- 图像数据的格式:灰度和彩色数据
- 模型的定义
- 显存占用的4种地方
- 模型参数+梯度参数
- 优化器参数
- 数据批量所占显存
- 神经元输出中间状态
- batchisize和训练的关系
作业:今日代码较少,理解内容即可
一、图像数据的介绍
结构化数据(如表格)的形状通常是 (样本数, 特征数)
图像数据的形状更复杂,需要保留空间信息(高度、宽度、通道),不能直接用一维向量表示。其中,颜色信息往往是最开始输入数据的通道的含义,因为每个颜色可以用红绿蓝三原色表示,因此一般输入数据的通道数是 3。

1.灰度图像
2.彩色图像
在 PyTorch 中,图像数据的形状的格式是 (通道数, 高度, 宽度) ,即 Channel First 格式。这与常见的 (高度, 宽度, 通道数)格式不同,Channel Last 格式,如 NumPy 数组。---注意顺序关系
注意点:
1. 如果用matplotlib库来画图,需要转换下顺序,我们后续介绍
2. 模型输入还需要加入 批次维度(Batch Size),形状变为 (批次大小, 通道数, 高度, 宽度)。例如,批量输入 10 张 MNIST 图像时,形状为 (10, 1, 28, 28)。
二、图像相关神经网络定义
1.黑白图像
# 先归一化,再标准化
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差,这个值很出名,所以直接使用
])
import matplotlib.pyplot as plt# 2. 加载MNIST数据集,如果没有会自动下载
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 定义两层MLP神经网络
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸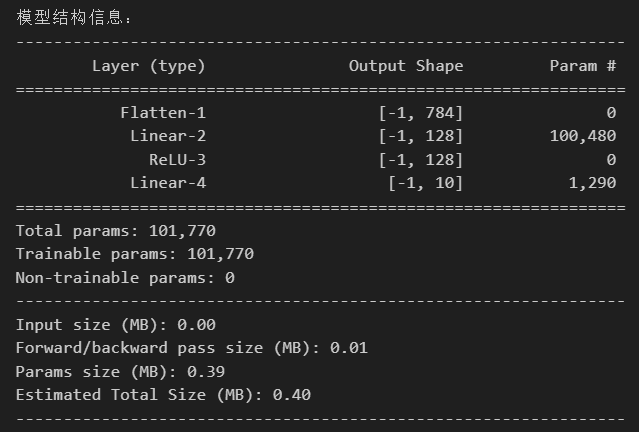
图像MLP与之前结构化MLP的差异对比
(1)输入图像,需要展平操作
MLP 的输入层要求输入是一维向量,但 MNIST 图像是二维结构(28×28 像素),形状为 [1, 28, 28](通道 × 高 × 宽)。
通过nn.Flatten()展平操作,将二维图像 “拉成” 一维向量(784=28×28 个元素),使其符合全连接层的输入格式。其中不定义这个flatten方法,直接在前向传播的过程中用 x = x.view(-1, 28 * 28) 将图像展平为一维向量也可以实现
(2)输入数据的尺寸包含了通道数input_size=(1, 28, 28)
(3)参数的计算
第一层 layer1(全连接层)
权重参数:输入维度 × 输出维度 = 784 × 128 = 100,352
偏置参数:输出维度 = 128
合计:100,352 + 128 = 100,480
第二层 layer2(全连接层)
权重参数:输入维度 × 输出维度 = 128 × 10 = 1,280
偏置参数:输出维度 = 10
合计:1,280 + 10 = 1,290
- 总参数:100,480(layer1) + 1,290(layer2) = 101,770
2.彩色图像
class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size=128, num_classes=10):super(MLP, self).__init__()# 展平层:将3×32×32的彩色图像转为一维向量# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072self.flatten = nn.Flatten()# 全连接层self.fc1 = nn.Linear(input_size, hidden_size) # 第一层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]x = self.relu(x) # 激活函数x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]return x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32)3.batch_size——批次维度
PyTorch 模型会自动处理 batch 维度(即第一维),无论 batch_size 是多少,模型的计算逻辑都不变。
class MLP(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # nn.Flatten()会将每个样本的图像展平为 784 维向量,但保留 batch 维度。self.layer1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.layer2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x) # 输入:[batch_size, 1, 28, 28] → [batch_size, 784]x = self.layer1(x) # [batch_size, 784] → [batch_size, 128]x = self.relu(x)x = self.layer2(x) # [batch_size, 128] → [batch_size, 10]return x三、占用显存的主要部分
1. 模型参数与梯度:模型的权重(Parameters)和对应的梯度(Gradients)会占用显存,尤其是深度神经网络(如 Transformer、ResNet 等),一个 1 亿参数的模型(如 BERT-base),单精度(float32)参数占用约 400MB(1e8×4Byte),加上梯度则翻倍至 800MB(每个权重参数都有其对应的梯度)
2. 优化器:部分优化器(如 Adam)会为每个参数存储动量(Momentum)和平方梯度(Square Gradient),进一步增加显存占用(通常为参数大小的 2-3 倍)
3. 其他开销:数据批次、前向或反向传播过程中的中间变量


![[Rust_1] 环境配置 | vs golang | 程序运行 | 包管理](https://i-blog.csdnimg.cn/img_convert/6b86288e492f88f7ae5584333dbf4e22.png)