理想与现实的差异
在上文中,我们提到,一个优先级100的线程,跟一个优先级为120的线程进行公平调度的资源抢占的话。


从抓取的一份systrace上简单的对比来看,

其份额大概是24:1856 (systrace上随便框的,数据不够准确,看个大概就行了)。大概有个概念就行了,这里不准备深入分析优先级到weight的换算,以及weight到资源占比的换算。
而当两个线程的优先级都是120的话,我们可以看到。这两个线程的资源占比在1:1. 每间隔4ms轮转一次。

那么问题来了,为什么是4ms,而不是3ms或者5ms 呢?
答案是因为linux的时钟tick的周期为4ms,也就是250HZ。
上面提到的“proportional scheduling”,是有一整套理论数学模型的,最近kernel6.6上引入的eevdf,其最早可以追溯到一篇1996年的论文。但是从理论模型到工程实现,却有着种种限制。就跟原子弹的爆炸原理大家都知道,但是能造出原子弹的没几个。
当CFS的调度器在选取任务的时候,pick_next_task从红黑树的拿到最左节点。调度器是知道这个线程1的virtual runtime的(简称V1),同时也是知道左次节点的线程2的virtual runtime(简称V2),随着线程1的在CPU上运行,线程1的virtual runtime V1一直在递增。是一旦V1超过V2的时候,线程1就立马让出CPU给线程2吗?
答案是否定的。因为从工程实现上不可取。从理论模型上,我们希望有一个“上帝视角”在监测线程的虚拟时间的变化,同时把它跟红黑树上最小虚拟时间进行比较。一旦超过,就立马触发进程切换。 这虽然可以用定时器来进行控制,但是会带来额外的开销。毕竟CPU最终是为了提供计算能力,在一定时间内提供的计算能力越高,效果越好,比如make -j32进行编译。工作量是一定的,我们希望越快结束越好。这就提出了另外一个要求,就是throughout。throughout越高越好。
但是任务调度器自身的代码逻辑并不产生throughout,反而是在额外的消耗CPU的资源。从throughout的角度,其实期望调度器越少的参与越好。
调度器的事件驱动
调度器没有上帝视角,也没有一个监视器在时时刻刻监视系统中进程的情况变化。因此大部分的调度器都折中地选择了通过事件来驱动。
那么都是哪些事件呢?这里我们借用一下高通walt代码里面的内容。
52 const char *task_event_names[] = { 53 "PUT_PREV_TASK", 54 "PICK_NEXT_TASK", 55 "TASK_WAKE", 56 "TASK_MIGRATE", 57 "TASK_UPDATE", 58 "IRQ_UPDATE" 59 }; |
由于我们上述的例子里面讲到的一个特殊的情况,即2个不会主动终止的死循环线程的调度轮换与配额问题。因此我们实际遇到的最多的两个事件是:
1.task wake
2.irq update
第一个task wake是指当一个线程A(也可能是隐藏在某个进程里面的中断)唤醒线程B的时候,需要检查一下,这个被唤醒的线程是否需要抢占当前CPU上正在运行的任务。
第二个irq update也比较好理解,最典型的就是我们上面提到的kernel tick。tick是一个arch timer的irq。每间隔4ms触发一次中断,进行线程状态的更新与判断。
这些event事件,有一种“过了这个村就没那个店”的感觉。
以task wake为例,因为CFS是每次都是选取虚拟时间最小的线程进行运行。假如被唤醒的线程B的虚拟时间,跟CPU上当前运行的线程的虚拟时间相比,要小一些,但是这个差异可以忽略不计。那么调度器就判断,抢占不成立。也就是被唤醒的线程B无法抢占当前正在CPU上运行的线程。当前线程继续运行。
那么什么时候线程B才会被调度出去呢?答案是“不确定”,依赖于事件, 最长要等下一个tick的发生。如果不凑巧,当前线程处于关中断状态,比如调用了spinlock_irqsave关闭了CPU的local irq呢? 这时候tick中断也不会发生,需要一直等下去。因此正在运行的线程B有可能并不是系统中“实际”虚拟时间最小的,只是没有事件来驱动更新数据而已。
虽然理论模型是比较完善的,但是在工程实现过程中进行各种取舍,大部分调度器(包括freebsd以及ios)都是基于事件触发的。就给调度器的实际运行结果带来了一些不确定性,它并不是一台完美无瑕的精准的机器。
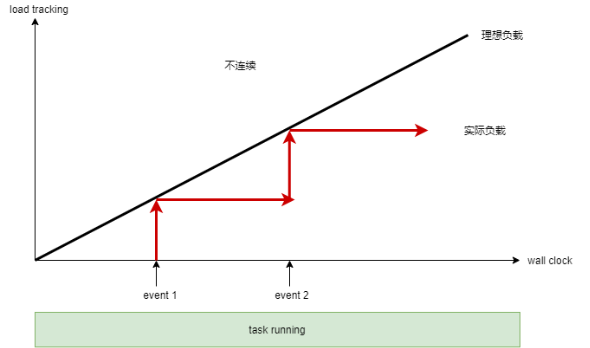
上图是一张示意图,横坐标是实际时间,纵坐标是一些负载或者虚拟时间的统计变量。黑色斜线是理论模式里面,虚拟时间随着时间增加的理想情形。但是因为整个调度器是基于事件触发的,实际情况是红色折线。每次事件发生时,虚拟时间发生统计上的跳变。理论上的连续,变成了实际的离散。
这些离散事件引起的“跳变”让整个调度器的运作并不是非常精准(当然,如果事件足够密集的话,可以构成一条近似的连续线条)。因此很多时候,tick周期4ms就成为托底的机制。因此这个tick的周期成为调度器的一个精度保障(关抢占、关中断这两种情况比较特殊,暂不在讨论范围内)。
如果我们将linux的心跳从250HZ改成1000HZ,那么整个调度器的精度会得到相应的提升,但是也会带来更多的开销,导致系统的throughout一定程度上的降低。
在上面我们引入了2个调度器的指标,其中一个是throughout吞吐量,我们当然希望吞吐量越大越好。因为吞吐量才是实际的输出,而调度器本身内部统计跟决策逻辑产生的是损耗。就跟红十会一样,会收“管理费”,所以大家才把钱捐给韩红的基金会。
另外一点是调度器的精度,或者latency延迟。这个从事performance分析的同学比较熟悉。
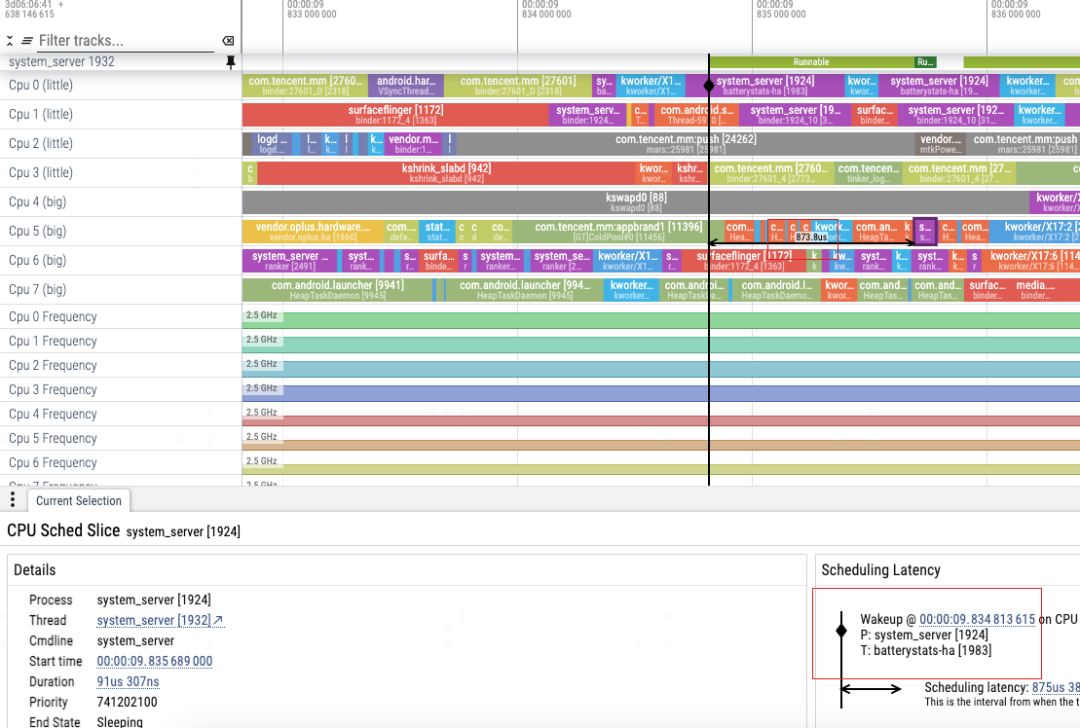
图:线程1932从被唤醒(被线程1983唤醒)到获取到CPU资源过程中,有873us的延迟
钱捐出去了,我们希望这些钱或者物资更快的达到需要的人手里,而不是在红十会的仓库里。我们希望调度器更好的发挥分时复用的能力,让各个进程看起来都是得到“实时”的调度。如果延迟比较大的话,就会产生”不实时“的感觉。
事实上这两个指标之间是矛盾的,因为throughout要求调度器尽量少的干预运行。但是低延迟要求调度器进行系统的跟踪监视,并且精度尽可能的高,尽快的做出响应,这些都要求调度器尽量多的运行。
到目前为止,我们介绍了任务调度器,以及cgroup,event-driven scheduler等等概念。都是在围绕着CPU的任务调度器。很多年前,当时手机处理的CPU还是单核的,慢慢的变成双核,四核直到今天的八核甚至十核。以前所有的CPU都是同构的,也就是每个CPU都是一样的(SMP)。但是随着处理器性能的提升,人们发现已经无法同时满足高性能与低功耗了。为了提升CPU单核处理器的性能,不得不把流水线做的更深,频率更高,乱序执行、多发射等等。高频性能与低频功耗不可兼得。
似乎进入了死胡同,但是人的想象力是无止尽的。“天空一声巨响,big-little闪亮登场”。在SOC上同时存在big大核跟little小核。大核可以提供高性能,给一些需要高算力的任务运行,little小核可以做到低功耗,给一些轻载任务来运行。似乎问题得到了完美的解决,要性能有性能,要功耗有功耗。其实不然,潘多拉之盒才刚刚开启,软件苦难的日子才开始。因为B-L成功的将一个硬件难题转变了软件难题,而软件似乎是无所不能的,而且也是“不值钱的”。
回到这个设计的最初设想,大核给需要性能的大任务用,满足性能;小核给轻载的小任务节省功耗。那么多大的任务是大任务呢?
多大的任务是大任务,多小的任务是小任务呢?
一下子傻眼了吧。因为在big-little出现之前,处理器基本都是同构的,也就是SMP-对称多处理"(Symmetrical Multi-Processing)技术,而且由于这些CPU公用同一个时钟源(clock source)来进行驱动,因此他们也是同频的。所以在任务选择的时候,只需要做到多个CPU之间任务分布的均衡或者算力需求的均衡就可以了。 因此SMP只要做好任务的均衡就行了,避免“一核有难、九核围观”的惨剧就行。

再次借用一下这张图,因为太经典了
但是在big-little架构下(HMP,heterogeneous multi-processor),大核跟小核的同频率性能存在较大的差异,而且频率也是不同的时钟源,并不同频(小核跟大核不同频, 每个cluster内部还是同频的),问题一下子复杂化。
回到原始的问题,那么多大的任务是大任务的呢? 这个问题最初一看,以为很好回答,但是如果细想一下,其实非常复杂。就跟人眼看一眼图片中的猫,就能认出这是猫一样,让计算机程序去识别图片中的猫,却非常困难,直到最近十年因为处理器算力提升重新捡起来的各种神经网络,这个问题才初步得到一定程度的解释,但是还没有根本解决。
一些人脑很容易判断的事实,计算机却非常难以判断。
要回答多大的任务才是大任务,就不得不回归到对于任务的量化度量上。
当前在linux生态中,存在两种任务的负载量化的模型,也就是pelt(per-entity load tracking)跟walt (Window Assisted Load Tracking)。这两种算法虽然不一样,但是都是基于历史信息来预估。就跟银行会基于你的“征信报告”来觉得是否给你发放贷款一样。这些方法有一定的局限性,因为有些人没征信记录(不用担心办信用卡,正确的使用信用卡是个加分项),有些人故意刷记录。
PELT(per-entity load tracking)
网上关于pelt(http://www.wowotech.net/process_management/450.html)以及walt的资料很多,这里不详细讲解了,只讲一下基本原理。从pelt的角度,任务在过去运行过的任何一段时间(注意是所有),都对于负载造成影响贡献,只是距离现在的时间不一样,它们的贡献权重不一样而已。时间近的,贡献权重大;时间远的,贡献权重小。

进程运行的时间横轴,以1ms为一个period周期,Li是一个调度实体在i个时间周期内的负载,虽然进程已经又运行了i个周期,它对当前系统负载仍有贡献 Li*y^i,y是衰减系数, y^32=0.5,距离当前时间点越远,衰减系数越大,对调度实体总的负载影响越小。为什么 y^32=0.5呢?这个是经验值,可以调整修改https://lwn.net/Articles/906375/。
pelt带来了一个很奇怪的问题,就是当任务不运行时候,基于pelt算法的理论,计算出来的负载是不为0的(因为衰减需要一定的时间)。因此,当一个CPU即使进入idle,CPU上的pelt负载也是不为0的(奇怪吧!),而且也参与到了整个cluster上的调频。
WALT(Window Assisted Load Tracking)
当移动android终端继续采用pelt的时候,大家发现个问题,就是pelt的负载累积过慢。以一个死循环的while(1)程序为例,横坐标是时间,纵坐标是通过pelt计算出来的负载(最大值是1024)。当这个进程从刚开始创建,到pelt能够正确的表示它的最大负载的时候,已经过去100+ms。
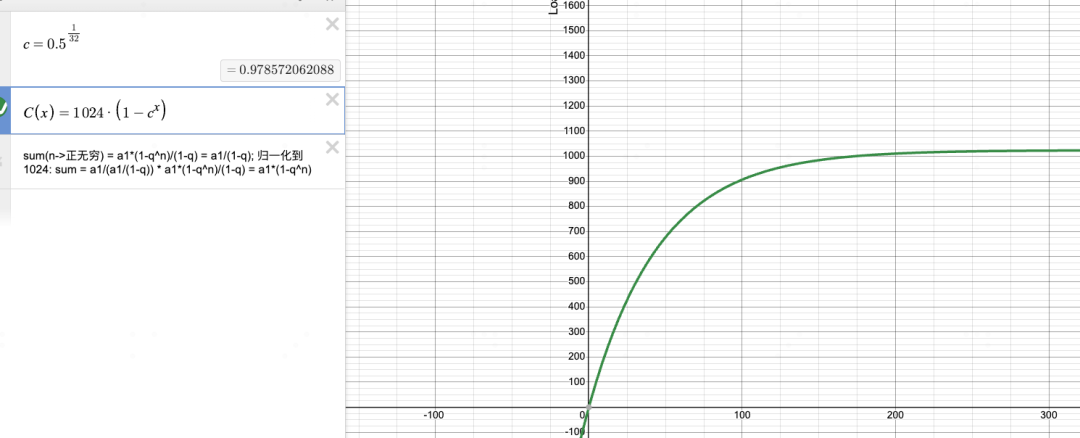
图:pelt时间负载曲线示意图
而我们的60HZ刷新率的屏幕的整个单帧绘制周期只有16.7ms。等到100ms的话,黄花菜都凉了。因此pelt的这种基于历史运行状态进行累计负载的做法,并不太适应于交互式的设备。
因此QUALCOMM在其最初的HMP架构的处理器上设计了walt算法。https://lwn.net/Articles/704903/

其核心思想就是把时间分成一个个对齐的窗口周期,通过统计线程在窗口周期的运行时间占比来计算负载。

图:walt窗口统计原理
听起来是不是很合理?!可惜,被社区给拒绝了。因此高通一直在单独维护walt的所有相关代码。相比pelt,walt确实可以大幅提升负载累积的速度,但是窗口周期虽然对周期性的绘制比较有利,但是android系统里面除了这些线程之外,还有很多其他的非周期性运行的线程。
比如说,当一个线程正好跨窗口,以下图为例,进程刚好被窗口边界(T1+T)分割成两部分,前一部分属于(T1,T1+T)的窗口周期,后一部分属于(T1+T, T1+2T)的窗口周期。但是这个线程很可能是因为丢帧才落到了2个周期内,是一个完整的负载,并不应该做切割。
图:进程被walt窗口切割
这时候pelt的理论优势就出来了。只要线程运行的pattern是一定的,它的负载值就是唯一的,而walt会受到窗口的影响。
但是不管是pelt,还是walt,都需要一定的统计时长(启发式统计,或许未来AI预测是个good idea),对于任务计算量突然发生变化的场景,依然显得无能为力。这一点以后再详细展开,可以看下图的一个实例。
图: 因为三方APK实现问题,线程负载突变,导致的负载跟踪不及时,导致的卡顿
上面不管pelt,还是walt。都是针对单个任务的负载量化方式,基于这些统计出来的量化负载,以及我们对于所谓“大任务”设置的各种threshold阈值,大体可以来粗略的来界定一个任务是不是大任务。
大任务跑大核,小任务就一定跑小核吗?
我猜大家肯定会下意识的回答是(苹果跟intel一般把小核称之为efficiency core),但是细想一下好像哪里不对。大家可能想到,如果都是小任务,而且小核堆积满了,这时候应该把多余的任务放到大核上。
那如果小核没有堆积满呢??
针对单个CPU,其算力与功耗的曲线图大概长成下面这个样子。
图:性能功耗能效示意图(网上随便搜的)
这是一条单调递增的,频率越高,功耗越高,斜率越大,能效比越差。这似乎是一条铁律。因此在SMP系统中,只需要考虑负载均衡(load balance)就行了,把负载尽可能均分到不同的CPU上。因为负载越均衡,系统的频率就会越低,功耗就会越低。
但是B-L引入之后,由于大核与小核之间是非对称异构的。情况瞬间发生了变化。
图:A53、A75能效曲线示意图
假如大小核的能效曲线如上图所示的话,我们依然可以认为任务在小核上功耗最优。那么如果情况变成下面这样呢。
当两条能效曲线出现了交叉的时候,到底任务跑在哪个CPU上更加省电呢?
这些都是B-L引入之后带来的问题,篇幅有点长,下一次我们继续介绍EAS。
往
期
推
荐
任务调度器:从入门到放弃(一)
ebpf工作原理介绍——ebpf指令集及虚拟机
自适应流媒体(ABR)技术与算法解析





![[LitCTF 2024]浏览器也能套娃?](https://i-blog.csdnimg.cn/direct/38fa3d73bfde45e5b5a2ebe3dd92db77.png)