
相关文章

CSS之动画(奔跑的熊、两面反转盒子、3D导航栏、旋转木马)
一、 2D转换 1.1 transform: translate( ) 转换(transform) 是CSS3中具有颠覆性的特征之一,可以实现元素的位移、旋转、缩放等效果 移动:translate 旋转:rotate 缩放:scale 下图为2D转换的坐标系 回忆…
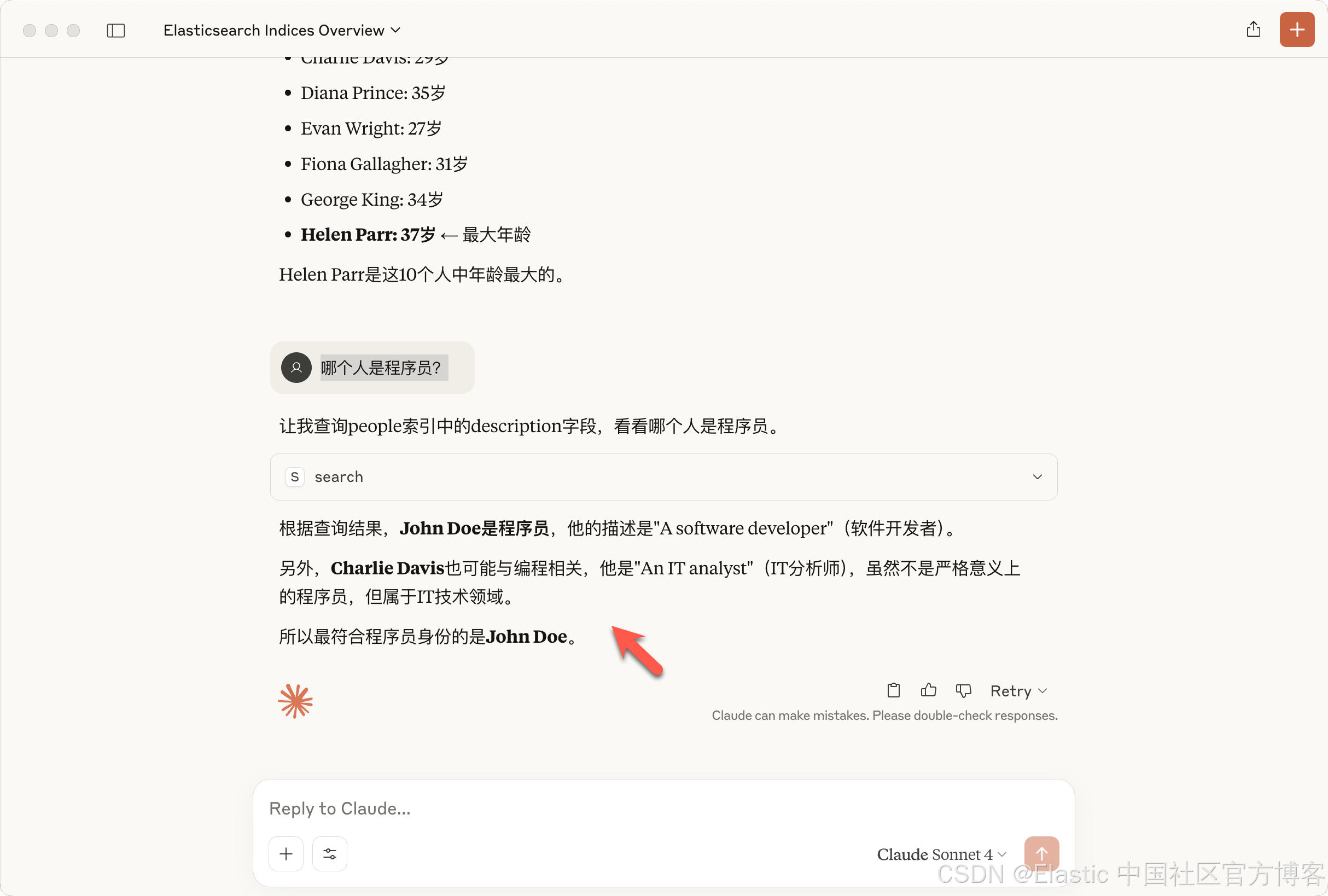
使用 MCP 将代理连接到 Elasticsearch 并对索引进行查询
本文是之前文章 “将代理连接到 Elasticsearch 使用模型上下文协议” 的扩展。在这里,我们将以详细的步骤来一步一步地展示如何安装 MCP Server 及使用 MCP 服务器和我们的 Elasticsearch 中的数据来进行对话。 安装 Elasticsearch 及 Kibana
如果你还没有安装好你…

PMI Suite V5.9.125 (Byos and Byosphere)2025年5月15日版本PMI Suite V5.9
1、完整质量分析
Intact Mass™工作流程提供自动MS/MS光谱注释、MS级反卷积和鉴定,与传统的自下而上方法相比,减少了数据分析所需的时间。
2、肽水平分析
鉴定复杂样品中的蛋白质和修饰肽。大幅缩短以肽为中心的工作流程的分析时间 3、色谱图分析
将…
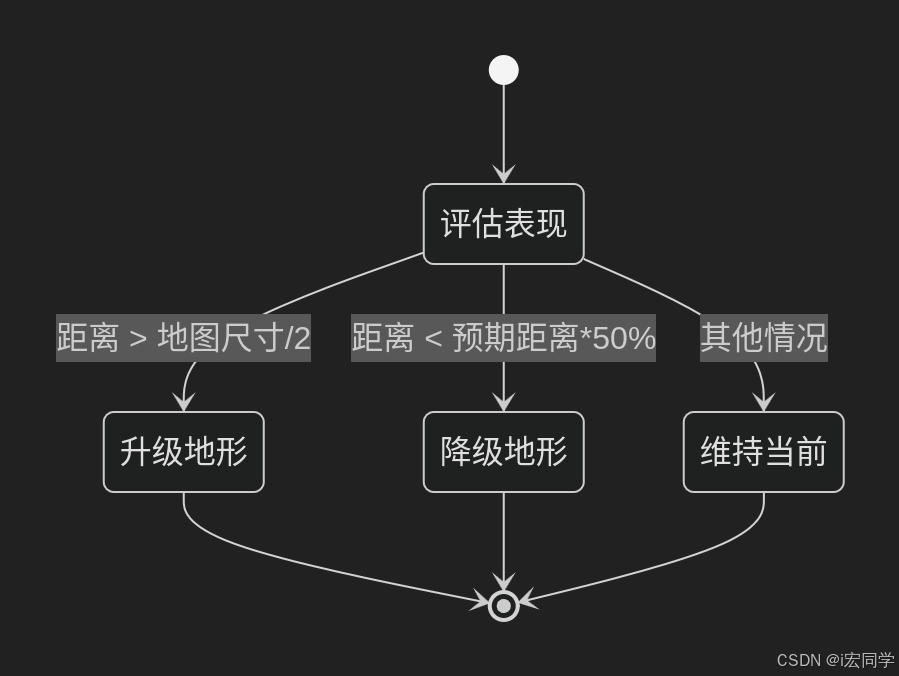
MDP的curriculums部分
文章目录 1. isaaclab中的curriculums1.1 modify_reward_weight1.1.1 函数功能1.1.2 参数详解1.1.3 函数逻辑1.1.4 如何使用 2. isaaclab_task中的curriculums2.1 terrain_levels_vel2.1 功能概述2.2 函数参数2.3 函数逻辑 3. robot_lab中的curriculums3.1 command_levels_vel …

【AUTOSAR OS】事件机制解析:定义、实现与应用
文章目录 一、Event的定义与作用二、核心数据结构三、重要函数实现与原理1. **事件初始化 Os_InitEvent()**2. **设置事件 SetEvent()/Os_SetEvent()**3. **等待事件 WaitEvent()/Os_WaitEvent()**4. **清除事件 ClearEvent()**5. **获取事件状态 GetEvent()** 四、应用示例&am…
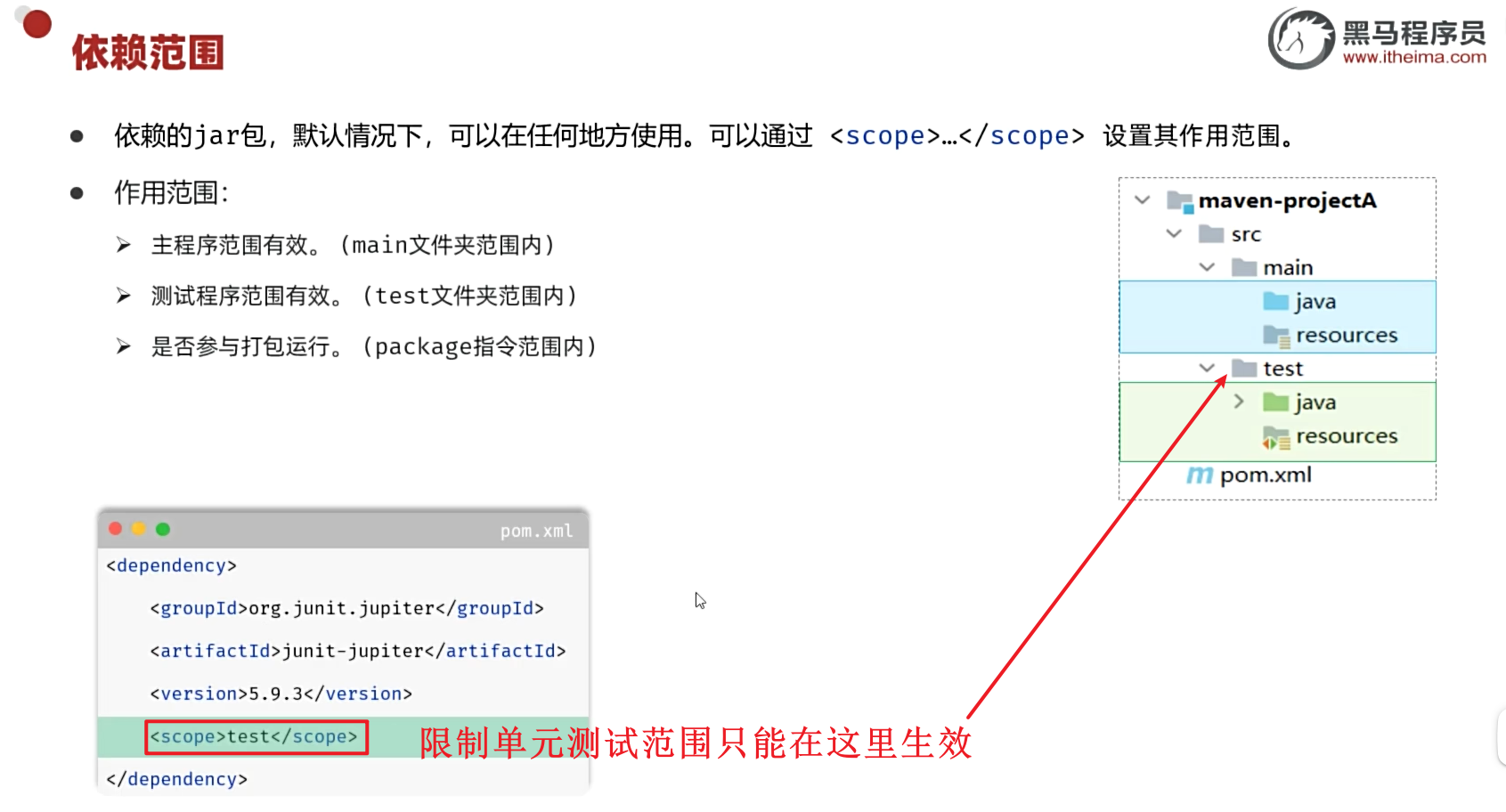
单元测试-断言常见注解
目录 1.断言
2.常见注解
3.依赖范围 1.断言 断言练习
package com.gdcp;import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;//测试类
public class UserServiceTest {Testpublic void testGetGender(){UserService userService new UserService…

5.3.1_1二叉树的先中后序遍历
知识总览: 什么是遍历:
按照某种次序把所有节点都访问一遍 二叉树的遍历-分支节点逐层展开法(会这个就行):
先序(根)遍历:根左右 中序(根)遍历:左根右 后序(根)遍历:左右根
分支节点逐层展开法&am…
SpringMVC的注解
1. SpringMVC:Spring Web MVC
2. RequestMapping 既是类注解,又是方法注解
3. 访问的URL路径:类路径方法路径
4.后端开发人员测试接口,通常使用postman或其他类似工具来发起请求 对于后端而言,使用postman或form表单࿰…
ipfs下载和安装(windows)
关于ipfs介绍,网上一大堆,这里就不讲了。
zip安装包下载衔接:https://github.com/ipfs/kubo/releases/download/v0.35.0/kubo_v0.35.0_windows-amd64.zip
下载之后解压,将文件放到一个合适的目录。 配置系统环境变量(…
![World of Warcraft Hunter [Grandel] [Ancient Petrified Leaf]](https://i-blog.csdnimg.cn/direct/ff41c528be99473e817e2c808ed62811.png)
World of Warcraft Hunter [Grandel] [Ancient Petrified Leaf]
World of Warcraft Hunter [Grandel] [Ancient Petrified Leaf] 猎人史诗弓任务 [远古石叶][罗克迪洛尔,上古守护者的手杖][伦鲁迪洛尔,上古守护者的长弓] 最伟大的猎手 Grandel,很多年前的图片。史诗弓流程。

【LeetCode 题解】两数之和(C++/Python 双解法):从语法到算法的全面解析
【LeetCode题解】两数之和(C/Python双解法):从语法到算法的全面解析
一、题目描述
题目链接:1. 两数之和 难度:简单 要求:给定一个整数数组 nums 和一个整数目标值 target,在数组中找出两个数…

《AI Agent项目开发实战》DeepSeek R1模型蒸馏入门实战
一、模型蒸馏环境部署
注:本次实验仍然采用Ubuntu操作系统,基本配置如下: 需要注意的是,本次公开课以Qwen 1.5-instruct模型为例进行蒸馏,从而能省略冷启动SFT过程,并且 由于Qwen系列模型本身性能较强&…
17.进程间通信(三)
一、System V 消息队列基本结构与理解 消息队列是全双工通信,可以同时收发消息。 结论1:消息队列提供了一种,一个进程给另一个进程发送有类型数据块的方式! 结论2:OS中消息队列可能有多个,要对消息队列进行…
【汽车电子入门】一文了解LIN总线
前言:LIN(Local Interconnect Network)总线,也就是局域互联网的意思,它的出现晚于CAN总线,于20世纪90年代末被摩托罗拉、宝马、奥迪、戴姆勒、大众以及沃尔沃等多家公司联合开发,其目的是提供一…

BayesFlow:基于神经网络的摊销贝叶斯推断框架
贝叶斯推断为不确定性条件下的推理、复杂系统建模以及基于观测数据的预测提供了严谨且功能强大的理论框架。尽管贝叶斯建模在理论上具有优雅性,但在实际应用中经常面临显著的计算挑战:后验分布通常缺乏解析解,模型验证和比较需要进行重复的推…


高压电绝缘子破损目标检测数据集简介与应用
在电力系统中,高压电绝缘子起着关键的绝缘与机械支撑作用。一旦发生破损,不仅影响输电线路的安全运行,还可能引发电力事故。因此,利用目标检测技术对高压绝缘子的破损情况进行智能识别,已成为当前电力巡检中的重要研究…

深度学习与神经网络 前馈神经网络
1.神经网络特征 无需人去告知神经网络具体的特征是什么,神经网络可以自主学习
2.激活函数性质
(1)连续并可导(允许少数点不可导)的非线性函数
(2)单调递增
(3)函数本…
paoxiaomo的XCPC算法竞赛训练经验
楼主作为一个普通二本的ICPC选手,在0基础的情况下凭借自学,获得过南昌邀请赛金牌,杭州区域赛银牌,一路上经历过不少的跌宕起伏,如今将曾经摸索出来的学习路线分享给大家
一,语言基础
学习C语言基础语法&a…
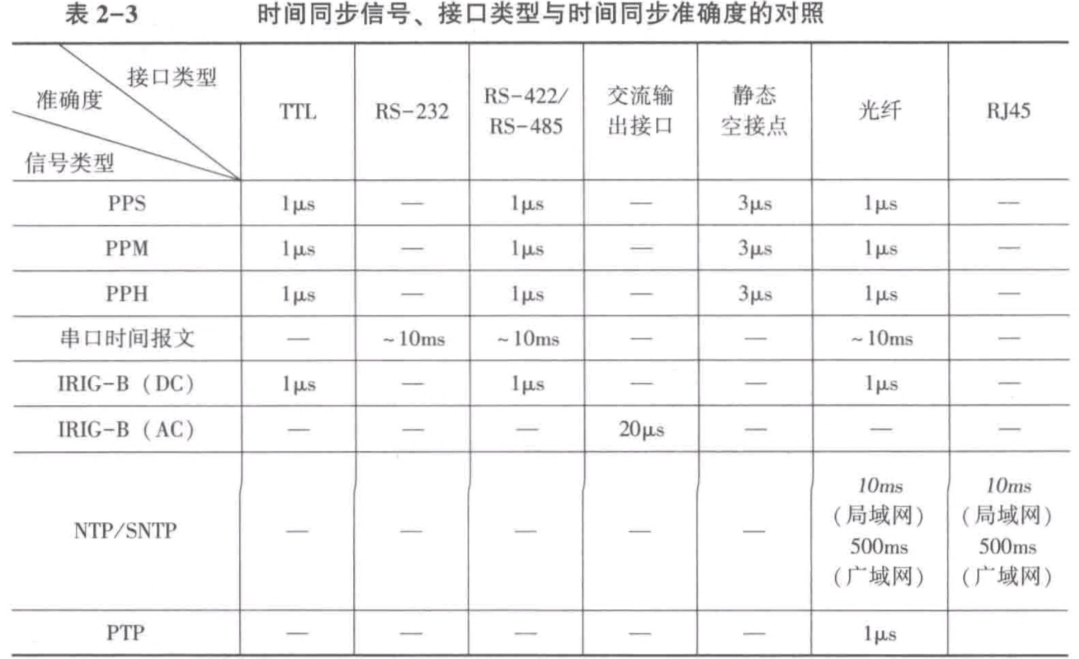
电力系统时间同步系统
电力系统中,电压、电流、功率变化等特征量测量都是时间相关函数[1],统一精准的时间源对于电网安全稳定运行至关重要,因此,电力系统运行规程[2]中明确要求继电保护装置、自动化装置、安全稳定控制系统、能量管理系统和生产信息管理…
推荐文章
- 美国“贸易吃亏论”站不住脚 服务贸易顺差巨大
- 90后一家四口为省钱住毛坯房称很满足 极简生活,够用就行
- 3类牙膏列入致癌“黑名单” 长期用或有致癌风险
- 山姆放量超10万瓶平价茅台 瞄准高净值人群
- 胖东来调改店更深层次逻辑在于供应链 客流回落与裸价挑战
- 刀郎演唱会结束后刀迷自发清理垃圾 文明素养获点赞
- 郑州多家酒店举报携程平台私自调价 商家权益受损引争议
- 全国多地25条河流发生超警以上洪水 多河段水位创历史新高
- 北京城区暴雨为何比预报下得大 副高外围影响加剧
- 外卖大战的订单冲爆咖啡奶茶店 补贴战引发销量激增
- 韩媒:蓉城旧将安德里戈加盟水原FC,合同为期六个月 租借期满寻新东家
- 本升专?职业技术学院3专业招本科生 职业教育新趋势