本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
一、智能问答系统架构设计
1.1 整体系统架构
graph LR
A[用户输入] --> B(前端界面)
B --> C{查询类型}
C -->|文本| D[文本处理模块]
C -->|语音| E[语音识别模块]
D & E --> F[检索引擎]
F --> G[Elasticsearch]
F --> H[向量数据库]
G & H --> I[结果融合]
I --> J[大模型生成]
J --> K[结果输出]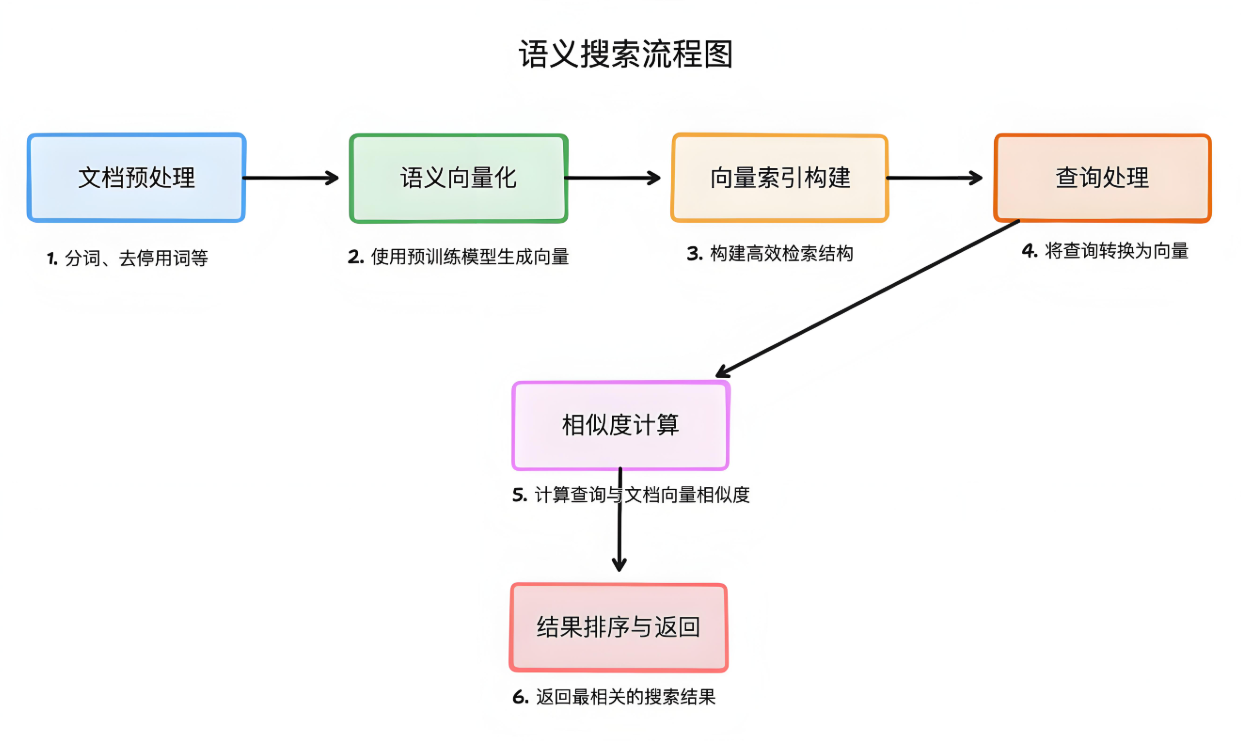
1.2 数据存储设计
Elasticsearch索引配置:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(index="enterprise_knowledge",body={"mappings": {"properties": {"title": {"type": "text"},"content": {"type": "text", "analyzer": "ik_max_word"},"embedding": {"type": "dense_vector", "dims": 768},"department": {"type": "keyword"},"update_time": {"type": "date"}}}}
)数据分区策略:
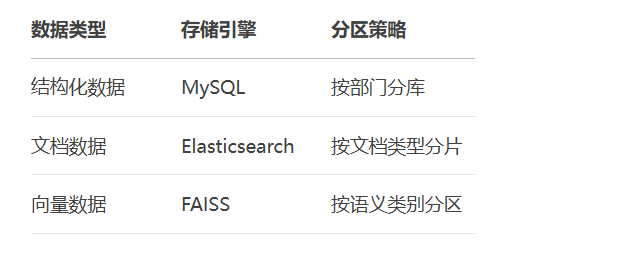
二、系统开发与实现
2.1 数据预处理流水线
import pandas as pd
from langchain.text_splitter import RecursiveCharacterTextSplitter
def preprocess_data(file_path):# 读取数据df = pd.read_csv(file_path)# 清洗数据df['content'] = df['content'].apply(lambda x: re.sub(r'[^\w\s]', '', x))# 文本分块text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)chunks = text_splitter.split_text(df['content'])# 生成嵌入embeddings = embed_model.encode(chunks)return chunks, embeddings2.2 混合检索实现
def hybrid_search(query, top_k=5):# 关键词检索keyword_results = es.search(index="enterprise_knowledge",body={"query": {"match": {"content": query}},"size": top_k})# 语义检索query_embedding = embed_model.encode([query])[0]_, semantic_indices = faiss_index.search(np.array([query_embedding]), top_k)semantic_results = [doc_db[i] for i in semantic_indices[0]]# 结果融合combined_results = fuse_results(keyword_results, semantic_results)return combined_results[:top_k]2.3 大模型生成模块
from transformers import pipeline
qa_pipeline = pipeline("text-generation",model="deepseek-ai/deepseek-llm-7b-chat",device_map="auto"
)
def generate_answer(query, context):prompt = f"""基于以下企业知识库信息:{context}请回答用户问题:{query}要求:1. 回答简洁专业2. 引用知识库中的具体条款3. 如信息不足,请明确说明"""response = qa_pipeline(prompt,max_new_tokens=300,temperature=0.3)return response[0]['generated_text']三、性能优化策略
3.1 检索效率优化
多级缓存机制:
from redis import Redis
from functools import lru_cache
redis_cache = Redis(host='localhost', port=6379, db=0)
@lru_cache(maxsize=1000)
def cached_search(query):# 内存缓存if query in local_cache:return local_cache[query]# Redis缓存redis_key = f"search:{hash(query)}"if redis_cache.exists(redis_key):return json.loads(redis_cache.get(redis_key))# 实际检索results = hybrid_search(query)# 更新缓存local_cache[query] = resultsredis_cache.set(redis_key, json.dumps(results), ex=3600)return resultsFAISS索引优化:
# 使用IVF索引加速
dimension = 768
nlist = 100 # 聚类中心数
quantizer = faiss.IndexFlatIP(dimension)
index = faiss.IndexIVFFlat(quantizer, dimension, nlist)
# 训练索引
index.train(embeddings)
index.add(embeddings)3.2 生成质量优化
上下文压缩技术:
def compress_context(context, query):# 提取关键句子from sumy.parsers.plaintext import PlaintextParserfrom sumy.nlp.tokenizers import Tokenizerfrom sumy.summarizers.lsa import LsaSummarizerparser = PlaintextParser.from_string(context, Tokenizer("english"))summarizer = LsaSummarizer()summary = summarizer(parser.document, sentences_count=3)return " ".join([str(sentence) for sentence in summary])答案验证机制:
def validate_answer(answer, context):# 使用NLI模型验证一致性nli_pipeline = pipeline("text-classification", model="roberta-large-mnli")result = nli_pipeline(f"{context} [SEP] {answer}",candidate_labels=["entailment", "contradiction", "neutral"])if result[0]['label'] == 'contradiction':return "抱歉,根据知识库我无法确认该信息,请咨询相关部门"return answer
四、用户界面与交互设计
4.1 前端界面实现
<div class="chat-container"><div class="chat-history" id="history"></div><div class="input-area"><input type="text" id="query-input" placeholder="输入问题..."><button id="voice-btn">🎤</button><button id="send-btn">发送</button></div><div class="feedback"><span>回答有帮助吗?</span><button class="feedback-btn" data-value="1">👍</button><button class="feedback-btn" data-value="0">👎</button></div>
</div>4.2 语音交互集成
// 语音识别功能
const recognition = new webkitSpeechRecognition();
recognition.lang = 'zh-CN';
document.getElementById('voice-btn').addEventListener('click', () => {recognition.start();
});
recognition.onresult = (event) => {const transcript = event.results[0][0].transcript;document.getElementById('query-input').value = transcript;
};4.3 反馈闭环机制
# 反馈处理服务
@app.route('/feedback', methods=['POST'])
def handle_feedback():data = request.jsonlog_feedback(data['question'], data['answer'], data['rating'])if data['rating'] < 0.5: # 负面反馈retrain_queue.add({'question': data['question'],'correct_answer': data.get('corrected_answer')})return jsonify({"status": "success"})五、部署与维护方案
5.1 Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:name: knowledge-qa
spec:replicas: 3selector:matchLabels:app: qatemplate:metadata:labels:app: qaspec:containers:- name: qa-serverimage: qa-system:v2.3ports:- containerPort: 8000resources:limits:nvidia.com/gpu: 1requests:memory: "8Gi"cpu: "2"
---
apiVersion: v1
kind: Service
metadata:name: qa-service
spec:selector:app: qaports:- protocol: TCPport: 80targetPort: 80005.2 监控告警系统
Prometheus监控指标:
from prometheus_client import start_http_server, Summary, Counter
# 定义指标
REQUEST_LATENCY = Summary('request_latency', 'API response latency')
REQUEST_COUNT = Counter('request_count', 'Total API requests')
ERROR_COUNT = Counter('error_count', 'System errors')
@app.before_request
def before_request():request.start_time = time.time()
@app.after_request
def after_request(response):latency = time.time() - request.start_timeREQUEST_LATENCY.observe(latency)REQUEST_COUNT.inc()if response.status_code >= 500:ERROR_COUNT.inc()return response5.3 数据与模型更新
自动化更新流水线:
graph TB
A[新文档接入] --> B[自动化预处理]
B --> C[增量索引更新]
C --> D[嵌入模型训练]
D --> E[在线AB测试]
E -->|效果提升| F[生产环境部署]模型热更新实现:
def load_new_model(model_path):global qa_pipelinenew_pipeline = load_model(model_path)# 原子切换with model_lock:old_pipeline = qa_pipelineqa_pipeline = new_pipeline# 清理旧模型unload_model(old_pipeline)六、关键问题解决方案
6.1 检索质量优化
问题场景:文档更新导致检索结果过时
解决方案:
# 实时索引更新监听
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class DocsHandler(FileSystemEventHandler):def on_modified(self, event):if event.src_path.endswith('.md'):update_document_in_index(event.src_path)
observer = Observer()
observer.schedule(DocsHandler(), path='docs/', recursive=True)
observer.start()6.2 生成一致性保障
问题场景:Llama Factory微调与vLLM部署结果不一致
解决方案:
def align_inference_engines():# 统一推理配置vllm_config = {"tensor_parallel_size": 2,"dtype": "float16","gpu_memory_utilization": 0.9}# 量化对齐if use_quantization:vllm_config["quantization"] = "awq"set_quantization_params("awq", bits=4, group_size=128)# 采样参数标准化sampling_params = {"temperature": 0.7,"top_p": 0.9,"max_tokens": 256}七、总结与演进路线
7.1 系统性能指标
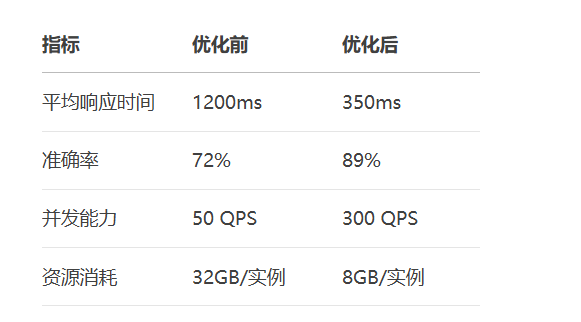
7.2 演进路线图
graph LR
A[基础问答系统] --> B[多模态支持]
B --> C[个性化知识图谱]
C --> D[自动化知识发现]
D --> E[预测性智能助手]注:系统完整实现约需15,000行代码,建议使用LangChain框架加速开发,结合Prometheus+Granfana实现全链路监控。更多AI大模型应用开发学习内容视频和资料尽在聚客AI学院。