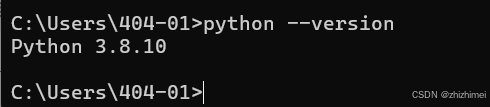
安装完成后通过以下命令验证python版本:
python --version
检查同步安装的pip版本:
python -m pip --version

3. 安装pytorch 1.13.0
如果不需要安装指定版本的pytorch,可以直接在pytorch官网获取安装命令:
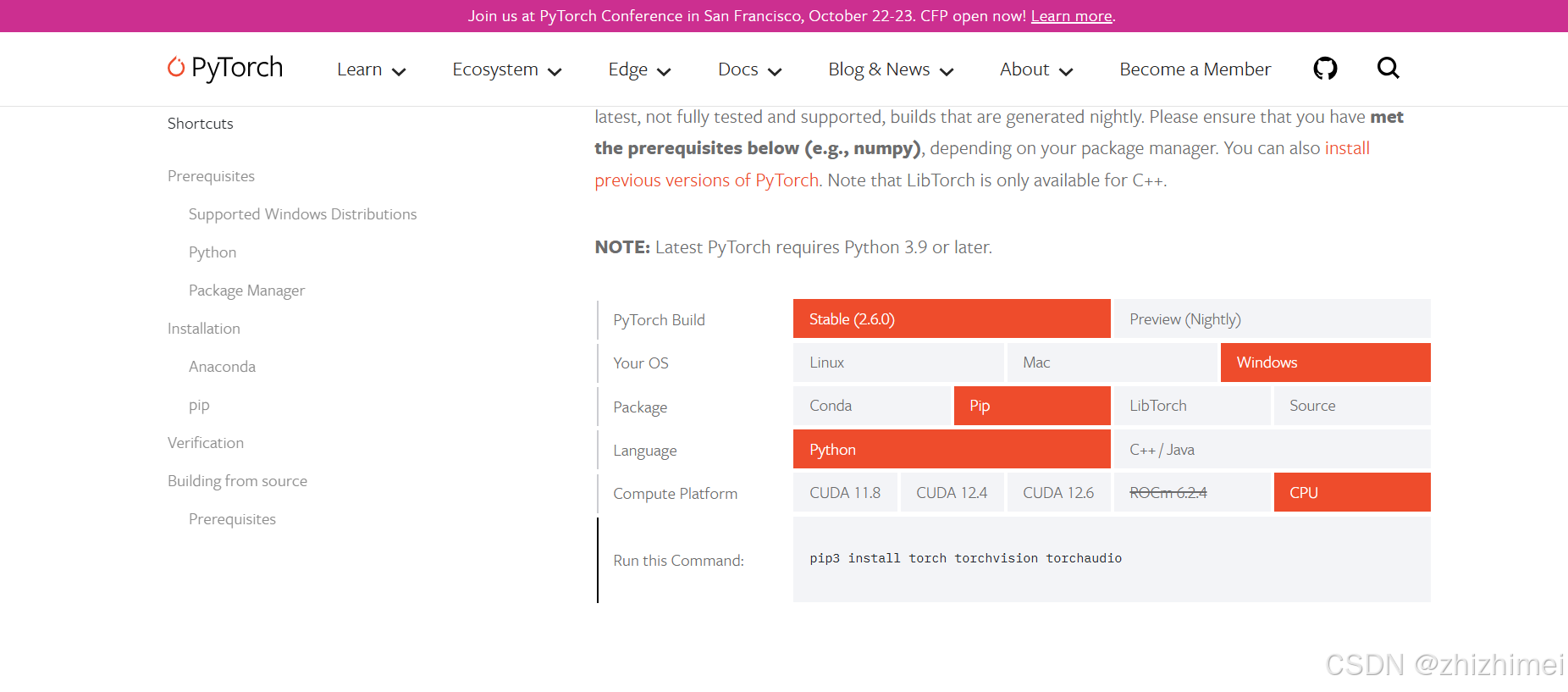
否则,可以以 管理员权限 打开命令行,通过以下命令安装指定版本的pytorch:
pip3 install pytorch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 cpuonly -i https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
若执行上述命令时遇到了报错:Could not find a version that satisfies the requirement xxx (from versions: none)
解决方案参考:解决pytorch指令安装时Could not find a version that satisfies the requirement xxx (from versions: none)
在https://download.pytorch.org/whl/torch_stable.html中下载找不到的安装文件,博主下载的文件如下:
torch-1.13.0+cpu-cp38-cp38-win_amd64.whl
torchvision-0.14.0+cpu-cp38-cp38-win_amd64.whl
然后执行安装命令:
pip install .\torch-1.13.0+cpu-cp38-cp38-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install .\torchvision-0.14.0+cpu-cp38-cp38-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装成功,通过以下命令验证pytorch版本:

4. 安装mingw64 14.2.0
参考文章:在window系统下搭建C/C++开发环境
在 https://github.com/niXman/mingw-builds-binaries/releases 中下载指定版本的安装包:
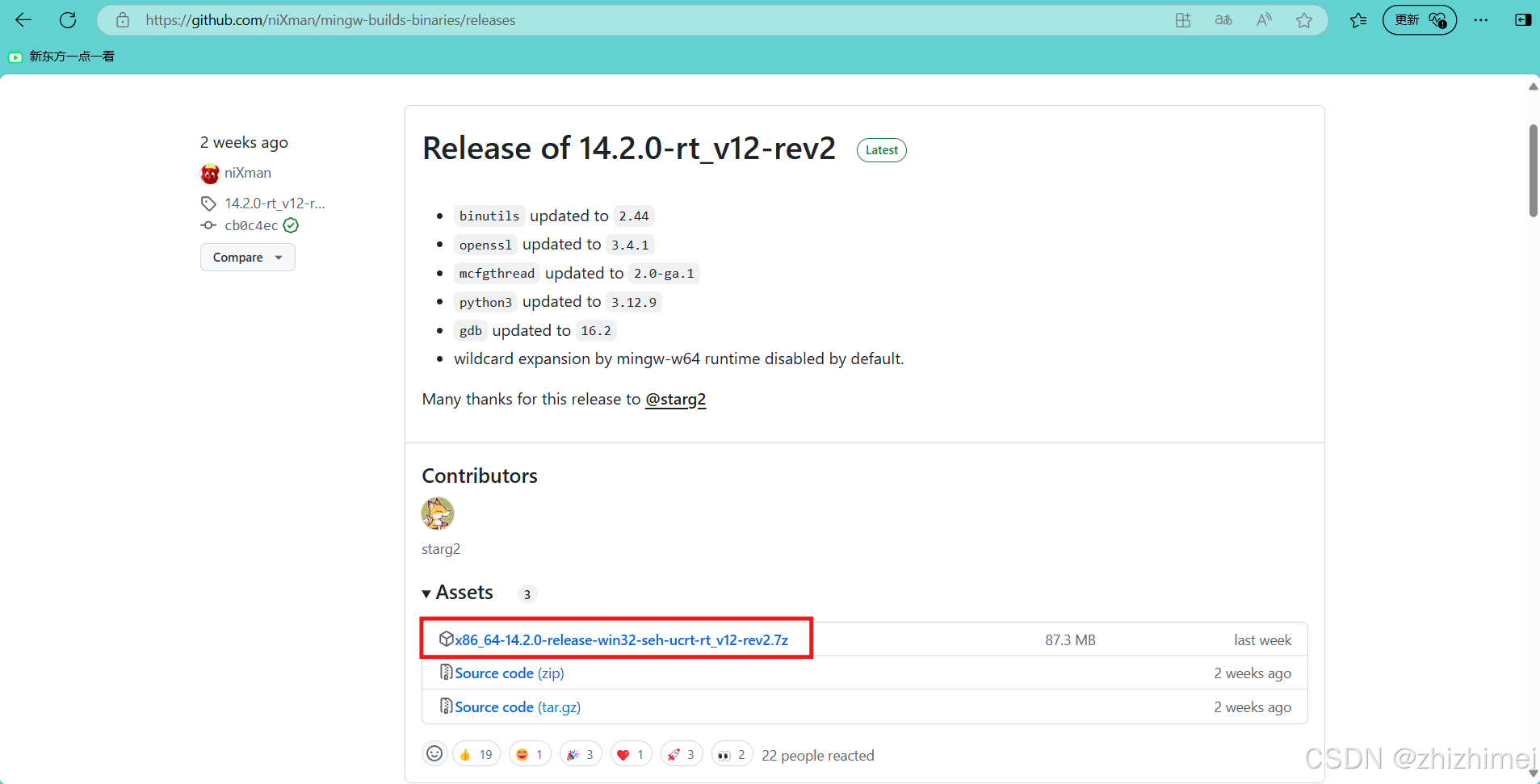
解压下载后的文件到指定安装目录:
配置环境变量:
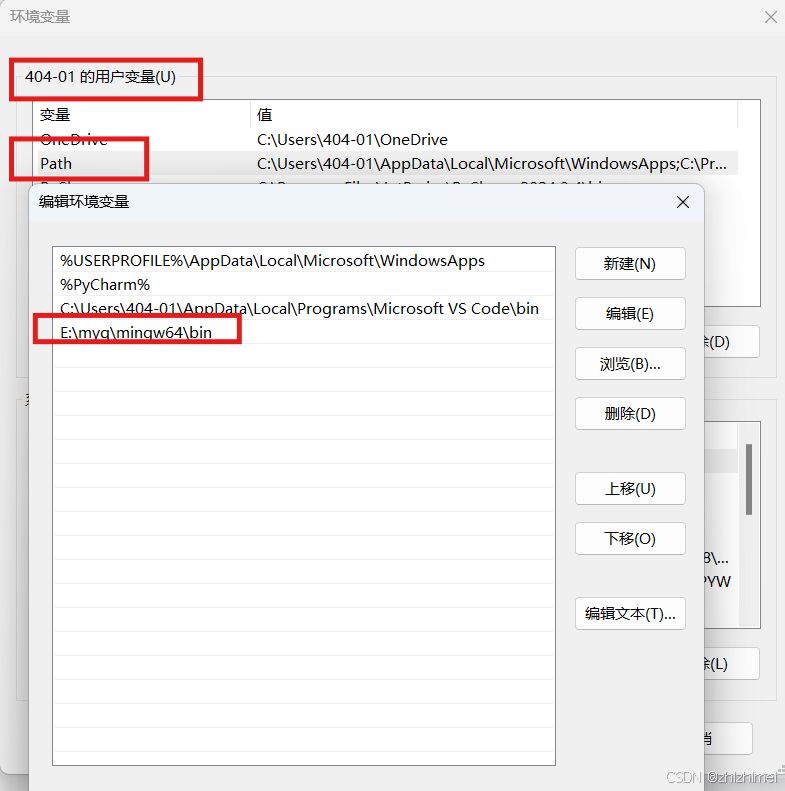
安装成功后验证:
gcc --version

gdb --version

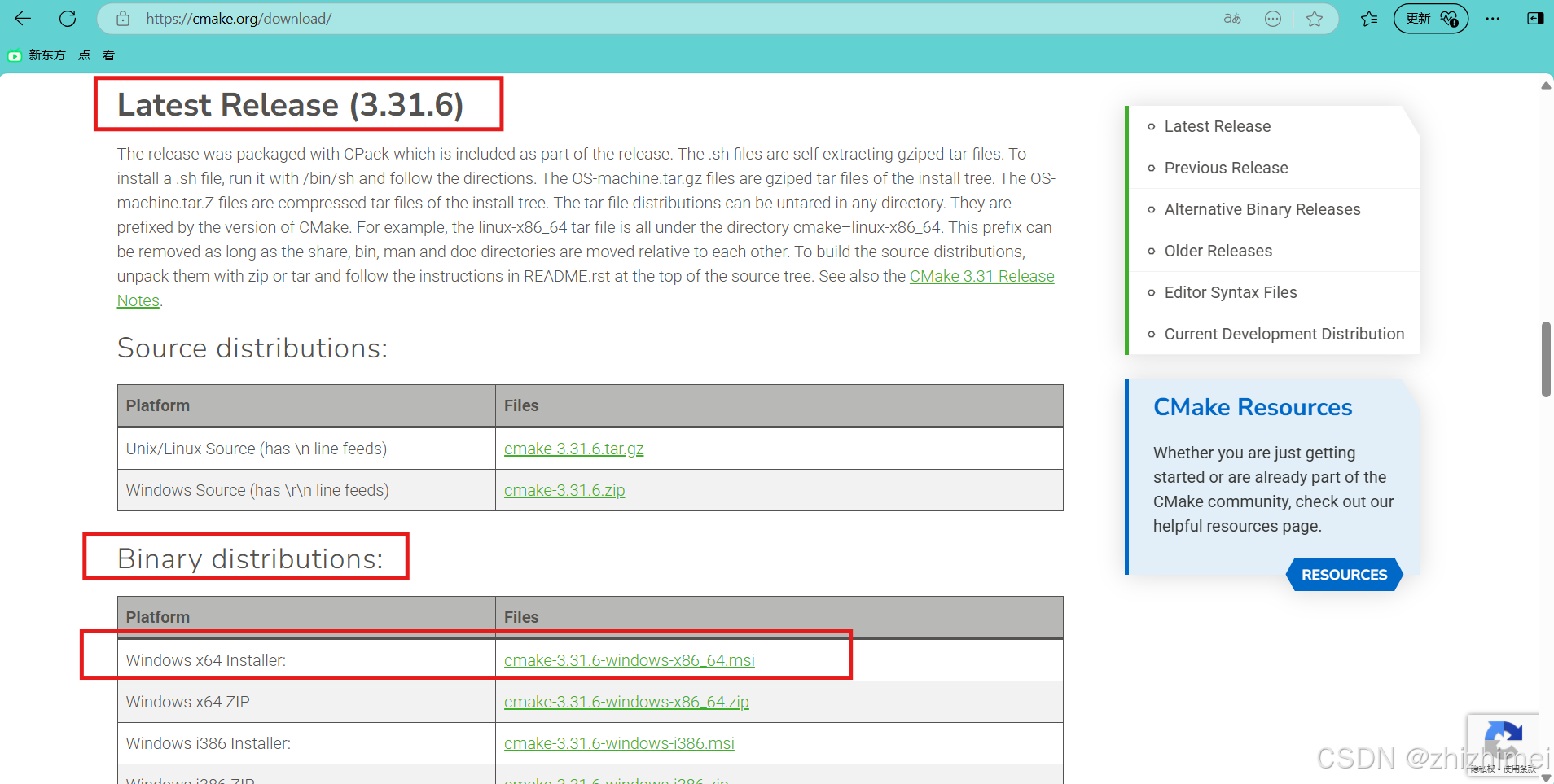
5. 安装cmake 3.31.6
参考文章:Windows下CMake的下载与安装详解
注意下载路径: Latest Release -> Binary distributions -> Windows x64Installer
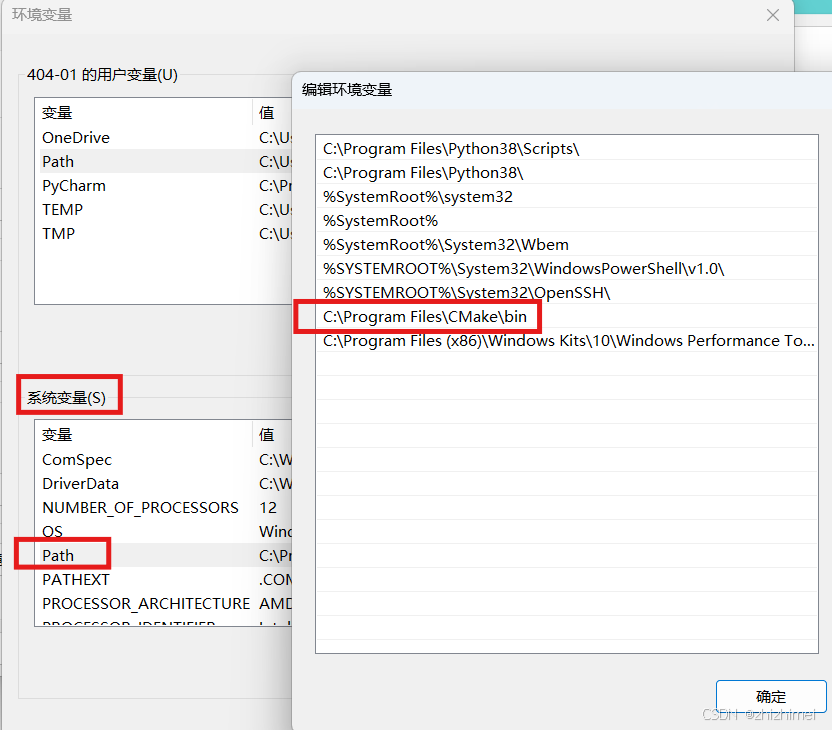
下载后运行安装包,等待安装完成后检查环境变量配置:
命令行检查cmake版本:
cmake -version

6. 安装 Visual Studio 2022
参考文章:最新保姆级教程:Windows 上安装 Visual Studio(超级详细)
二、运行YOLO模型并转换为ONNX文件
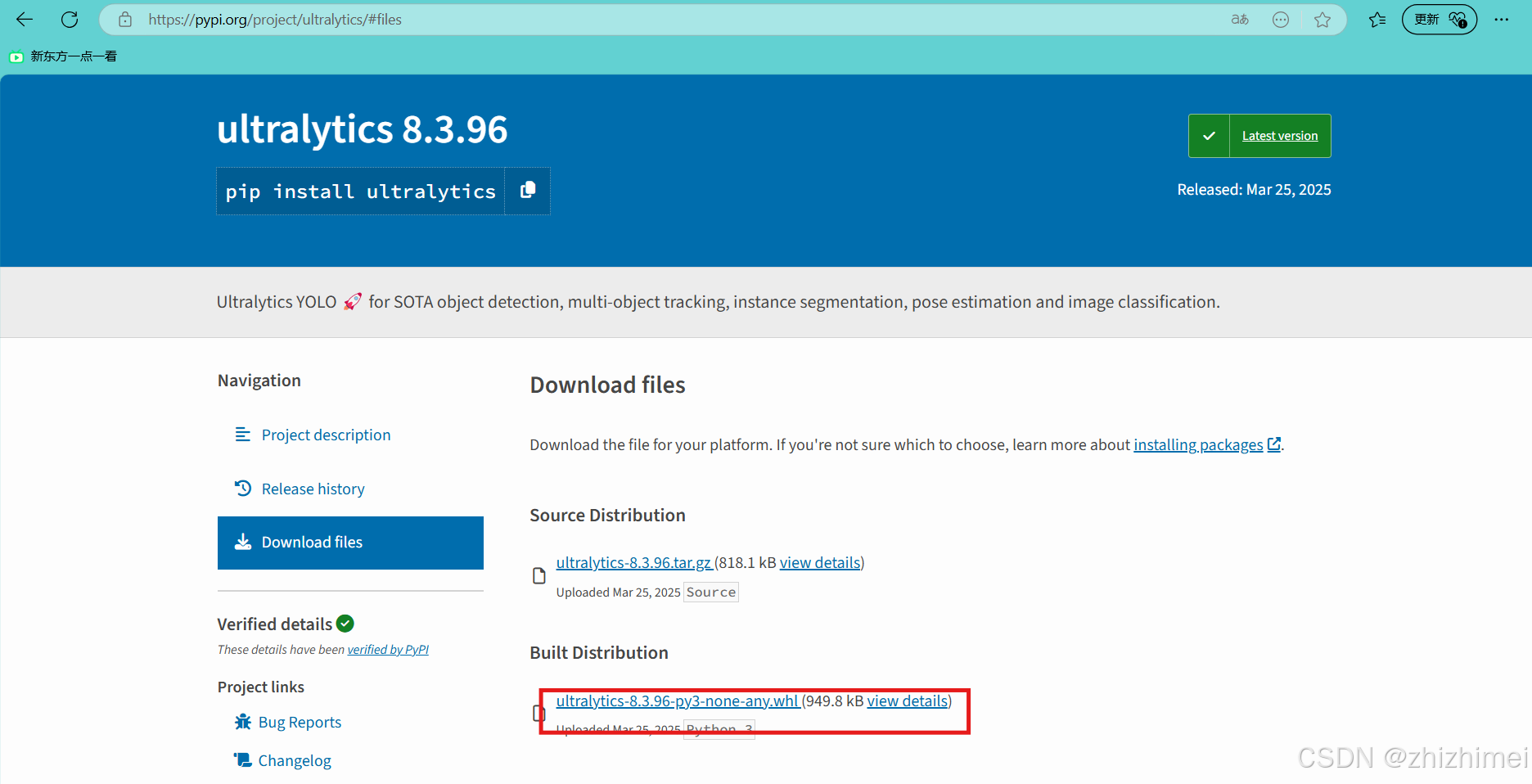
1. 下载yolo11源码和 ultralytics-8.3.31-py3-none-any.whl 文件
源码下载地址:ultralytics
离线安装包下载地址:pypi官方网址
2. 下载yolo11n.pt权重文件
权重下载地址:yolo11n
3. 配置train.py文件,执行 python train.py(自动下载数据集)
使用pycharm打开下载的yolo11源码,新建train.py文件
from ultralytics import YOLO# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)# Train the model
results = model.train(data="coco.yaml", epochs=100, imgsz=640)
其中coco.yaml文件可以在下面的目录中找到:
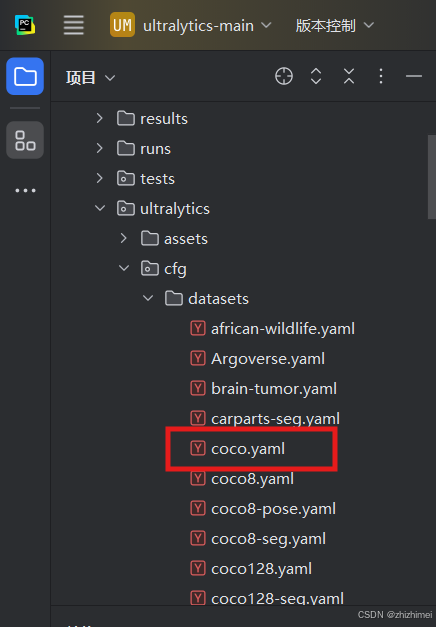
命令行执行:
python train.py
之后等待coco数据集下载完成后会开始使用cpu训练模型:
4. 配置test.py文件,成功推理图片并存储结果
还可以编写test.py文件检验yolo11n.pt的推理效果
import os.pathfrom ultralytics import YOLO
from PIL import Imageyolo_model = YOLO('./yolo11n.pt')
source = 'E:/myq/ultralytics-main/datasets/coco/images/val2017'
result = yolo_model(source)for i, r in enumerate(result):name = os.path.basename(r.path)img_bgr = r.plot()img_bgr = Image.fromarray(img_bgr[..., ::-1])r.save(filename=f'results/{name}_infer.jpg')
运行test.py文件可得到推理结果:
python test.py
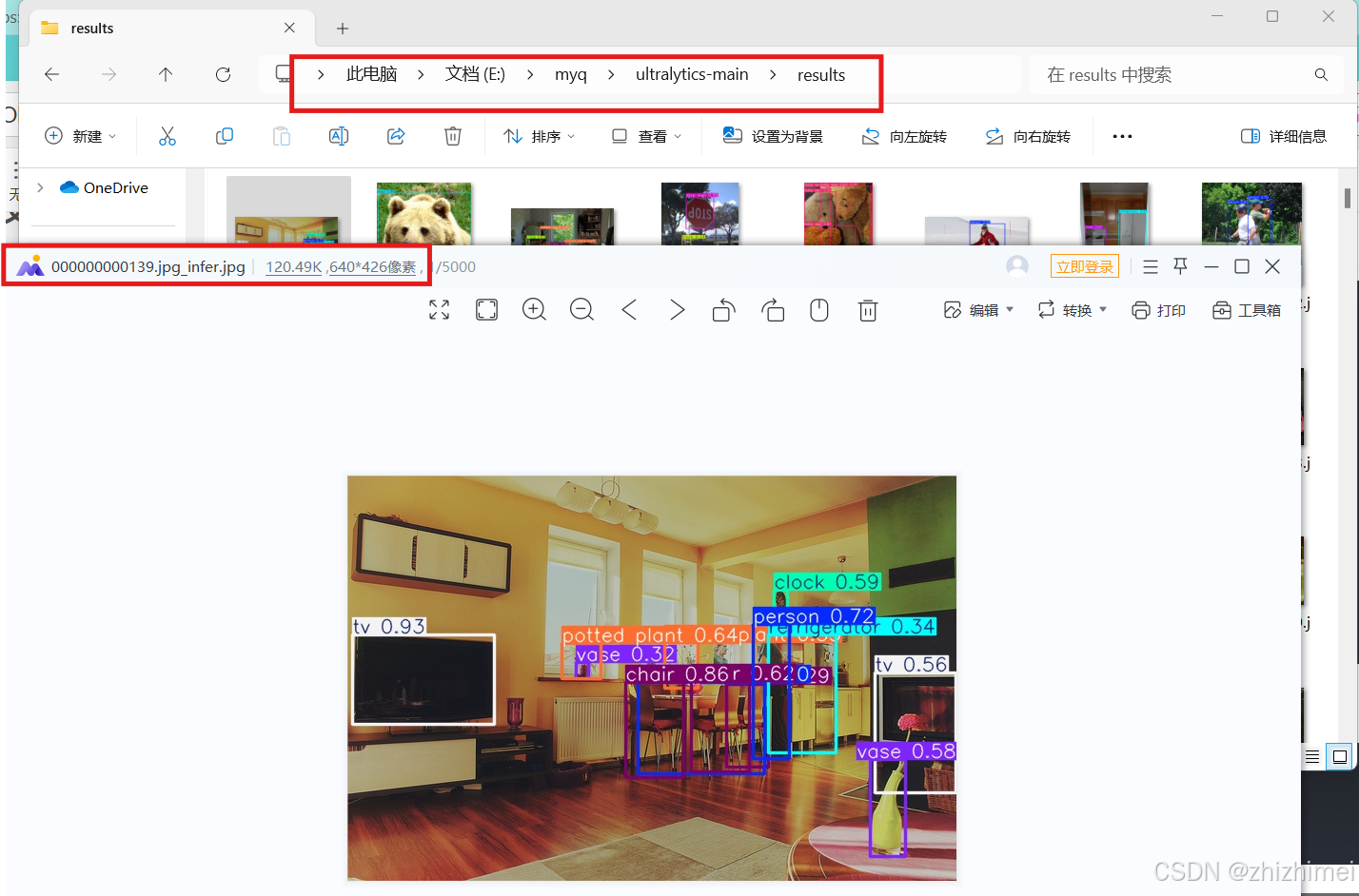
5. 转换成onnx文件
新建toonnx.py文件:
from ultralytics import YOLOmodel = YOLO("yolo11n.pt")
model.export(format="onnx")
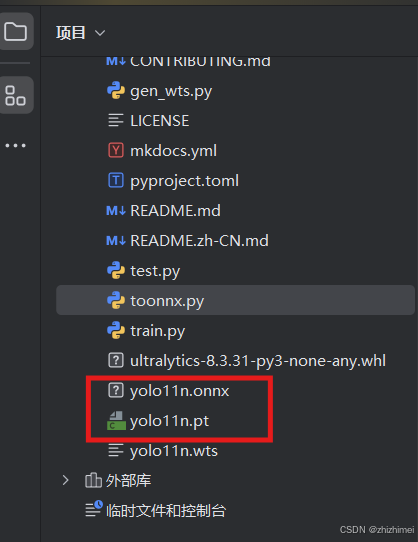
运行后得到yolo11n.onnx文件:
python toonnx.py
三、OpenCV静态库生成与链接
参考文章:
WINDOWS下编译OPENCV4.5.4静态库
vs2022配置opencv静态库
VS配置opencv动态链接库和静态链接库(超简单)
1.下载 opencv-4.11.0-windows
下载两个压缩包:opencv-4.11.0.zip、opencv_contrib-4.11.0.zip
解压缩opencv-4.11.0.zip得到:
注意:路径中最好不要存在中文字样,以免编译出错!!!!
解压缩opencv_contrib-4.11.0.zip到与opencv-4.11.0的同目录下:
在该目录下新建一个build_word文件夹:
2. 静态库编译
根据 cMake的环境变量找到cmake-gui,双击运行:
选择源码路径和编译路径:
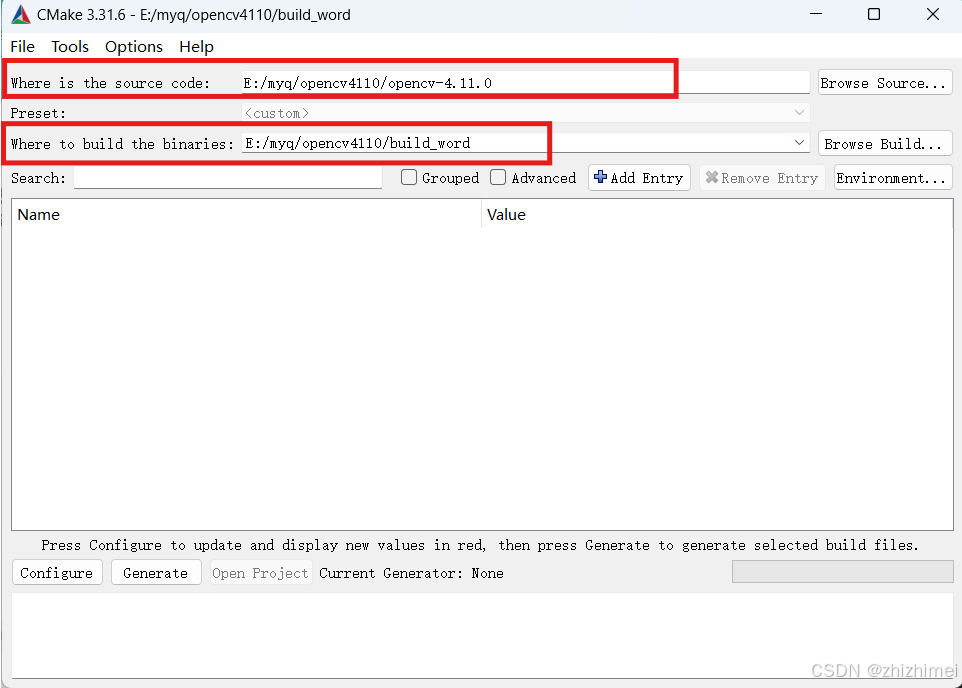
点击Configure,编译器选择VS2022后点击Finish:

等待第一次编译完成后修改下列编译参数:
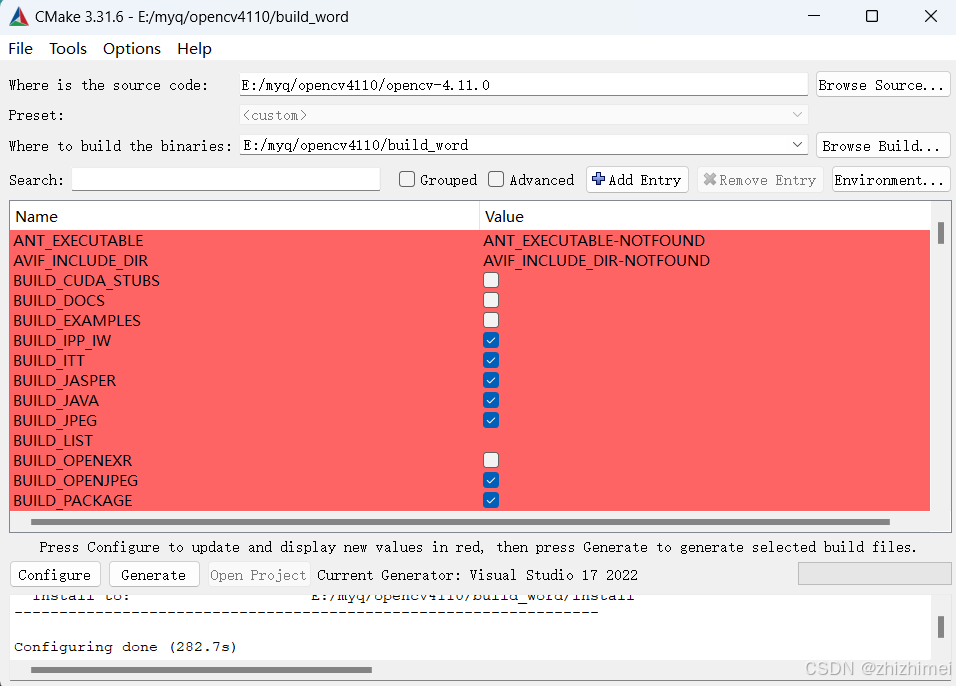
搜索MODULES,添加opencv-contrib路径:
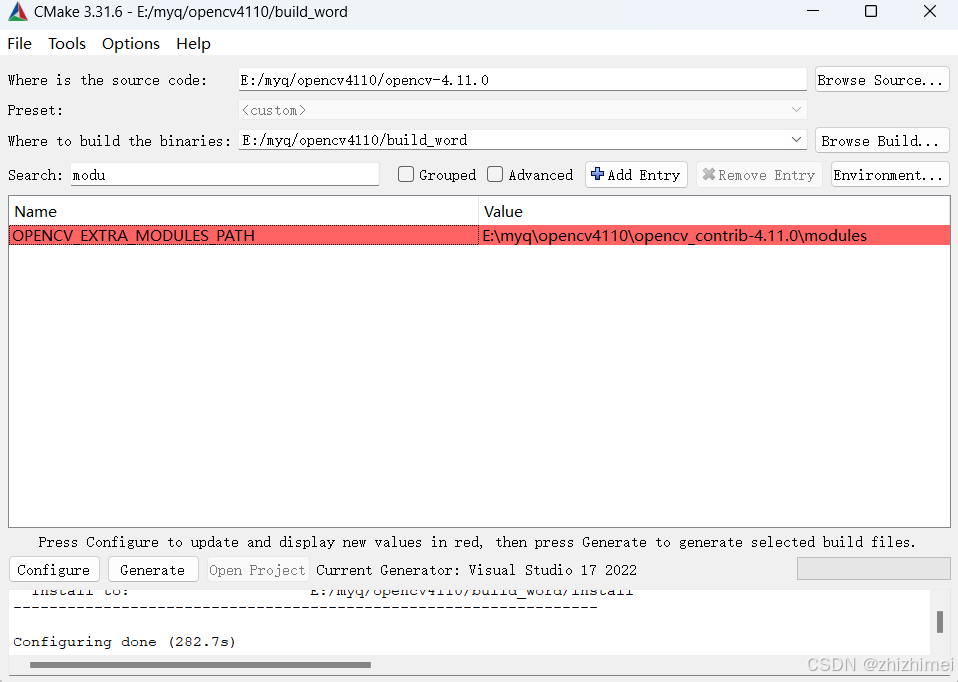
搜索SHARED, Value去掉对勾:
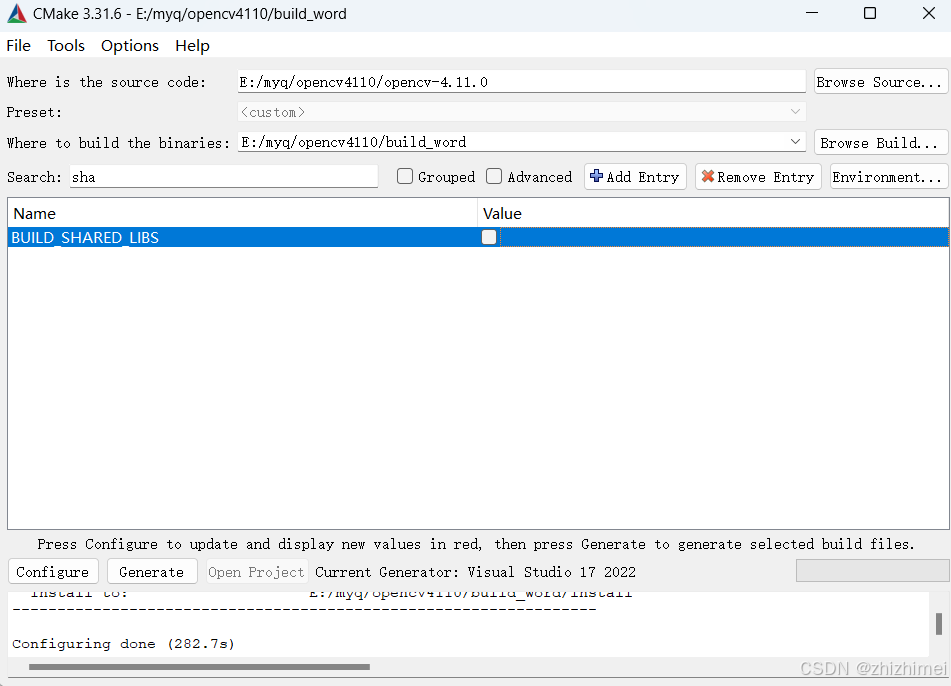
搜索BUILD_opencv_world,勾选Value:
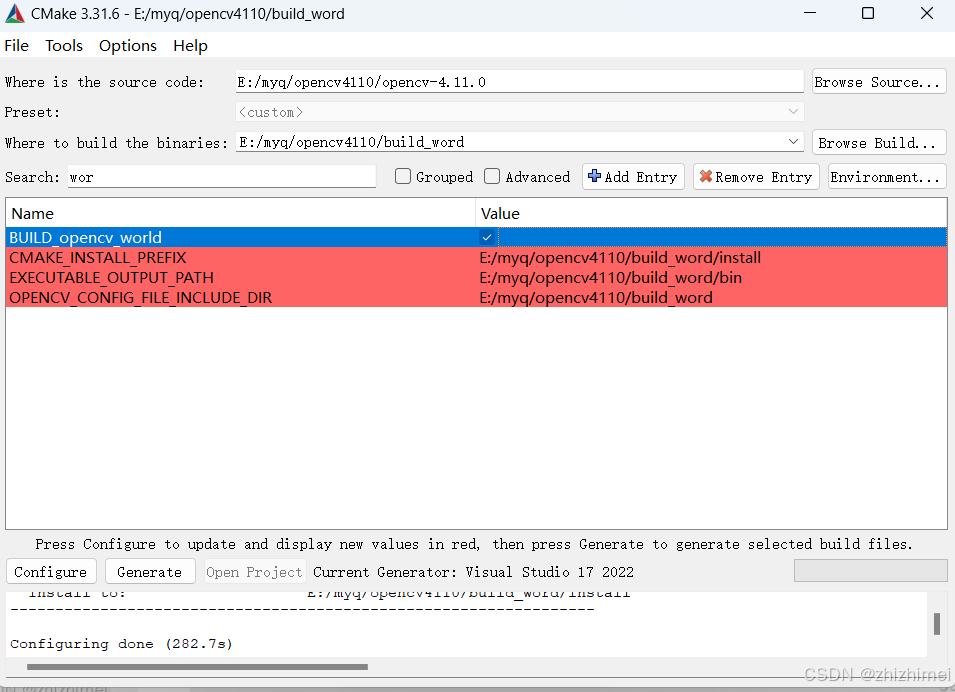
搜索BUILD_WITH_STATIC_CRT,取消勾选以生成MD静态库(根据个人需求来选择):
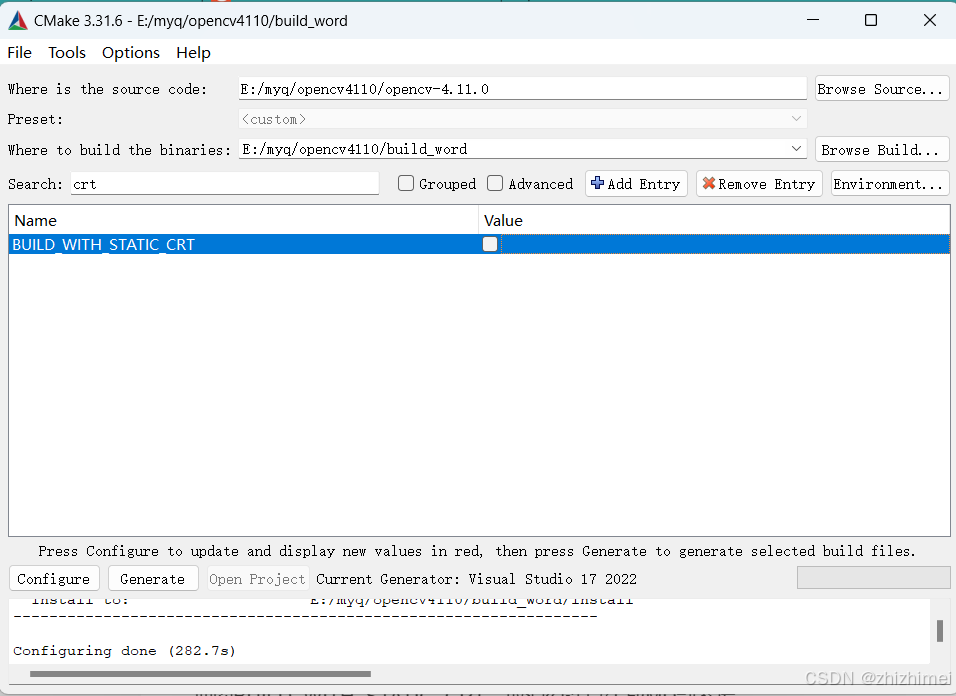
修改好编译选项后,再次点击configure,一直重复configure到没有爆红出现:
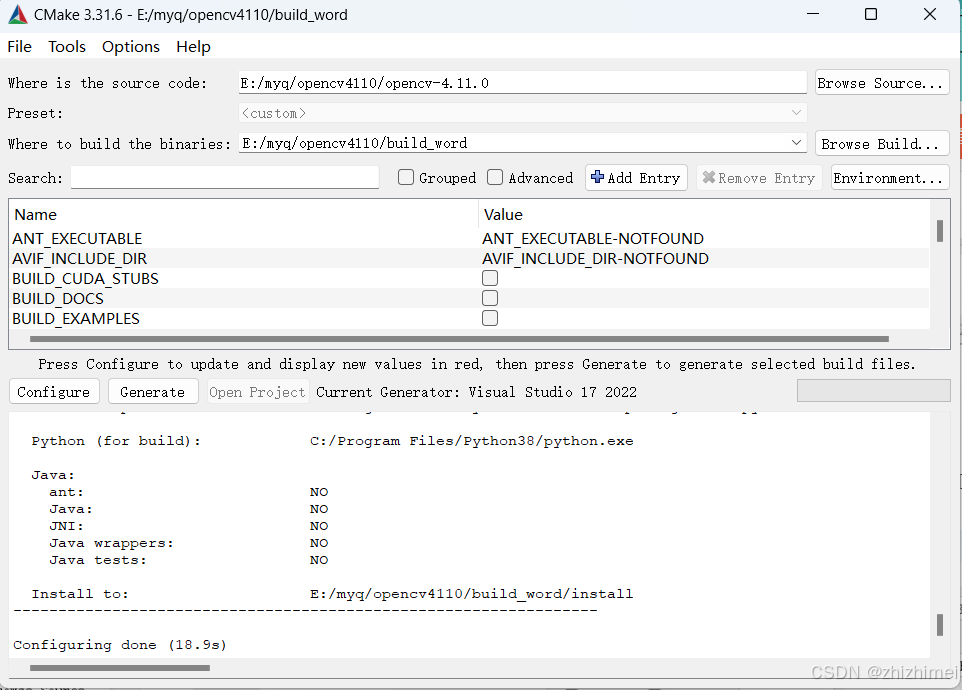
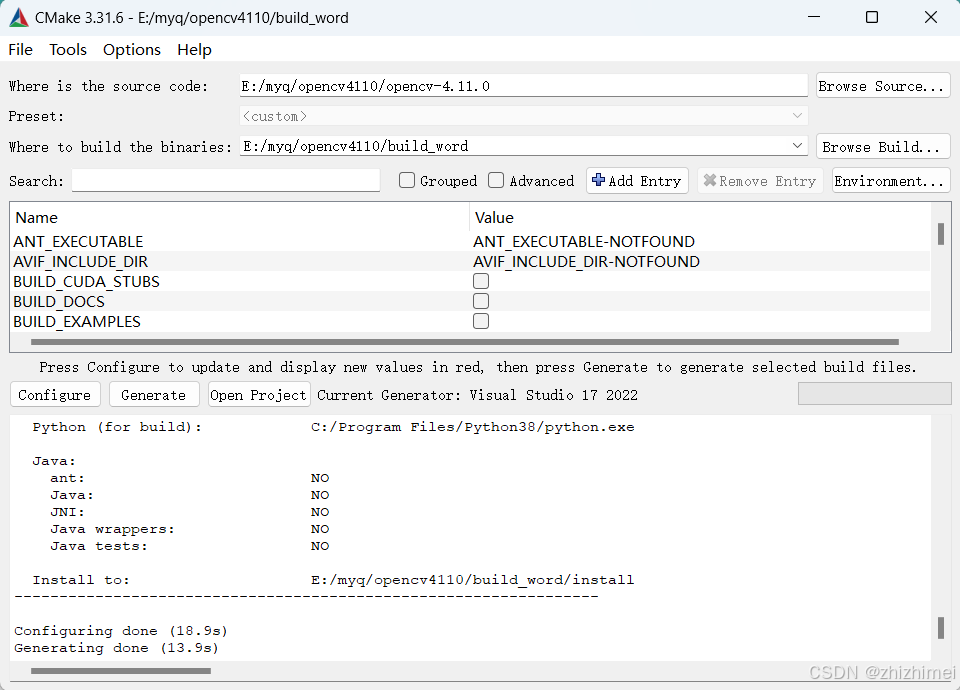
点击generate,等待执行完成:
以管理员身份运行Visual Studio 2022,打开build_word目录下的OpenCV.sln文件:
修改编译模式 Release - x64(和要集成到的动态库保持一致):
生成 -> 生成解决方案,等待完成(过程可能会比较长,耐心等待):
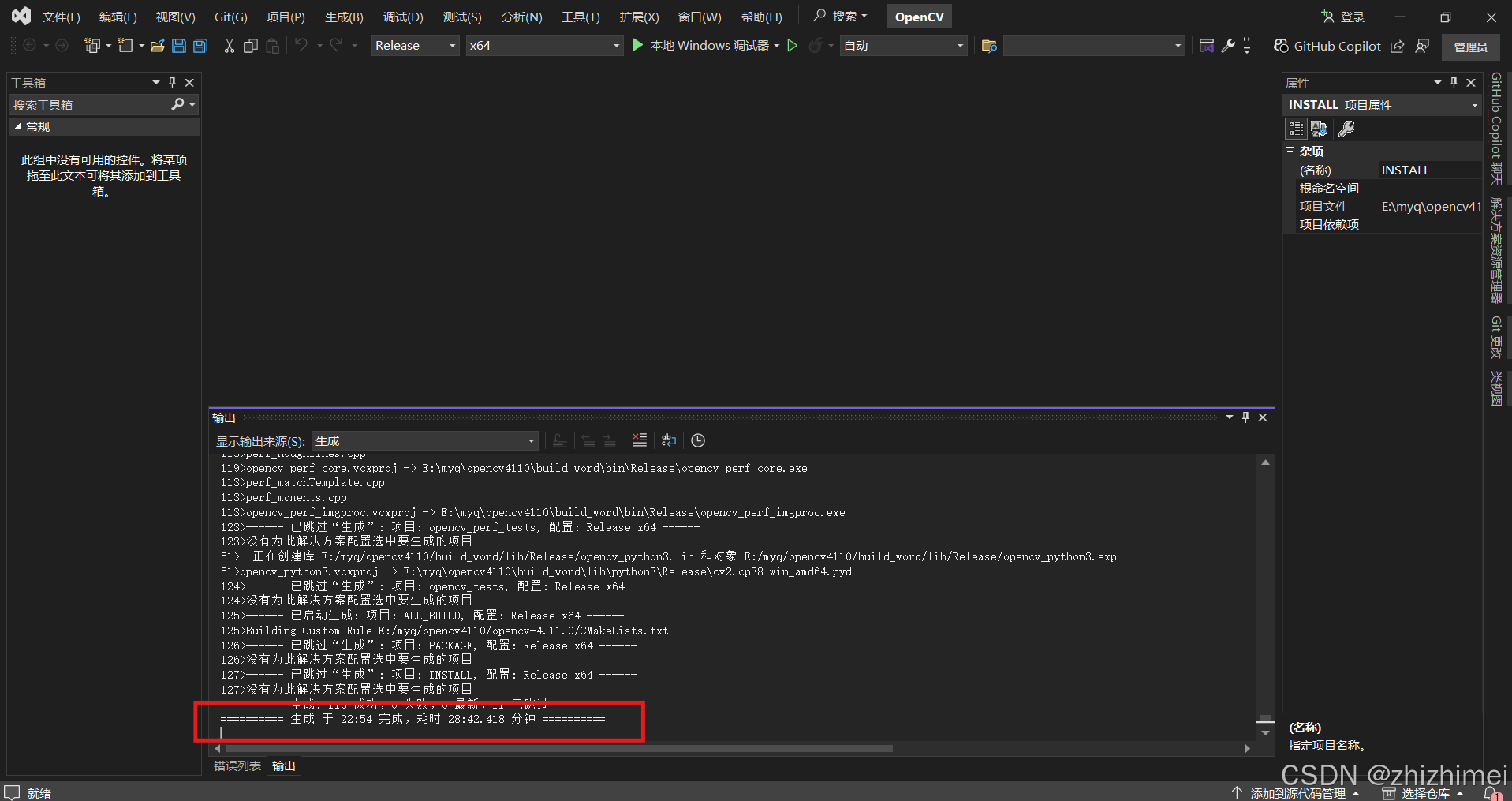
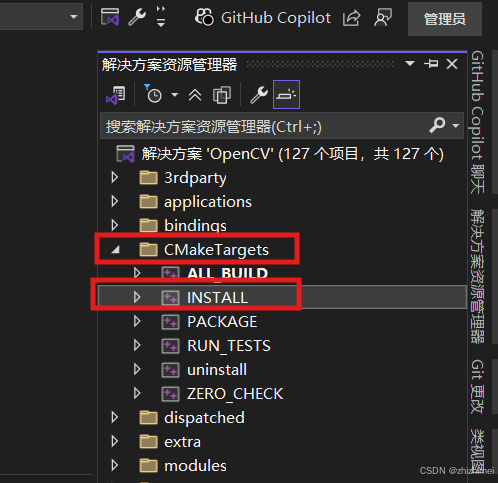
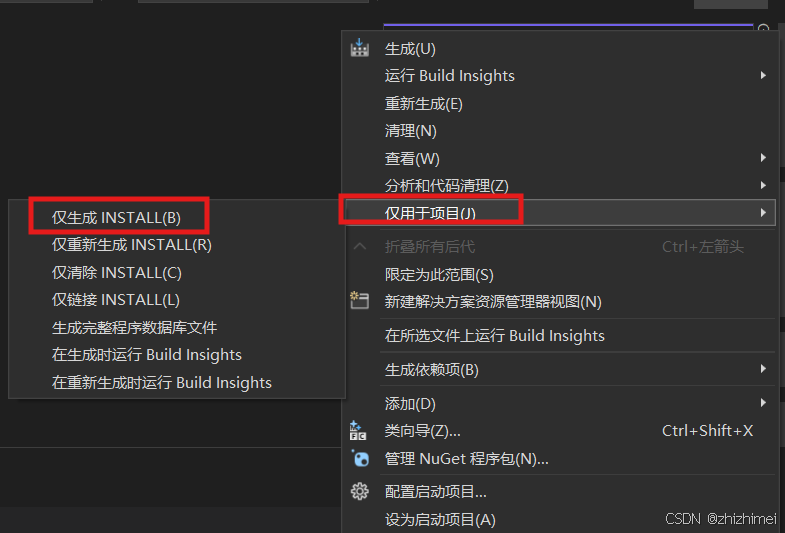
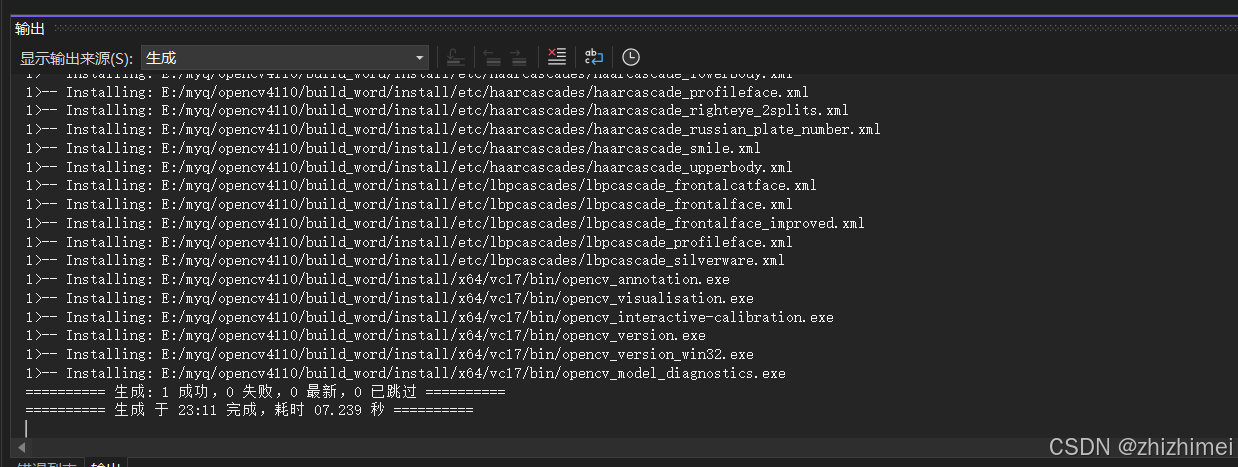
解决方案资源管理器 -> CMake Targets -> INSTALL -> 右击 -> 仅用于项目 -> 仅生成INSTALL,等待执行完成:
3. 检查编译好的OpenCV静态库文件
编译好的静态库文件在 build_word -> install 目录下:
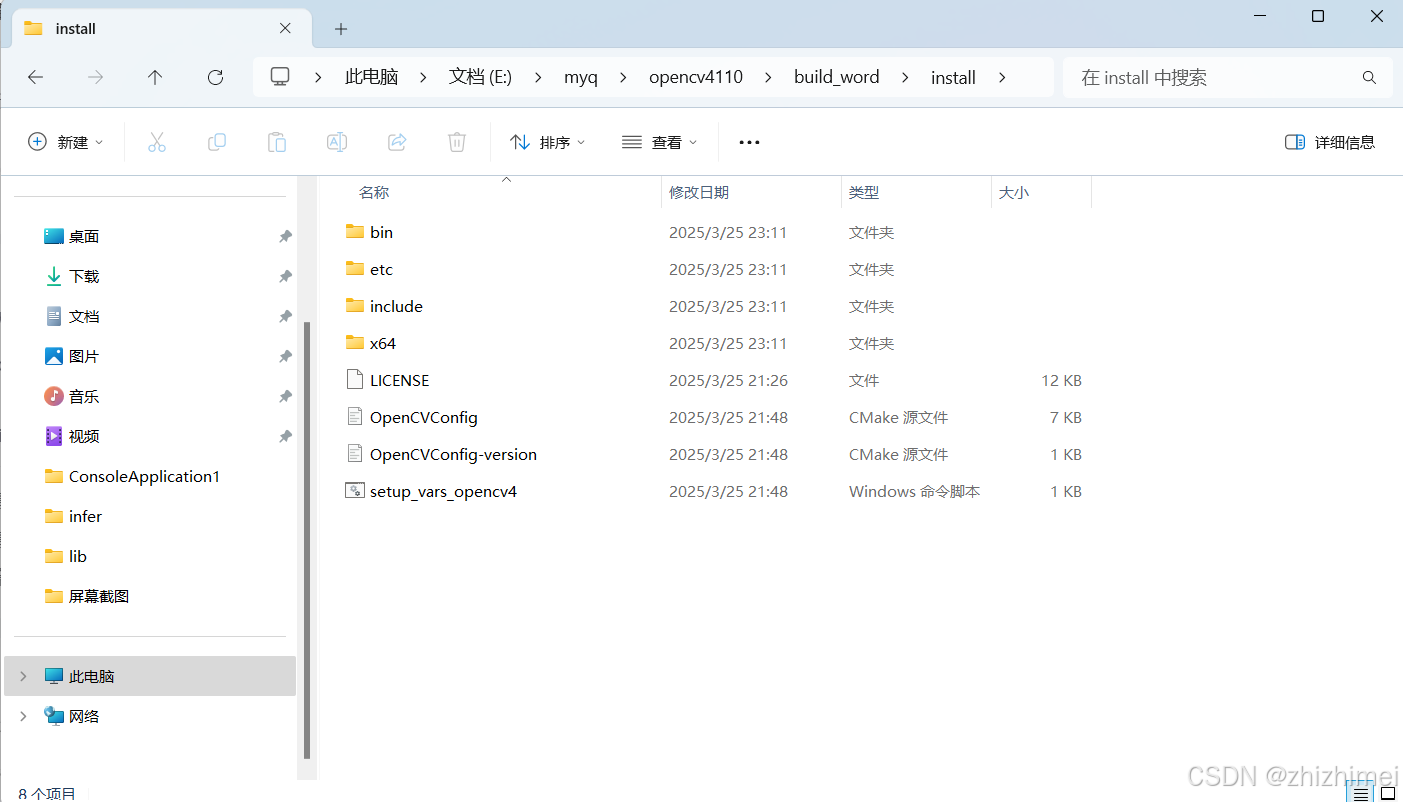
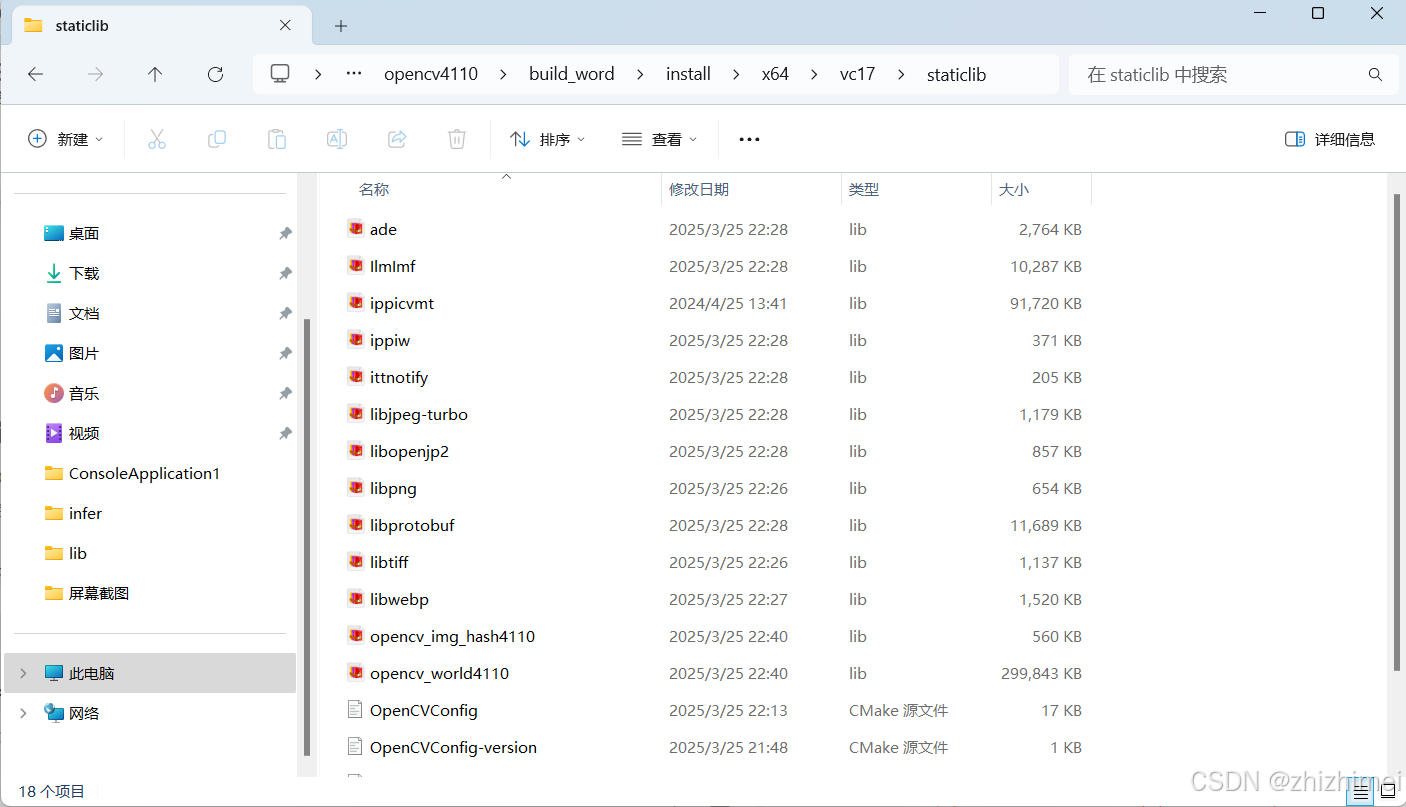
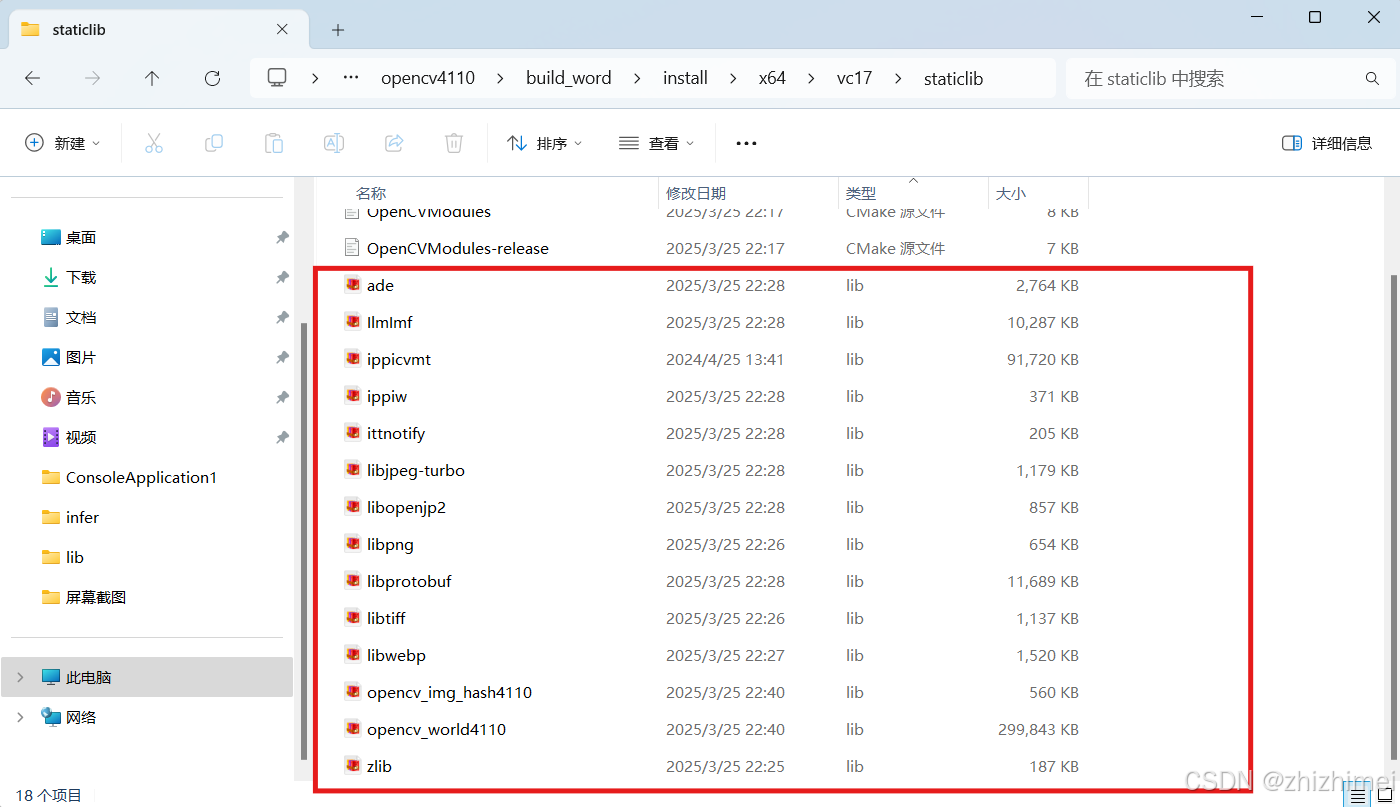
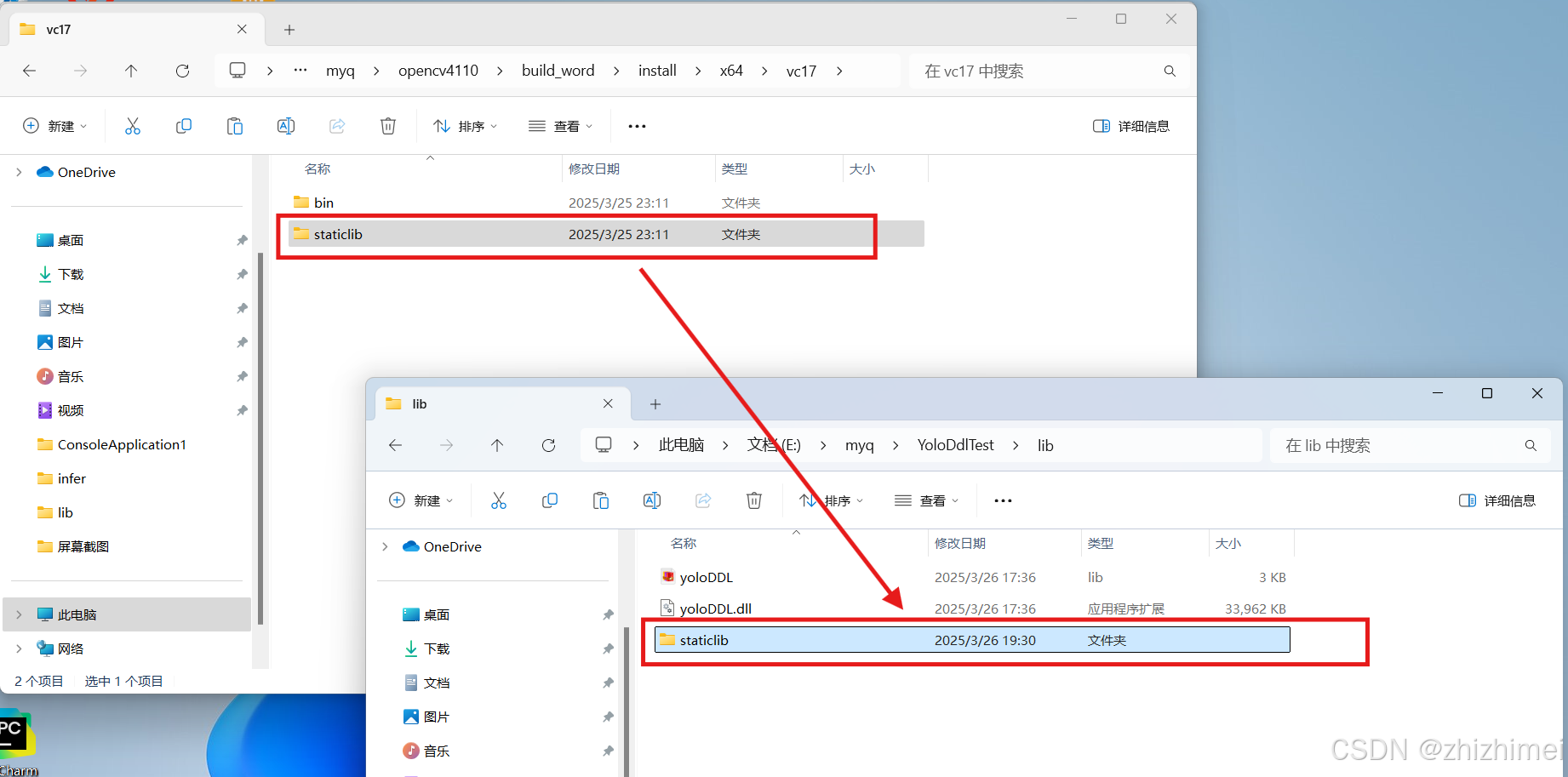
其中,build_word\install\x64\vc17\staticlib目录下存放的是静态库:
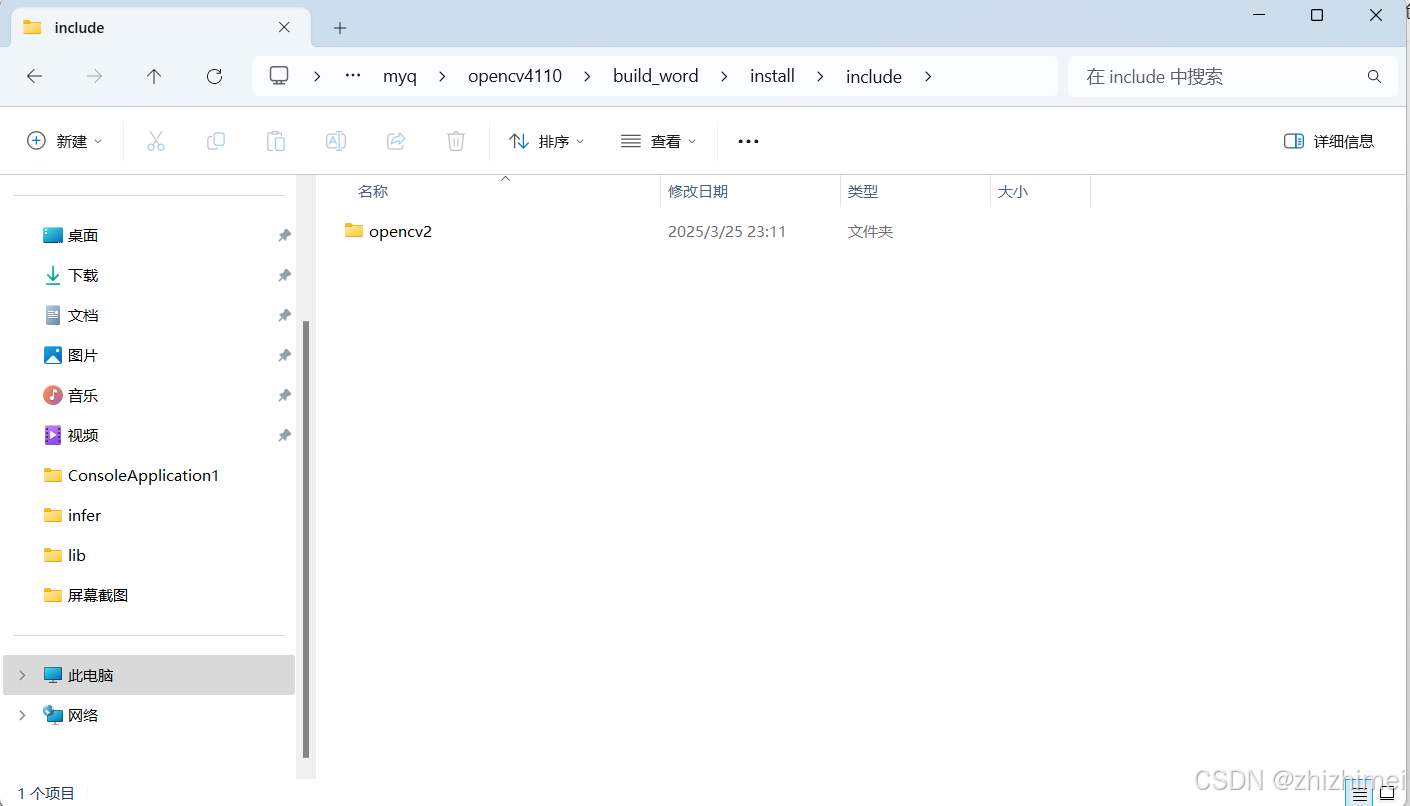
build_word\install\include目录下存放的是静态库头文件:
4. 编译过程中可能存在的问题
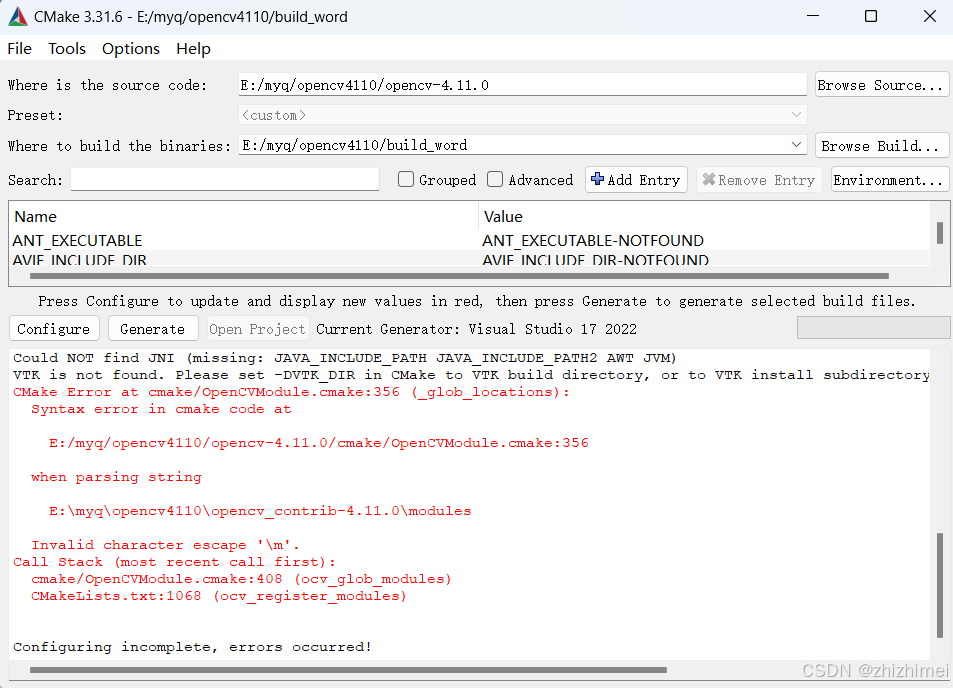
可能的报错1:opencv-contrib路径错误,在 Windows 系统中,路径分隔符通常是反斜杠 \,但在 CMake 中,反斜杠会被当作转义字符处理
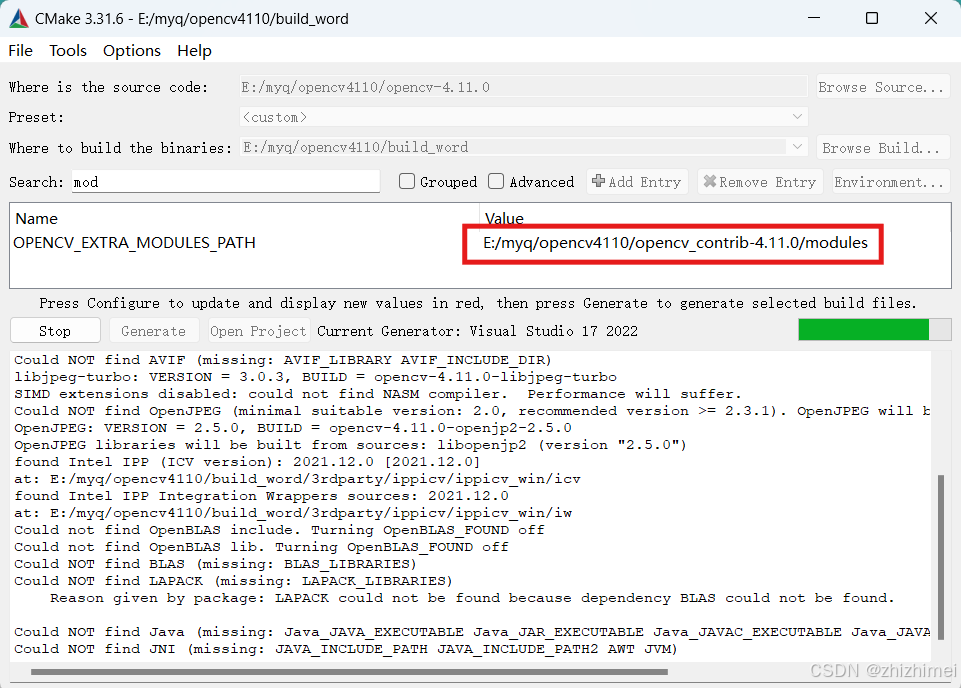
解决方案:更正路径后重新configure
四、DDL动态库封装Yolo11n
参考文章:
VS2019-C++创建和调用DLL动态链接库(傻瓜式教程)
手把手教你 封装YOLOv8推理位DLL 给客户端调用
VS配置opencv动态链接库和静态链接库(超简单)
YOLOv8目标检测——详细记录使用OpenCV的DNN模块进行推理部署C++实现
代码仓库
1. 新建Yolo动态库项目
打开Visual Studio 2022 -> 创建新项目 -> 动态链接库 -> 下一步:
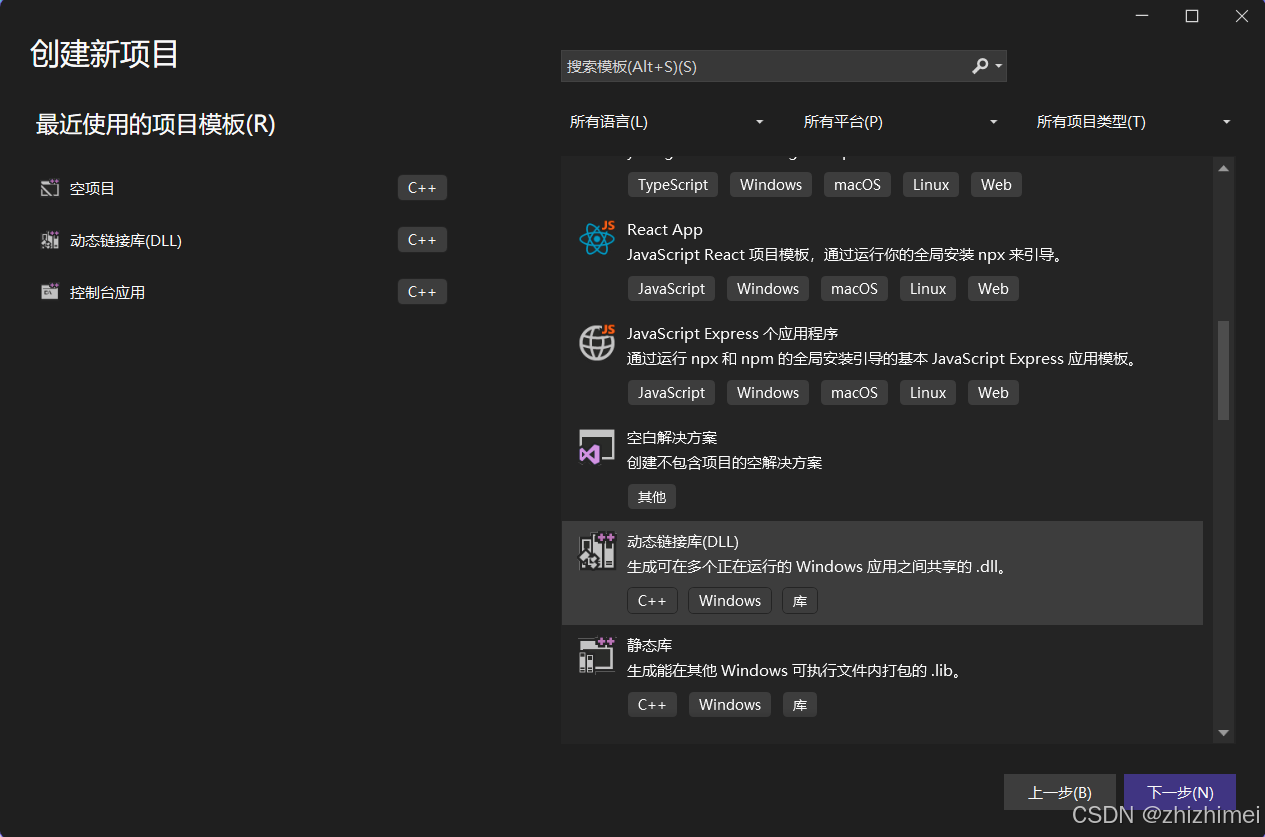
编辑项目名称 -> 创建 -> 动态库项目创建完成:
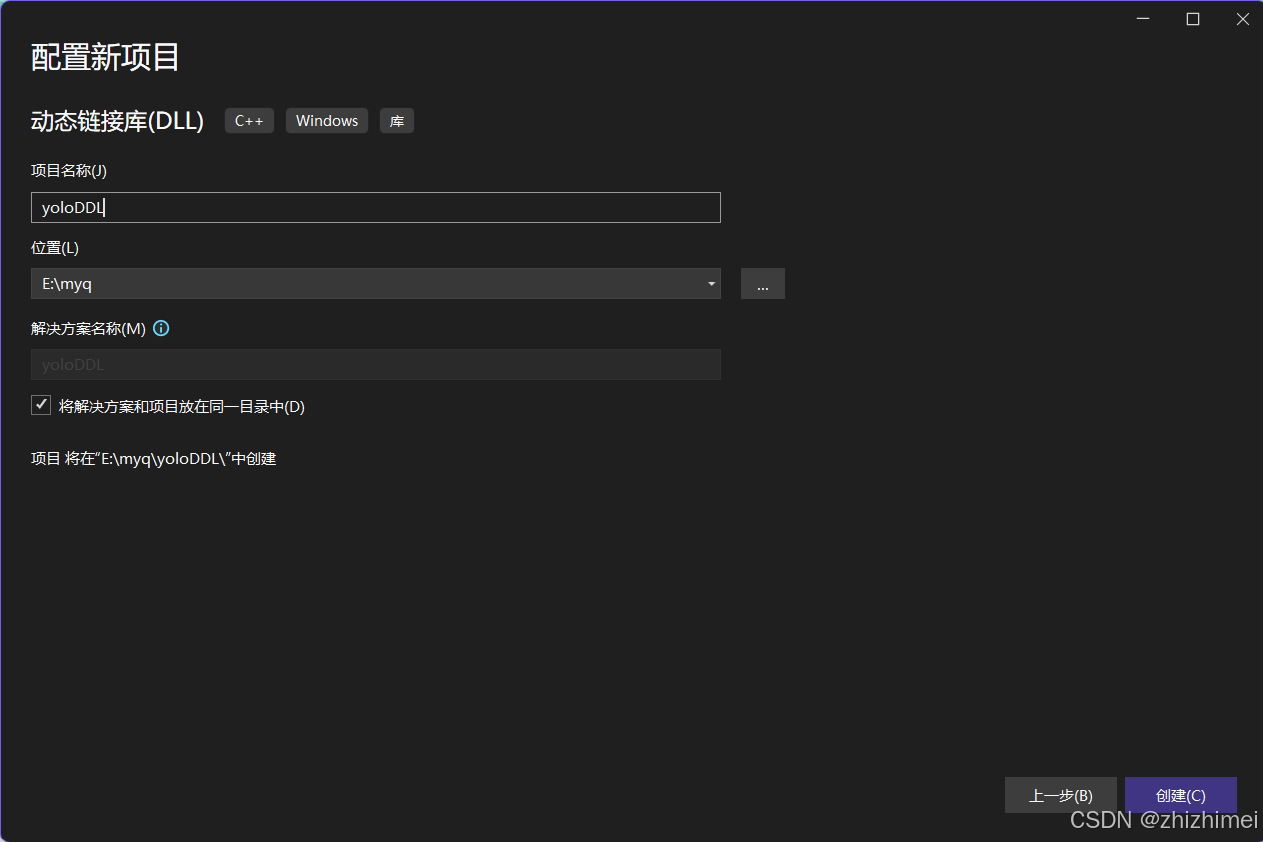
修改解决方案配置:Release + x64(根据自身需求调整,与opencv静态库的配置保持一致即可):
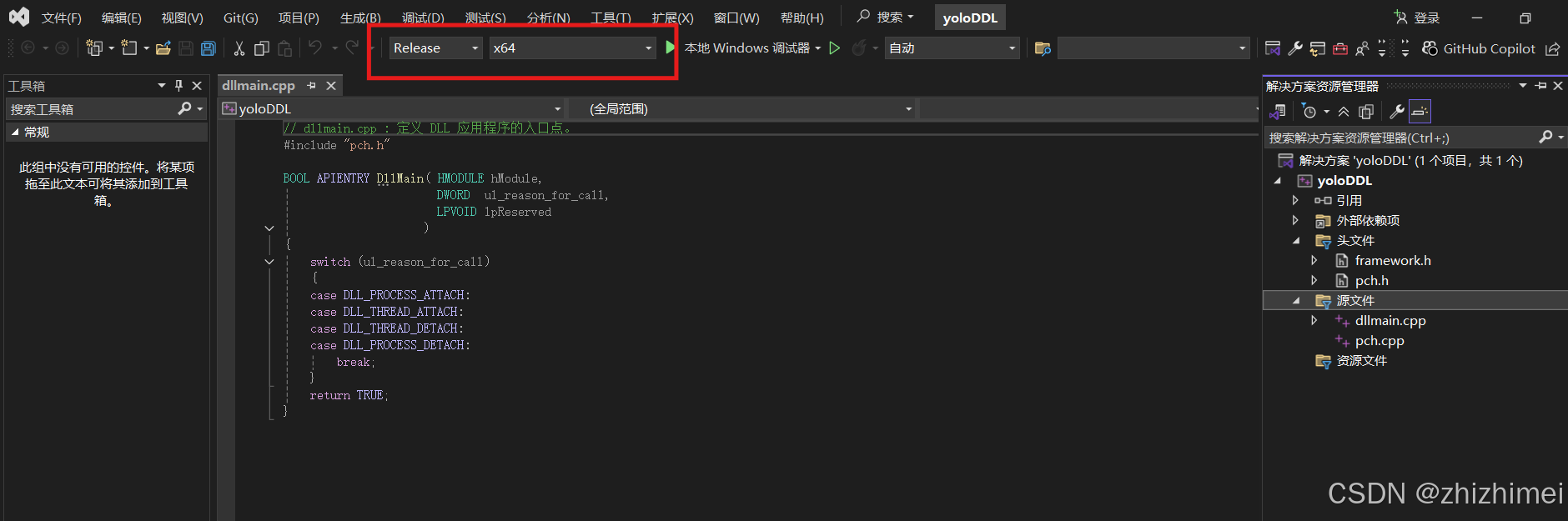
修改yoloDDL属性页 -> 常规 -> C++语言标准:ISO C++17
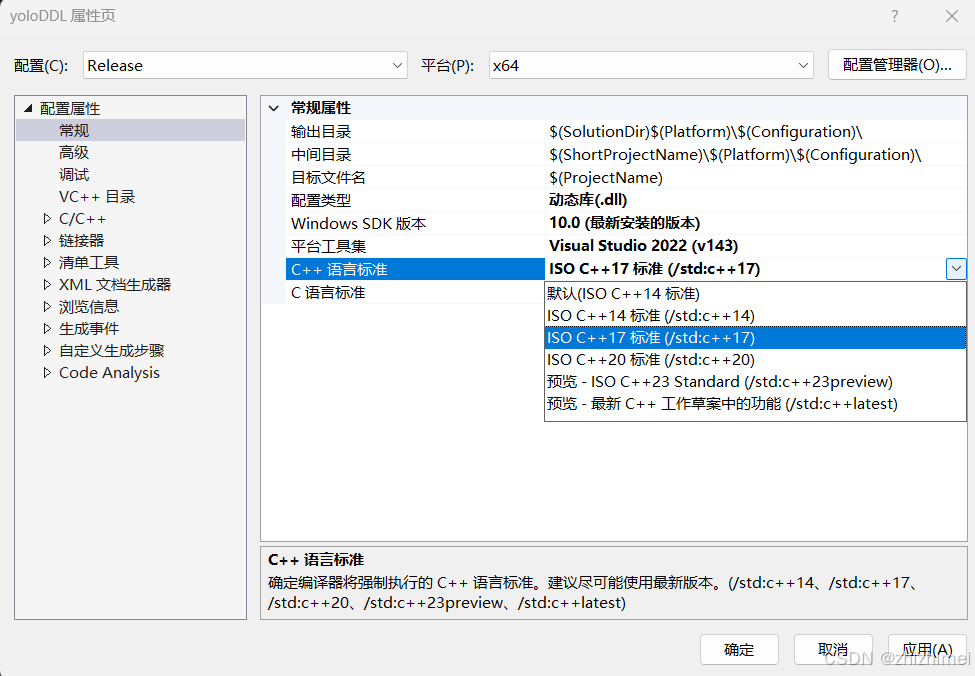
修改C/C++ -> 命令行 下的其他选项添加:/Zc:__cplusplus
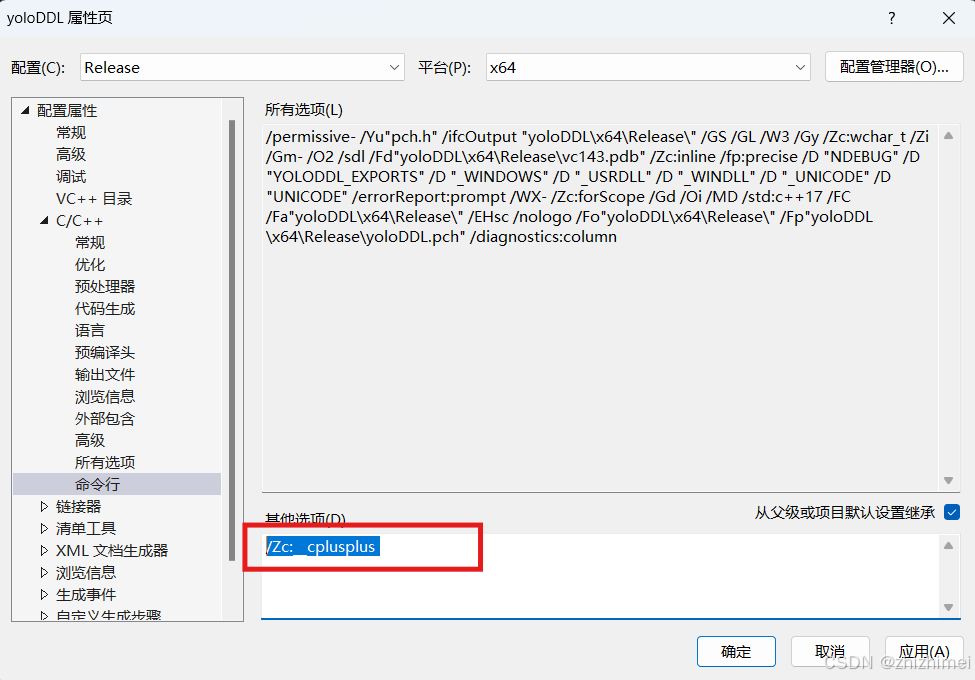
修改 C/C++ -> 预编译头下的预编译头选项:不使用预编译头
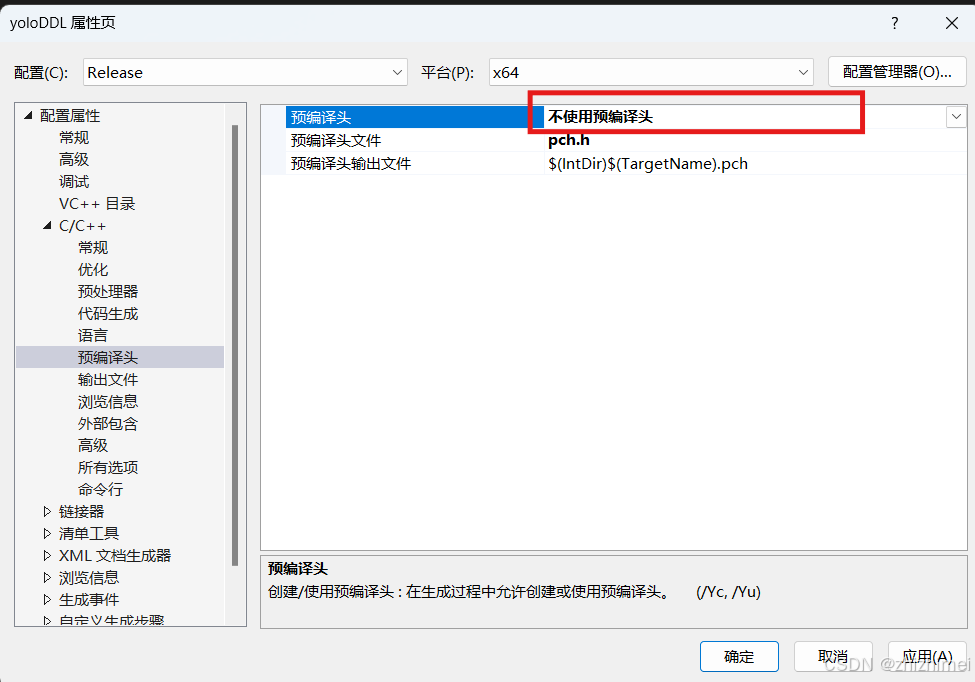
完成上述配置后可以删除初始化自带的头文件和源文件,便于后面新建
2. 配置OpenCV静态库
点击项目 -> yoloDDL和属性
如果点击项目后出来的不是 “项目名称” + “和属性”,鼠标点击项目中任意位置选中后再试
(1)修改VC++目录下的包含目录:选择OpenCV编译后的include文件夹
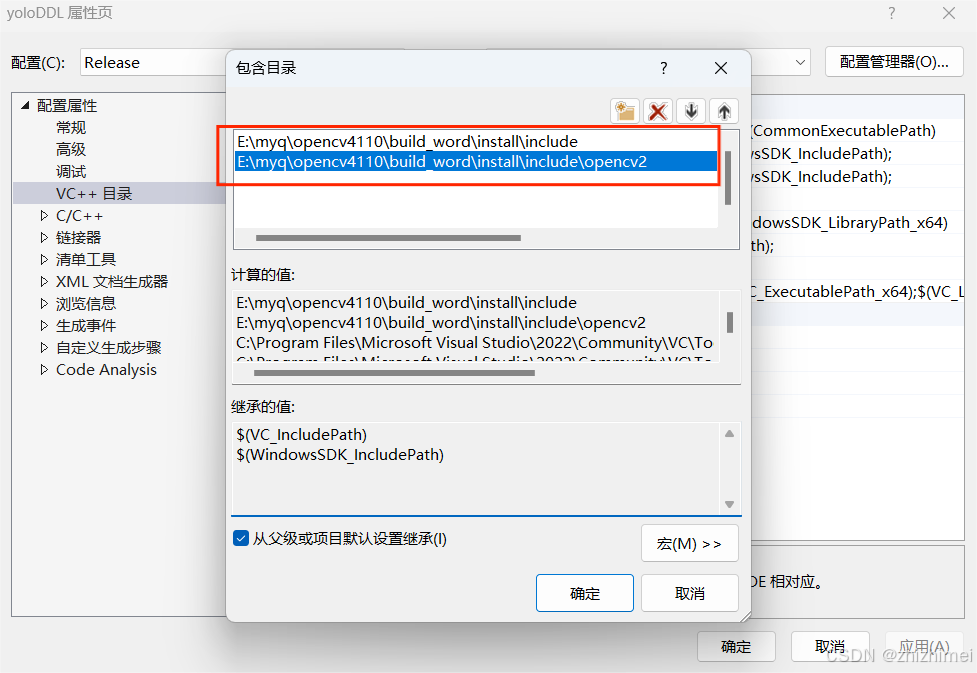
(2)修改VC++目录下的库目录:选择OpenCV编译后的静态库文件夹
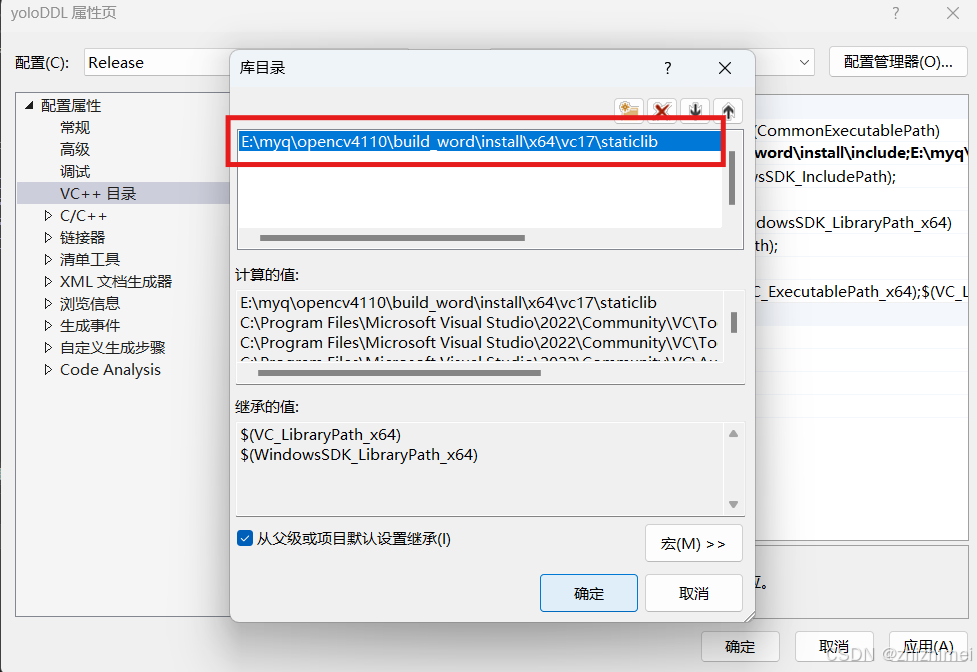
(3)修改链接器 ->常规下的附加库目录:选择OpenCV编译后的静态库文件夹
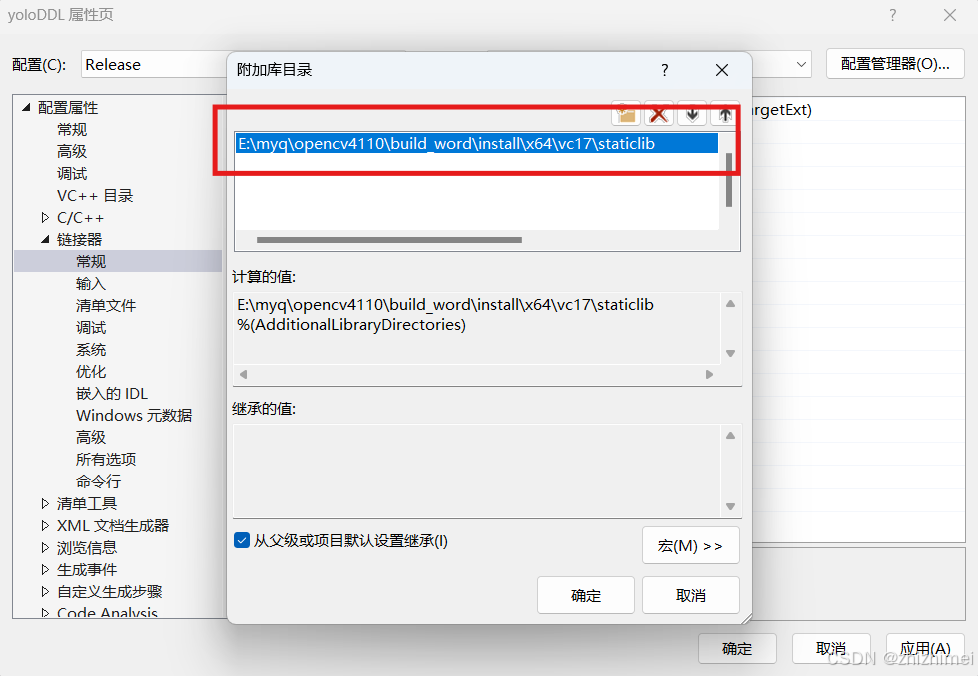
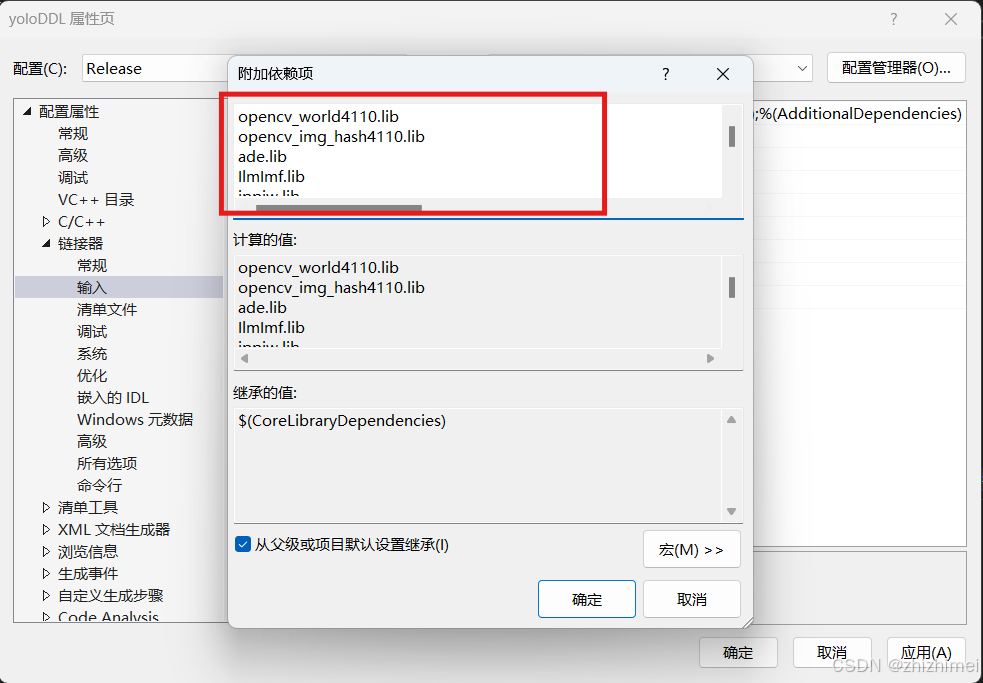
(4)修改链接器 ->输入下的附加依赖项:输入OpenCV编译后的静态库中的.lib文件
opencv_world4110.lib
opencv_img_hash4110.lib
ade.lib
IlmImf.lib
ippiw.lib
ittnotify.lib
libjpeg-turbo.lib
libpng.lib
libprotobuf.lib
libtiff.lib
libwebp.lib
zlib.lib
ippicvmt.lib
libopenjp2.lib
3. 使用OpenCV加载YOLO模型进行推理预测
在头文件目录下新建YOLO11nModel.h文件:
#pragma once
#ifndef MY_HEADER_H
#define MY_HEADER_H
#ifdef DLL_EXPORTS
#define DLL_API __declspec(dllexport)
#else
#define DLL_API _declspec(dllimport)
#endif#include <opencv2/opencv.hpp>//=========导出函数C++调用接口============
class DLL_API YOLO11nModel {
public:YOLO11nModel(const std::string& onnx_path, const std::string& images_path);~YOLO11nModel();
};#endif
在源文件目录下新建YOLO11nModel.cpp文件:
#define DLL_EXPORTS
#include "yolo11nModel.h"
#include <iostream>#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include "stdio.h"
#include <filesystem>
#include <fstream>using namespace cv;
using namespace cv::dnn;
using namespace std;
namespace fs = std::filesystem;const float INPUT_WIDTH = 640.0;
const float INPUT_HEIGHT = 640.0;
const float SCORE_THRESHOLD = 0.3;
const float NMS_THRESHOLD = 0.4;struct Detection
{int class_id;float confidence;cv::Rect box;
};// 获取待检测jpg图片
std::vector<std::string> getJpgFiles(const std::string& dir) {if (!fs::exists(dir)) {std::cout << "图片路径 " << dir << " 不合法!" << std::endl;}std::vector<std::string> files;if (fs::is_directory(dir)) {for (const auto& entry : fs::recursive_directory_iterator(dir)) {if (fs::is_regular_file(entry) && entry.path().extension() == ".jpg") {files.push_back(entry.path().string());}}}else if (fs::is_regular_file(dir)) {files.push_back(dir);}else {std::cerr << dir << " 不是普通文件和目录!";}return files;
}// 信箱缩放函数
cv::Mat letterbox(const cv::Mat& image, int& dw, int& dh, const cv::Size& new_shape = cv::Size(640, 640), int stride = 32, const cv::Scalar& color = cv::Scalar(114, 114, 114)) {cv::Size shape = image.size();float r = std::min(static_cast<float>(new_shape.height) / shape.height, static_cast<float>(new_shape.width) / shape.width);int new_unpad_w = std::round(shape.width * r);int new_unpad_h = std::round(shape.height * r);cv::Mat resized;cv::resize(image, resized, cv::Size(new_unpad_w, new_unpad_h));dw = new_shape.width - new_unpad_w;dh = new_shape.height - new_unpad_h;dw /= 2;dh /= 2;cv::Mat padded;cv::copyMakeBorder(resized, padded, dh, dh, dw, dw, cv::BORDER_CONSTANT, color);return padded;
}// 图像预处理
cv::Mat preprocess(const cv::Mat& image, const cv::Size& inputSize, int& dw, int& dh) {// 信箱缩放cv::Mat paddedImage = letterbox(image, dw, dh, inputSize);// BGR 转 RGBcv::cvtColor(paddedImage, paddedImage, cv::COLOR_BGR2RGB);// 归一化并转换为 CHW 格式cv::Mat blob = cv::dnn::blobFromImage(paddedImage, 1.0 / 255.0, inputSize, cv::Scalar(), true, false);return blob;
}// 后处理:将检测结果绘制在图像上
void drawDetections(Mat& frame, const vector<Mat>& output, std::vector<std::string> classNames, std::vector<cv::Scalar> color, int dw, int dh) {cv::Mat output0 = cv::Mat(cv::Size(output[0].size[2], output[0].size[1]), CV_32F, (float*)output[0].data).t(); //[bs,84,8400]=>[bs,8400,84]float* data = (float*)output0.data;int net_width = output0.cols;int rows = output0.rows;std::vector<int> class_ids;std::vector<float> confidences;std::vector<cv::Rect> boxes;float factor = std::max(frame.cols / INPUT_WIDTH, frame.rows / INPUT_HEIGHT);for (int r = 0; r < rows; ++r) {cv::Mat scores(1, classNames.size(), CV_32FC1, data + 4);cv::Point class_id_point;double max_class_socre;minMaxLoc(scores, 0, &max_class_socre, 0, &class_id_point);//cout << scores << endl;max_class_socre = (float)max_class_socre;if (max_class_socre >= SCORE_THRESHOLD) {//rect [x,y,w,h]float x = data[0];float y = data[1];float w = data[2];float h = data[3];//cout << x << ", " << y << ", " << w << ", " << h << endl;int left = int((x - dw - 0.5 * w) * factor);int top = int((y - dh - 0.5 * h) * factor);int width = int(w * factor);int height = int(h * factor);boxes.push_back(cv::Rect(left, top, width, height));class_ids.push_back(class_id_point.x);confidences.push_back(max_class_socre);}data += net_width;//next line}std::vector<int> nms_result;cv::dnn::NMSBoxes(boxes, confidences, SCORE_THRESHOLD, NMS_THRESHOLD, nms_result);std::vector<Detection> detetctResults;for (int i = 0; i < nms_result.size(); i++) {int idx = nms_result[i];Detection result;result.class_id = class_ids[idx];result.confidence = confidences[idx];result.box = boxes[idx];detetctResults.push_back(result);}for (int i = 0; i < detetctResults.size(); i++){int left, top;left = detetctResults[i].box.x;top = detetctResults[i].box.y;int color_num = i;rectangle(frame, detetctResults[i].box, color[detetctResults[i].class_id], 1.4, 8);std::string label = classNames[detetctResults[i].class_id] + ":" + std::to_string(detetctResults[i].confidence);int baseLine;cv::Size labelSize = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);top = std::max(top, labelSize.height);putText(frame, label, cv::Point(left, top), cv::FONT_HERSHEY_SIMPLEX, 0.6, color[detetctResults[i].class_id], 2);}
}// 为每个类别生成颜色
std::vector<cv::Scalar> colorGenerator() {std::vector<cv::Scalar> color;std::srand(time(0));//使用当前时间作为随机数种子for (int i = 0; i < 80; i++) // coco数据集有80个类别{int b = rand() % 256;int g = rand() % 256;int r = rand() % 256;color.push_back(cv::Scalar(b, g, r));}return color;
}// 加载数据集类别名称
std::vector<std::string> load_class_list()
{std::vector<std::string> class_list;std::ifstream ifs("E:\\myq\\yolo11nDDL\\class.txt");std::string line;while (getline(ifs, line)){class_list.push_back(line);}return class_list;
}YOLO11nModel::YOLO11nModel(const std::string& onnx_path, const std::string& images_path) {if (!fs::exists(onnx_path) || !fs::is_regular_file(onnx_path)) {std::cout << "onnx模型文件 " << onnx_path << " 不是合法的文件路径!" << std::endl;}// 获取待推理图像std::vector<std::string> images = getJpgFiles(images_path);// 推理结果保存路径fs::path basePath = fs::current_path();fs::path inferPath = basePath / "infer";if (!fs::exists(inferPath)) {fs::create_directory(inferPath);}// 获取数据集类别名称std::vector<std::string> class_list = load_class_list();std::vector<cv::Scalar> class_color = colorGenerator();// 从 ONNX 文件中读取模型cv::dnn::Net net = readNetFromONNX(onnx_path);// 设置后端(可以根据环境选择 CPU/GPU)net.setPreferableBackend(DNN_BACKEND_OPENCV);net.setPreferableTarget(DNN_TARGET_CPU);// 检查模型是否成功加载if (net.empty()) {std::cerr << "Failed to load network!" << std::endl;}else {std::cout << "The YOLO model has been loaded!" << std::endl;}// 图像推理for (std::string image : images) {Mat img = imread(image);if (img.empty()) {std::cerr << "无法加载图像 " << image << " !";}Size inputSize(640, 640);int dw = 0, dh = 0;Mat inputBob = preprocess(img, inputSize, dw, dh);net.setInput(inputBob);std::vector<Mat> output;// ====== 推理并计时 ======auto start = chrono::high_resolution_clock::now(); // 记录时间net.forward(output, net.getUnconnectedOutLayersNames()); // 推理auto end = chrono::high_resolution_clock::now(); // 结束时间chrono::duration<double> elapsed = end - start; // 计算推理时间// 输出推理时间cout << image << " 推理时间: " << elapsed.count() * 1000 << " ms" << endl;// ====== 绘制结果 ======drawDetections(img, output, class_list, class_color, dw, dh);// ====== 保存结果 ======fs::path filePath = image;fs::path savePath = inferPath / filePath.filename().string();imwrite(savePath.string(), img);}cout << "推理完成!" << endl;
}YOLO11nModel::~YOLO11nModel() {//std::cout << "destory instance done!" << std::endl;
}
执行编译(图中报错可忽略):
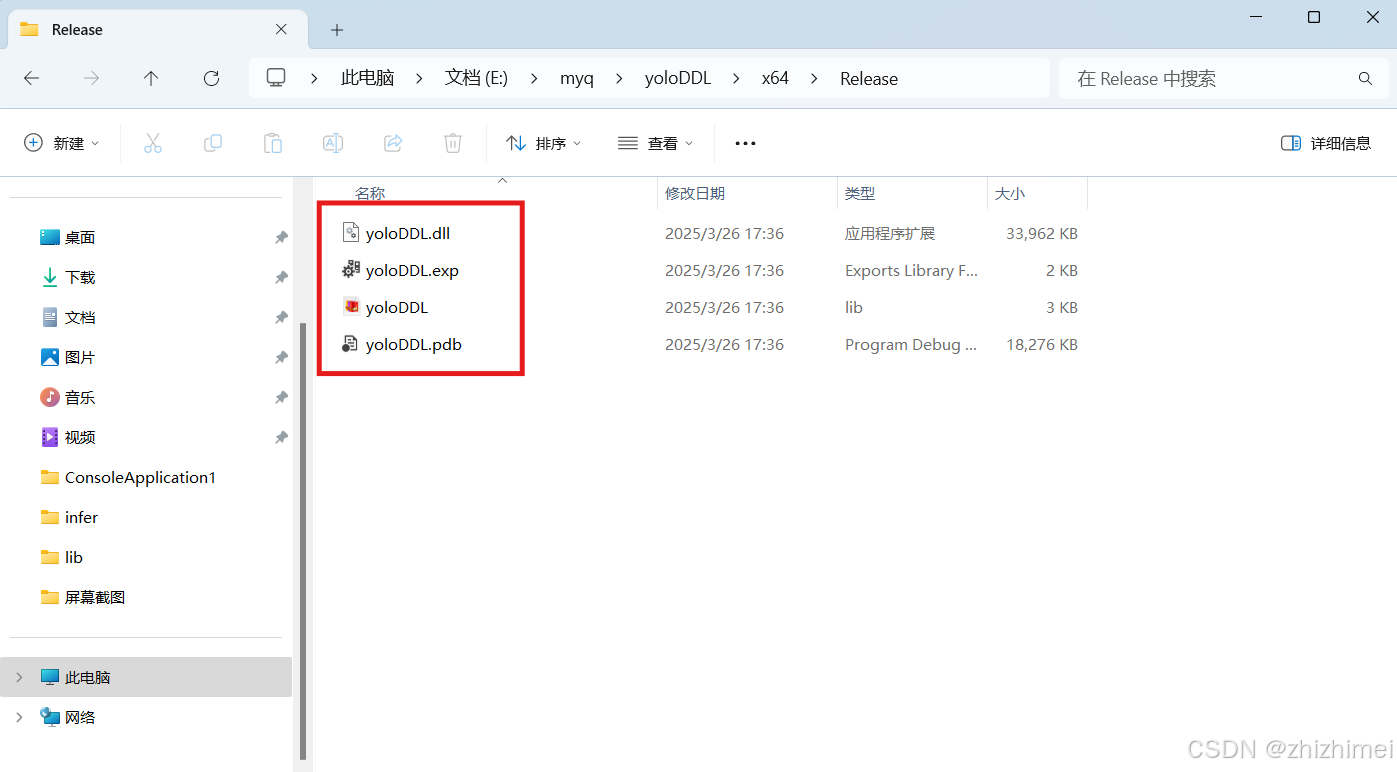
在文件夹中查看链接了OpenCV静态库的YOLO动态库文件:
因为连接了OpenCV静态库,所以生成.ddl文件较大,这样做的好处是在目标平台上调用YOLO动态库时不需要再在目标平台上配置OpenCV环境了
五、DDL动态库验证
1. 创建新项目
打开Visual Studio 2022新建一个控制台新项目:
修改编译配置:Release - x64
2. Yolo动态库配置
(1)在YoloDdlTest文件夹下新建include文件夹,分别拷贝文件yolo11nModel.h和OpenCV静态库的头文件夹include/opencv2到include中:
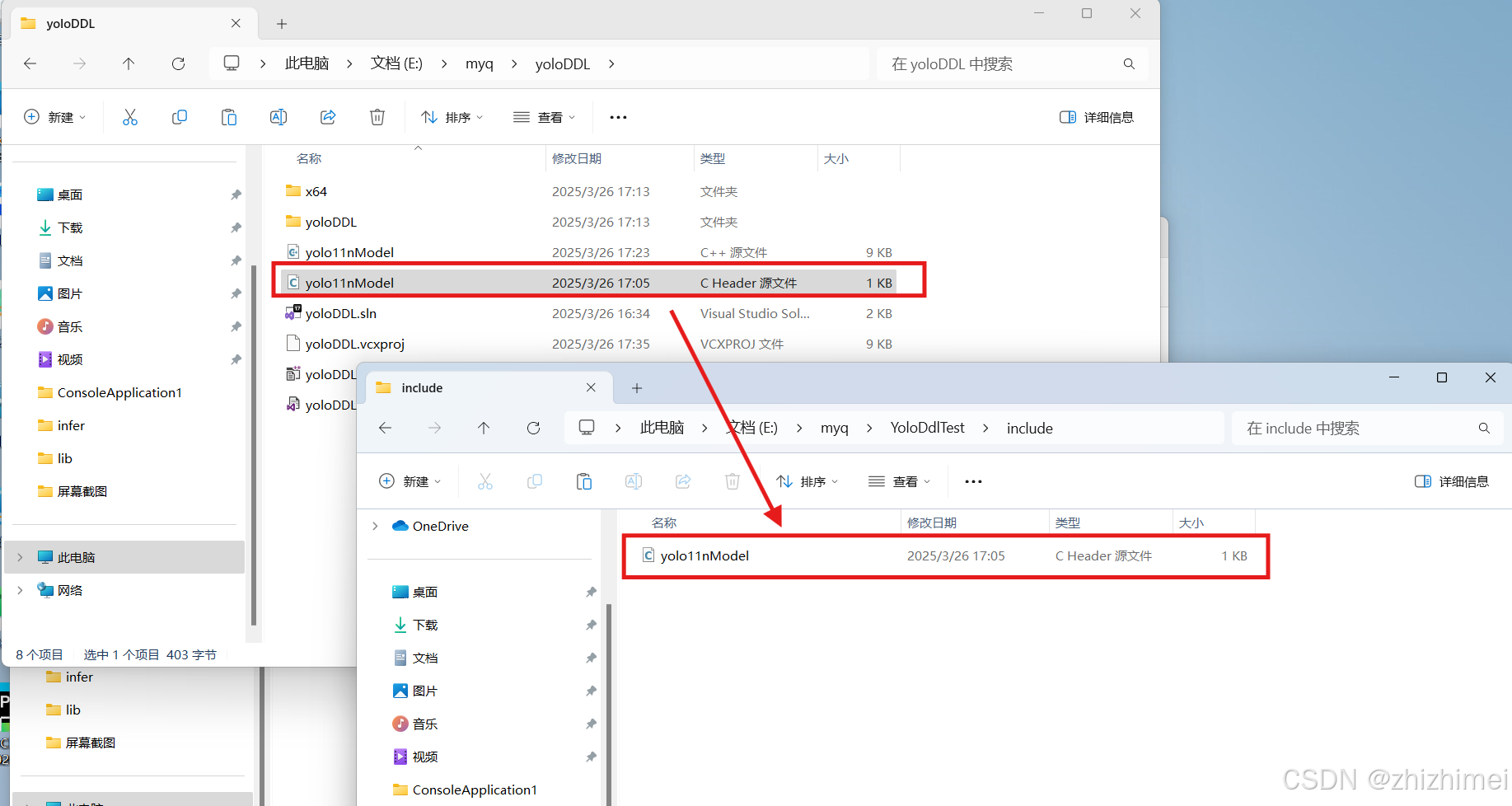
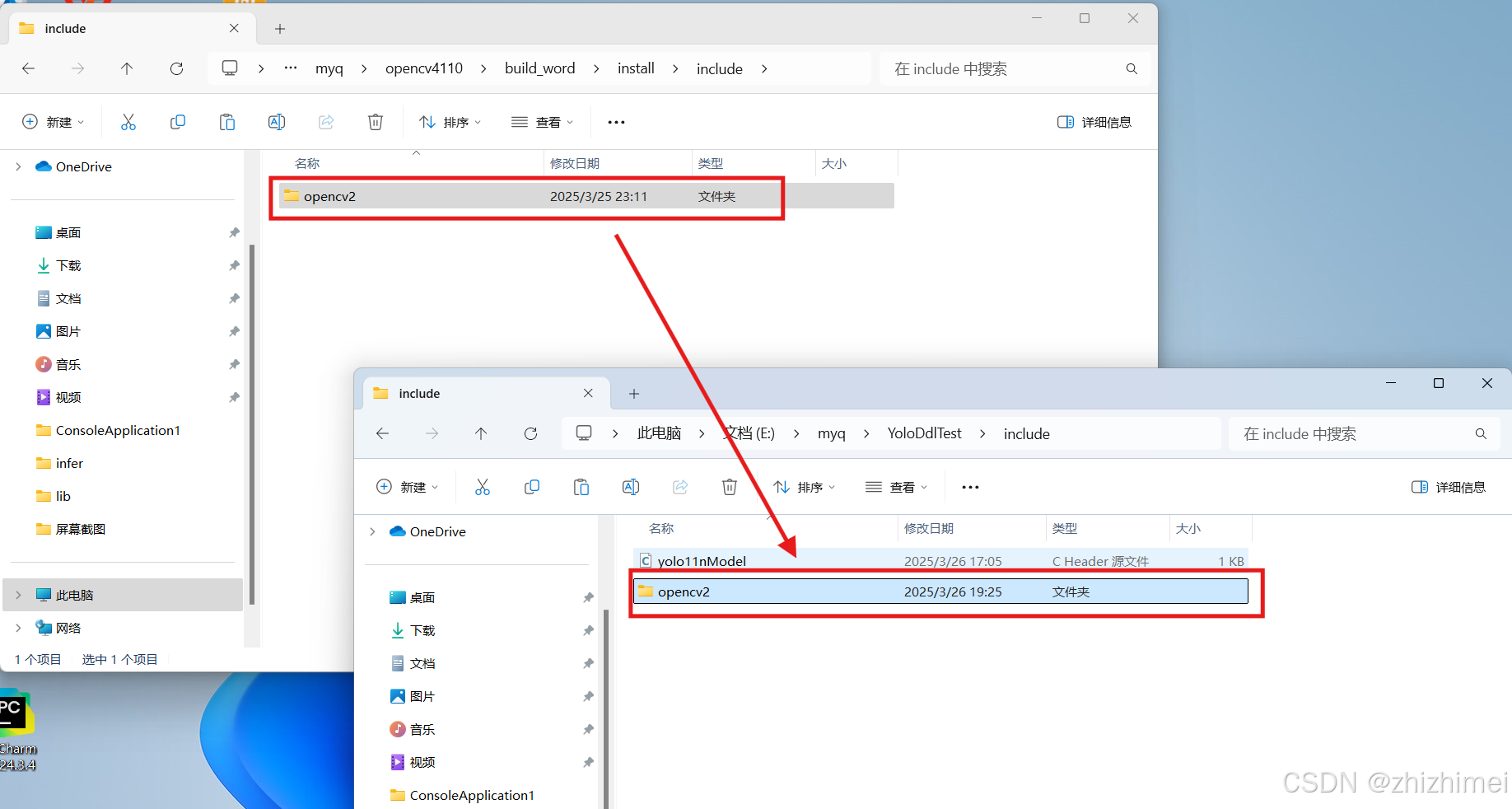
(2)新建lib文件夹,分别将YOLO动态库生成的yoloDDLl.lib和yoloDDL.ddl、OpenCV的静态库文件夹staticlib拷贝到这里:
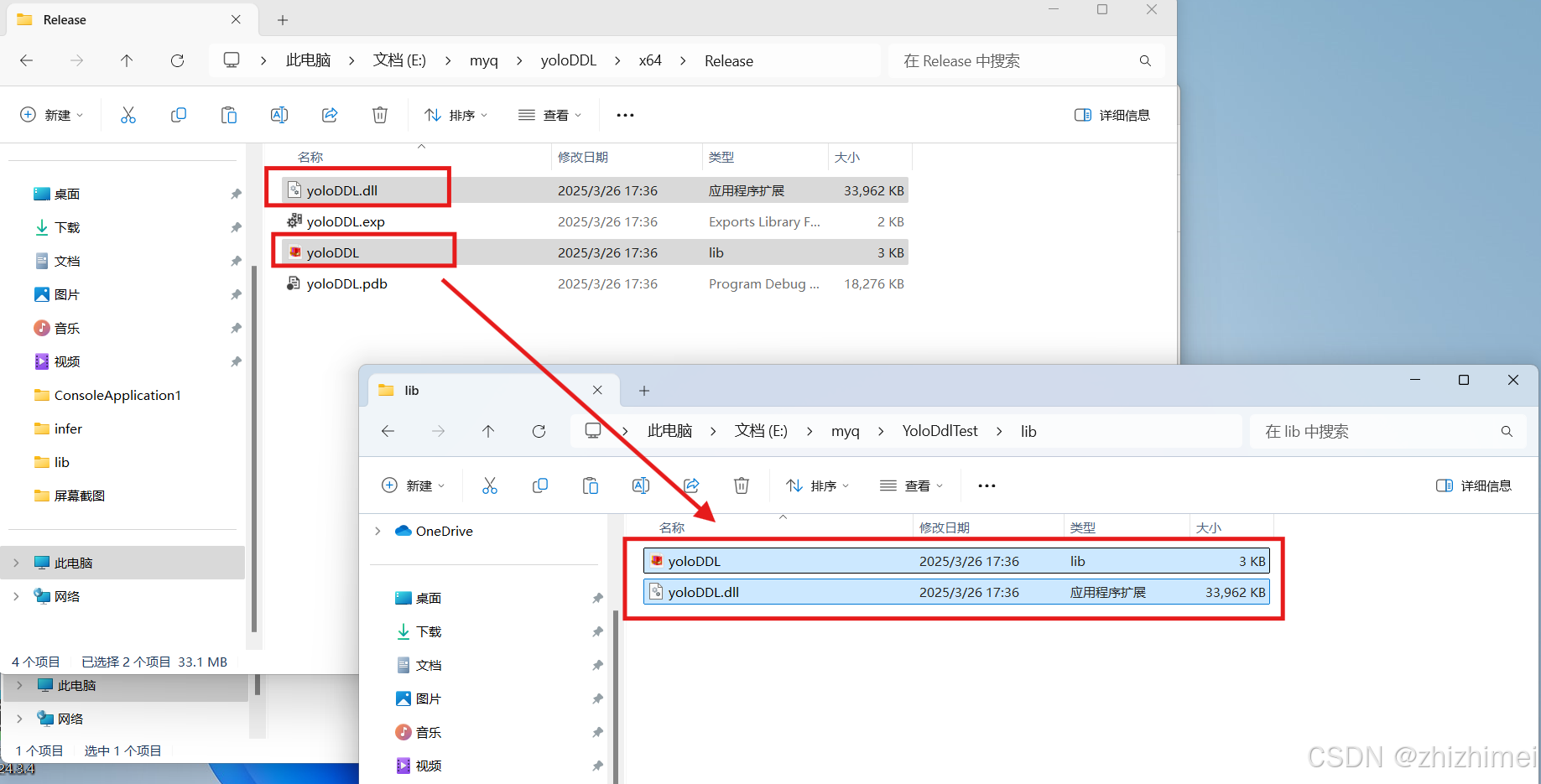
(3)将yolo11DDL.ddl文件拷贝到下列位置:
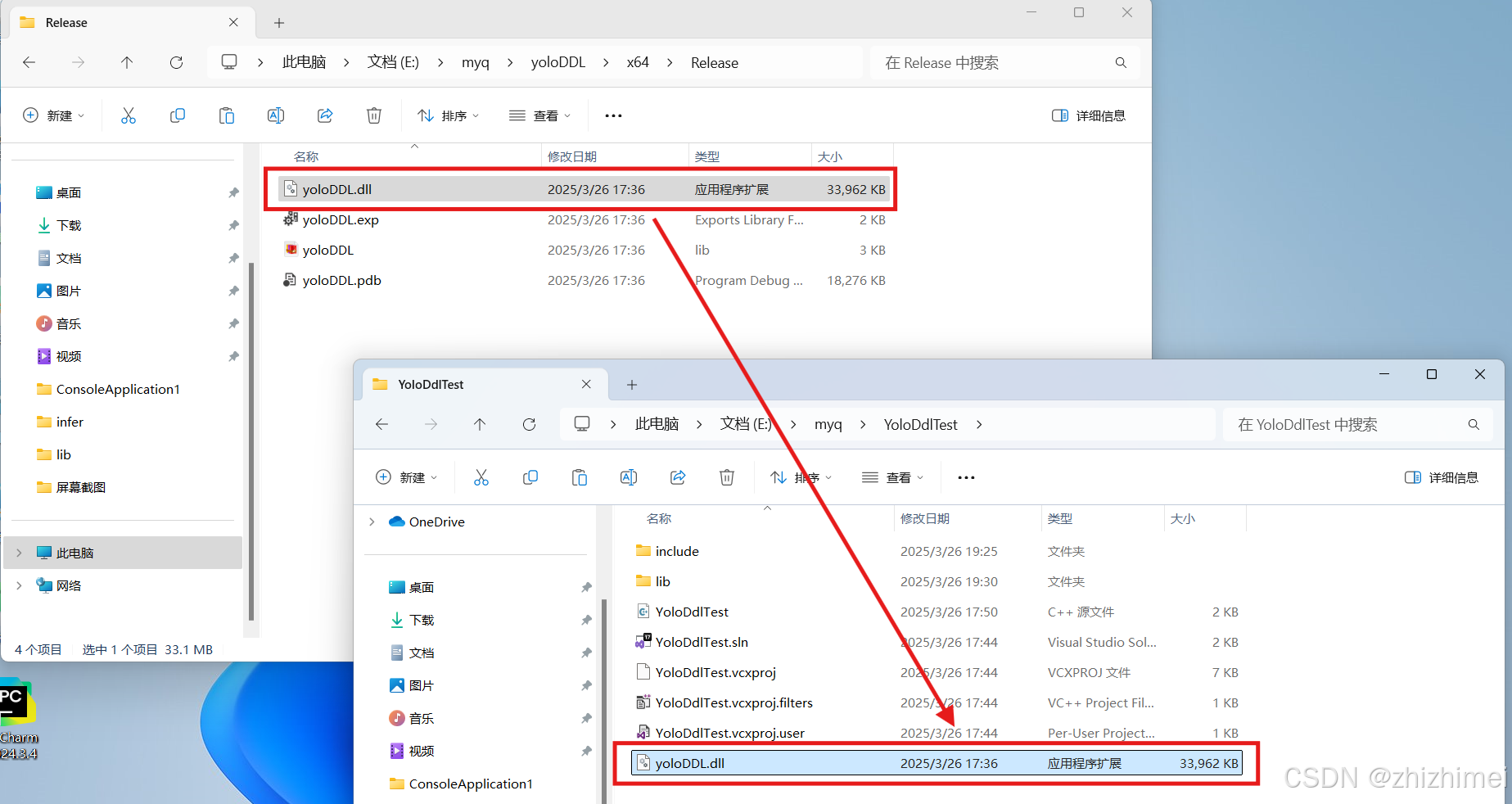
(4)VS2022 -> 项目 -> YoloDdlTest和属性,修改项目属性配置
- 常规 -> C++ 语言标准:ISO C++17
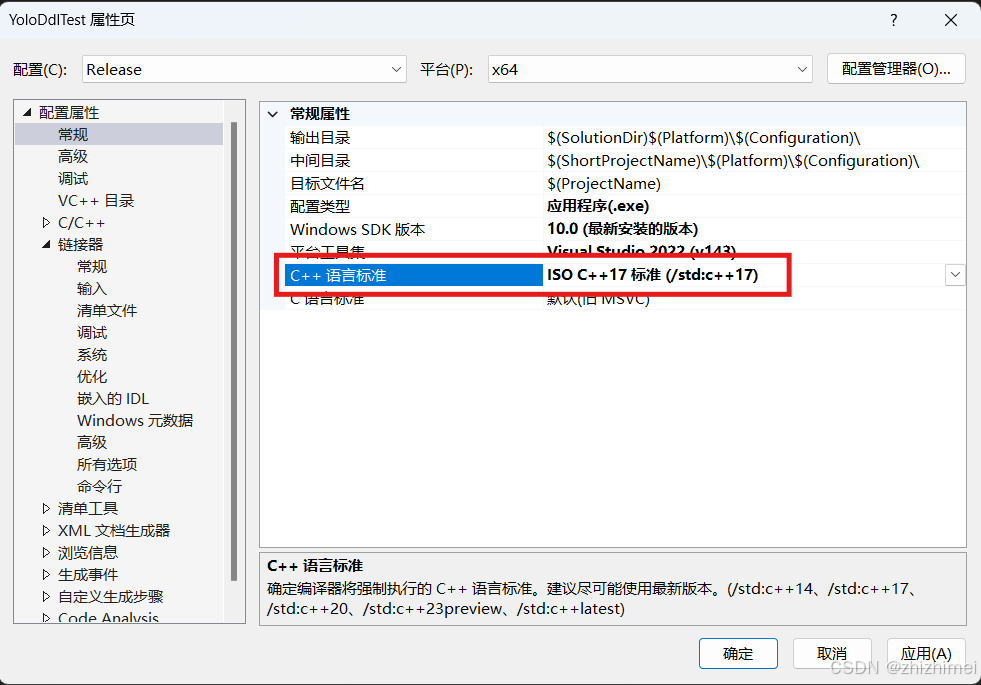
- VC++ 目录 -> 包含目录:设置为项目的include目录
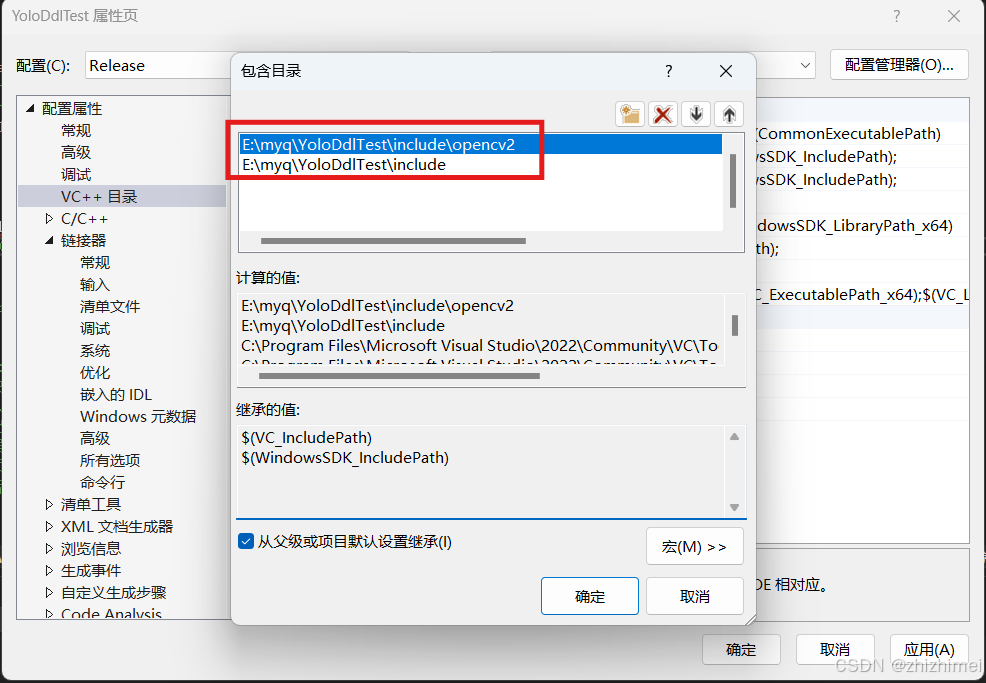
- VC++ 目录 -> 库目录:设置为项目的lib目录
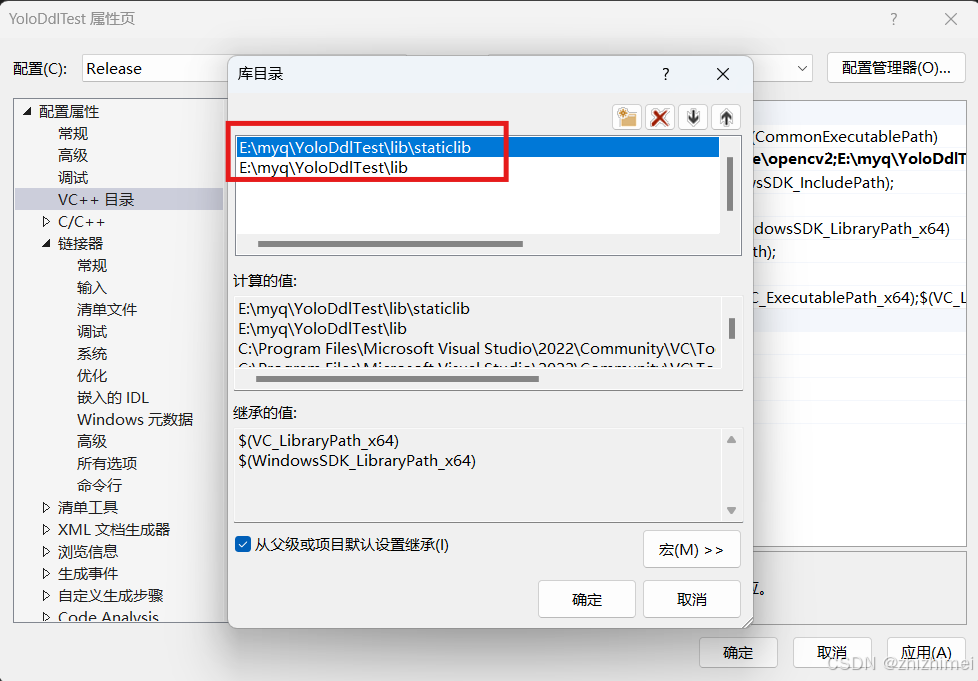
- 链接器 -> 常规 -> 附加库目录:设置为项目的lib目录
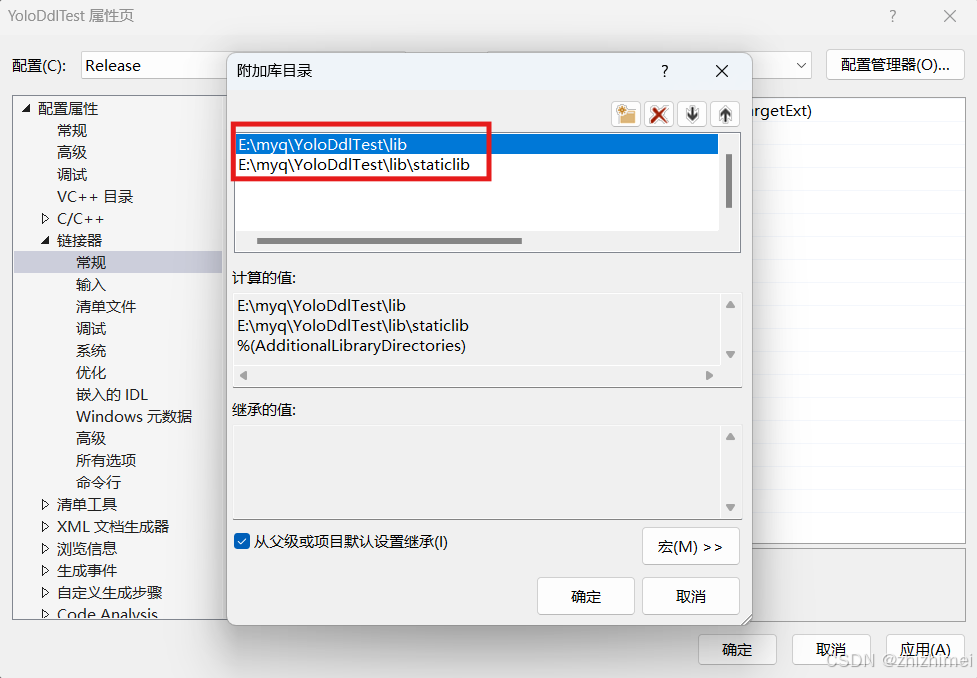
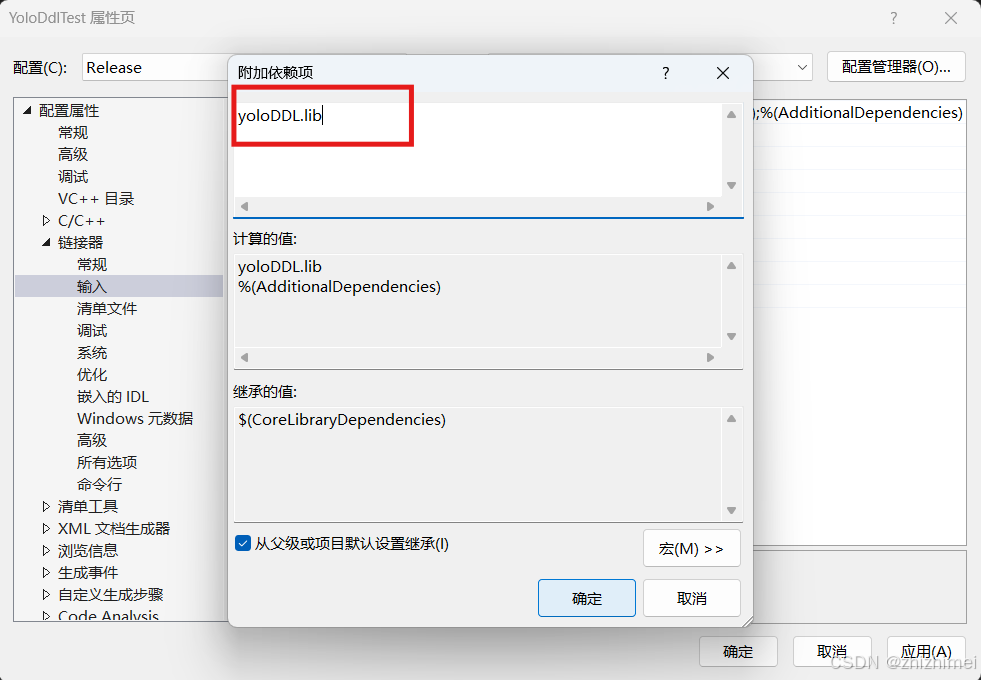
- 链接器 -> 输入 -> 附加依赖项:
yoloDDL.lib
3. 动态库调用
编辑YoloDdlTest.cpp文件:
#include "stdio.h"
#include <iostream>
#include <yolo11nModel.h>int main()
{YOLO11nModel::YOLO11nModel("E:\\myq\\yolo11nDDL\\yolo11n.onnx", "E:\\myq\\ultralytics-main\\datasets\\coco\\images\\val2017");//cvWaitKey(6000);
}
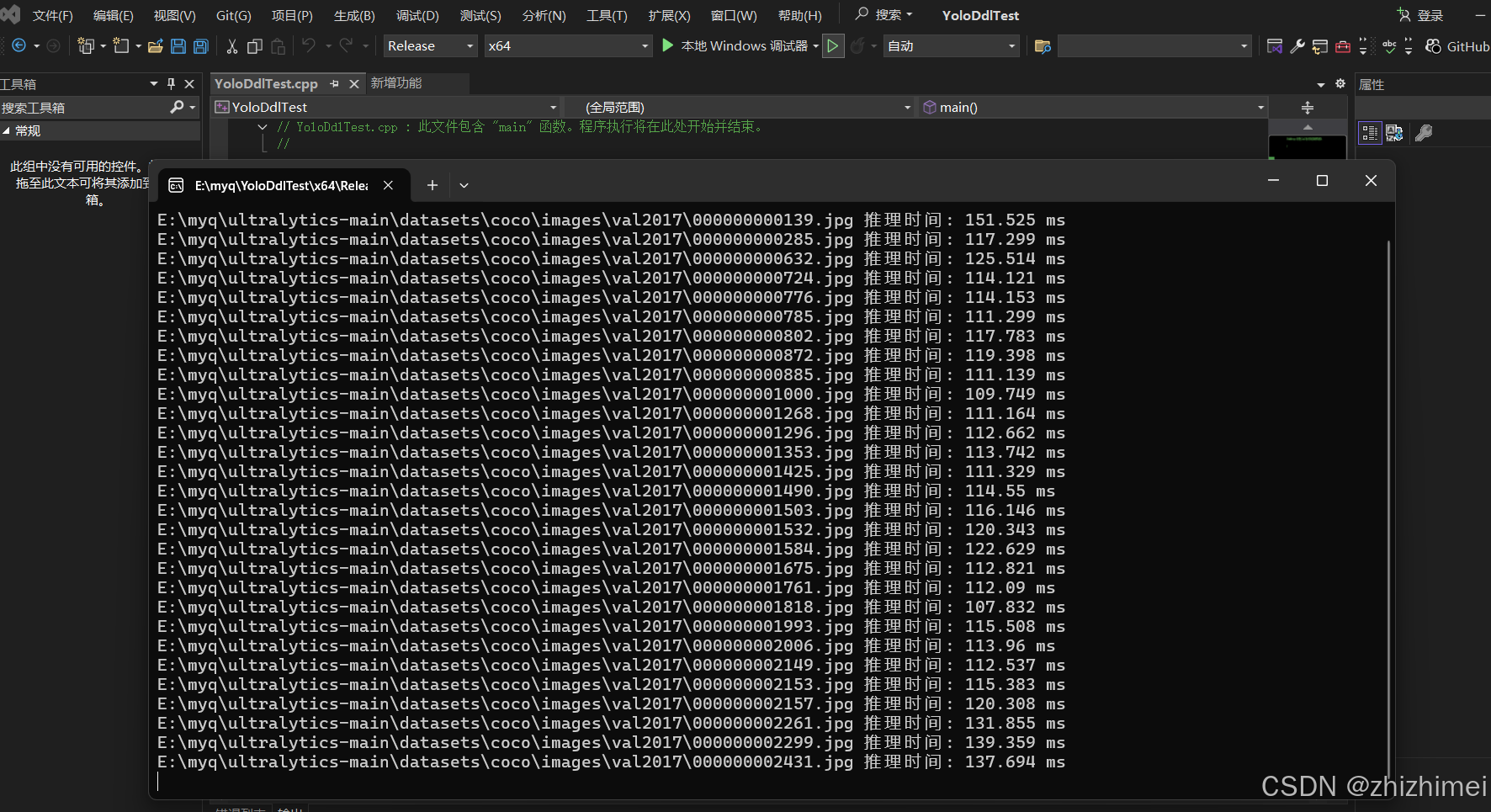
编译运行:通过动态库成功调用YOLO模型!
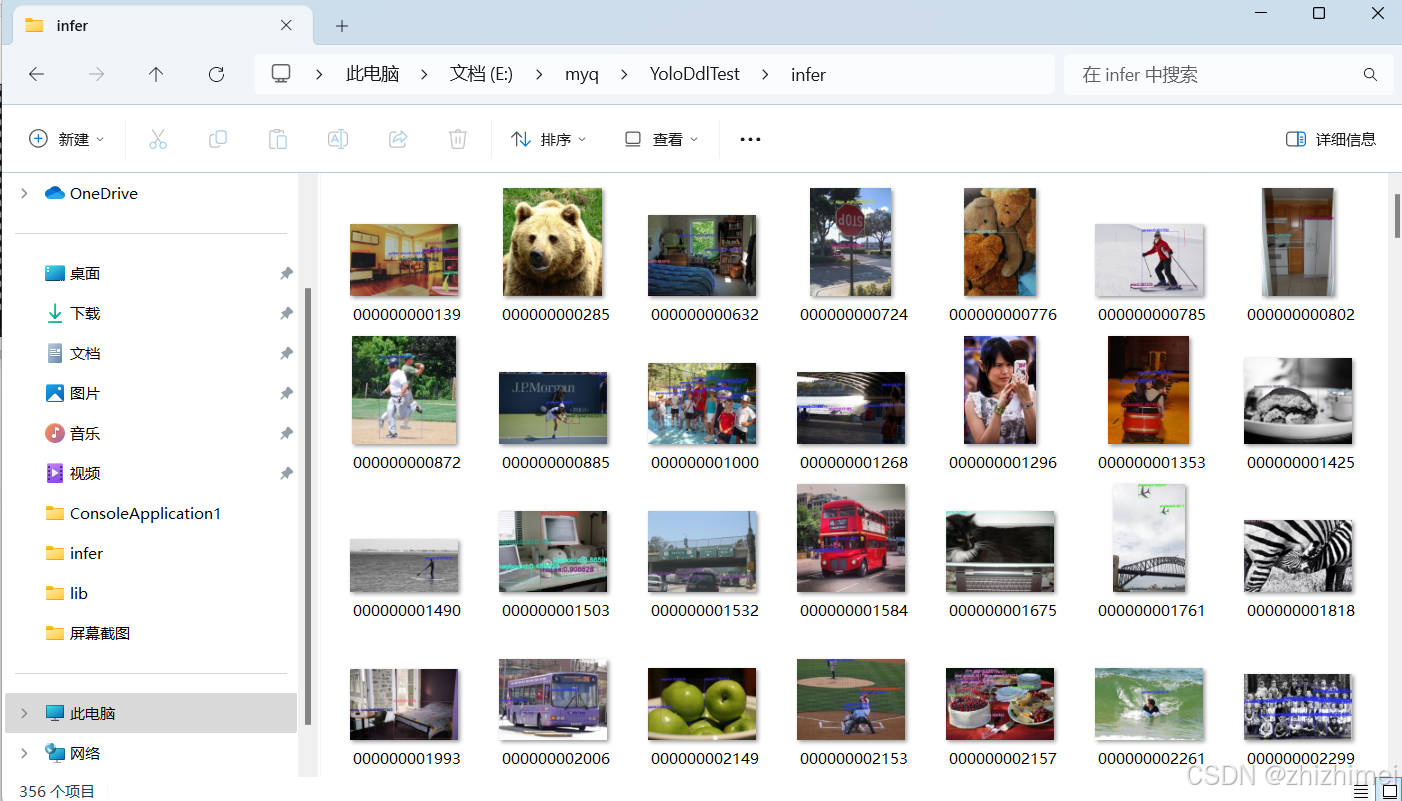
在infer文件夹下能看到推理图:

总结
至此,YOLO11n 的动态库封装与部署流程圆满完成!生成的动态库已可在目标平台上直接调用,助力模型快速集成与部署。希望这篇文章能为你在实际开发中提供一些实用的参考和帮助,少踩坑、快落地!







![[嵌入式实验]实验四:串口打印电压及温度](https://i-blog.csdnimg.cn/direct/447a807c000f4538aa4f05dd4172c828.png)