LangChain实战:文档加载、分割与向量存储详解
在本文中,我将详细解析如何使用LangChain框架完成文档的加载、文本分割和向量存储的全过程。这是构建基于文档的问答系统、搜索引擎等AI应用的基础步骤。
1. 环境准备与数据加载
首先,我们需要导入必要的库并加载文档数据:
import os
import re
from dotenv import load_dotenv
from langchain_community.document_loaders import TextLoader, DirectoryLoader# 1.加载数据
loader = TextLoader("Q&A.txt", encoding="utf-8")
documents = loader.load()
在上面的代码中:
- 我们导入了必要的库,包括
os、re、dotenv工具包以及LangChain的文档加载器 - 使用
TextLoader加载单个文本文件,并指定编码为"utf-8" - 调用
load()方法读取文件内容到documents变量
批量加载文件(可选)
如果需要处理多个文档,可以使用DirectoryLoader:
"""批量加载数据文件
directLoader = DirectoryLoader("day3", glob="**/*.txt", loader_cls=TextLoader, show_progress=True)
documentss = directLoader.load()
"""
这段代码(已被注释)展示了如何:
- 加载指定目录中的所有txt文件
glob="**/*.txt"指定匹配所有嵌套子目录中的txt文件show_progress=True参数允许显示加载进度
2. 文本分割
文档加载后,通常需要将其分割成更小的块以便于处理:
from langchain_text_splitters import CharacterTextSplitter# 自带的文本分割器(有可能分的不彻底)
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0, separator="\n\n", keep_separator=True)
这段代码中:
- 我们使用
CharacterTextSplitter创建了一个文本分割器 chunk_size=500设置每个分块的最大字符数为500chunk_overlap=0设置分块间不重叠separator="\n\n"指定使用两个换行符作为分隔符keep_separator=True表示在分割后保留分隔符
自定义分割方法
我们还展示了两种手动分割文本的方法:
# 手写分割方法
text = re.split(r'\n\n', documents[0].page_content) # 使用正则表达式分割文本
# segments = text_splitter.split_text(documents[0].page_content) # 使用自定义的文本分割器
segments_documents = text_splitter.create_documents(text)
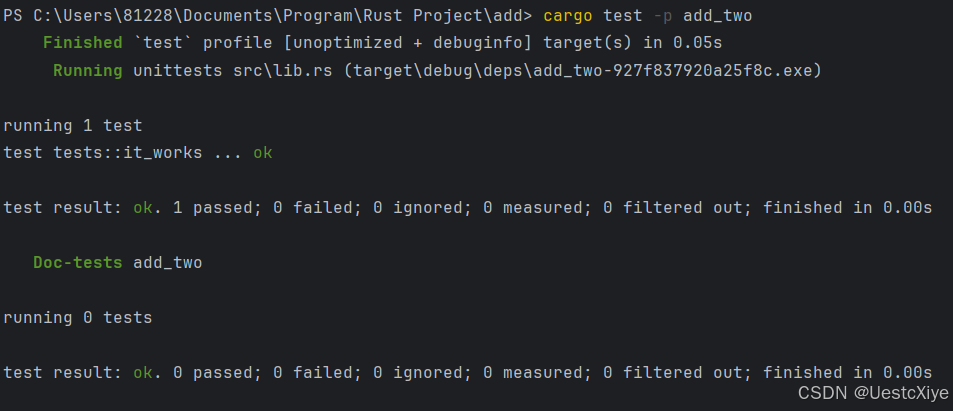
print(len(segments_documents)) # 打印分割后的段落数量
这里:
- 使用正则表达式
re.split()根据空行分割原始文档 - 使用分割器的
create_documents()方法将文本列表转换为Document对象列表 - 打印分割后的段落数量,便于我们了解分割效果
3. 向量存储
最后,我们需要将分割后的文本转换为向量并存储,以便后续检索:
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_redis import RedisConfig, RedisVectorStoreload_dotenv()
# 阿里云百炼平台的向量模型
embedding = DashScopeEmbeddings(model="text-embedding-v3", dashscope_api_key=os.getenv("ALY_EMBADING_KEY"))
redis_url = "redis://localhost:6379" # Redis数据库的连接地址config = RedisConfig(index_name="my_index2", # 索引名称redis_url=redis_url, # Redis数据库的连接地址
)# 创建向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# 添加文本到向量存储
vector_store.add_documents(segments_documents)
在这部分代码中:
- 使用
load_dotenv()加载环境变量,通常用于存储API密钥 - 创建阿里云百炼平台的文本嵌入模型实例
- 设置Redis连接配置,包括索引名称和数据库地址
- 初始化
RedisVectorStore作为向量存储 - 使用
add_documents()方法将分割后的文档添加到向量存储中
总结
通过上述步骤,我们完成了:
- 文档加载:读取本地文本文件
- 文本分割:将大文档分割为合适大小的片段
- 向量化存储:使用嵌入模型将文本转化为向量并存储在Redis数据库
这个流程为后续的文本检索、相似度查询和基于文档的问答系统提供了基础。使用Vector Store可以实现高效的语义搜索,相比传统关键词搜索能够更好地理解查询意图和文档内容。
需要注意的是,代码中使用了阿里云百炼平台的嵌入模型,在实际使用时需要确保相应的API密钥配置正确。同时,Redis数据库也需要预先安装并启动。
这种向量存储方法的特点是可以快速检索与查询文本语义相似的文档片段,非常适合构建智能客服、知识库问答等应用场景。




![[java八股文][JavaSpring面试篇]SpringCloud](https://i-blog.csdnimg.cn/img_convert/0b326c93749653e1f2b6ed02a7ee56f2.png)