Spring Cloud 知识
- 一. 服务注册与发现
- 1. Eureka
- 1. Eureka 的概念
- 2. Eureka 的特点
- 3. Eureka 的应用场景
- 4. Eureka 的实现原理
- 2. Nacos
- 1. Nacos 的概念
- 2. Nacos 的特点
- 3. Nacos 的应用场景
- 4. Nacos 的实现原理
- 1. 服务注册与发现:
- 2. 配置管理:
- 3. 一致性算法:
- 4. 通信机制:
- 5. 多环境支持:
- 5. Nacos的心跳机制
- 1.主动上报:
- 2. 反向探测:
- 3. 服务状态更新与通知:
- 6. 配置管理
- 1. 概念
- 2.特点
- 3.场景示例-动态更新数据库地址
- **(1)在 Nacos 控制台添加配置**
- **(2)服务端集成 Nacos 配置管理**
- **(3)动态更新配置**
- **(4)监听配置变更**
- **4. Nacos 配置管理的实现原理**
- **(1)配置存储**
- **(2)配置推送**
- **(3)动态更新**
- **5. 动态更新的优势**
- **6. 注意事项**
- **总结**
- 3. Nacos 和 Eureka 有什么区别
- 1. 应用场景
- 1.Nacos:
- 2. Eureka:
- 2. 总结
- 二. 负载均衡
- 1.概念
- 2.特点
- 3.应用场景
- 4.实现原理
- 5.实现方式
- 6.常见算法
- 1. 轮询(Round Robin)
- 2. 最少连接(Least Connections)
- 3. IP 哈希(IP Hashing)
- 4. 加权轮询(Weighted Round Robin)
- 5. 加权最少连接(Weighted Least Connections)
- 6. 随机(Random)
- 7. 响应时间最少(Least Response Time)
- 7. Feign和Ribbon
- 1. 概念
- 2. Feign 和 Ribbon 的关系
- 3. Feign 的工作原理
- 1. 声明式接口
- 2. 负载均衡
- 3. 容错机制
- 4. 动态代理
- 4. Ribbon 的工作原理
- 1. 服务实例列表获取
- 2 负载均衡策略选择
- 3. 请求转发
- 4. 动态调整
- 3. Feign 和 Ribbon 的集成
- 5. 总结
- 8. Feign和OpenFeign
- 1. 概念
- 2. 主要区别
- 1. 功能和特性
- 2. 使用方式
- 9. Feign和Dubbo
- 1. 通信协议
- 2. 服务调用方式
- 3. 负载均衡
- 4. 容错机制
- 5. 服务注册与发现
- 6. 适用场景
- 三. 断路器
- 1. 熔断
- 1. 概念
- 2. 熔断原理
- 3. 熔断机制
- 4. 使用场景
- 5. 实现方式
- 1. Hystrix
- 2. Sentinel
- 2. 降级
- 1. 工作原理
- 2. 使用场景
- 3. 实现方式
- 3. 限流
- 1. 概念
- 2. 常见限流算法
- 1. 漏桶算法
- 1. 概念
- 2. 核心思想
- 3. 不足
- 4. 算法描述
- 2. 令牌桶算法
- 1. 概念
- 2. 核心思想
- 3. 算法描述
- 3. 令牌桶和漏桶对比
- 3. 基于Redis 令牌桶算法实现限流
- 1. 实现原理
- 2. 操作步骤
- 1. 引入依赖
- 2. 配置KeyResolver-指定限流的 Key
- 3. 配置限流的过滤器信息
- 4. 测试结果
- 5. Redis存储内容
- 4. Sentinel 限流
- 1. 概念
- 2. 应用场景
- 3. 实现原理
- 4. 滑动窗口限流算法
- 5. 实现方式
- 6. 代码示例
- 1. 定义资源
- 2. 配置 QPS 限流规则
- 7. Sentinel 实现集群限流
- 1.集群限流的基本原理
- 2.配置集群限流服务端
- 3.配置集群限流客户端
- 四. API网关
- 五. 分布式配置中心
- 1. 概念
- 2. 主要功能包括:
- 3. 常见的配置中心
- 1. Spring Cloud Config
- 2. Nacos
- 3. Apollo
- 4. ZooKeeper
- 4.Nacos配置中心的实现原理
- 六. 链路追踪
- 1. 概念
- 2. 作用
- 3. 链路追踪方案
- 1. Spring Cloud Sleuth + Zipkin
- 2. SkyWalking
- 3. OpenTelemetry
- 七. 服务间通信机制
- 1.分布式事务
- 1.概念
- 2.特点
- 3. 应用场景
- 4.实现原理
- 5. 实现方式
- 6.总结
- 2.分布式事务解决方案-seata
- 1.Seata 的概念
- 2.Seata 的特点
- 3.Seata 的实现原理
- 4.事务回滚的实现
- 1. 事务日志记录
- 2. 回滚操作:
- 5.事务回滚的实现细节(以 AT 模式为例)
- 1.提交阶段:
- 2. 回滚阶段:
- 6.总结
一. 服务注册与发现
1. Eureka
1. Eureka 的概念
Eureka 是一款服务发现框架,主要用于构建分布式系统中的服务注册与发现。它包含两个核心组件:
- Eureka Server:作为服务注册中心,维护服务实例的注册信息。
- Eureka Client:服务提供者和消费者通过 Eureka Client 与 Eureka Server 交互,完成服务注册、发现和心跳检测。
2. Eureka 的特点
- 服务注册与发现:服务提供者启动时自动注册,消费者通过注册中心发现服务。
- 客户端负载均衡:Eureka Client 可以根据服务实例列表选择合适的服务实例进行调用。
- 自我保护机制:在网络分区或服务实例大量失效时,Eureka Server 不会误剔除健康实例,防止服务瘫痪。
- 高可用性:支持集群部署,通过多个 Eureka Server 节点相互复制注册信息,避免单点故障。
- 简单易用:与 Spring Cloud 深度集成,易于配置和使用。
3. Eureka 的应用场景
- 微服务架构:Eureka 是微服务架构中服务注册与发现的核心组件,支持服务间的动态调用和扩展。
- 负载均衡:通过客户端负载均衡策略(如轮询、随机等)分散请求压力,提高系统性能。
- 健康检查:通过心跳机制监控服务实例的健康状态,及时剔除不可用实例。
- 云原生环境:适用于云原生应用,支持动态扩缩容和高可用性。
4. Eureka 的实现原理
- 服务注册:服务启动时,Eureka Client 将自身信息(如服务名、IP 地址、端口号)注册到 Eureka Server。
- 心跳机制:服务实例定期向 Eureka Server 发送心跳(默认每 30 秒一次),表明自身存活。若 Eureka Server 在多个心跳周期内未收到心跳,则将该实例从注册表中移除。
- 服务发现:服务消费者通过 Eureka Client 查询 Eureka Server 获取目标服务的实例列表,并缓存这些信息。
- 自我保护模式:当 Eureka Server 在短时间内收到大量服务下线请求时,会进入自我保护模式,避免因网络问题误剔除健康实例。
- 集群同步:Eureka Server 之间通过异步复制机制同步服务注册信息,确保集群内各节点数据一致。
2. Nacos
1. Nacos 的概念
Nacos是一个开源的动态服务发现、配置管理和服务管理平台,广泛应用于微服务架构和云原生环境中。它提供了以下核心功能:
- 服务发现与注册:允许微服务在启动时向 Nacos 注册自身信息,并通过 Nacos 查询其他服务实例。
- 动态配置管理:支持集中式配置管理,允许动态更新配置信息,无需重启应用。
- 健康检查:通过心跳机制监控服务实例的健康状态,并自动剔除不健康的实例。
- 动态 DNS 服务:支持服务名到 IP 地址的动态映射。
- 多环境支持:通过命名空间和分组隔离不同环境的配置。
2. Nacos 的特点
- 功能全面:集成了服务发现、配置管理、健康检查、动态 DNS 等功能。
- 高可用性:支持集群部署,通过 Raft 算法保证分布式数据一致性。
- 易用性:提供丰富的 API 和客户端 SDK,支持多种编程语言。
- 云原生支持:与 Kubernetes 等云原生技术集成,支持容器化部署。
- 动态更新:配置信息支持动态更新和推送,无需重启应用。
3. Nacos 的应用场景
- 微服务架构:作为服务注册中心,支持服务发现和动态调用。
- 配置管理:集中管理微服务的配置信息,支持动态更新。
- 动态路由:与网关集成,实现基于规则的流量路由和负载均衡。
- 服务监控:通过健康检查监控服务状态,自动剔除不健康的实例。
- 多环境管理:支持开发、测试、生产等多环境的配置管理。
- 分布式系统:管理集群中的服务实例,支持高可用和容错。
4. Nacos 的实现原理
1. 服务注册与发现:
1.注册机制:服务实例启动时向 Nacos Server 注册自身信息,并通过心跳机制保持状态。
2. 发现机制:服务消费者通过 Nacos 查询服务实例列表,实现动态调用。
3. 健康检查:Nacos 使用心跳机制监控服务实例的健康状态,并自动剔除不健康的实例。
2. 配置管理:
- 配置存储:配置信息存储在 MySQL 或其他数据库中。
- 动态更新:客户端通过轮询或推送机制获取最新的配置信息。
3. 一致性算法:
Nacos 使用 Raft 算法保证分布式环境下数据的一致性。
4. 通信机制:
Nacos 使用 gRPC 实现客户端与服务端之间的高效通信。
5. 多环境支持:
通过命名空间和分组隔离不同环境的配置,支持多集群部署。
5. Nacos的心跳机制
1.主动上报:
- 客户端定期向Nacos Server发送心跳信号,表明服务实例处于健康状态。默认心跳间隔为5秒。如果Nacos Server在15秒内未收到心跳,会将该实例标记为不健康状态。
- 如果超过30秒仍未收到心跳,实例将被从注册表中移除。
2. 反向探测:
- Nacos Server会主动向客户端发起健康检查请求,通常用于长期运行的服务实例。
- 如果客户端未在规定时间内响应,Nacos会将其标记为不可用,但不会立即删除,直到多次探测失败。
3. 服务状态更新与通知:
Nacos Server在收到心跳后,会更新服务实例的健康状态,并在状态变化时推送服务变更事件给客户端。
6. 配置管理
集中管理微服务的配置信息,并支持动态更新。这意味着当配置信息发生变化时(例如数据库地址变更),服务可以无需重启即可获取最新的配置。
1. 概念
Nacos 提供了一个集中式的配置管理平台,允许开发者将配置信息(如数据库地址、端口号、API 密钥等)存储在 Nacos 服务器中,而不是硬编码在代码或本地配置文件中。
2.特点
- 集中管理:所有配置信息存储在 Nacos 中,便于统一管理和维护。
- 动态更新:配置信息发生变化时,服务可以实时获取更新,无需重启。
- 环境隔离:支持不同环境(开发、测试、生产)的配置隔离
3.场景示例-动态更新数据库地址
(1)在 Nacos 控制台添加配置
- 登录 Nacos 控制台。
- 在“配置管理”模块中,添加一个新的配置:
- Data ID:配置的唯一标识,例如
database-config。 - Group:配置分组,例如
DEFAULT_GROUP。 - 配置内容:
spring:datasource:url: jdbc:mysql://old-db-address:3306/mydbusername: rootpassword: password
- Data ID:配置的唯一标识,例如
(2)服务端集成 Nacos 配置管理
在微服务项目中,引入 Nacos 配置管理依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
在 bootstrap.yml 文件中配置 Nacos 的连接信息和配置监听:
spring:application:name: my-servicecloud:nacos:config:server-addr: 127.0.0.1:8848 # Nacos 服务器地址file-extension: yaml # 配置文件格式group: DEFAULT_GROUP # 配置分组data-id: database-config # 配置的 Data ID
(3)动态更新配置
当数据库地址变更时:
-
在 Nacos 控制台中修改配置内容:
spring:datasource:url: jdbc:mysql://new-db-address:3306/mydbusername: rootpassword: password -
Nacos 会自动推送配置变更事件到客户端。
-
客户端通过监听机制捕获配置变更,并动态更新本地配置。
(4)监听配置变更
如果需要在代码中监听配置变更,可以使用 @RefreshScope 注解:
@RestController
@RefreshScope // 支持动态刷新
public class DatabaseConfigController {@Value("${spring.datasource.url}")private String dbUrl;@GetMapping("/db-config")public String getDbConfig() {return "Current Database URL: " + dbUrl;}
}
当配置更新后,访问 /db-config 接口时,会返回最新的数据库地址。
4. Nacos 配置管理的实现原理
(1)配置存储
Nacos 将配置信息存储在内存中,并通过持久化机制(如数据库或文件)保存配置数据。配置信息以键值对的形式存储,每个配置项都有唯一的 Data ID 和 Group。
(2)配置推送
当配置信息发生变化时,Nacos 通过以下机制通知客户端:
- 长轮询机制:客户端通过长轮询(Long Polling)请求监听配置变化。当配置更新时,Nacos 会立即响应客户端的轮询请求,推送最新的配置。
- 事件推送机制:客户端通过监听配置变更事件,动态更新本地配置。
(3)动态更新
客户端通过 Spring 的 @RefreshScope 或 Nacos 的监听机制,捕获配置变更事件,并动态更新 Spring 容器中的配置属性。
5. 动态更新的优势
- 无需重启服务:配置更新后,服务可以实时获取最新配置,无需重启。
- 集中管理:所有配置信息存储在 Nacos 中,便于统一管理和审计。
- 环境隔离:支持不同环境的配置管理,避免配置冲突。
- 高可用性:Nacos 支持集群部署,确保配置管理的高可用性。
6. 注意事项
- 配置优先级:Nacos 支持多种配置来源(如本地配置文件、环境变量、Nacos 配置)。当存在冲突时,优先级顺序为:环境变量 > Nacos 配置 > 本地配置文件。
- 配置格式:支持多种配置格式(如 YAML、Properties),但需要在 Nacos 控制台中明确指定。
- 监听范围:使用
@RefreshScope时,仅支持对@Value注入的属性或@ConfigurationProperties配置类的动态刷新。
总结
Nacos 的配置管理功能通过集中存储配置信息、动态推送配置变更和客户端监听机制,实现了配置的动态更新。这对于微服务架构中的配置管理非常实用,尤其是当配置信息(如数据库地址、API 密钥等)需要频繁变更时,Nacos 能够显著提升系统的灵活性和可维护性。
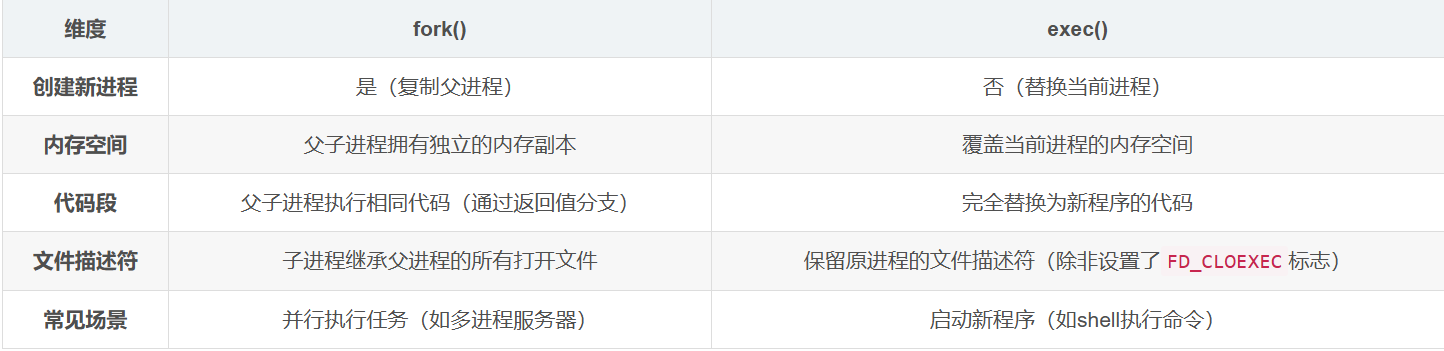
3. Nacos 和 Eureka 有什么区别
1. 应用场景
1.Nacos:
- 适用于需要动态配置管理、服务治理和多环境管理的复杂微服务架构。
- 支持云原生应用,与 Kubernetes 等技术集成。
- 适合对服务健康检查和配置动态更新有较高要求的场景。
2. Eureka:
- 更适合对服务注册与发现功能需求简单、追求高可用性的场景。
- 与 Spring Cloud 生态系统高度集成,适合传统微服务架构。
2. 总结
- 如果你的项目需要强大的服务治理功能、动态配置管理以及对数据一致性的支持,Nacos 是更好的选择。
- 如果你的项目主要关注服务注册与发现,且对可用性要求较高,Eureka 更为简洁和轻量。
二. 负载均衡
1.概念
在 Spring Cloud 中,负载均衡用于将客户端请求分发到多个服务实例,以优化资源利用率、提高系统可用性和响应速度。负载均衡器在客户端和服务实例之间充当“交通警察”的角色,根据预设的策略动态选择目标服务实例。
2.特点
-
高可用性:通过将流量分发到多个服务实例,避免单点故障。
-
性能优化:根据服务器的负载情况动态分配流量,避免某些服务器过载。
-
会话保持:支持将同一客户端的多次请求路由到同一服务实例,确保会话一致性。
-
动态扩展:支持水平扩展,通过动态添加或移除服务实例来适应流量变化。
-
透明性:对客户端透明,客户端无需感知后端服务实例的具体分布。
3.应用场景
-
微服务架构:在 Spring Cloud 微服务架构中,负载均衡用于动态发现和分发请求到多个服务实例。
-
容器化部署:在 Kubernetes 或 Docker 等容器化环境中,负载均衡用于管理动态变化的服务实例。
-
高流量应用:如电商、视频流媒体等需要处理高并发请求的场景。
-
多数据中心部署:通过地理负载均衡,将请求路由到离用户最近的数据中心,减少延迟。
4.实现原理
Spring Cloud 的负载均衡通过客户端负载均衡器(如 Ribbon)或服务网格(如 Istio)实现。其工作原理包括:
-
服务发现:通过注册中心(如 Eureka、Consul)获取服务实例列表。
-
健康检查:定期检查服务实例的健康状态,确保流量只分发到健康的实例。
-
流量分发:根据预设的负载均衡算法将请求分发到目标实例。
-
会话保持(可选):通过算法(如 IP 哈希)确保同一客户端的请求被路由到同一实例。
5.实现方式
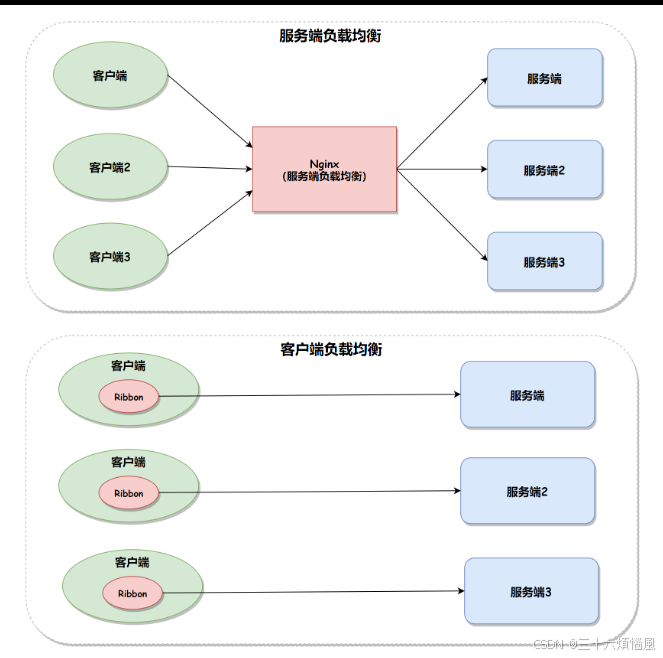
-
客户端负载均衡:如 Spring Cloud Ribbon,由客户端决定将请求发送到哪个服务实例。
-
服务端负载均衡:如 Nginx 或 HAProxy,通过反向代理实现负载均衡。
-
服务网格:如 Istio,通过中间层代理实现负载均衡。
-
云平台负载均衡:如 AWS ELB 或阿里云 SLB,提供托管的负载均衡服务。
6.常见算法
1. 轮询(Round Robin)
按顺序将请求分发到每个服务实例,适用于服务器性能相近的场景。
2. 最少连接(Least Connections)
将请求分发到当前连接数最少的实例,适合处理长连接。
3. IP 哈希(IP Hashing)
根据客户端 IP 地址的哈希值分配请求,确保同一客户端的请求被路由到同一实例。
4. 加权轮询(Weighted Round Robin)
根据服务实例的权重分配请求,权重高的实例会接收更多流量。
5. 加权最少连接(Weighted Least Connections)
结合权重和连接数,优先选择权重高且连接数少的实例。
6. 随机(Random)
随机选择服务实例,适用于服务器性能一致的场景。
7. 响应时间最少(Least Response Time)
将请求分配到响应时间最短的实例,适合对性能要求较高的场景。
7. Feign和Ribbon
1. 概念
在 Spring Cloud 中,Feign 和 Ribbon 在微服务架构中共同实现服务调用和负载均衡。
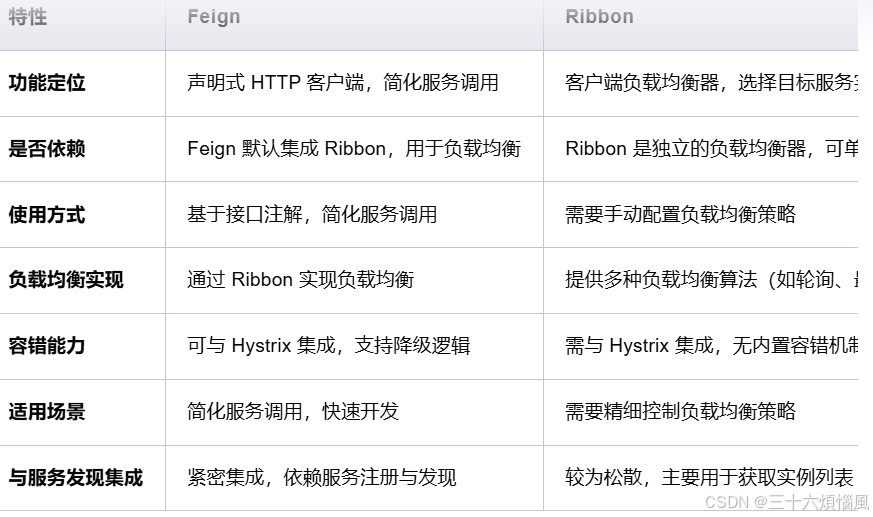
2. Feign 和 Ribbon 的关系
3. Feign 的工作原理
1. 声明式接口
Feign 通过定义接口和注解的方式,简化了微服务之间的调用。开发者只需要定义一个接口,并使用注解(如 @FeignClient)标记,Feign 会自动生成代理实现。
@FeignClient(name = "your-service-name")
public interface YourServiceClient {@GetMapping("/your-endpoint")String yourMethod();
}
2. 负载均衡
Feign 默认使用 Ribbon 实现负载均衡。Ribbon 会根据配置的策略(如轮询、最少连接等)选择目标服务实例。
3. 容错机制
Feign 可以与 Hystrix 集成,实现熔断和降级逻辑,提高系统的容错能力。
4. 动态代理
Feign 使用动态代理技术,根据接口定义生成代理对象,代理对象在调用时会通过 Ribbon 选择合适的服务实例进行请求
4. Ribbon 的工作原理
1. 服务实例列表获取
Ribbon 在客户端维护一个服务实例列表,并根据预设的策略选择目标实例。通过服务注册中心(如 Eureka)获取目标服务的所有实例列表。这些实例列表会动态更新,以反映服务的可用性。
2 负载均衡策略选择
根据配置的负载均衡策略(如轮询、最少连接等),Ribbon 从实例列表中选择一个目标实例。Ribbon 支持多种负载均衡算法,如:
- 轮询(Round Robin)
- 最少连接(Least Connections)
- 加权轮询(Weighted Round Robin)
- 随机(Random)
3. 请求转发
Ribbon 将客户端的请求转发到选定的服务实例。如果请求失败,Ribbon 可以根据配置进行重试。
4. 动态调整
如果某个服务实例不可用,Ribbon 会自动从实例列表中移除该实例,并将后续请求转发到其他健康的实例
3. Feign 和 Ribbon 的集成
在 Spring Cloud 中,Feign 默认集成了 Ribbon,用于实现负载均衡。以下是集成的步骤:
- 添加依赖
在项目中添加 Spring Cloud 的依赖,包括 Feign 和 Ribbon:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-ribbon</artifactId>
</dependency>
- 启用 Feign 客户端
在主程序中启用 Feign 客户端:
@SpringBootApplication
@EnableFeignClients
public class YourApplication {public static void main(String[] args) {SpringApplication.run(YourApplication.class, args);}
}
- 定义 Feign 客户端
定义一个 Feign 客户端接口,用于调用目标服务:
@FeignClient(name = "your-service-name")
public interface YourServiceClient {@GetMapping("/your-endpoint")String yourMethod();
}
- 配置负载均衡策略
通过配置文件或代码配置 Ribbon 的负载均衡策略。例如,配置为“最少连接”策略:
spring:application:name: gateway-servicecloud:gateway:routes:// 服务名相同,id不同,代表多实例- id: backend-serviceuri: lb://backend-servicepredicates:- Path=/api/**# Ribbon配置
ribbon:# 设置Ribbon的负载均衡策略为最少连接NFLoadBalancerRuleClassName: com.netflix.loadbalancer.BestAvailableRule或者通过代码实现自定义策略:
@Configuration
public class RibbonConfiguration {@Beanpublic IRule ribbonRule() {return new LeastConnectionsRule(); // 最少连接策略}
}
5. 总结
- Feign 是一个声明式 HTTP 客户端,通过接口注解简化了服务调用,适合快速开发。
- Ribbon 是一个客户端负载均衡器,提供了多种负载均衡算法,适合需要精细控制负载均衡策略的场景。
- 在 Spring Cloud 中,Feign 默认集成了 Ribbon,通过配置可以灵活选择负载均衡策略。
- 通过合理使用 Feign 和 Ribbon,可以构建高效、灵活且高可用的微服务架构。
8. Feign和OpenFeign
1. 概念
都用于实现微服务之间的声明式 HTTP 客户端调用
2. 主要区别
1. 功能和特性
-
OpenFeign 除了继承 Feign 的核心功能外,还增加了对 Spring MVC 注解的支持(如 @RequestMapping、@GetMapping 等),使得代码风格更加统一。
-
配置方式:支持通过 @FeignClient 注解和配置类实现,同时提供了更灵
2. 使用方式
- Feign
@FeignClient(name = "your-service-name")
public interface YourServiceClient {@GetMapping("/your-endpoint")String yourMethod();
}
- OpenFeign
OpenFeign 的使用方式与 Feign 类似,但支持更多 Spring MVC 注解:
@FeignClient(name = "your-service-name")
public interface YourServiceClient {@RequestMapping(method = RequestMethod.GET, value = "/your-endpoint")String yourMethod();
}
9. Feign和Dubbo
1. 通信协议
- Feign:基于 HTTP/HTTPS 协议进行通信,使用短连接。它通过 HTTP 客户端(如 Ribbon)发送请求,适合 RESTful 风格的服务调用。
- Dubbo:默认使用 Dubbo 协议,基于 Netty 的 TCP 长连接,通信效率更高,适合高性能、低延迟的场景。此外,Dubbo 还支持多种协议(如 RMI、HTTP、Redis 等)。
2. 服务调用方式
- Feign:是一个声明式的 HTTP 客户端,通过注解定义接口,自动生成代理实现,调用方式类似于本地方法调用。
- Dubbo:是一个完整的 RPC 框架,提供者和消费者都需要集成 Dubbo。消费者通过代理调用服务,提供者实现接口并暴露服务。
3. 负载均衡
- Feign:通过集成 Ribbon 提供负载均衡,支持轮询、随机、最少连接等策略。
- Dubbo:内置多种负载均衡策略(如随机、轮询、最少活跃调用、一致性哈希等),并支持权重配置,灵活性更高。
4. 容错机制
- Feign:通过集成 Hystrix 提供熔断机制,支持简单的重试策略。
- Dubbo:支持多种容错策略(如失败重试、快速失败、广播调用等),并提供 retry 次数和 timeout 等配置。
5. 服务注册与发现
- Feign:依赖 Spring Cloud 的注册中心(如 Eureka、Consul、Nacos)。
- Dubbo:支持多种注册中心(如 ZooKeeper、Redis、Consul 等),默认使用 ZooKeeper。
6. 适用场景
- Feign:适用于基于 HTTP 的微服务架构,特别是与 Spring Cloud 生态集成的场景。
- Dubbo:适用于高性能、低延迟的内部服务调用,适合对性能要求较高的复杂业务场景。
三. 断路器
1. 熔断
1. 概念
通过监控服务调用的成功率和响应时间,当调用失败次数超过一定阈值时,熔断器会“熔断”,直接拒绝对该服务的调用,返回预设的错误信息或不执行后续逻辑。
2. 熔断原理
- 监控调用状态:记录调用的成功、失败、超时等状态。
- 自动熔断:当失败率达到一定阈值时,自动切换到“熔断状态”,直接返回错误或默认值,避免继续调用。
- 恢复调用:经过一定时间后,尝试恢复调用,如果成功则恢复调用链路,否则继续熔断。
3. 熔断机制
熔断机制涉及三种状态:
- 熔断关闭状态(Closed):服务调用正常,熔断器处于关闭状态。
- 熔断开启状态(Open):当服务调用失败率超过阈值(如50%)时,熔断器进入开启状态,后续调用直接返回失败。
- 半熔断状态(Half-Open):经过一段时间后,熔断器进入半熔断状态,尝试恢复服务调用,监控调用成功率。如果成功率达到预期,则恢复正常调用。
4. 使用场景
- 高并发场景:如秒杀、抢购等,防止服务过载。
- 依赖外部服务:当系统依赖第三方服务时,防止外部服务不可用导致系统故障。
- 网络不稳定场景:避免网络问题导致的级联故障。
5. 实现方式
1. Hystrix
关键特性:
- 状态管理:包括关闭(Closed)、打开(Open)和半开(Half-Open)三种状态。
- 配置灵活:可以通过配置文件设置熔断的阈值、超时时间等参数。
- 降级逻辑:支持自定义降级方法,当服务调用失败时,执行降级逻辑。
hystrix:command:default:circuitBreaker:# 默认情况下,熔断器在打开状态后会进入一个休眠窗口(Sleep Window),默认为 5 秒sleepWindowInMilliseconds: 10000 # 设置为 10 秒
@Service
public class OrderService {@HystrixCommand(fallbackMethod = "handleFallback")public boolean purchaseOrder(String productId) {// 查询库存Integer stock = inventoryService.getStock(productId);if (stock < 1) {// 库存不足,调用支付服务return paymentService.payOrder(productId);}return true;}private boolean handleFallback(String productId) {// 处理降级逻辑,如返回错误信息或调用备用接口return false;}
}
2. Sentinel
Sentinel 是阿里巴巴开源的分布式系统的流量控制和熔断框架,支持动态规则配置和实时监控。
关键特性:
- 动态规则:支持通过配置文件或动态规则引擎设置熔断规则。
- 与 Spring Cloud 集成:可以与 Spring Cloud 的 Feign、Ribbon 等组件无缝集成。
sentinel:transport:localhost: 8719rules:- rule: "com.example.service.UserService.getUserInfo.*, limitAppQPS=1,limitCount=3,limitStrategy=1,resourceName=user-service,resourceType=spring-cloud,operationId=getUserInfo"enable: true
@FeignClient(name = "EUREKA-CLIENT")
public interface EurekaClientService {@GetMapping("/info")String getInfo();
}@Service
public class UserService {@Autowiredprivate EurekaClientService eurekaClientService;@GetMapping("/user/{id}/info")@SentinelResource(value = "getUserInfo", blockHandler = "handleException")public User getUserInfo(@PathVariable("id") Long id) {// 业务逻辑String info = eurekaClientService.getInfo();return new User(id, info);}private User handleException(Long id, Throwable e) {// 处理异常,例如返回默认值return new User(id, "服务不可用");}
}
2. 降级
降级机制是当服务出现异常或超时时,系统提供的一种备用方案,确保系统的核心功能尽可能可用。
1. 工作原理
当服务调用失败、超时或触发熔断时,执行预先定义的降级逻辑。常见的降级方式包括:
- 静态降级:返回固定的默认值或提示信息。
- 缓存降级:返回缓存中的数据。
- 备用逻辑:调用备用服务或功能。
2. 使用场景
- 非核心功能:如推荐系统、评论系统等,通过降级保证主业务流程不受影响。
- 资源有限:当系统资源不足时,对某些业务进行降级以节省资源。
- 系统升级:在系统升级过程中,部分服务可能暂时不可用,通过降级返回默认值。
3. 实现方式
- Spring Cloud Feign:通过**@FeignClient注解**实现服务降级。
@FeignClient(name = "user-service", fallback = UserServiceFallback.class)
public interface UserService {@GetMapping("/users/{id}")User getUserById(@PathVariable("id") Long id);
}@Component
public class UserServiceFallback implements UserService {@Overridepublic User getUserById(Long id) {return new User(id, "Default User", "N/A");}
}
- 全局异常处理:通过Spring的全局异常处理机制实现统一的降级逻辑。
3. 限流
1. 概念
API 网关作为所有请求的入口,请求量大,我们可以通过对并发访问的请求进行限速来保护系统的可用性。
2. 常见限流算法
1. 漏桶算法
1. 概念
水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率
2. 核心思想
可见这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。
3. 不足
因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流量突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。

4. 算法描述
-
一个固定容量的漏桶,按照常量固定速率流出水滴;
-
如果桶是空的,则不需流出水滴;
-
可以以任意速率流入水滴到漏桶;
-
如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
2. 令牌桶算法
1. 概念
系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10ms)往桶里加入Token,如果桶已经满了就不再加了。新请求来临时,会各自拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务。
2. 核心思想
令牌桶的核心是可以预先在令牌桶中存储一些Token,这样当流量激增的时候,可以并发处理这一批请求,而且一旦需要提高速率,则按需提高放入桶中的令牌的速率.

3. 算法描述
-
假设限制2r/s,则按照500毫秒的固定速率往桶中添加令牌;
-
桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝;
-
当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上;
-
如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
3. 令牌桶和漏桶对比
-
令牌桶是按照固定速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数减为零时则拒绝新的请求;
-
漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入的请求数累积到漏桶容量时,则新流入的请求被拒绝;
-
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌),并允许一定程度突发流量;
-
漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次又是2),从而平滑突发流入速率;
-
令牌桶允许一定程度的突发,而漏桶主要目的是平滑流入速率;
-
两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
3. 基于Redis 令牌桶算法实现限流
Spring Cloud Gateway 提供了 RedisRateLimiter,这是一个基于 Redis 的令牌桶算法实现,用于在分布式环境中对微服务进行限流保护
1. 实现原理
RedisRateLimiter 使用 Redis 的原子操作(如 Lua 脚本)来实现令牌桶算法。其核心逻辑如下:
- 令牌生成:以固定速率向令牌桶中添加令牌。
- 令牌消费:每个请求到达时,尝试从令牌桶中获取令牌。
- 状态存储:使用 Redis 存储令牌桶的状态(当前令牌数量、上次更新时间等)。
- 原子操作:通过 Lua 脚本确保令牌的生成和消费操作是原子性的,避免并发问题
2. 操作步骤
1. 引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
2. 配置KeyResolver-指定限流的 Key
import org.springframework.cloud.gateway.filter.ratelimit.KeyResolver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import reactor.core.publisher.Mono;/*** 限流配置KeyResolver——有三种写法(接口限流/ip限流/用户限流)*/
@Configuration
public class RateLimiteConfig {/*** 接口限流:根据请求路径限流* 如果不使用@Primary注解,会报错* @return*/@Bean@Primarypublic KeyResolver pathKeyResolver() {return exchange -> Mono.just(exchange.getRequest().getPath().toString());}/*** 根据请求IP限流* @return*/@Beanpublic KeyResolver ipKeyResolver() {return exchange -> Mono.just(exchange.getRequest().getRemoteAddress().getHostName());}/*** 根据请求参数中的userId进行限流* 请求地址写法:http://localhost:8801/rate/123?userId=lisi* @return*/@Beanpublic KeyResolver userKeyResolver() {return exchange -> Mono.just(exchange.getRequest().getQueryParams().getFirst("userId"));}
}
3. 配置限流的过滤器信息
1. filter 名称必须是 RequestRateLimiter。
2. redis-rate-limiter.replenishRate:表示每秒向令牌桶中补充的令牌数量。
3. redis-rate-limiter.burstCapacity:令牌桶的容量,允许在 1s 内完成的最大请求数。
4. key-resolver:使用 SpEL 按名称引用 bean。
spring:cloud:gateway:routes:- id: rate-limit-demouri: lb://mima-cloud-producerpredicates:#访问路径:http://localhost:8801/rate/123- Path=/rate/**filters:- name: RequestRateLimiterargs:# 表示每秒向令牌桶中补充的令牌数量redis-rate-limiter.replenishRate: 10# 令牌桶的最大容量,允许在1s内完成的最大请求数。redis-rate-limiter.burstCapacity: 20# 使用SpEL表达式从Spring容器中获取Bean对象, 查看RateLimiteConfig实现类中的方法名key-resolver: "#{@pathKeyResolver}"#key-resolver: "#{@ipKeyResolver}"#key-resolver: "#{@userKeyResolver}"
4. 测试结果
多次调用请求,控制台打印结果
[开始]请求路径:/rate/123
[应答]请求路径:/rate/123耗时:2ms
2024-09-08 16:23:27.253 DEBUG 18512 --- [ioEventLoop-4-1] o.s.w.s.adapter.HttpWebHandlerAdapter : [62eb90e0] Completed 429 TOO_MANY_REQUESTS
2024-09-08 16:23:27.394 DEBUG 18512 --- [ctor-http-nio-2] o.s.w.s.adapter.HttpWebHandlerAdapter : [62eb90e0] HTTP GET "/rate/123"
corsFilter... run
[开始]请求路径:/rate/123
[应答]请求路径:/rate/123耗时:2ms
2024-09-08 16:23:27.397 DEBUG 18512 --- [ioEventLoop-4-1] o.s.w.s.adapter.HttpWebHandlerAdapter : [62eb90e0] Completed 429 TOO_MANY_REQUESTS
2024-09-08 16:23:27.536 DEBUG 18512 --- [ctor-http-nio-2] o.s.w.s.adapter.HttpWebHandlerAdapter : [62eb90e0] HTTP GET "/rate/123"
corsFilter... run
5. Redis存储内容
当发生限流时,会向redis中存储两个数据127.0.0.1:6379> keys *1) "request_rate_limiter.{localhost}.timestamp"2) "request_rate_limiter.{localhost}.tokens"大括号中就是我们的限流 Key,这里是 IP,本地的就是 localhost。timestamp:存储的是当前时间的秒数,也就是 System.currentTimeMillis()/1000 或者 Instant.now().getEpochSecond()。tokens:存储的是当前这秒钟对应的可用令牌数量。
4. Sentinel 限流
1. 概念
Sentinel 是阿里巴巴开源的一款用于微服务流量控制的框架,主要用于分布式系统的流量控制、熔断降级、系统负载保护等功能。
2. 应用场景
- 流量控制:限制请求的并发量或 QPS,防止系统过载。
- 熔断降级:当服务调用失败次数达到阈值时,自动熔断,避免故障蔓延。
- 系统负载保护:监控系统资源(如 CPU、内存、线程池等),动态调整流量,防止资源过载。
- 热点参数限流:对热门资源(如热门商品、用户 ID 等)进行限流。
- 实时监控与报警:提供丰富的监控面板和实时报警功能。
3. 实现原理
- 流量统计:使用滑动时间窗口算法统计请求量,避免固定窗口的突变问题。
- 规则引擎:通过预设规则(如限流规则、熔断规则等),结合实时统计信息对流量进行控制。
- 动态规则配置:支持通过 API 或数据源动态修改规则,支持拉模式(客户端定期拉取)和推模式(配置中心推送)。
- 资源定义:通过编程方式或注解标记需要保护的资源。
4. 滑动窗口限流算法
- 滑动窗口限流算法的核心思想是将一个较大的时间窗口划分为多个小的时间区间,每个区间维护独立的请求计数器。
- 随着时间的推移,窗口会逐步滑动,丢弃最早的时间区间,并添加新的区间.
例如,假设限流窗口为1秒,划分为10个100毫秒的小区间,每秒允许的最大请求数为100。当窗口内的总请求数达到100时,后续请求将被拒绝,直到窗口滑动[2]。
优点
- 更平滑的限流效果:避免了固定窗口算法在时间边界处流量突增的问题[3]。
- 适应性强:能够更好地应对流量的波动[5]。
- 灵活性高:可以通过调整窗口大小和区间数量来优化限流策略[6]。
5. 实现方式
- 编程方式:使用 Sentinel 提供的 API(如 SphU.entry)定义资源并进行流量控制。
- 注解方式:通过注解(如 @SentinelResource)快速定义资源。
- 配置文件:通过 YAML 或 Properties 文件配置规则。
- 动态数据源:集成配置中心(如 Nacos、Zookeeper)动态更新规则。
- 监控与可视化:通过 Sentinel Dashboard 实现实时监控和规则管理。
6. 代码示例
- 引入 Sentinel 依赖
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId><version>版本号</version> <!-- 替换为你的 Spring Cloud Alibaba 版本 -->
</dependency>
- 定义资源并配置限流规则-通过注解
1. 定义资源
使用 @SentinelResource 注解标记需要限流的方法。
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class MyController {@GetMapping("/test")@SentinelResource(value = "myResource", blockHandler = "handleBlock")public String test() {return "Request passed";}// 处理被限流的请求public String handleBlock(BlockException e) {return "Request blocked";}
}
2. 配置 QPS 限流规则
# 配置 QPS 限流规则
sentinel.flow.rule.resource=myResource
sentinel.flow.rule.count=100
sentinel.flow.rule.grade=1
7. Sentinel 实现集群限流
主要通过集群限流客户端和服务端的协同工作来完成,以下是具体实现方法:
1.集群限流的基本原理
Sentinel通过一个独立的集群限流服务端(Token Service)来集中管理集群的流量控制。当请求到达某个服务节点时,该节点会向集群限流服务端请求令牌(Token)。服务端根据全局流量规则判断是否发放令牌,从而实现对整个集群流量的精确控制。
2.配置集群限流服务端
集群限流服务端需要独立部署,主要负责接收客户端的令牌请求,并根据全局规则进行流量控制。服务端的实现依赖于sentinel-cluster-server-default模块。
3.配置集群限流客户端
在需要限流的微服务中,需要配置为集群限流客户端,并与服务端进行通信。具体步骤如下:
- 添加依赖
在微服务项目的pom.xml文件中添加sentinel-cluster-client-default依赖:
<dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-cluster-client-default</artifactId><version>${version}</version>
</dependency>
- 设置客户端身份和配置
通过代码设置当前节点为集群限流客户端,并配置客户端参数:
@SpringBootApplication
public class WebMvcDemoApplication {static {// 指定当前身份为 Token ClientClusterStateManager.applyState(ClusterStateManager.CLUSTER_CLIENT);// 配置集群限流客户端参数ClusterClientConfig clientConfig = new ClusterClientConfig();clientConfig.setRequestTimeout(1000);ClusterClientConfigManager.applyNewConfig(clientConfig);}
}
- 连接集群限流服务端
配置集群限流服务端的地址和端口:
@SpringBootApplication
public class WebMvcDemoApplication {static {ClusterClientAssignConfig assignConfig = new ClusterClientAssignConfig();assignConfig.setServerHost("127.0.0.1");assignConfig.setServerPort(11111);// 设置命名空间ConfigSupplierRegistry.setNamespaceSupplier(() -> "serviceA");// 应用配置,触发客户端连接服务端ClusterClientConfigManager.applyNewAssignConfig(assignConfig);}
}
-
配置限流规则
集群限流规则可以通过 Sentinel 控制台进行配置。在控制台中,需要将规则的clusterMode设置为集群模式,并指定全局流量阈值。当客户端请求令牌时,服务端会根据这些规则进行流量判断。 -
集群限流的优势
与单机限流相比,集群限流可以精确控制整个集群的流量,避免因流量不均匀导致部分节点提前限流。例如,假设集群有 3 个节点,单机限流阈值为 200 QPS,则理想情况下集群阈值为 600 QPS。但在实际场景中,某个节点可能提前达到 200 QPS 并开始限流,而其他节点可能只有 100 QPS,导致集群整体流量未充分利用。集群限流则可以避免这种情况,确保整个集群的流量达到阈值后再进行限流。
通过以上配置,Sentinel 可以实现对分布式集群的精确流量控制,适用于高并发场景下的流量管理。
四. API网关
五. 分布式配置中心
1. 概念
配置中心用于集中管理和存储应用程序的配置信息。它允许开发人员和运维人员在运行时动态地修改应用程序的配置,而无需重新部署或重启应用。
2. 主要功能包括:
- 集中管理配置:将所有服务的配置信息集中存储在一个地方,便于统一管理和维护。
- 动态更新:支持配置信息的动态更新,当配置发生变化时,能够实时通知相关服务。
- 版本控制:提供配置的历史版本管理,便于追踪和回滚。
- 环境隔离:支持不同环境(如开发、测试、生产)的配置隔离。
- 权限管理:提供细粒度的权限控制,确保只有授权用户可以修改配置。
- 灰度发布:支持配置的灰度发布,逐步推广新配置。
3. 常见的配置中心
1. Spring Cloud Config
- 特点:与Spring Boot和Spring Cloud集成良好,支持从本地文件系统、Git仓库或SVN仓库中读取配置信息。
- 适用场景:适用于基于Spring Cloud构建的微服务架构。
2. Nacos
- 特点:阿里巴巴开源的动态服务发现、配置管理和服务管理平台,支持多种数据格式(如JSON、YAML、Properties),提供强大的配置管理和服务发现功能。
- 适用场景:适用于需要统一解决服务发现、配置管理和动态路由等问题的场景。
3. Apollo
- 特点:携程开源的分布式配置中心,支持多环境配置管理,提供详细的权限控制和审计日志,支持客户端缓存和热更新。
- 适用场景:适用于大型分布式系统,特别是需要高可用和高性能的场景。
4. ZooKeeper
- 特点:分布式协调工具,支持树状结构存储配置信息,通过监听机制实现配置的动态更新。
- 适用场景:适用于对配置一致性要求较高的场景。
4.Nacos配置中心的实现原理
- 配置存储:配置信息以键值对形式存储在 Nacos Server 中,支持分组(Group)和命名空间(Namespace)。
- 动态更新:当配置发生变化时,Nacos 会通过监听机制通知订阅了该配置的服务实例,服务可以实时更新配置,无需重启。
- 配置加载:应用通过集成 nacos-config-spring-boot-starter,在启动时从 Nacos Server 加载配置,并通过注解(如 @NacosValue)注入配置值。
六. 链路追踪
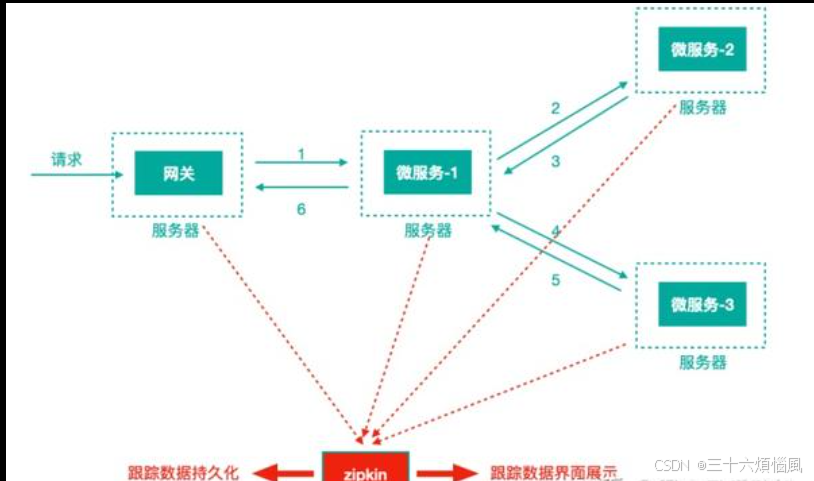
1. 概念
- 在微服务架构中,系统被拆分为多个独立的服务,每个服务都有独立的日志记录机制。
- 一个请求可能需要经过多个服务的处理。如果没有有效的链路追踪机制,很难确定请求的具体执行路径,进而难以定位问题
2. 作用
- 追踪请求路径:记录请求在各个服务中的流转路径,包括调用顺序、处理时间和异常信息。
- 性能分析:通过监控每个服务的响应时间,找到导致延迟的服务,从而优化性能。
- 故障排查:在服务请求失败或延迟时,快速定位到具体的服务,减少排查时间。
- 服务依赖分析:了解各个服务间的依赖关系,有助于优化服务部署和扩展性规划
3. 链路追踪方案
1. Spring Cloud Sleuth + Zipkin
- Spring Cloud Sleuth 是 Spring Cloud 生态中用于分布式链路追踪的核心组件,能够为每个请求生成唯一的 Trace ID 和 Span ID,并在日志中自动注入这些信息。
- Zipkin 是一个轻量级的分布式追踪系统,支持可视化界面,方便开发者分析和诊断系统问题。
- 集成方式:通过在项目中引入 spring-cloud-starter-sleuth 和 spring-cloud-starter-zipkin,可以轻松实现链路追踪。
- 适用场景:适合中小规模的 Spring Cloud 项目,尤其是对集成度和易用性要求较高的场景。
2. SkyWalking
- SkyWalking 是一个开源的分布式追踪系统,支持多种语言和框架,提供丰富的可视化功能。
- 它不仅支持链路追踪,还提供服务依赖分析、性能监控等高级功能。
- 适用场景:适合大型分布式系统,尤其是需要高性能和复杂功能支持的场景。
3. OpenTelemetry
- OpenTelemetry 是一个统一的分布式追踪和指标采集标准,支持多种语言和框架。
- 它提供了灵活的扩展性和与其他工具(如 Jaeger、Zipkin)的兼容性。
- 适用场景:适合需要与其他平台或语言进行互操作,且希望遵循标准化的场景。
七. 服务间通信机制
1.分布式事务
1.概念
分布式事务是指在分布式系统环境下,一组操作要么全部成功,要么全部失败,涉及多个独立的服务或数据库实例。它需要通过网络远程协作完成事务操作,确保数据的一致性和完整性。
2.特点
-
强一致性:某些分布式事务解决方案(如2PC、3PC)可以保证数据的强一致性。
-
最终一致性:某些方案(如基于消息队列的异步处理)允许系统在一段时间后达到一致状态。
-
性能开销:分布式事务通常会引入额外的性能开销,尤其是在高并发场景下。
-
复杂性:实现分布式事务需要考虑网络故障、服务失败等多种因素。
3. 应用场景
-
微服务架构:多个服务通过远程调用协作完成业务逻辑,如订单服务和库存服务的协同操作。
-
跨数据库实例:单体系统访问多个数据库实例时,需要保证数据一致性。
-
跨应用事务:多个应用之间需要同步更新数据。
4.实现原理
-
两阶段提交(2PC):分为准备阶段和提交阶段,协调者管理所有参与者的事务状态。
-
三阶段提交(3PC):在2PC基础上增加预表决阶段,减少阻塞。
-
TCC(Try-Confirm-Cancel):通过业务逻辑实现事务的预处理、确认和回滚。
-
基于消息的最终一致性:通过消息队列异步处理事务,避免同步阻塞。
-
Saga模式:将事务分解为多个本地事务,通过补偿事务处理失败。
5. 实现方式
• 两阶段提交(2PC):适用于对强一致性要求较高的场景,但性能较差。
• TCC模式:适用于高并发场景,但对业务逻辑有较强侵入性。
• 基于消息的最终一致性:适用于对实时性要求不高的场景,通过消息队列实现异步处理。
• Saga模式:适用于复杂的业务流程,通过编排或编排型实现。
• Seata框架:支持多种事务模式(如AT、TCC、Saga等),适用于微服务架构。
6.总结
分布式事务的实现方式和解决方案多种多样,选择时需根据具体业务需求、性能要求和一致性要求进行权衡。例如:
-
对强一致性要求高的场景可选择2PC或TCC。
-
对性能和可用性要求高的场景可选择基于消息的最终一致性或Saga模式。
-
微服务架构中可使用Seata框架统一管理分布式事务。
2.分布式事务解决方案-seata
1.Seata 的概念
Seata 是一个开源的分布式事务解决方案,旨在为微服务架构中的分布式事务提供统一的事务管理功能。它通过***全局事务(Global Transaction)和分支事务(Branch Transaction)***的概念,解决了跨服务和跨数据库的一致性问题。
2.Seata 的特点
-
多种事务模式:支持 AT(自动事务)、TCC(Try-Confirm-Cancel)、SAGA(长事务)、XA 等多种事务模式,满足不同业务场景的需求。
-
高性能:通过异步提交、批量处理等方式优化事务性能。
-
易于集成:与 Spring Boot 和 Spring Cloud 等微服务框架无缝集成。
-
高可用性:支持集群部署,防止单点故障。
3.Seata 的实现原理
Seata 的核心设计基于全局事务和分支事务的管理,通过事务管理器(TM)、资源管理器(RM)和事务协调器(TC)来实现。
-
全局事务(Global Transaction):由 TM 发起并控制,包含多个分支事务,最终决定提交或回滚。
-
分支事务(Branch Transaction):对应于具体操作(如数据库操作、远程服务调用等),由 RM 管理。
-
事务协调器(TC):负责协调全局事务的提交或回滚,管理事务状态。
-
资源管理器(RM):管理分支事务的执行,与本地资源(如数据库)交互。
4.事务回滚的实现
Seata 的事务回滚机制基于事务日志记录和补偿操作,确保数据的最终一致性。
1. 事务日志记录
在事务执行过程中,Seata 会记录事务的执行日志(如undo_log),包括操作前后的数据状态。
2. 回滚操作:
-
AT 模式:通过记录的事务日志生成回滚 SQL,将数据恢复到事务开始前的状态。
-
TCC 模式:在全局事务回滚时,调用分支事务的 Cancel 方法,释放资源并撤销操作。
-
SAGA 模式:通过补偿机制(Compensation)回滚已经执行成功的局部事务。
5.事务回滚的实现细节(以 AT 模式为例)
1.提交阶段:
业务操作成功时,Seata 自动提交事务。
2. 回滚阶段:
-
如果业务操作失败或全局事务需要回滚,Seata 根据事务日志中的“快照”生成回滚 SQL。
-
执行回滚 SQL,将数据恢复到事务开始前的状态。
6.总结
Seata 通过全局事务和分支事务的管理,结合事务日志记录和补偿机制,实现了分布式事务的一致性。它支持多种事务模式,易于集成,并且提供了高性能和高可用性,是微服务架构中分布式事务管理的优秀解决方案。