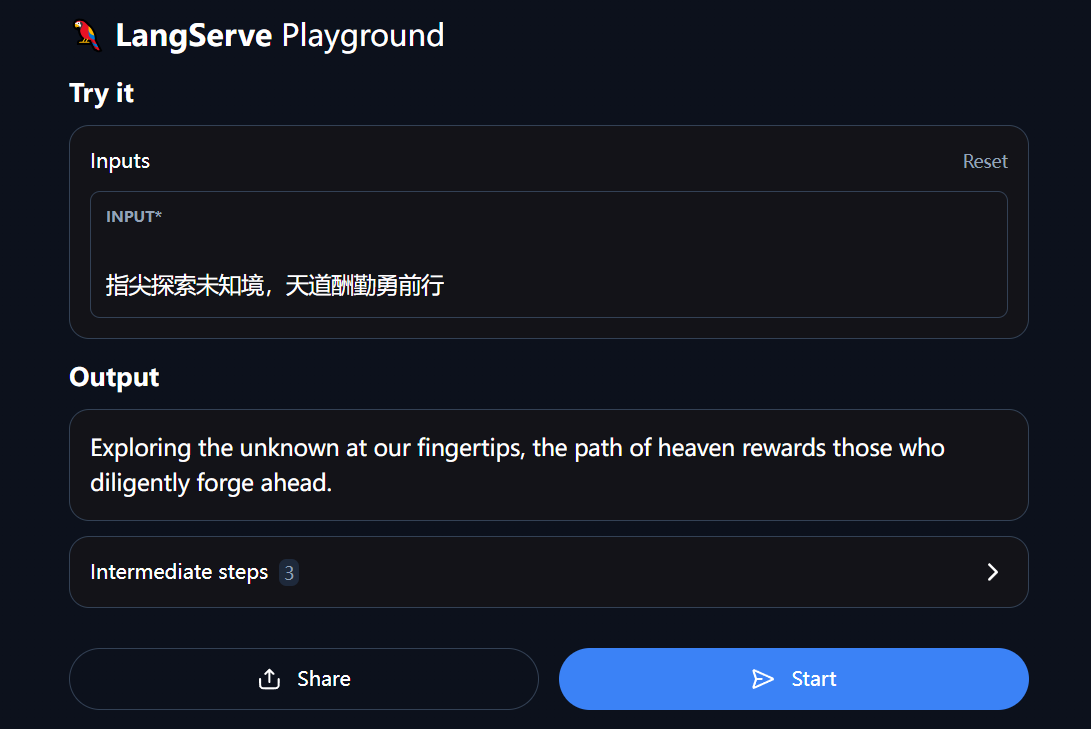
在前一章说明损失函数的用途时,引入了梯度,导数等名词,现在我们详细了解一下这些名词
1. 导数
假如你是全程马拉松选手,在开始的 10 分钟内跑了 2 千米。如果要计算此时的奔跑速度,则为 2/10 = 0.2[千米 / 分]。也就是说,你以 1 分钟前进 0.2 千米的速度(变化)奔跑。
在这个马拉松的例子中,我们计算了“奔跑的距离”相对于“时间”发生了多大变化。不过,这个 10 分钟跑 2 千米的计算方式,严格地讲,计算的是 10 分钟内的平均速度。而导数表示的是某个瞬间的变化量。因此,将 10 分钟这一时间段尽可能地缩短,比如计算前 1 分钟奔跑的距离、前 1 秒钟奔跑的距离、前 0.1 秒钟奔跑的距离……这样就可以获得某个瞬间的变化量(某个瞬时速度)。
综上,导数就是表示某个瞬间的变化量。它可以定义成下面的式子。
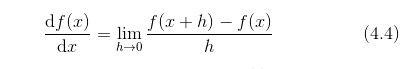
式(4.4)表示的是函数的导数。左边的符号 表示 f (x )关于 x 的导数,即 f (x )相对于 x 的变化程度。式(4.4)表示的导数的含义是,x 的“微小变化”将导致函数 f (x )的值在多大程度上发生变化。其中,表示微小变化的 h 无限趋近 0,表示为 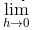 。
。
接下来,我们参考式(4.4),来实现求函数的导数的程序。如果直接实现式(4.4)的话,向 h 中赋入一个微小值,就可以计算出来了。比如,下面的实现如何?
# 不好的实现示例
def numerical_diff(f, x):
h = 10e-50
return (f(x+h) - f(x)) / h
函数 numerical_diff(f, x) 的名称来源于数值微分的英文 numerical differentiation(所谓数值微分就是用数值方法近似求解函数的导数的过程)。这个函数有两个参数,即“函数 f ”和“传给函数 f 的参数 x ”。乍一看这个实现没有问题,但是实际上这段代码有两处需要改进的地方。
在上面的实现中,因为想把尽可能小的值赋给 h (可以话,想让 h 无限接近 0),所以 h 使用了 10e-50 (有 50 个连续的 0 的“0.00 … 1”)这个微小值。但是,这样反而产生了舍入误差 (rounding error)。所谓舍入误差,是指因省略小数的精细部分的数值(比如,小数点第 8 位以后的数值)而造成最终的计算结果上的误差。比如,在 Python 中,舍入误差可如下表示。
>>> np.float32(1e-50)
0.0
如上所示,如果用 float32 类型(32 位的浮点数)来表示 1e-50 ,就会变成 0.0,无法正确表示出来。也就是说,使用过小的值会造成计算机出现计算上的问题。这是第一个需要改进的地方,即将微小值 h 改为 10-4 。使用 10-4 就可以得到正确的结果。
第二个需要改进的地方与函数 f 的差分有关。虽然上述实现中计算了函数 f 在 x+h 和 x 之间的差分,但是必须注意到,这个计算从一开始就有误差。如图 4-5 所示,“真的导数”对应函数在 x 处的斜率(称为切线),但上述实现中计算的导数对应的是 (x + h ) 和 x 之间的斜率。因此,真的导数(真的切线)和上述实现中得到的导数的值在严格意义上并不一致。这个差异的出现是因为 h 不可能无限接近 0。
如图 4-5 所示,数值微分含有误差。为了减小这个误差,我们可以计算函数 f 在 (x + h ) 和 (x - h ) 之间的差分。因为这种计算方法以 x 为中心,计算它左右两边的差分,所以也称为中心差分 (而 (x + h ) 和 x 之间的差分称为前向差分 )。下面,我们基于上述两个要改进的点来实现数值微分(数值梯度)。
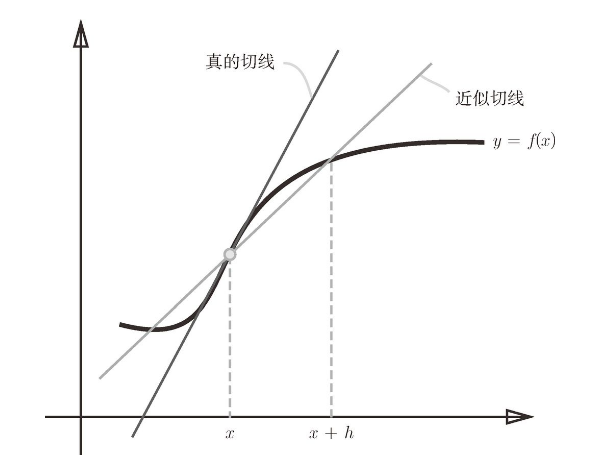
图 4-5 真的导数(真的切线)和数值微分(近似切线)的值不同
def numerical_diff(f, x):h = 1e-4return (f(x + h) - f(x - h)) / (2 * h)
如上所示,利用微小的差分求导数的过程称为数值微分 (numerical differentiation)。而基于数学式的推导求导数的过程,则用 “解析性 ”(analytic)一词,称为“解析性求解”或者“解析性求导”。比如,y = x^2 的导数,可以通过 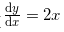 解析性地求解出来。因此,当 x = 2 时,y 的导数为 4。解析性求导得到的导数是不含误差的“真的导数”。
解析性地求解出来。因此,当 x = 2 时,y 的导数为 4。解析性求导得到的导数是不含误差的“真的导数”。
2. 数值微分的例子
现在我们试着用上述的数值微分对简单函数进行求导。先来看一个由下式表示的 2 次函数。
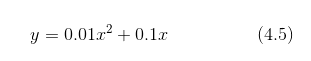
用 Python 来实现式(4.5),并绘制函数图像如下所示。
import matplotlib.pylab as plt
import numpy as npdef numerical_diff(f, x):h = 1e-4return (f(x + h) - f(x - h)) / (2 * h)def function_1(x):return 0.01 * x ** 2 + 0.1 * xx = np.arange(0, 20, 0.1)
y = function_1(x)
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.show()print(numerical_diff(function_1, 5))
print(numerical_diff(function_1, 10))输出:
0.1999999999990898
0.2999999999986347
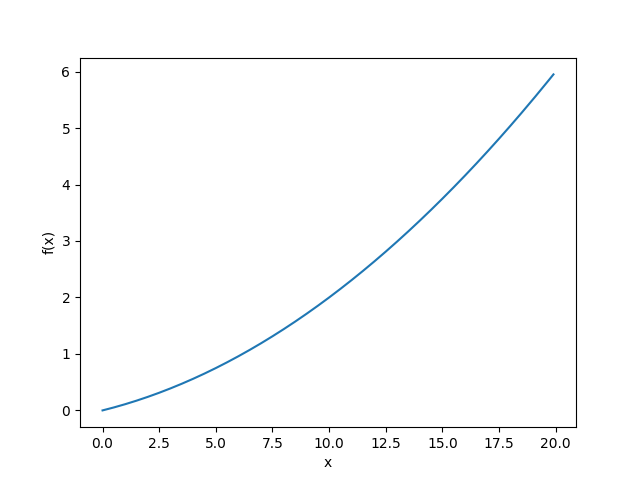
图 4-6 f(x)=0.01x^2+0.1x 的图像
这里计算的导数是 f (x ) 相对于 x 的变化量,对应函数的斜率。另外,f(x)=0.01x**2 + 0.1x 的解析解是df(x)/dx = 0.02x+0.1 。因此,在 x = 5 和 x = 10 处,“真的导数”分别为 0.2 和 0.3。和上面的结果相比,我们发现虽然严格意义上它们并不一致,但误差非常小。实际上,误差小到基本上可以认为它们是相等的。
现在,我们用上面的数值微分的值作为斜率,画一条直线。结果如图 4-7 所示,可以确认这些直线确实对应函数的切线(源代码在 ch04/gradient_1d.py 中)。
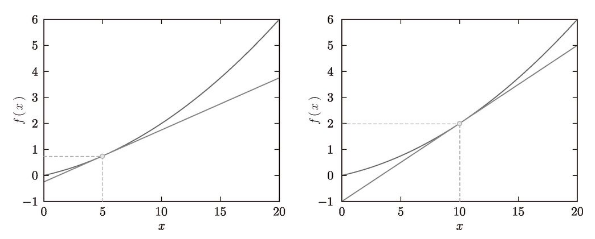
图 4-7 x=5 、x=10 处的切线:直线的斜率使用数值微分的值
3. 偏导数
接下来,我们看一下式 (4.6) 表示的函数。虽然它只是一个计算参数的平方和的简单函数,但是请注意和上例不同的是,这里有两个变量。
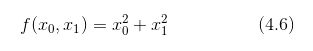
这个式子可以用 Python 来实现,如下所示。
def function_2(x):
return x[0]**2 + x[1]**2
# 或者return np.sum(x**2)
这里,我们假定向参数输入了一个 NumPy 数组。函数的内部实现比较简单,先计算 NumPy 数组中各个元素的平方,再求它们的和(np.sum(x2) 也可以实现同样的处理)。我们来画一下这个函数的图像。结果如图 4-8 所示,是一个三维图像。
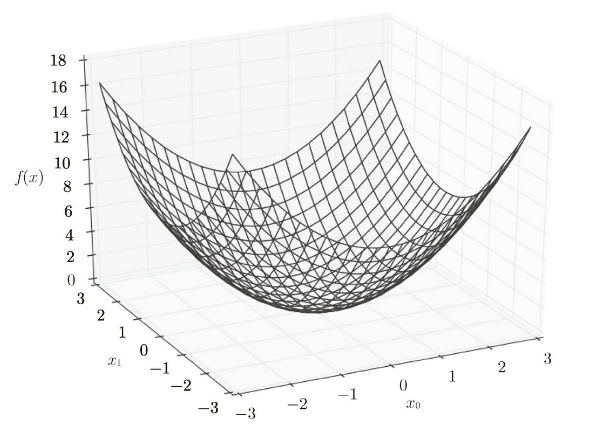
图 4-8 f(x0,x1)=x02 + x12 的图像**
现在我们来求式(4.6)的导数。这里需要注意的是,式(4.6)有两个变量,所以有必要区分对哪个变量求导数,即对 x_0 和 x_1 两个变量中的哪一个求导数。另外,我们把这里讨论的有多个变量的函数的导数称为偏导数 。用数学式表示的话,可以写成 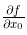 、
、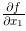
怎么求偏导数呢?我们先试着解一下下面两个关于偏导数的问题。
问题 1 :求 x_0=3,x_1=4 时,关于 x_0 的偏导数 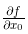 。
。
>>> def function_tmp1(x0):
... return x0*x0 + 4.0**2.0...
>>> numerical_diff(function_tmp1, 3.0)
6.00000000000378
问题 2 :求 x_0=3,x_1=4 时,关于 x_1 的偏导数 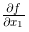 。
。
>>> def function_tmp2(x1):
... return 3.0**2.0 + x1*x1...
>>> numerical_diff(function_tmp2, 4.0)
7.999999999999119
在这些问题中,我们定义了一个只有一个变量的函数,并对这个函数进行了求导。例如,问题 1 中,我们定义了一个固定 x_1 = 4 的新函数,然后对只有变量 x_0 的函数应用了求数值微分的函数。从上面的计算结果可知,问题 1 的答案是 6.00000000000378,问题 2 的答案是 7.999999999999119,和解析解的导数基本一致。
像这样,偏导数和单变量的导数一样,都是求某个地方的斜率。不过,偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。在上例的代码中,为了将目标变量以外的变量固定到某些特定的值上,我们定义了新函数。然后,对新定义的函数应用了之前的求数值微分的函数,得到偏导数。
4. 梯度
在刚才的例子中,我们按变量分别计算了 x_0 和 x_1 的偏导数。现在,我们希望一起计算 x_0 和 x_1 的偏导数。比如,我们来考虑求 x_0=3,x_1=4 时 (x_0,x_1) 的偏导数 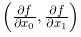 。另外,像
。另外,像 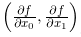 这样的由全部变量的偏导数汇总而成的向量称为梯度 (gradient)。梯度可以像下面这样来实现。
这样的由全部变量的偏导数汇总而成的向量称为梯度 (gradient)。梯度可以像下面这样来实现。
def numerical_gradient(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x) # 生成和x形状相同的数组,元素都为0for idx in range(x.size):tmp_val = x[idx]# f(x+h)的计算x[idx] = tmp_val + hfxh1 = f(x)# f(x-h)的计算x[idx] = tmp_val - hfxh2 = f(x)grad[idx] = (fxh1 - fxh2) / (2 * h)x[idx] = tmp_val # 还原值return grad函数 numerical_gradient(f, x) 的实现看上去有些复杂,但它执行的处理和求单变量的数值微分基本没有区别(数组参数在循环的时候只在当次循环中,对对应的元素进行了+h,-h的操作,数组中其他元素保持不变)。需要补充说明一下的是,np.zeros_like(x) 会生成一个形状和 x 相同、所有元素都为 0 的数组。
函数 numerical_gradient(f, x) 中,参数 f 为函数,x 为 NumPy 数组,该函数对 NumPy 数组 x 的各个元素求数值微分。现在,我们用这个函数实际计算一下梯度。这里我们求点 (3, 4)、(0, 2)、(3, 0) 处的梯度。
result = numerical_gradient(function_2, np.array([3, 4]))
print(result)
result = numerical_gradient(function_2, np.array([3.0, 4.0]))
print(result)输出:
[25000 35000]
[6. 8.]
可见,在使用整数数组做参数时,附加值被忽略了导致最终结果错误,此处需要注意
像这样,我们可以计算 在各点处的梯度。上例中,点 (3, 4) 处的梯度是 (6, 8)、点 (0, 2) 处的梯度是 (0, 4)、点 (3, 0) 处的梯度是 (6, 0)。这个梯度意味着什么呢?为了更好地理解,我们把 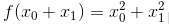 的梯度画在图上。不过,这里我们画的是元素值为负梯度 (后面我们将会看到,负梯度方向是梯度法中变量的更新方向) 的向量(源代码在 ch04/gradient_2d.py 中)。
的梯度画在图上。不过,这里我们画的是元素值为负梯度 (后面我们将会看到,负梯度方向是梯度法中变量的更新方向) 的向量(源代码在 ch04/gradient_2d.py 中)。
如图 4-9 所示,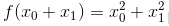 的梯度呈现为有向向量(箭头)。观察图 4-9,我们发现梯度指向函数f(x_0,x_1)的“最低处”(最小值),就像指南针一样,所有的箭头都指向同一点。其次,我们发现离“最低处”越远,箭头越大。
的梯度呈现为有向向量(箭头)。观察图 4-9,我们发现梯度指向函数f(x_0,x_1)的“最低处”(最小值),就像指南针一样,所有的箭头都指向同一点。其次,我们发现离“最低处”越远,箭头越大。
虽然图 4-9 中的梯度指向了最低处,但并非任何时候都这样。实际上,梯度会指向各点处的函数值降低的方向。更严格地讲,梯度指示的方向是各点处的函数值减小最多的方向 (高等数学告诉我们,方向导数 = cos(θ ) × 梯度(θ 是方向导数的方向与梯度方向的夹角)。因此,所有的下降方向中,梯度方向下降最多。) 。这是一个非常重要的性质,请一定牢记!
4.1 梯度法
机器学习的主要任务是在学习时寻找最优参数。同样地,神经网络也必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。但是,一般而言,损失函数很复杂,参数空间庞大,我们不知道它在何处能取得最小值。而通过巧妙地使用梯度来寻找函数最小值(或者尽可能小的值)的方法就是梯度法。
这里需要注意的是,梯度表示的是各点处的函数值减小最多的方向。因此,无法保证梯度所指的方向就是函数的最小值或者真正应该前进的方向。实际上,在复杂的函数中,梯度指示的方向基本上都不是函数值最小处。
函数的极小值、最小值以及被称为鞍点 (saddle point)的地方,梯度为 0。极小值是局部最小值,也就是限定在某个范围内的最小值。鞍点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。虽然梯度法是要寻找梯度为 0 的地方,但是那个地方不一定就是最小值(也有可能是极小值或者鞍点)。此外,当函数很复杂且呈扁平状时,学习可能会进入一个(几乎)平坦的地区,陷入被称为“学习高原”的无法前进的停滞期。
虽然梯度的方向并不一定指向最小值,但沿着它的方向能够最大限度地减小函数的值。因此,在寻找函数的最小值(或者尽可能小的值)的位置的任务中,要以梯度的信息为线索,决定前进的方向。
此时梯度法就派上用场了。在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法 (gradient method)。梯度法是解决机器学习中最优化问题的常用方法,特别是在神经网络的学习中经常被使用。
根据目的是寻找最小值还是最大值,梯度法的叫法有所不同。严格地讲,寻找最小值的梯度法称为梯度下降法 (gradient descent method),寻找最大值的梯度法称为梯度上升法 (gradient ascent method)。但是通过反转损失函数的符号,求最小值的问题和求最大值的问题会变成相同的问题,因此“下降”还是“上升”的差异本质上并不重要。一般来说,神经网络(深度学习)中,梯度法主要是指梯度下降法。
现在,我们尝试用数学式来表示梯度法,如式(4.7)所示。
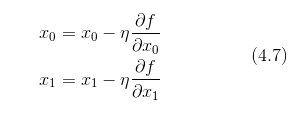
式(4.7)的 η 表示更新量,在神经网络的学习中,称为学习率 (learning rate)。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。
式(4.7)是表示更新一次的式子,这个步骤会反复执行。也就是说,每一步都按式(4.7)更新变量的值,通过反复执行此步骤,逐渐减小函数值。虽然这里只展示了有两个变量时的更新过程,但是即便增加变量的数量,也可以通过类似的式子(各个变量的偏导数)进行更新。
学习率需要事先确定为某个值,比如 0.01 或 0.001。一般而言,这个值过大或过小,都无法抵达一个“好的位置”。在神经网络的学习中,一般会一边改变学习率的值,一边确认学习是否正确进行了。
用Python实现梯度下降法如下
def gradient_descent(f, init_x, lr=0.01, step_num=100):x = init_xfor i in range(step_num):grad = numerical_gradient(f, x)x -= lr * gradreturn x
参数 f 是要进行最优化的函数,init_x 是初始值,lr 是学习率 learning rate,step_num 是梯度法的重复次数。numerical_gradient(f,x) 会求函数的梯度,用该梯度乘以学习率得到的值进行更新操作,由 step_num 指定重复的次数。
使用这个函数可以求函数的极小值,顺利的话,还可以求函数的最小值。下面,我们就来尝试解决下面这个问题。
def function_2(x):return x[0] * x[0] + x[1] * x[1]def numerical_gradient(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x) # 生成和x形状相同的数组for idx in range(x.size):tmp_val = x[idx]# f(x+h)的计算x[idx] = tmp_val + hfxh1 = f(x)# f(x-h)的计算x[idx] = tmp_val - hfxh2 = f(x)grad[idx] = (fxh1 - fxh2) / (2 * h)x[idx] = tmp_val # 还原值return graddef gradient_descent(f, init_x, lr=0.01, step_num=100):x = init_xfor i in range(step_num):grad = numerical_gradient(f, x)x -= lr * gradreturn xinit_x = np.array([3.0, 4.0])
result = gradient_descent(function_2,init_x,0.1,100)
print(result)输出:
[6.11110793e-10 8.14814391e-10]
这里,设初始值为 (-3.0, 4.0) ,开始使用梯度法寻找最小值。最终的结果是 (-6.1e-10, 8.1e-10) ,非常接近 (0, 0) 。实际上,真的最小值就是 (0, 0) ,所以说通过梯度法我们基本得到了正确结果。如果用图来表示梯度法的更新过程,则如图 4-10 所示。可以发现,原点处是最低的地方,函数的取值一点点在向其靠近。这个图的源代码在 ch04/gradient_method.py 中(但 ch04/gradient_method.py 不显示表示等高线的虚线)。
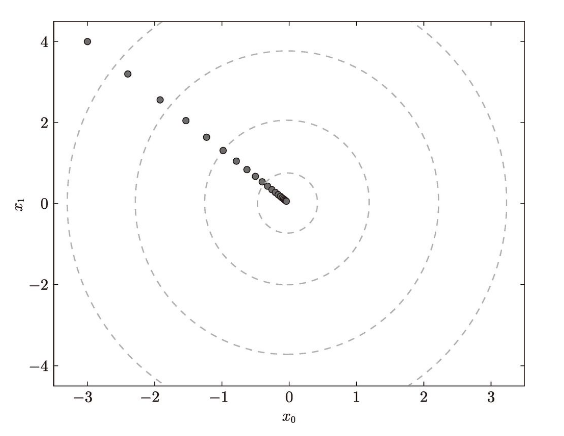

前面说过,学习率过大或者过小都无法得到好的结果。我们来做个实验验证一下。
init_x = np.array([3.0, 4.0])
result = gradient_descent(function_2,init_x,10,100)
print(result)
输出: [ 2.58983747e+13 -1.29524862e+12]init_x = np.array([3.0, 4.0])
result = gradient_descent(function_2, init_x, 1e-10, 100)
print(result)输出:[2.99999994 3.99999992]
实验结果表明,学习率过大的话,会发散成一个很大的值;反过来,学习率过小的话,基本上没怎么更新就结束了。也就是说,设定合适的学习率是一个很重要的问题。
像学习率这样的参数称为 超参数 。这是一种和神经网络的参数(权重和偏置)性质不同的参数。相对于神经网络的权重参数是通过训练数据和学习算法自动获得的,学习率这样的超参数则是人工设定的。一般来说,超参数需要尝试多个值,以便找到一种可以使学习顺利进行的设定。
4.2 神经网络的梯度
神经网络的学习也要求梯度。这里所说的梯度是指损失函数关于权重参数的梯度。比如,有一个只有一个形状为 2 × 3 的权重 W 的神经网络,损失函数用 L 表示。此时,梯度可以用 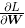 表示。用数学式表示的话,如下所示。
表示。用数学式表示的话,如下所示。
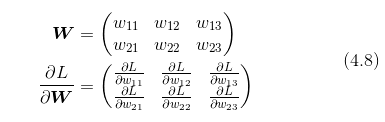
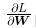 的元素由各个元素关于W 的偏导数构成。比如,第 1 行第 1 列的元素
的元素由各个元素关于W 的偏导数构成。比如,第 1 行第 1 列的元素 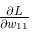 表示当 w_11 稍微变化时,损失函数 L 会发生多大变化。这里的重点是,
表示当 w_11 稍微变化时,损失函数 L 会发生多大变化。这里的重点是, 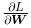 的形状和 W 相同。实际上,式(4.8)中的 W 和
的形状和 W 相同。实际上,式(4.8)中的 W 和 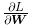 都是 2 × 3 的形状。
都是 2 × 3 的形状。
下面,我们以一个简单的神经网络为例,来实现求梯度的代码。为此,我们要实现一个名为 simpleNet 的类(源代码在 ch04/gradient_simplenet.py 中)。
import numpy as npdef cross_entropy_error(y, t):delta = 1e-7return -np.sum(t * np.log(y + delta))def softmax(x):c = np.max(x)exp_x = np.exp(x - c)return exp_x / sum(exp_x)def numerical_gradient(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x)# nditer 提供了多种控制参数,用于控制迭代的行为# multi_index 表示返回元素的多维索引it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])while not it.finished:idx = it.multi_indextmp_val = x[idx]x[idx] = float(tmp_val) + hfxh1 = f(x) # f(x+h)x[idx] = tmp_val - hfxh2 = f(x) # f(x-h)grad[idx] = (fxh1 - fxh2) / (2 * h)x[idx] = tmp_val # 还原值it.iternext()return gradclass SimpleNet:def __init__(self):self.W = np.random.randn(2, 3)def predict(self, x):return np.dot(x, self.W)def loss(self, x, t):z = self.predict(x)y = softmax(z)loss = cross_entropy_error(y, t)return loss
simpleNet 类只有一个实例变量,即形状为 2×3 的权重参数。它有两个方法,一个是用于预测的 predict(x) ,另一个是用于求损失函数值的 loss(x,t) 。这里参数 x 接收输入数据,t 接收正确解标签。
接下来求一下 梯度
net = SimpleNet()
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])def f(w):# w 参数为伪参数,未使用,为了符合numerical_gradient 函数的定义return net.loss(x, t)dw = numerical_gradient(f,net.W)
print(dw)输出:
[[ 0.29331802 0.20045909 -0.4937771 ][ 0.43997703 0.30068863 -0.74066566]]
numerical_gradient(f, x) 的参数 f 是函数,x 是传给函数 f 的参数。因此,这里参数 x 取 net.W ,并定义一个计算损失函数的新函数 f ,然后把这个新定义的函数传递给 numerical_gradient(f, x) 。
numerical_gradient(f, net.W) 的结果是 dW ,一个形状为 2 × 3 的二维数组。观察一下 dW 的内容,例如,会发现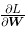 中的
中的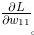 的值大约是 0.3,这表示如果将 w_11增加 h ,那么损失函数的值会增加 0.3h。再如,
的值大约是 0.3,这表示如果将 w_11增加 h ,那么损失函数的值会增加 0.3h。再如,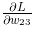 对应的值大约是 -0.7,这表示如果将 w_23 增加 h ,损失函数的值将减小 0.7h 。因此,从减小损失函数值的观点来看,w_23 应向正方向更新,w_11 应向负方向更新。至于更新的程度,w_23 比 w_11 的贡献要大。
对应的值大约是 -0.7,这表示如果将 w_23 增加 h ,损失函数的值将减小 0.7h 。因此,从减小损失函数值的观点来看,w_23 应向正方向更新,w_11 应向负方向更新。至于更新的程度,w_23 比 w_11 的贡献要大。
求出神经网络的梯度后,接下来只需根据梯度法,更新权重参数即可。在下一节中,我们会以 2 层神经网络为例,实现整个学习过程。




![[网页五子棋][匹配模式]创建房间类、房间管理器、验证匹配功能,匹配模式小结](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fstricky-1319251483.cos.ap-chongqing.myqcloud.com%2Fimg%2F202505290928112.png&pos_id=img-m9Mc18oK-1748530545157)