作者:来自 Elastic Luca Wintergerst

ES|QL 的 LOOKUP JOIN 现已进入技术预览阶段,它允许你在查询时对日志、指标和追踪进行丰富处理,无需在摄取时进行非规范化。动态添加部署、基础设施或业务上下文,减少存储占用,加速 Elastic Observability 中的根本原因分析。
连接关键点:使用 ES|QL 联接实现更丰富的可观测性洞察
你可能已经看到我们最近发布的关于 Elasticsearch 中引入 SQL 风格联接的公告,也就是 ES|QL 的 LOOKUP JOIN 命令(目前处于技术预览阶段!)。虽然那篇文章介绍了基础内容,但现在我们将从可观测性的角度更深入地探讨这一功能。这项新的联接能力,如何帮助工程师和 SRE 更好地理解日志、指标和追踪数据,同时通过减少数据反规范化来提升 Elasticsearch 的存储效率?
注意:在深入细节之前,需要再次强调,这项功能目前依赖一个特殊的查找索引(lookup index)。目前 还无法 对任意索引进行 JOIN 操作。
可观测性不只是收集数据,更重要的是理解数据。很多时候,原始遥测数据 —— 例如一条日志、一项指标或一个追踪片段——缺乏快速诊断或影响评估所需的完整上下文。我们需要关联数据、使用业务或基础设施上下文对其进行丰富,并提出更高级的问题。
传统上,在 Elasticsearch 中实现这些能力的方法包括在摄取时对数据进行非规范化(例如通过使用 enrich processor 的 ingest pipeline),或在客户端执行联接。
通过在数据流入时添加必要的上下文(如主机详情或用户属性),每个文档在进入索引时就已准备好用于查询和分析,无需后续额外处理。这种方法在很多场景下运行良好,特别是当引用数据变化缓慢或丰富字段对几乎每次查询都至关重要时。
但随着环境变得越来越动态和多样化,频繁更新引用数据(或避免在每个文档中重复存储字段)的需求也暴露了一些权衡和限制。
在 Elasticsearch 8.18 和 9.0 中引入的 ES|QL LOOKUP JOIN 提供了另一种更加灵活的选择,适用于那些需要实时查找和最小重复数据的场景。这两种方法 —— 摄取时丰富与查询时 LOOKUP JOIN —— 根据更新频率、查询性能和存储考量等不同用例需求,可以互为补充并同时有效。
为什么在可观测性中使用 Lookup Join
Lookup join 保持了灵活性。你可以在查询时根据需要动态决定是否查找额外信息来辅助调查。
以下是一些示例:
-
部署信息:是哪个版本的代码在产生这些错误?
-
基础设施映射:是哪个 Kubernetes 集群或云区域延迟较高?使用了什么硬件?
-
业务上下文:这个性能下降是否影响到了关键客户?
-
团队归属:哪个团队负责这个抛出异常的服务?
要把这类信息完美地反规范化到每一条日志或指标数据中,既困难又低效。而且像部署列表、服务器清单、客户等级或服务归属这类查找数据集,通常和遥测数据是独立变化的。
LOOKUP JOIN 在这里非常适用,原因如下:
-
查找索引可写:更新你的部署列表、CMDB 导出或值班表到查找索引中,下一次的 ES|QL 查询会立即使用这些最新数据。无需重新执行复杂的 enrich 策略或重新索引数据。
-
灵活性:你可以在查询时决定需要联接哪个上下文。也许你今天关注的是部署版本,明天关注的则是云区域。
-
更简单的设置:如之前的文章所说,不需要维护任何 enrich 策略。只需创建一个带有
index.mode: lookup的索引并加载你的数据——每个查找索引最多支持 20 亿条文档。
可观测性使用场景与 ES|QL 示例
现在让我们看一些示例,了解 Lookup Join 如何提供帮助。
使用部署上下文丰富错误日志
假设你发现 checkout-service 的错误突然增加。你的日志已经流入数据流中,但它们只包含服务名称。这些文档本身没有任何与部署活动相关的信息。
FROM logs-*| WHERE log.level == "error"| WHERE service.name == "opbeans-ruby"
你需要知道这些错误是否与最近的部署有关。为此,我们可以维护一个名为 deployments_info_lkp 的索引(设置为 index.mode: lookup),它将服务名称映射到其部署时间。这个索引可以在每次部署发生时由我们的 CI/CD 流水线自动更新。
PUT /deployments_info_lkp
{"settings": {"index.mode": "lookup"},"mappings": {"properties": {"service": {"properties": {"name": {"type": "keyword"},"deployment_time": {"type": "date"},"version": {"type": "keyword"}}}}}
}# Bulk index the deployment documents
POST /_bulk
{ "index" : { "_index" : "deployments_info_lkp" } }
{ "service.name": "opbeans-ruby", "service.version": "1.0", "deployment_time": "2025-05-22T06:00:00Z" }
{ "index" : { "_index" : "deployments_info_lkp" } }
{ "service.name": "opbeans-go", "service.version": "1.1.0", "deployment_time": "2025-05-22T06:00:00Z" }
利用这些信息,你现在可以编写一个将这两个数据源连接起来的查询。
ES|QL 查询:
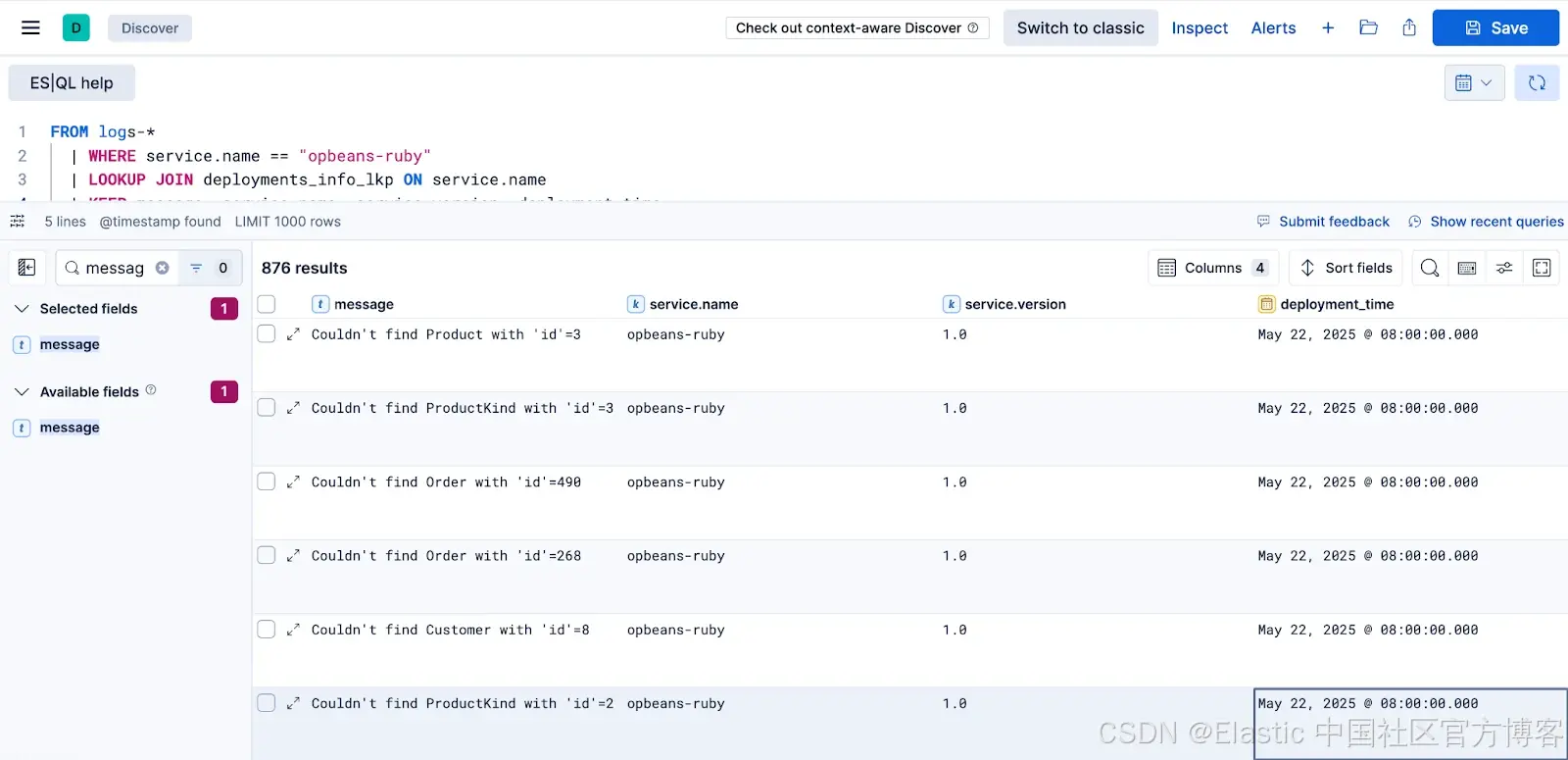
FROM logs-* | WHERE log.level == "error"| WHERE service.name == "opbeans-ruby"| LOOKUP JOIN deployments_info_lkp ON service.name
这本身就是排查问题的重要一步。现在每条错误日志中都包含了 deployment_time 列。接下来的最后一步是利用这个字段进行进一步筛选。
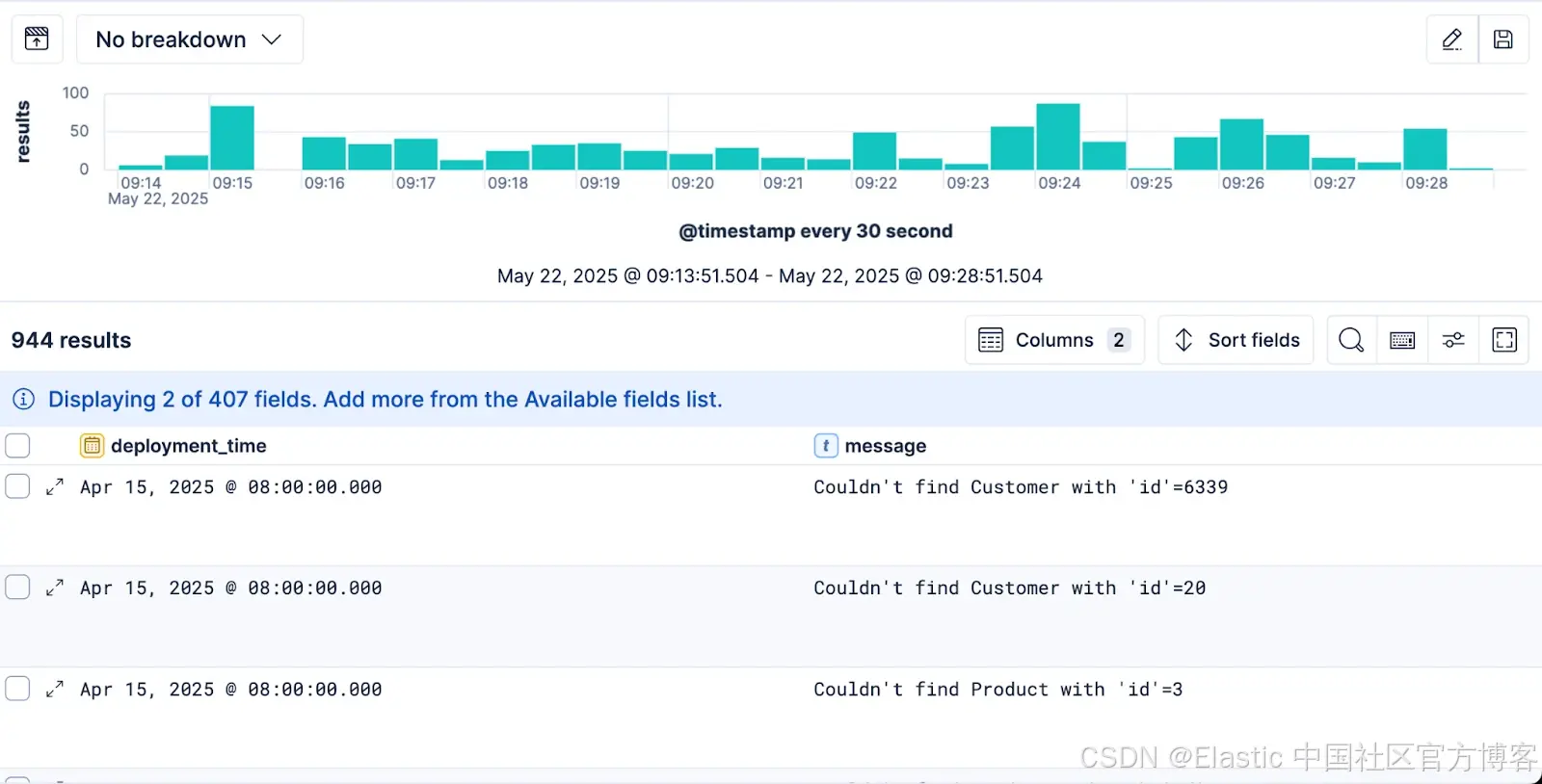
我们从 lookup 索引中连接到的任何数据,都可以像 ES|QL 查询中其他常规可用数据一样处理。这意味着我们可以基于它进行过滤,并检查是否有最近的部署。
FROM logs-*| WHERE log.level == "error"| WHERE service.name == "opbeans-ruby"| LOOKUP JOIN deployments_info_lkp ON service.name | KEEP message, service.name, service.version, deployment_time | WHERE deployment_time > NOW() - 2h
使用 JOIN 节省磁盘空间
通过在每条日志事件中直接包含主机操作系统或云服务商等上下文信息来反规范化数据,虽然查询方便,但会增加存储消耗,尤其是在高流量数据流中。与其重复存储这些经常冗余的信息,不如利用 join 按需获取,从而节省宝贵的磁盘空间。虽然压缩通常能很好地处理重复数据,但完全移除这些字段仍能显著减少存储。
在这个示例中,我们使用了 1,000,000 条 Kubernetes 容器日志数据,采用 Kubernetes 集成的默认映射,启用了 logsdb 索引模式。该索引的初始大小为 35.5MB。
GET _cat/indices/k8s-logs-default?h=index,pri.store.size
###
k8s-logs-default 35.5mb
通过磁盘使用情况 API(disk usage API),我们观察到像 host.os 和 cloud.* 这样的字段大约占据了磁盘上索引总大小(35.5MB)的 5%。这些字段在某些情况下有用,但像 os.name 这样的信息很少被查询。
// Example host.os structure
"os": {"codename": "Plow", "family": "redhat", "kernel": "6.6.56+","name": "Red Hat Enterprise Linux", "platform": "rhel", "type": "linux", "version": "9.5 (Plow)"
}// Example cloud structure
"cloud": {"account": { "id": "elastic-observability" },"availability_zone": "us-central1-c","instance": { "id": "5799032384800802653", "name": "gke-edge-oblt-edge-oblt-pool-46262cd0-w905" },"machine": { "type": "e2-standard-4" },"project": { "id": "elastic-observability" },"provider": "gcp", "region": "us-central1", "service": { "name": "GCE" }
}
与其在每个文档中存储这些信息,不如在 ingest pipeline 中去除这些字段:
PUT _ingest/pipeline/drop-host-os-cloud
{"processors": [{ "remove": { "field": "host.os" } },{ "set": { "field": "tmp1", "value": "{{cloud.instance.id}}" } }, // Temporarily store the ID{ "remove": { "field": "cloud" } }, // Remove the entire cloud object{ "set": { "field": "cloud.instance.id", "value": "{{tmp1}}" } }, // Restore just the cloud instance ID{ "remove": { "field": "tmp1", "ignore_missing": true } } // Clean up temporary field]
}
重新索引(并强制合并为一个段)后,索引大小如下,节省了大约 5% 的空间。
GET _cat/indices/k8s-logs-*?h=index,pri.store.size
###
k8s-logs-default 33.7mb
k8s-logs-drop-cloud-os 35.5mb
现在,为了在分析时重新获得被移除的 host.os 和 cloud.* 信息,而不必存储在每条日志中,我们可以创建一个 lookup 索引。该索引将存储完整的主机和云元数据,使用我们在日志中保留的 cloud.instance.id 作为键。这个 instance_metadata_lkp 索引会比节省的空间小得多,因为它只需为每个唯一实例存储一条文档。
# Create the lookup index for instance metadata
PUT /instance_metadata_lkp
{"settings": {"index.mode": "lookup"},"mappings": {"properties": {"cloud.instance.id": { # The join key we kept in the logs"type": "keyword"},"host.os": { # The full host.os object we removed"type": "object","enabled": false # Often don't need to search sub-fields here},"cloud": { # The full cloud object we removed (mostly)"type": "object","enabled": false # Often don't need to search sub-fields here}}}
}# Bulk index sample instance metadata (keyed by cloud.instance.id)
# This data might come from your cloud provider API or CMDB
POST /_bulk
{ "index" : { "_index" : "instance_metadata_lkp", "_id": "5799032384800802653" } }
{ "cloud.instance.id": "5799032384800802653", "host.os": { "codename": "Plow", "family": "redhat", "kernel": "6.6.56+", "name": "Red Hat Enterprise Linux", "platform": "rhel", "type": "linux", "version": "9.5 (Plow)" }, "cloud": { "account": { "id": "elastic-observability" }, "availability_zone": "us-central1-c", "instance": { "id": "5799032384800802653", "name": "gke-edge-oblt-edge-oblt-pool-46262cd0-w905" }, "machine": { "type": "e2-standard-4" }, "project": { "id": "elastic-observability" }, "provider": "gcp", "region": "us-central1", "service": { "name": "GCE" } } }
通过这种设置,当你需要日志的完整主机或云上下文时,只需在 ES|QL 查询中使用 LOOKUP JOIN,并继续基于 lookup 索引中的数据进行过滤。
FROM logs-* | LOOKUP JOIN instance_metadata_lkp ON cloud.instance.id | WHERE cloud.region == "us-central1"
这种方法允许我们在需要时查询完整上下文(例如,按 host.os.name 或 cloud.region 过滤日志),同时通过避免冗余数据的反规范化,显著减少高流量日志索引的存储占用。
需要注意的是,低基数的元数据字段通常压缩效果很好,这里大部分存储节省来自 host.os.name 和 cloud.instance.name 字段的 “text” 映射。请务必使用 disk usage API 来评估这种方法是否适合你的具体用例。
开始使用 Observability 的 Lookup
创建必要的 lookup 索引很简单。正如我们最初的博客文章所述,你可以使用 Kibana 的索引管理界面、Create Index API 或文件上传工具,关键是在索引设置中将 "index.mode" 设置为 "lookup"。
对于 Observability,可以考虑自动填充这些 lookup 索引:
-
定期从你的 CMDB、CRM 或 HR 系统导出数据。
-
让你的 CI/CD 流水线在成功部署后更新 deployments_lkp 索引。
-
使用 Logstash 等工具,配置 elasticsearch 输出写入你的 lookup 索引。
性能和替代方案说明
虽然功能强大,但 joins 并非免费。每个 LOOKUP JOIN 都会增加查询的处理开销。对于非常静态的上下文数据(例如主机永久所在的云区域)且几乎每次查询都需要时,传统的在 ingest 时丰富数据的方法,可能在特定查询上性能更优,前期处理和存储开销换取查询速度。
但是,对于 Observability 中常见的动态、灵活和有针对性的丰富场景,比如映射不断变化的部署、用户分组或团队结构,LOOKUP JOIN 提供了一个高效且更易管理的解决方案。
结论
ES|QL 的 LOOKUP JOIN 让你能在查询时轻松关联并丰富日志、指标和跟踪数据,结合最新的外部信息;你可以更快地从发现问题到理解其范围、影响和根本原因。
该功能目前在 Elasticsearch 8.18 和 Serverless 中处于技术预览阶段,现已在 Elastic Cloud 上可用。我们鼓励你用自己的 Observability 数据试用,并通过 Discover 中 ES|QL 编辑器的“Submit feedback”按钮分享反馈。期待看到你如何用它来连接系统中的点!
原文:Connecting the Dots: ES|QL Joins for Richer Observability Insights — Elastic Observability Labs