为什么需要“自适应推理”?
LLM 虽然聪明,但有个“学霸病”——不管题目难易,都要写满解题过程。比如问“1+1=?”,它可能从宇宙起源开始推导,这就是论文提到的“过思考(overthinking)”问题。
论文:ARM: Adaptive Reasoning Model
链接:https://arxiv.org/pdf/2505.20258
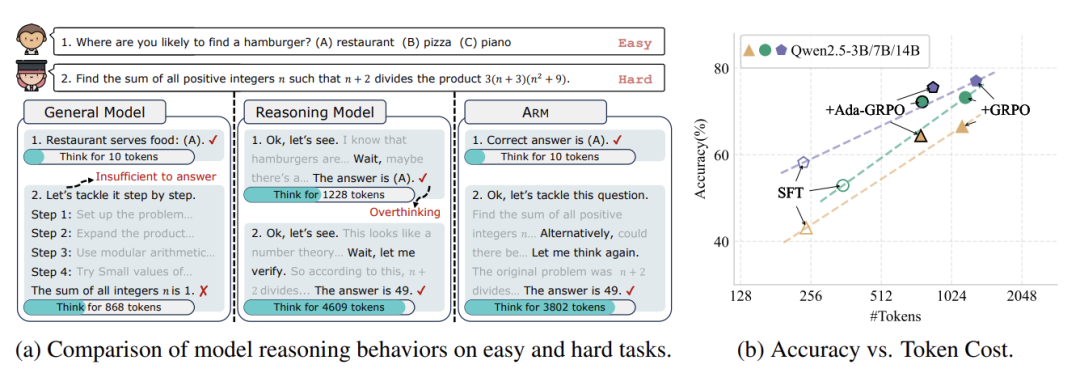
这种“过度认真”不仅浪费计算资源(生成的token越多,耗电越多),甚至可能因为废话太多反而答错题!虽然人类可以手动控制回答长度,但这违背了AI自主决策的终极目标。
ARM模型如何做到“能屈能伸”?
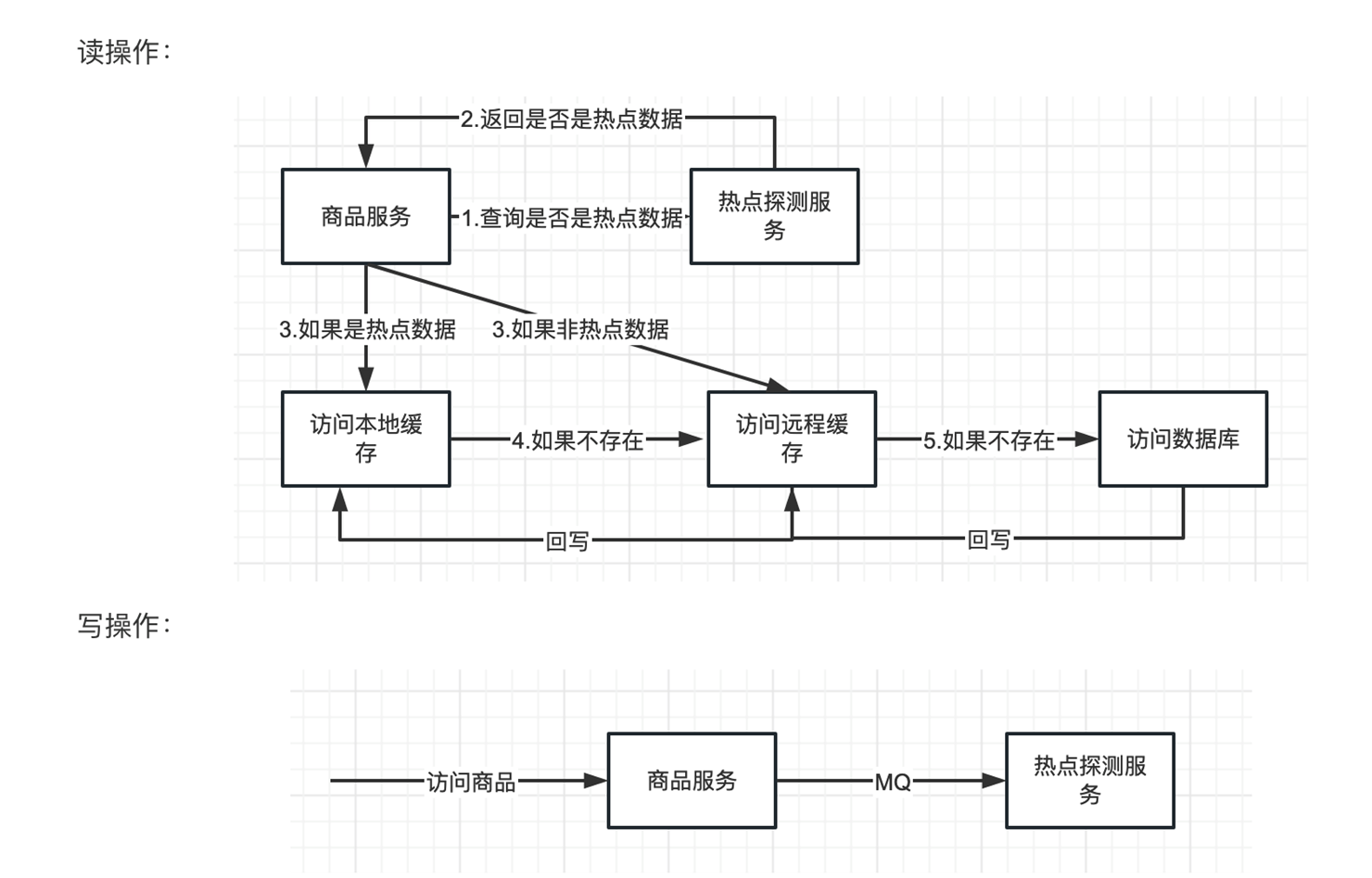
ARM内置四种解题策略:
直球模式(Direct Answer):直接报答案
简略推理(Short CoT):写两三步关键思路
代码解题(Code):用编程思维拆解问题
深度思考(Long CoT):传统的长篇推导
还支持三种决策模式:
自适应模式:AI自己判断题目难度选策略
指令模式:人类指定用哪种方法(适合批量处理同类题)
共识模式:三种简单方法投票,意见不一致再启动深度思考
Ada-GRPO算法
传统强化学习方法(GRPO)有个致命问题——格式崩溃。就像学生发现写长答案得分高,就所有题都写长答案,完全放弃简单方法。
论文提出的Ada-GRPO用动态奖励公式破解困局:
其中 包含:
多样性奖励:冷门解题法加分
衰减因子:后期更重视准确性
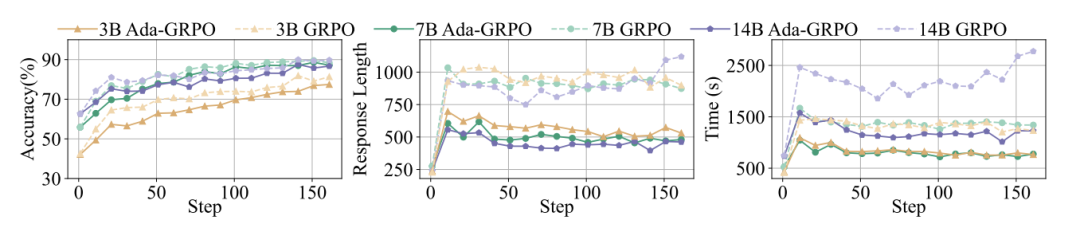
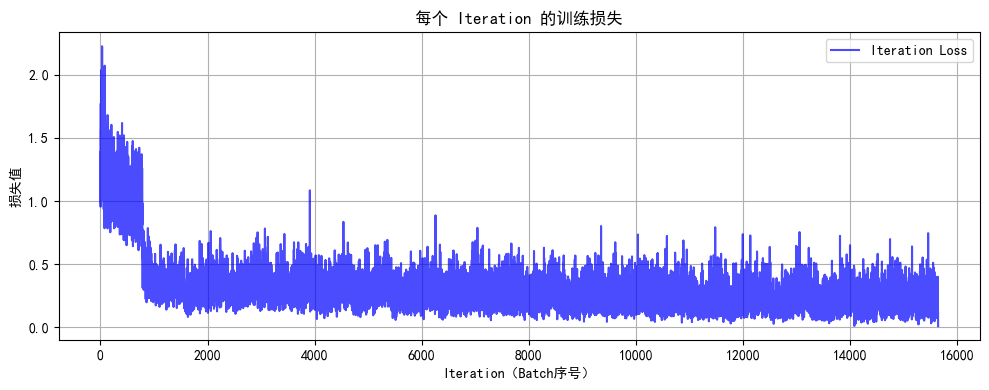
这相当于告诉模型:“前期多尝试不同方法,找到规律后重点用靠谱的”。最终实现训练速度翻倍,且token用量减少30%-70%。
实验:少花力气反而更聪明?
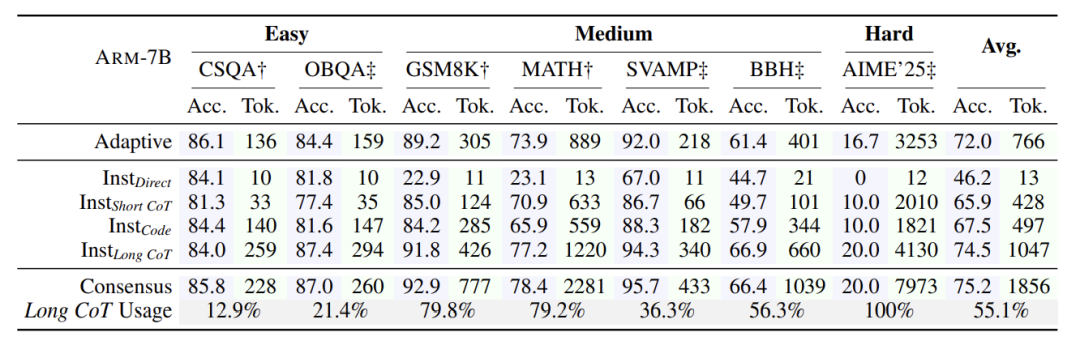
在数学、常识、符号推理等23个数据集测试中:
平均省30% token,极端任务省70%
准确率与全程长答案的模型持平
训练速度提升2倍
典型案例:
常识题(如“花瓶底部叫什么”)用直球模式,token从500降到50,准确率不变
奥数题自动切换长答案模式,正确率反超传统模型
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
![[网页五子棋][匹配模式]创建房间类、房间管理器、验证匹配功能,匹配模式小结](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fstricky-1319251483.cos.ap-chongqing.myqcloud.com%2Fimg%2F202505290928112.png&pos_id=img-m9Mc18oK-1748530545157)