关于deepseek的系列模型,断断续续也看了相关paper,之前也做了部分记录但是一直没发出来,最近打算梳理下deepseek的系列模型,有个系统性的认识,后续可能再补个千问系列,部分细节持续更新~
Deepseek相关模型
DeepSeek 从 2024 年 01 月到 2025 年 01 月发布了一系列模型,其中最主要的就是语言系列模型,这个文档中我们会对语言模型涉及的关键技术进行具体介绍:
- 语言模型:DeepSeek V1、MoE、V2、V3。
- 多模态模型:DeepSeek VL-1、VL-2、Janus。
- 数学、代码、Reasoning 模型:DeepSeek Math、Coder、Coder-V2、R1。

DeepSeek V1
paper原文:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
贡献点:
- 首先考察了批大小和学习率的规模法则,并发现了它们与模型大小的趋势。
- 对数据和模型规模的缩放规律进行了全面研究,成功揭示了最佳模型/数据缩放分配策略,并预测了我们大规模模型的预期性能。
- 从不同数据集推导出的缩放规律存在显著差异。这表明数据集的选择对缩放行为有显著影响,因此在跨数据集运用scaling law时有一些注意点。
效果:
- DeepSeek LLM 在各种基准测试中超越了 LLaMA-2 70B,特别是在代码、数学和推理领域。
- SFT 和 DPO 之后,DeepSeek 67B chat model在中文和英文开放式评估中都优于 GPT-3.5。这突出了 DeepSeek 67B 在生成高质量回复和进行有意义的对话方面的优越性能,涵盖了英文和中文两种语言。
小编说:从V1在代码、数学和推理上的效果就比较好,这可能也是deepseek后面陆续Deepseek-math、deepseek-R1推理领域等系列大招的基础,加强优势在很多时候比比补齐短板可能更有力量,尤其是对新的创业公司来说。扯远了~
7B 和 13B Base model,都是在 2 T Token 上预训练,然后经过 SFT(1M) + DPO 获得 Chat model。
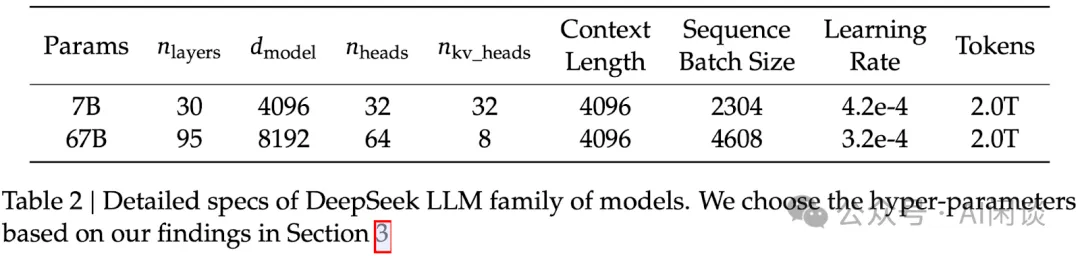
- 只在 67B 的大模型采用 GQA,7B 模型依然采用 MHA。
- ROPE
- SwiGLU
- RMSNorm
- 词表采用Byte-level Byte-Pair Encoding (BBPE),采用了预分词来防止不同字符类别,将数字拆分为单个数字。常规标记数设置为 100000,分词器在约 24 GB 的多语言语料库上进行了训练,我们用 15 个特殊标记扩充了最终的词汇表总数达到 100015,为未来可能需要的任何额外特殊标记保留空间,最终词汇表大小配置为 102400。
- 采用 FlashAttention V1。
- 对于 LayerNorm、GEMM 和 Adam 更新等操作采用 Layer/OP 融合,以加速训练。
预训练
数据处理:
- 去重:通过采样唯一实例确保数据的多样化表示;重复数据会导致模型过度拟合局部模式,增加生成时的重复概率,显著影响PPL
- 过滤:增强了信息的密度;
- 再混合:解决数据不平衡问题,专注于增加代表性不足领域,确保多样化的观点和信息
采用了 Multi-Step Learning Rate 调度策略(80%+10%+10%):学习率在 2000 个预热步骤后达到最大值,然后在对 80%的训练 token 进行处理后降低到最大值的 31.6%。之后在处理 90%的 token 后进一步降低到最大值的 10%。训练阶段的梯度裁剪设置为 1.0,多步学习率效果与 Cosine Learning Rate Decay 相近。当在保持模型大小不变的情况下调整训练规模时,好处是比较容易从第一个 Stage 的 Checkpoint 进行 Continuous Training。
其他技术点包括:
- 使用HAI-LLM框架,分布式策略:ZeRO-1 DP + PP(1F1B)。
- bf16 精度下训练模型,但在 fp32 精度下累积梯度,在 Cross-Entropy CUDA Kernel 中实时将 BF16 的 Logits 转为 FP32,而不是提前在 HBM 中转换。
- 每 5 分钟异步保存一次 Checkpoint,以便浪费进度不超过 5 分钟;并定时删除过早 Checkpoint,以避免占据太多空间。
- 生成任务推理阶段采用vLLM,非生成任务continuous batching
- 以前的scaling law: 模型规模N,数据规模 D,计算预算C可以近似为6ND。本文:Non-embedding FLOPs/token为M的话,C = MD
GQA
Grouped-Query Attention (GQA) 是对 Multi-Head Attention (MHA) 和 Multi-Query Attention (MQA) 的扩展。通过提供计算效率和模型表达能力之间的灵活权衡,实现了查询头的分组。GQA将查询头分成了G个组,每个组共享一个公共的键(K)和值(V)投影。
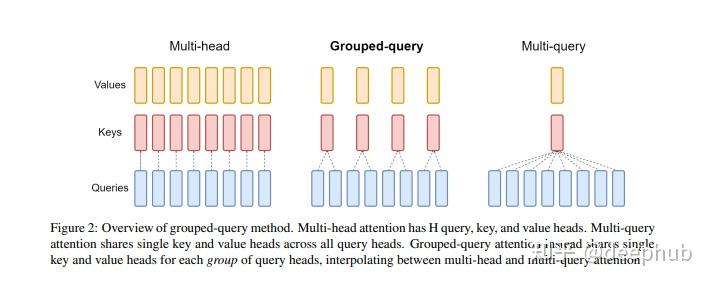
GQA是最佳性能(MQA)和最佳模型质量(MHA)之间的一个很好的权衡。
下图显示,使用GQA,可以获得与MHA几乎相同的模型质量,同时将处理时间提高3倍,达到MQA的性能。这对于高负载系统来说可能是必不可少的。
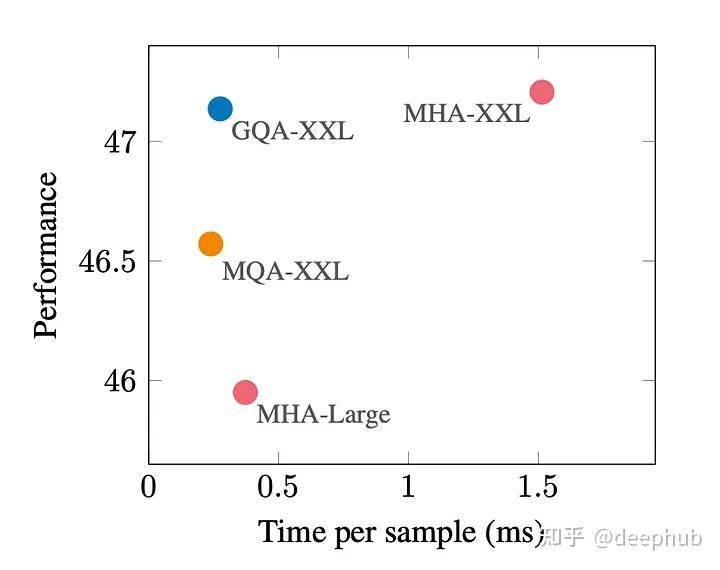
使用G个组可以减少存储每个头的键和值所需的内存开销,特别是在具有大的上下文窗口或批次大小的情况下。GQA提供了对模型质量和效率的细致控制。
FlashAttention
AdamW
后训练
采用标准的 SFT + DPO 标准流程。
- 150 万个英中文指令数据实例,涵盖了helpfulness and harmlessness topics。helpful Data数据包含 120 万个实例,其中 31.2%用于普通任务,46.6%用于数学问题,22.2%用于coding。安全数据包含30万,涵盖了各种敏感主题。
SFT+DPO:
| 模型大小 | SFT阶段epoch | SFT阶段lr | DPO阶段lr | DPO阶段batch size |
|---|---|---|---|---|
| 7B | 4 epoch | 1e-5 | 5e-6 | 512 |
| 67B | 2epoch | 5e-6 | 5e-6 | 512 |
- 67B训练epoch数少是因为 67B 模型的过拟合问题比较严重。
- 3868 Chinese and English数据量上观察重复字符导致的停不下来的比例,随着数学 SFT 数据的数量增加,重复率上升,可能是因为数学 SFT 数据偶尔包含相似的推理模式,较弱的模型难以掌握这种推理模式,导致重复响应,因此采用了两阶段的SFT+DPO训练,在保持基准分数并显著减少重复。
- DPO阶段学习率warm up和cosine learning rate scheduler
- DPO可以增强模型的开放式生成能力,同时在标准基准测试中的性能差异不大。
评估
评估数据:
- Multi-subject multiple-choice: MMLU、C-Eval、CMMLU
- Language understanding and reasoning: HellaSwag、PIQA、ARC、OpenBookQA、BigBench Hard
- Closed-book question answering: TriviaQA、NaturalQuestions
- Reading comprehension: RACE、DROP、C3
- Reference disambiguation: WinoGrande、CLUEWSC
- Language modeling: Pile
- Chinese understanding and culture: CHID、CCPM
- Math: GSM8K、MATH、CMath
- Code: HumanEval、MBPP
- Standardized exams: AGIEval
评估方式:
采用perplexity-based evaluation来评估多选任务数据集,计算每个选项的困惑度,并选择最低的那个作为模型的预测。
- 对ARC和OpenBookQA使用无条件归一化(unconditional normalization)计算困惑度。
- 对于TriviaQA、NaturalQuestions、DROP、MATH、GSM8K、HumanEval、MBPP、BBH、AGIEval、CLUEWSC 和 CMath 采用基于生成的评估,这里的基于生成的评估是指让模型生成自由文本并从生成的文本中解析结果,并使用greedy贪婪解码。
关于无条件归一化的困惑度

Benchmark评估
Base model效果与分析
- DeepSeek模型双语一共2T,LLaMA2英文2TB,但是v1在英文任务上comparable,在中文和推理、数学等任务上碾压。
- 随着模型规模的扩大,GSM8K 和 BBH等任务表现得到了明显提升。由于使用相同的数据集训练了 7B 和 67B 模型,这种改进可以归因于大型模型的强大少样本学习能力。然而,随着数学数据比例的增加,小模型和大模型之间的差距可能会缩小。
- DeepSeek 67B 相对于 LLaMA2 70B 的优势大于 DeepSeek 7B 相对于 LLaMA2 7B 的优势。这种现象突显了语言冲突对较小模型的影响更大。尽管 LLaMA2 没有在中文数据上进行专门训练,但在某些中文任务(如 CMath)上表现出色。这表明某些基本能力(如数学推理)可以有效地跨语言迁移。然而,像 CHID 这样需要评估中文成语用法的任务,要求模型在预训练期间消耗大量中文 token。在这种情况下,LLaMA2 与 DeepSeek LLM 相比表现显著较差。
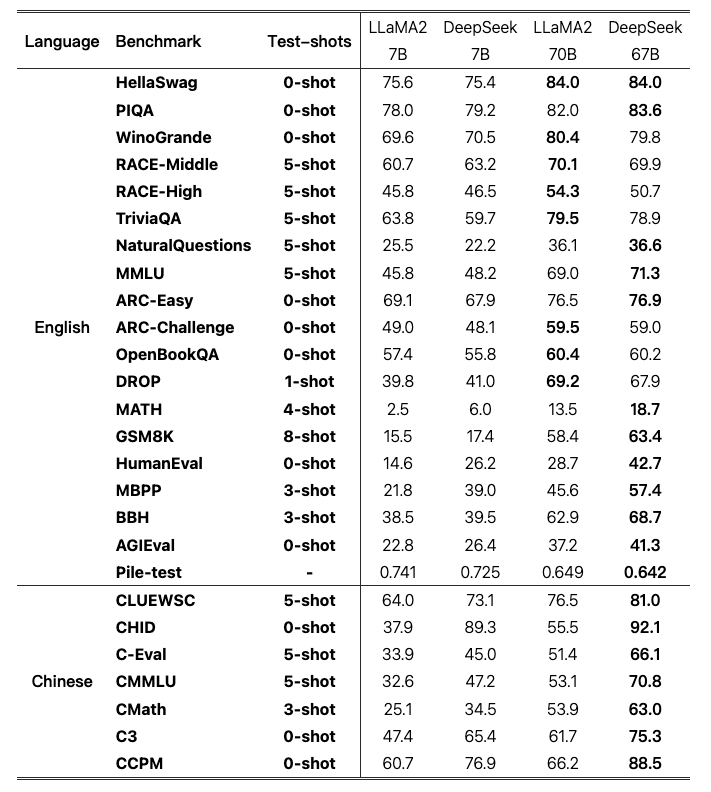
Chat Model效果和分析
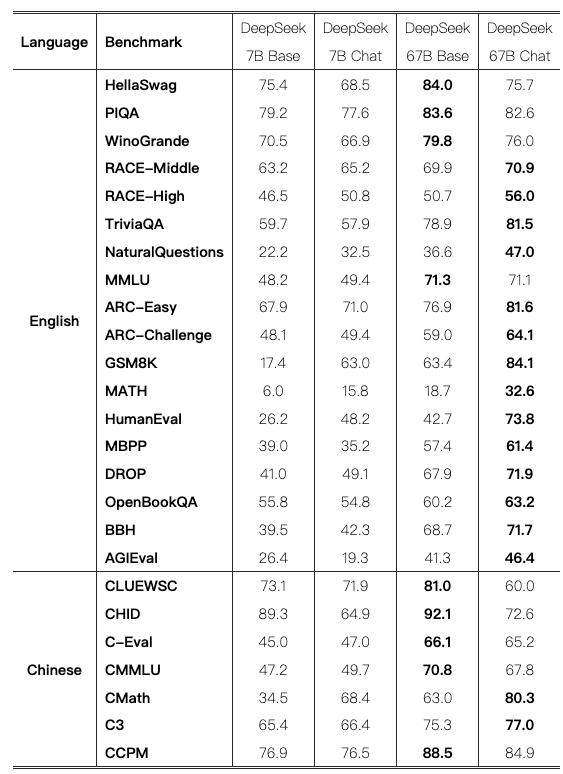
使用 0-shot 评估聊天模型在 MMLU、GSM8K、MATH、C-Eval 和 CMMLU 上的表现,而基础模型的结果仍然在 few-shot 设置下获得。
- 在大多数任务中经过调整后的整体改进。然而,在某些情况下,某些任务的性能有所下降。
- Knowledge: Base model和Chat model 在知识相关任务(如 TriviaQA、MMLU 和 C-Eval)中的表现存在波动。然而,并不认为这种轻微的波动表明在 SFT(监督微调)后知识的获取或丧失。SFT 的价值在于其能够学习在聊天模型的零样本设置中达到与基础模型在少样本设置中相当的成绩,这与实际场景相符。
- Reasoning:Chat model 在推理任务(如 BBH、Natural Questions)中表现出提升。然而,我们认为 SFT 阶段并没有学习推理能力,而是学习了推理路径的正确格式。
- Performance Drop Tasks:少数任务的性能始终下降。这些特定任务通常涉及完形填空任务或句子补全任务,例如 HellaSwag,可以认为纯语言模型更适合处理此类任务。
- Math and Code:微调后,在数学和编码任务上表现出显著改进。HumanEval 和 GSM8K 得分提高了 20 分以上。推测是,基础模型最初对这些任务欠拟合,而 SFT 阶段通过大量的 SFT 数据学习了额外的编码和数学知识。然而,模型的能力可能主要集中在对代码补全和代数问题的处理上。为了全面理解数学和编码,在预训练阶段整合多样化的数据至关重要,作为后续工作TODO。
- 微调策略:
- 7B模型:首先使用所有数据对模型进行微调。然后第二阶段排除了数学和代码数据。动机:第一阶段模型的重复率(温度设为0)为 2.0%。在第二阶段微调后降低到 1.4%,同时保持了基准分数,二阶段专注于使用对话数据进行微调,从而解决重复率问题。从后面的实验结果中可以看到,二阶段并未损害模型在代码和数学方面的能力,同时减少了重复行为并提升了指令遵循能力。
- 67B模型:第一阶段微调后的重复率已经低于 1%,而第二阶段反而导致模型在基准上的分数变差,因此,对于 67B 模型只进行了一个阶段的 SFT。
Open-Ended Evaluation
中文
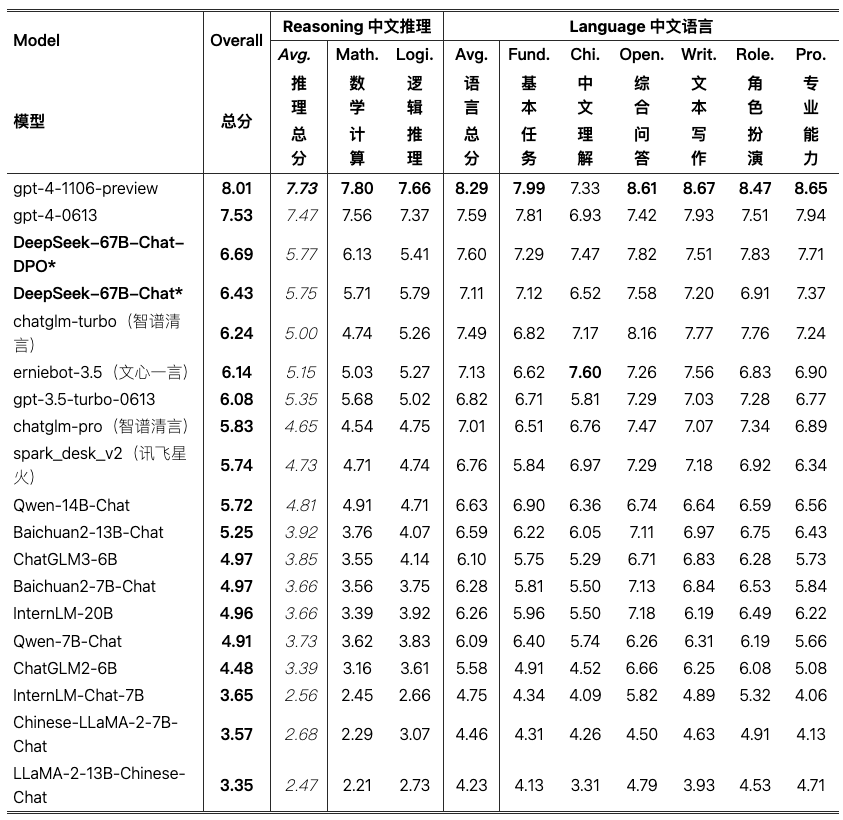
上述为AlignBench中文上的效果,有一说一,从这上面看那个时候的V1模型其实就崭露头角了,其他几个中文闭源模型应该都是几百B的模型。模型在更复杂的中文逻辑推理和数学计算方面表现更优。
AlignBench 总共包括 8 个主要类别、36 个次要类别,涵盖了 683 个问题。对于每个问题,除了提示,AlignBench 还提供了专业参考答案和用于 GPT-4 评价回答质量的评分模板。
英文
使用 MT-Bench 基准,该基准包含 8 种不同类别的多轮问题,DeepSeek LLM 67B Chat DPO 进一步将平均分数提升至第 1 名,仅次于 GPT-4(OpenAI,2023 年)。这些结果表明 DeepSeek LLM 具有强大的多轮开放式生成能力。
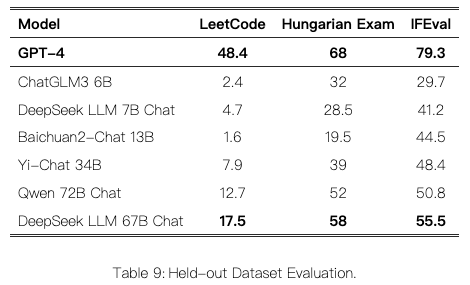
Held-Out Evaluation
数据污染和基准过度拟合是评估 LLMs 的两个挑战。一种常见的做法是利用最近发布的测试集来评估模型作为持出测试集。
LeetCode: 我们使用了 LeetCode 周赛(2023 年 7 月至 11 月的周赛 351-372 和双周赛 108-117)中的问题。我们通过爬取 LeetCode 数据来获取这些问题,其中包含 126 个问题,每个问题有超过 20 个测试用例。采用的评估指标类似于 HumanEval。在这方面,如果模型的输出成功通过所有测试用例,则认为模型有效地解决了该问题。
另外在Hungarian National High-School Exam和Instruction Following Evaluation任务上都进行了评估。
其他讨论
关于Multi-Choice Question
额外加入 2000 万 MC(多项选择)数据已被证明不仅有利于中文多项选择基准测试,也有助于提升英文基准测试。这表明模型解决 MC 问题的能力得到了增强。然而,这种改进并未扩展到其他非多项选择格式的评估上,例如 TriviaQA 和内部中文 QA 测试集上,这些是生成式评估基准。这表明用户可能并未感觉到模型在对话交互中变得更智能,因为这些交互涉及生成响应而非解决多项选择问题。因此选择在预训练和微调阶段都排除 MC 数据,因为包含它会导致过度拟合基准测试,并且不会有助于模型实现真正的智能。
关于预训练中的指令数据
普遍认为,在预训练的后期阶段加入指令数据能够提升基础模型在基准任务上的表现。
在预训练的最后 10%阶段整合了 500 万条指令数据,这些数据主要是选择题。我们观察到基础模型在基准任务上的表现确实有所提升。然而,最终结果几乎与在 SFT 阶段加入相同数据时取得的结果相同。
得出结论,虽然这种方法能够提升基础模型在基准任务上的表现,但其整体潜力与不加入这些指令数据时相当。如果指令数据规模较大,将其加入预训练过程是可以接受的。由于我们倾向于排除选择题,且拥有的非选择题数据有限,我们决定不在预训练过程中加入指令数据。
关于System Prompt
略微修改了 LLaMA-2 引入的提示作为系统提示。
You are DeepSeek Chat, a helpful, respectful and honest AI assistant developed by DeepSeek. The knowledge cut-off date for your training data is up to May 2023. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don’t know the answer to a question, please don’t share false information.
引入系统提示时,7B LLM 的性能会略有下降。然而,在使用 67B LLM 时,添加提示显著提升了结果。
解释是,较大的模型能更好地理解系统提示背后的意图,从而更有效地遵循指令并生成更优质的响应。另一方面,较小的模型难以充分理解系统提示,而训练与测试之间的不一致性可能会对其性能产生负面影响。




![c++流之sstream/堆or优先队列的应用[1]](https://i-blog.csdnimg.cn/direct/0195bda68fa64396a7715bc5735974d8.png)