PostgreSQL性能飞跃指南:从慢查询到服务器配置的全栈优化实战
关键词: PostgreSQL性能优化、查询优化、数据库调优、执行计划、索引优化、服务器配置、EXPLAIN分析、数据库性能监控
摘要: 你的PostgreSQL查询慢得像蜗牛爬行?数据库服务器CPU飙升到100%?本文从一个电商网站的真实性能危机出发,用通俗易懂的语言和丰富的实战案例,带你掌握PostgreSQL性能调优的核心技巧。从慢查询分析到索引优化,从内存配置到连接池管理,让你的数据库性能提升10倍不是梦!
引言:当你的数据库"罢工"了
想象一下这个场景:周五晚上8点,你正准备下班,突然收到一连串的报警信息——网站响应超时、用户投诉无法下单、服务器CPU使用率飙升到100%。你打开数据库监控面板,发现PostgreSQL正在处理成千上万个缓慢的查询,就像一个过度劳累的工人,气喘吁吁却又不得不继续工作。
这种情况你是否遇到过?或者害怕遇到?
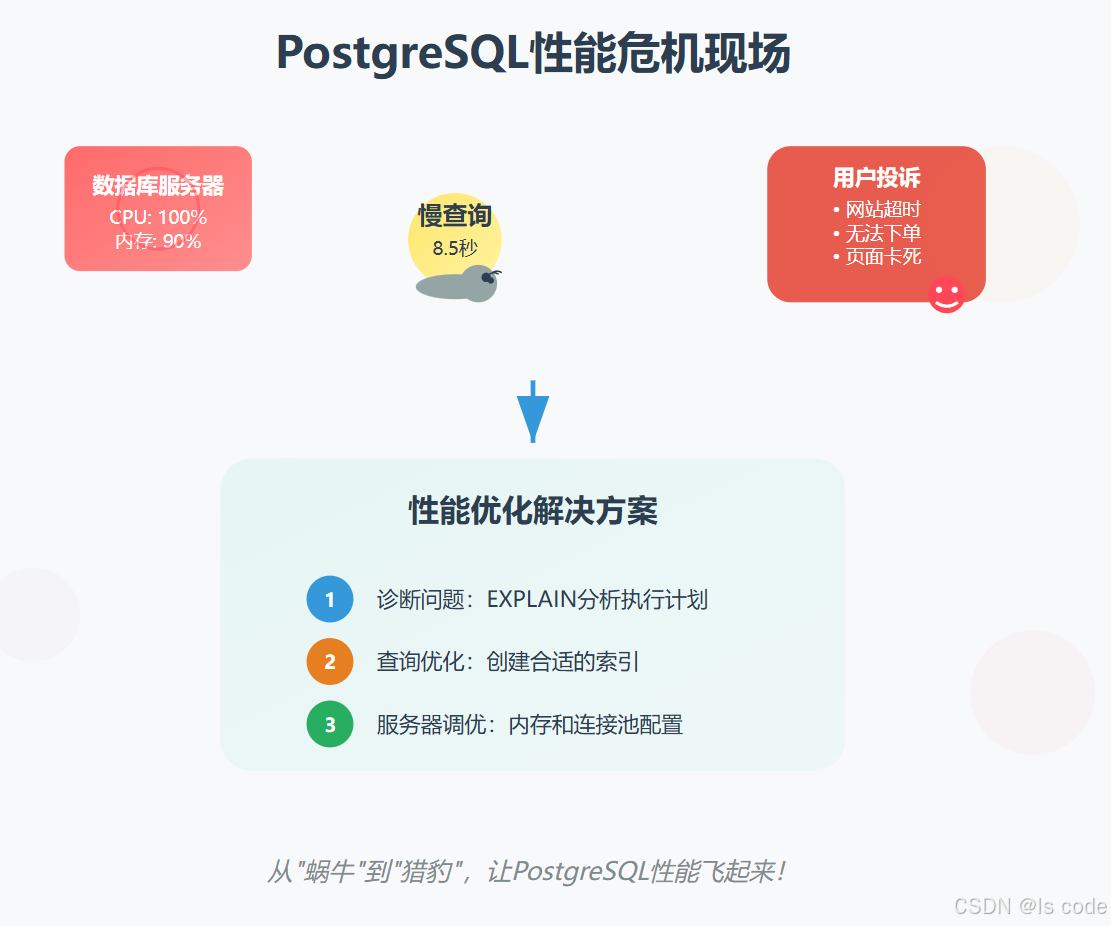
今天,我们就来解决这个让无数开发者头疼的问题:如何让PostgreSQL从"蜗牛"变成"猎豹"。
第一章:诊断问题——像医生一样"望闻问切"
1.1 性能问题的"症状"识别
就像医生看病要先观察症状一样,PostgreSQL性能优化的第一步是正确识别问题。
常见的"病症"包括:
- 查询响应时间超过预期(比如简单查询超过1秒)
- CPU使用率持续居高不下
- 内存使用量异常增长
- 磁盘I/O频繁
- 连接数接近上限
快速自检清单:
-- 查看当前活跃连接数
SELECT count(*) FROM pg_stat_activity WHERE state = 'active';-- 查看最耗时的查询
SELECT query, mean_exec_time, calls
FROM pg_stat_statements
ORDER BY mean_exec_time DESC
LIMIT 10;-- 查看数据库大小
SELECT pg_database.datname, pg_size_pretty(pg_database_size(pg_database.datname))
FROM pg_database;
1.2 EXPLAIN:你的"透视镜"
如果查询语句是一个黑盒子,那么EXPLAIN就是我们的"透视镜",它能让我们看清楚PostgreSQL内部是如何执行查询的。
基础用法:
-- 查看查询计划
EXPLAIN SELECT * FROM orders WHERE customer_id = 12345;-- 查看详细的执行统计
EXPLAIN (ANALYZE, BUFFERS)
SELECT o.order_id, c.customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.order_date >= '2024-01-01';
读懂执行计划的"密码":
- Seq Scan(全表扫描):像在图书馆里一本本翻找,效率很低
- Index Scan(索引扫描):像用图书馆的目录快速定位,效率很高
- Hash Join:像整理两堆扑克牌然后配对
- Nested Loop:像双重循环,数据量大时要小心

第二章:查询优化——让SQL跑得飞起来
2.1 索引策略:数据库的"高速公路"
索引就像高速公路,能让数据查询"一路绿灯"。但是,索引不是越多越好,就像城市不能到处都是高速公路一样。
索引设计的黄金法则:
-- 1. 为经常查询的列创建索引
CREATE INDEX idx_orders_customer_id ON orders(customer_id);-- 2. 复合索引要注意列的顺序
CREATE INDEX idx_orders_date_status ON orders(order_date, status);-- 3. 部分索引减少存储空间
CREATE INDEX idx_orders_recent ON orders(customer_id)
WHERE order_date >= '2024-01-01';-- 4. 表达式索引处理复杂查询
CREATE INDEX idx_customers_name_lower ON customers(lower(customer_name));
索引选择实战案例:
假设你有一个订单表,经常需要查询:
- 某个客户的所有订单
- 某个日期范围的订单
- 特定状态的订单
-- 错误的做法:为每个列单独创建索引
CREATE INDEX idx1 ON orders(customer_id);
CREATE INDEX idx2 ON orders(order_date);
CREATE INDEX idx3 ON orders(status);-- 正确的做法:根据查询模式创建复合索引
CREATE INDEX idx_orders_optimized ON orders(customer_id, order_date, status);
2.2 查询重写:让SQL更聪明
有时候,同样的需求可以用不同的SQL实现,性能却大相径庭。
优化前后对比:
-- 慢查询:使用子查询
SELECT * FROM products
WHERE category_id IN (SELECT category_id FROM categories WHERE category_name = 'Electronics'
);-- 快查询:使用JOIN
SELECT p.* FROM products p
JOIN categories c ON p.category_id = c.category_id
WHERE c.category_name = 'Electronics';-- 慢查询:使用DISTINCT
SELECT DISTINCT customer_id FROM orders WHERE order_date >= '2024-01-01';-- 快查询:使用EXISTS
SELECT customer_id FROM customers c
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id AND o.order_date >= '2024-01-01'
);
2.3 统计信息:让优化器更聪明
PostgreSQL的查询优化器就像一个导航系统,需要准确的"路况信息"才能选择最佳路线。这些"路况信息"就是统计信息。
-- 手动更新统计信息
ANALYZE orders;-- 查看表的统计信息
SELECT schemaname, tablename, last_analyze, last_autoanalyze
FROM pg_stat_user_tables
WHERE tablename = 'orders';-- 设置更频繁的自动分析
ALTER TABLE orders SET (autovacuum_analyze_scale_factor = 0.05);
第三章:服务器配置优化——硬件资源的艺术
3.1 内存配置:给PostgreSQL一个大脑
内存配置就像给大脑分配不同的区域处理不同的任务。
核心参数配置:
# 共享缓冲区(数据页缓存)
shared_buffers = 1GB # 建议为总内存的25%# 工作内存(单个查询使用)
work_mem = 64MB # 复杂查询的临时空间# 维护工作内存(索引创建、VACUUM等)
maintenance_work_mem = 256MB # 大型维护操作# 有效缓存大小(告诉优化器可用内存)
effective_cache_size = 3GB # 建议为总内存的75%
内存配置的经验法则:
- 4GB内存的服务器:shared_buffers=1GB, work_mem=32MB
- 8GB内存的服务器:shared_buffers=2GB, work_mem=64MB
- 16GB内存的服务器:shared_buffers=4GB, work_mem=128MB
3.2 连接池配置:避免"交通堵塞"
连接就像车道,太少会堵车,太多会浪费资源。
# 最大连接数
max_connections = 200# 连接超时设置
statement_timeout = 300s
idle_in_transaction_session_timeout = 600s# 使用连接池工具(如PgBouncer)
PgBouncer配置示例:
[databases]
myapp = host=localhost port=5432 dbname=myapp[pgbouncer]
pool_mode = transaction
max_client_conn = 1000
default_pool_size = 100
3.3 磁盘I/O优化:让数据读写更流畅
磁盘I/O就像数据的"高速公路收费站",优化得好可以大大减少等待时间。
# 检查点配置(数据持久化)
checkpoint_timeout = 15min
checkpoint_completion_target = 0.9
max_wal_size = 2GB# 随机页面成本(SSD建议调低)
random_page_cost = 1.1 # SSD: 1.1, HDD: 4.0# 日志配置
log_min_duration_statement = 1000 # 记录超过1秒的查询
log_checkpoints = on
log_lock_waits = on

第四章:监控与维护——持续健康检查
4.1 性能监控:你的"健康管家"
就像定期体检一样,数据库也需要持续监控。
关键监控指标:
-- 数据库活动监控
SELECT datname,numbackends as connections,xact_commit + xact_rollback as transactions,blks_read + blks_hit as total_reads,round(100.0 * blks_hit / (blks_hit + blks_read), 2) as cache_hit_ratio
FROM pg_stat_database
WHERE datname NOT IN ('template0', 'template1', 'postgres');-- 慢查询监控
SELECT query,calls,total_exec_time,mean_exec_time,rows
FROM pg_stat_statements
WHERE mean_exec_time > 1000 -- 超过1秒的查询
ORDER BY total_exec_time DESC
LIMIT 10;-- 锁等待监控
SELECT blocked_locks.pid AS blocked_pid,blocked_activity.usename AS blocked_user,blocking_locks.pid AS blocking_pid,blocking_activity.usename AS blocking_user,blocked_activity.query AS blocked_statement
FROM pg_catalog.pg_locks blocked_locks
JOIN pg_catalog.pg_stat_activity blocked_activity ON blocked_activity.pid = blocked_locks.pid
JOIN pg_catalog.pg_locks blocking_locks ON blocking_locks.locktype = blocked_locks.locktype
JOIN pg_catalog.pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid
WHERE NOT blocked_locks.granted;
4.2 定期维护:让数据库保持"青春"
-- 定期VACUUM清理死元组
VACUUM ANALYZE orders;-- 重建索引
REINDEX TABLE orders;-- 检查表膨胀
SELECT schemaname, tablename,n_dead_tup,n_live_tup,round(100 * n_dead_tup / (n_live_tup + n_dead_tup), 2) as dead_ratio
FROM pg_stat_user_tables
WHERE n_dead_tup > 0
ORDER BY dead_ratio DESC;
第五章:实战案例——电商网站的性能救援
让我们回到开头的场景:一个电商网站的性能危机。
问题描述:
- 订单查询页面加载超过10秒
- 数据库CPU使用率90%+
- 用户投诉无法正常下单
诊断过程:
-- 1. 发现问题查询
EXPLAIN (ANALYZE, BUFFERS)
SELECT o.*, c.customer_name, p.product_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2024-01-01'
ORDER BY o.order_date DESC;-- 执行时间:8.5秒,全表扫描!
解决方案:
-- 1. 创建复合索引
CREATE INDEX idx_orders_date_customer ON orders(order_date, customer_id);
CREATE INDEX idx_order_items_order_product ON order_items(order_id, product_id);-- 2. 优化查询(分页查询)
SELECT o.*, c.customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.order_date >= '2024-01-01'
ORDER BY o.order_date DESC
LIMIT 20 OFFSET 0;-- 3. 调整服务器配置
shared_buffers = 2GB
work_mem = 128MB
effective_cache_size = 6GB
结果:
- 查询时间从8.5秒降低到0.2秒
- CPU使用率从90%降低到30%
- 用户体验显著改善
总结:性能优化的"武功秘籍"
PostgreSQL性能优化就像练武功,需要内功(服务器配置)和招式(查询优化)相结合:
🏆 性能优化检查清单
查询层面:
- ✅ 使用EXPLAIN分析执行计划
- ✅ 为高频查询列创建合适索引
- ✅ 避免不必要的全表扫描
- ✅ 优化JOIN顺序和条件
- ✅ 使用适当的数据类型
服务器层面:
- ✅ 合理配置shared_buffers
- ✅ 调整work_mem大小
- ✅ 使用连接池管理连接
- ✅ 定期VACUUM和ANALYZE
- ✅ 监控关键性能指标
运维层面:
- ✅ 建立性能监控体系
- ✅ 设置慢查询日志
- ✅ 定期性能评估和优化
- ✅ 制定容量规划和扩展策略
🚀 下一步行动
- 立即行动:检查你当前最慢的查询,用EXPLAIN分析执行计划
- 短期目标:建立基础的性能监控体系
- 长期规划:制定数据库性能优化的标准流程
记住,性能优化不是一次性的工作,而是一个持续改进的过程。就像保持身体健康需要坚持锻炼一样,数据库性能也需要我们持续关注和优化。
最后的建议: 在生产环境进行任何优化之前,请务必在测试环境验证效果,并做好数据备份。毕竟,“欲速则不达”,稳妥的优化才是王道!
参考资源
📚 官方文档
- PostgreSQL官方性能调优指南
- PostgreSQL配置参数参考
🛠️ 推荐工具
- pg_stat_statements:查询性能统计
- PgBouncer:连接池管理
- pgAdmin:数据库管理界面
- Grafana + Prometheus:性能监控可视化
📖 延伸阅读
- 《PostgreSQL即学即用》- 深入理解PostgreSQL架构
- 《高性能PostgreSQL实战》- 企业级优化实践
- PostgreSQL Wiki - 社区最佳实践分享