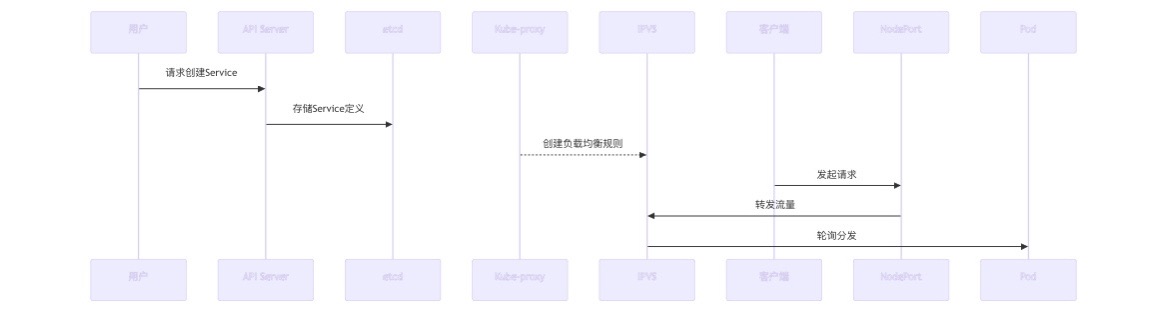
什么场景下用雪花算法?
软件项目开发中,主键自动生成是基本需求。而各个数据库对于该需求也提供了相应的支持,比如:数据库自增(MySql,oracle)。但是在分布式环境中,分库分表之后,不同表生成全局唯一的ID是非常棘手的问题。因为同一个逻辑表内的不同实际表之间的自增键是无法互相感知的,这样会造成重复ID的生成。我们当然可以通过约束表生成键的规则(设置不同的起始和步长)来达到数据的不重复,但是这需要引入额外的运维力量来解决重复性问题,如果数据库节点变更会使框架缺乏扩展性。
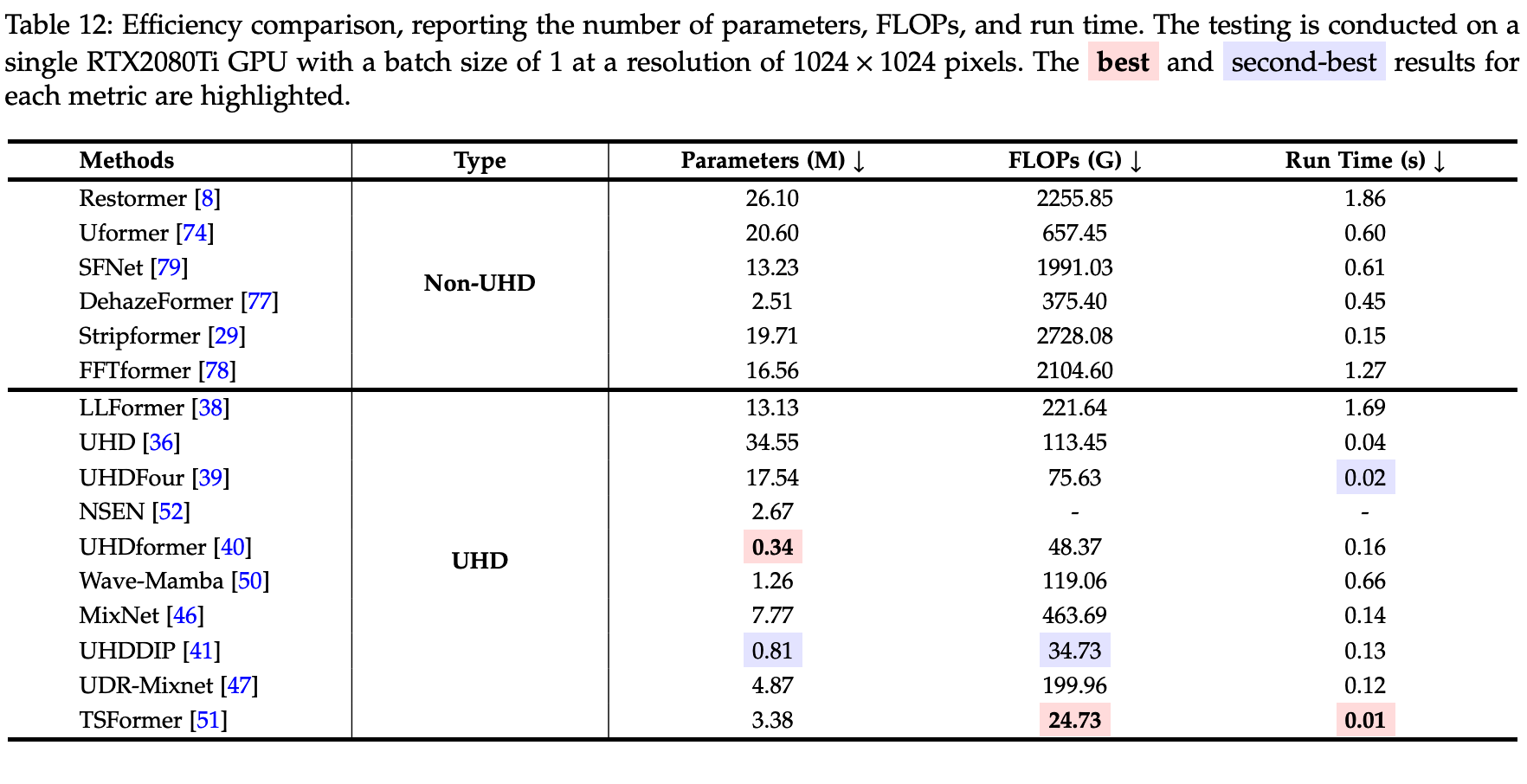
雪花算法Snowflake简介
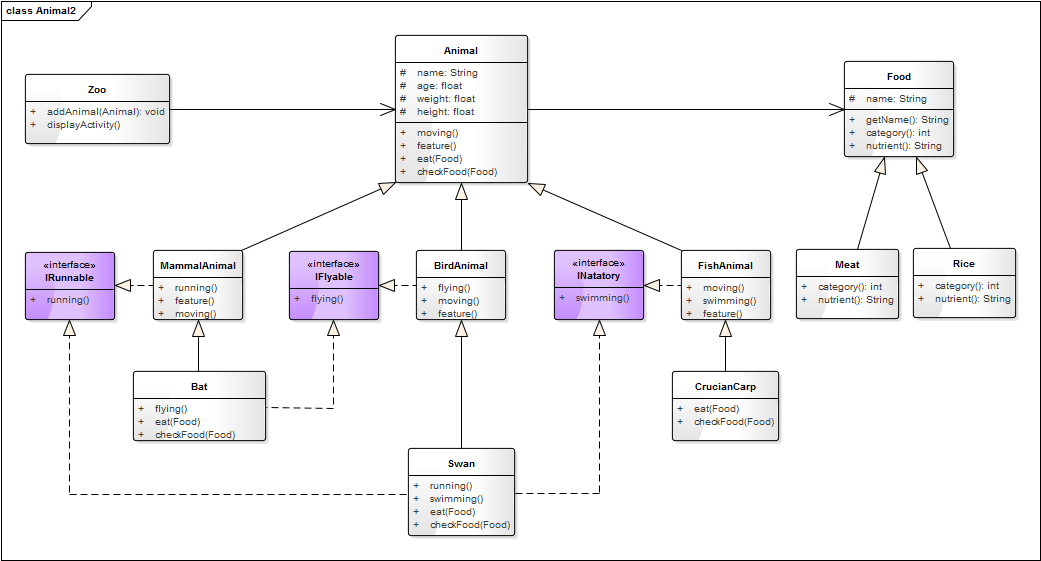
雪花算法是一款基于本地生成,保证ID全局唯一,且ID整体有序递增

| 0 | 0000000000 0000000000 0000000000 0000000000 0 | 0000000000 | 0000000000 00 |
| 1bit符号 | 41bit 时间戳 | 10bit机器ID | 12bit序列号 |
1bit:不使用,默认为0
41bit:单位毫秒,时间戳=当前系统时间-系统上线时间
10bit:机器ID,可同时部署的机器节点数2的十次方-1=1023;适用于分布式环境下对各个节点进行标识,可以具体根据节点数和部署情况设计划分机器位10位长度
12bit:序列号,自增ID,当时间戳和机器ID相同时,此值递增保证唯一性。即同一机器同一毫秒可生成唯一ID数为2的12次方-1=4096-1=4095;
| 优点 | 1.时间自增排序; 2.适合分布式场景,整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分)效率较高,一个节点每毫秒4096个ID序号,服务最大每毫秒409.6万个序列号 |
| 缺点 | 1.雪花算法在单机系统上ID是递增的,但是在分布式系统多节点的情况下不是绝对递增,所有节点的时钟(System.currentTimeMillis())并不能保证不完全同步,所以有可能会出现不是全局递增的情况 2.不能在一台服务器上部署多个分布式ID服务; 3.时钟回拨问题; |