有以下两种方法可供选择。在我们的数据集上运行卷积基,将输出保存为NumPy数组,并保存在硬盘上,然后将这个数组输入到一个独立的密集连接分类器中。这种方法速度快,计算代价低,因为对于每张输入图像只需运行一次卷积基,而卷积基是当前流程中计算代价最高的。但出于同样的原因,这种方法无法使用数据增强。在已有模型(conv_base)上添加Dense层,并在输入数据上端到端地运行整个模型。这样就可以使用数据增强,因为每张输入图像进入模型时都会经过卷积基。但出于同样的原因,这种方法的计算代价比第一种要高很多。以下分别介绍这两种方法。首先来看第一种方法:将conv_base在数据上的输出保存下来,然后将这些输出作为新模型的输入。不使用数据增强的快速特征提取我们将在训练集、验证集和测试集上调用conv_base模型的predict()方法,将特征提取为NumPy数组。我们来遍历数据集,提取VGG16的特征和对应的标签,如代码清单所示。
import numpy as npdef get_features_and_labels(dataset):all_features = []all_labels = []for images, labels in dataset:preprocessed_images = keras.applications.vgg16.preprocess_input(images)features = conv_base.predict(preprocessed_images)all_features.append(features)all_labels.append(labels)return np.concatenate(all_features), np.concatenate(all_labels)train_features, train_labels = get_features_and_labels(train_dataset)
val_features, val_labels = get_features_and_labels(validation_dataset)
test_features, test_labels = get_features_and_labels(test_dataset)
重要的是,predict()只接收图像作为输入,不接收标签,但当前数据集生成的批量既包含图像又包含标签。此外,VGG16模型的输入需要先使用函数keras.applications.vgg16.preprocess_input进行预处理。这个函数的作用是将像素值缩放到合适的范围内。提取的特征形状为(samples, 5, 5, 512)。
>>> train_features.shape
(2000, 5, 5, 512)
接下来,我们可以定义密集连接分类器(注意使用dropout正则化),并在刚刚保存的数据和标签上训练这个分类器,如代码清单所示。
代码清单 定义并训练密集连接分类器
inputs = keras.Input(shape=(5, 5, 512))
x = layers.Flatten()(inputs) ←----请注意,将特征传入Dense层之前,需要先经过Flatten层
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)model.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])callbacks = [keras.callbacks.ModelCheckpoint(filepath="feature_extraction.keras",save_best_only=True,monitor="val_loss")
]
history = model.fit(train_features, train_labels,epochs=20,validation_data=(val_features, val_labels),callbacks=callbacks)
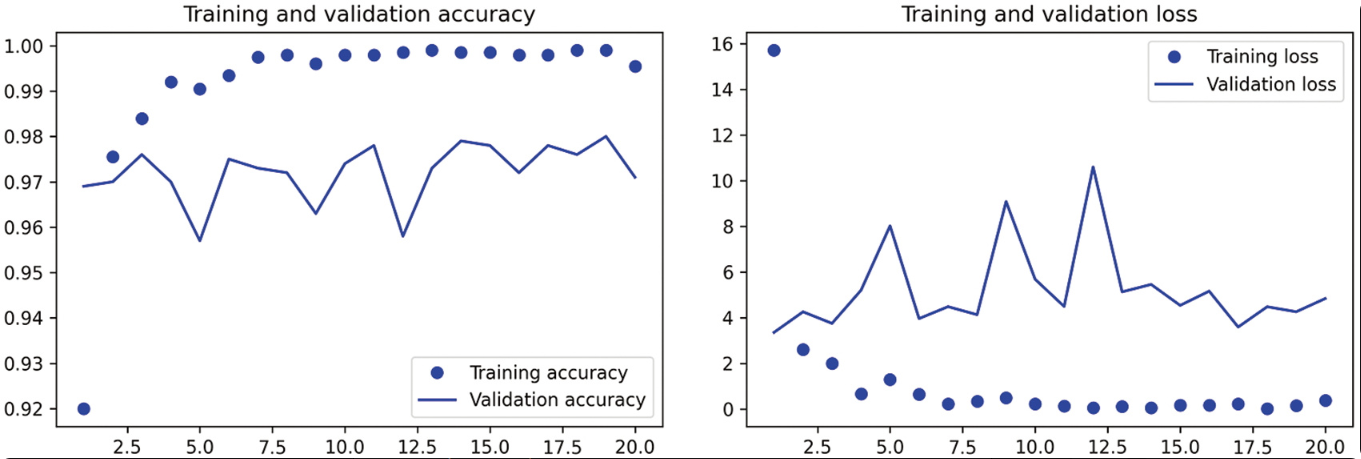
训练速度非常快,因为只需要处理两个Dense层。即使在CPU上运行,每轮的时间也不到1秒。我们来看一下训练过程中的精度曲线和损失曲线。
代码清单 绘制结果
import matplotlib.pyplot as plt
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
验证精度达到约97%,比从头开始训练的小模型要高得多。但这种对比有失公平,因为ImageNet包含许多狗和猫的样本,也就是说,我们的预训练模型已经拥有完成当前任务所需的知识。在使用预训练的特征时,情况并非总是如此。然而,从图中也可以看出,尽管dropout比率很大,但模型几乎从一开始就出现过拟合。这是因为这种方法没有使用数据增强,而数据增强对防止小型图像数据集的过拟合非常重要。
使用数据增强的特征提取
下面我们来看特征提取的第二种方法。它的速度更慢,计算代价更高,但在训练过程中可以使用数据增强。这种方法就是将conv_base与一个新的密集分类器连接起来以创建一个新模型,然后在输入数据上端到端地训练这个模型。为了实现这一方法,首先要冻结卷积基。冻结一层或多层,是指在训练过程中保持其权重不变。如果不这样做,那么卷积基之前学到的表示将会在训练过程中被修改。因为其上添加的Dense层是随机初始化的,所以在神经网络中传播的权重更新将非常大,会对之前学到的表示造成很大破坏。在Keras中,冻结某层或模型的方法是将其trainable属性设为False,如代码清单所示。
代码清单 将VGG16卷积基实例化并冻结
conv_base = keras.applications.vgg16.VGG16(weights="imagenet",include_top=False)
conv_base.trainable = False
将trainable设为False,这将清空该层或模型的可训练权重列表,如代码清单所示。
代码清单 打印冻结前后的可训练权重列表
>>> conv_base.trainable = True
>>> print("This is the number of trainable weights ""before freezing the conv base:", len(conv_base.trainable_weights))
This is the number of trainable weights before freezing the conv base: 26
>>> conv_base.trainable = False
>>> print("This is the number of trainable weights ""after freezing the conv base:", len(conv_base.trainable_weights))
This is the number of trainable weights after freezing the conv base: 0
现在我们可以创建一个新模型,将以下三部分连接起来,如代码清单所示。(1)一个数据增强代码块(2)已冻结的卷积基(3)一个密集连接分类器代码清单 在卷积基上添加数据增强代码块和分类器
data_augmentation = keras.Sequential([layers.RandomFlip("horizontal"),layers.RandomRotation(0.1),layers.RandomZoom(0.2),]
)inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs) ←----使用数据增强
x = keras.applications.vgg16.preprocess_input(x) ←----对输入值进行缩放
x = conv_base(x)
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])
如此设置之后,只会训练新添加的2个Dense层的权重。总共有4个权重张量,每层2个(主权重矩阵和偏置向量)。请注意,为了让这些修改生效,你必须编译模型。如果在编译之后修改权重的trainable属性,那么应该重新编译模型,否则这些修改将被忽略。下面来训练模型。由于使用了数据增强,模型需要更长时间才会开始过拟合,因此可以训练更多轮—这里设为50轮。注意 这种方法的计算代价很高,只有在能够使用GPU的情况下(比如Colab的免费GPU)才可以去尝试。它在CPU上是无法运行的。如果无法在GPU上运行代码,那么应首选第一种方法。
callbacks = [keras.callbacks.ModelCheckpoint(filepath="feature_extraction_with_data_augmentation.keras",save_best_only=True,monitor="val_loss")
]
history = model.fit(train_dataset,epochs=50,validation_data=validation_dataset,callbacks=callbacks)
我们再次绘制结果。可以看到,验证精度达到约98%。这比之前的模型有了很大改进。
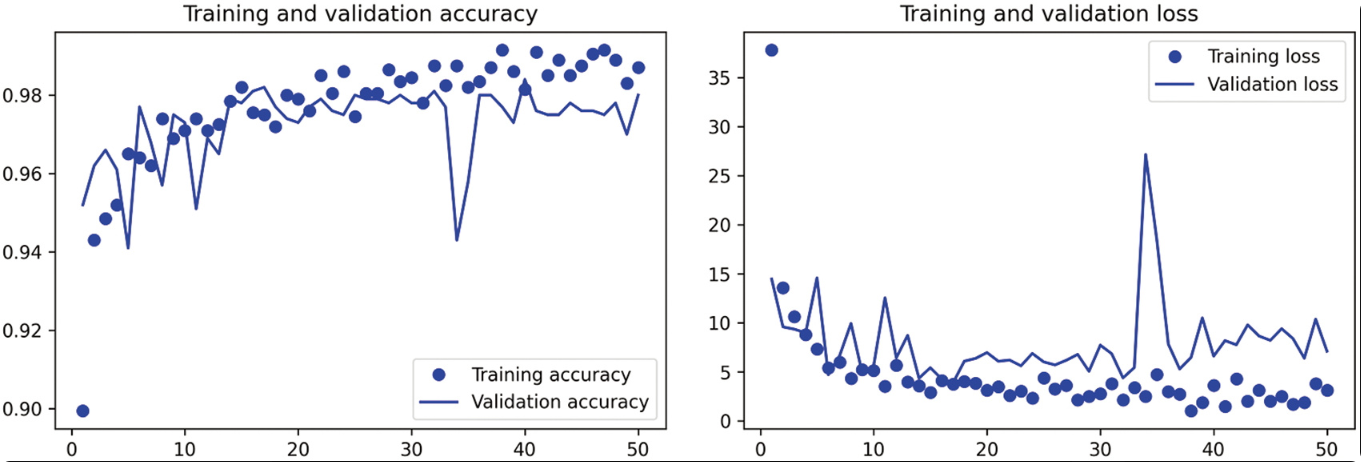
我们来看一下测试精度,如代码清单所示。
代码清单 在测试集上评估模型
test_model = keras.models.load_model("feature_extraction_with_data_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
测试精度为97.5%。与之前相比,这只是一个不大的改进。鉴于模型在验证数据上取得的好结果,这有点令人失望。模型的精度始终取决于评估模型的样本集。有些样本集可能比其他样本集更难以预测,在一个样本集上得到的好结果,并不一定能够在其他样本集上完全复现。

![[GHCTF 2025]SQL???](https://i-blog.csdnimg.cn/direct/525ce8e22c1649bcbb992a50722fd07c.png)