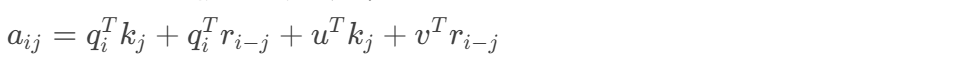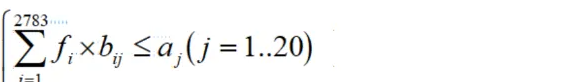脱发因素机器学习数据分析
一、背景描述
随着年龄增长,脱发成为影响外貌与健康的重要问题。
本数据集包含遗传、荷尔蒙变化、医疗状况、药物治疗、营养缺乏、心理压力等12个可能导致脱发的因素,
旨在通过数据分析挖掘各因素与脱发的潜在关联,为健康管理和医疗干预提供参考。
二、数据说明
| 字段 | 说明 | 数据类型 |
|---|---|---|
| Id | 标识符 | 整数 |
| Genetics | 是否有秃头家族史(1:是 / 0:否) | 二分类(0/1) |
| Hormonal Changes | 是否经历荷尔蒙变化 | 二分类(0/1) |
| Medical Conditions | 病史(多选项) | 字符串(逗号分隔) |
| Medications & Treatments | 药物治疗史(多选项) | 字符串(逗号分隔) |
| Nutritional Deficiencies | 营养缺乏(多选项) | 字符串(逗号分隔) |
| Stress | 压力水平(低/中/高) | 分类变量 |
| Age | 年龄 | 整数 |
| Poor Hair Care Habits | 是否有不良护发习惯 | 二分类(0/1) |
| Environmental Factors | 是否暴露于有害环境 | 二分类(0/1) |
| Smoking | 是否吸烟 | 二分类(0/1) |
| Weight Loss | 是否经历显著体重减轻 | 二分类(0/1) |
| Hair Loss | 是否脱发 | 二分类(0/1) |
三、需求
1. 描述统计
- 计算平均年龄与年龄分布
- 统计最常见的医疗条件及其频率
- 统计营养缺乏的种类及出现频率
2. 可视化分析
- 不同年龄段脱发比例(柱状图)
- 各因素与脱发的相关性(热力图)
- 不同压力水平下的脱发情况(柱状图)
3. 机器学习建模
- 构建分类模型预测脱发(逻辑回归、随机森林)
- 聚类分析探索脱发群体类型(KMeans)
- 识别关键影响因素(随机森林特征重要性)
四、代码实现
导包
# 先设置环境变量,避免CPU核心数警告
import os# 设置使用的CPU核心数(根据实际情况调整,建议为逻辑核心数的一半)
os.environ["LOKY_MAX_CPU_COUNT"] = "4"# 导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')# 配置matplotlib支持中文字体
plt.rcParams.update({"font.family": ["SimHei", "serif"],"axes.unicode_minus": False
})数据预处理
# ---------------------- 数据读取与预处理 ---------------------- #
# 读取数据(确保列名与数据说明一致)
data = pd.read_csv('data/08/predict_hair_fall.csv')# ---------------------- 1. 二分类字段转换(Yes/No转0/1)---------------------- #
binary_columns = ['Genetics', 'Hormonal Changes', 'Poor Hair Care Habits','Environmental Factors', 'Smoking', 'Weight Loss', 'Hair Loss'
]
for col in binary_columns:data[col] = data[col].replace({'Yes': 1, 'No': 0}) # 假设数据用Yes/No表示# ---------------------- 2. 多选项字段拆分(生成二进制特征)---------------------- #
def split_multiple_features(df, column_name, prefix):"""拆分多选项字段为二进制特征"""df[column_name] = df[column_name].fillna('') # 处理空值# 拆分并生成虚拟变量dummies = df[column_name].str.split(', ', expand=True).stack().reset_index(level=1, drop=True)dummies = pd.get_dummies(dummies, prefix=prefix)return df.join(dummies.groupby(level=0).sum())# 拆分具体字段(注意列名需与数据集完全一致)
data = split_multiple_features(data, 'Medical Conditions', '病史')
data = split_multiple_features(data, 'Medications & Treatments', '药物')
data = split_multiple_features(data, 'Nutritional Deficiencies', '营养')# ---------------------- 3. 压力水平转换(文本转数值)---------------------- #
stress_mapping = {'Low': 1, 'Moderate': 2, 'High': 3}
data['Stress'] = data['Stress'].map(stress_mapping)# ---------------------- 4. 准备建模数据(排除非数值列)---------------------- #
drop_columns = ['Medical Conditions', 'Medications & Treatments', 'Nutritional Deficiencies', 'Id' # 排除原始字符串列和ID
]
model_data = data.drop(drop_columns, axis=1).copy() # 建模专用数据集(无字符串)描述统计
# ---------------------- 描述统计 ---------------------- #
# 1. 年龄统计
average_age = model_data['Age'].mean()
print(f"平均年龄:{average_age:.1f}岁")plt.figure(figsize=(8, 4))
sns.histplot(model_data['Age'], bins=10, kde=True, color='skyblue')
plt.title('年龄分布直方图')
plt.xlabel('年龄')
plt.ylabel('人数')
plt.show()# 2. 常见医疗条件统计
medical_counts = model_data.filter(like='病史_').sum().sort_values(ascending=False)
print("\n常见医疗条件(前5):")
print(medical_counts.head(5))# 3. 营养缺乏统计
nutritional_counts = model_data.filter(like='营养_').sum().sort_values(ascending=False)
print("\n营养缺乏种类(前5):")
print(nutritional_counts.head(5))平均年龄:34.2岁

常见医疗条件(前5):
病史_No Data 110
病史_Alopecia Areata 107
病史_Psoriasis 100
病史_Thyroid Problems 99
病史_Androgenetic Alopecia 98
dtype: int64营养缺乏种类(前5):
营养_Zinc Deficiency 108
营养_Vitamin D Deficiency 104
营养_Biotin Deficiency 99
营养_Vitamin A Deficiency 99
营养_Omega-3 fatty acids 92
dtype: int64
可视化分析
# ---------------------- 可视化分析(使用原始数据创建分组)---------------------- #
# 单独处理可视化数据(保留年龄分组)
visual_data = data.copy()
visual_data['年龄分组'] = pd.cut(visual_data['Age'], bins=[0, 20, 30, 40, 50, 60, 100],labels=['<20', '20-30', '30-40', '40-50', '50-60', '>60'])不同年龄段脱发比例
# 1. 不同年龄段脱发比例
age_loss_ratio = visual_data.groupby('年龄分组')['Hair Loss'].mean().reset_index()plt.figure(figsize=(10, 6))
sns.barplot(x='年龄分组', y='Hair Loss', data=age_loss_ratio, palette='viridis')
plt.title('不同年龄段脱发比例')
plt.xlabel('年龄分组')
plt.ylabel('脱发比例')
plt.xticks(rotation=45)
plt.show()
因素与脱发的相关性热力图(使用建模数据,全为数值型)
# 2. 因素与脱发的相关性热力图(使用建模数据,全为数值型)
corr = model_data.corr()plt.figure(figsize=(12, 8))
sns.heatmap(corr[['Hair Loss']].sort_values(by='Hair Loss', ascending=False), annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('各因素与脱发的相关性')
plt.show()
不同压力水平脱发情况
# 3. 不同压力水平脱发情况
stress_loss = model_data.groupby('Stress')['Hair Loss'].mean().reset_index()
stress_loss['压力水平'] = stress_loss['Stress'].map({1:'低', 2:'中', 3:'高'})plt.figure(figsize=(8, 5))
sns.barplot(x='压力水平', y='Hair Loss', data=stress_loss, palette='rocket')
plt.title('不同压力水平脱发比例')
plt.xlabel('压力水平')
plt.ylabel('脱发比例')
plt.show()
机器学习建模
# ---------------------- 机器学习建模 ---------------------- #
X = model_data.drop('Hair Loss', axis=1)
y = model_data['Hair Loss']# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)逻辑回归模型
# 1. 逻辑回归模型
logreg = LogisticRegression(max_iter=1000)
logreg.fit(X_train, y_train)
print(f"逻辑回归准确率:{accuracy_score(y_test, logreg.predict(X_test)):.2f}")逻辑回归准确率:0.47
随机森林模型
# 2. 随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
print(f"随机森林准确率:{accuracy_score(y_test, rf.predict(X_test)):.2f}")随机森林准确率:0.43
聚类分析 K-means 模型
# 3. 聚类分析(KMeans)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 肘部法则确定聚类数
inertia = []
for k in range(2, 6):kmeans = KMeans(n_clusters=k, random_state=42)inertia.append(kmeans.fit(X_scaled).inertia_)plt.figure(figsize=(8, 4))
plt.plot(range(2, 6), inertia, marker='o', linestyle='--', color='b')
plt.title('肘部法则确定聚类数')
plt.xlabel('聚类数k')
plt.ylabel('惯性值')
plt.show()
执行聚类
# 执行聚类(假设k=3)
kmeans = KMeans(n_clusters=3, random_state=42)
model_data['Cluster'] = kmeans.fit_predict(X_scaled)
print("\n聚类分布:")
print(model_data['Cluster'].value_counts())聚类分布:
Cluster
2 601
1 226
0 172
Name: count, dtype: int64
重要特征分布
# 4. 特征重要性分析
features = X.columns
importances = rf.feature_importances_
importance_df = pd.DataFrame({'特征': features, '重要性': importances}).sort_values(by='重要性', ascending=False)plt.figure(figsize=(10, 6))
sns.barplot(x='重要性', y='特征', data=importance_df.head(10), palette='Set3')
plt.title('前10重要特征')
plt.xlabel('重要性得分')
plt.ylabel('特征')
plt.show()