📝本篇摘要
- 在本篇将介绍C++定长内存池的概念及实现问题,引入内存池技术,通过实现一个简单的定长内存池部分,体会奥妙所在,进而为之后实现整体的内存池做铺垫!


🏠欢迎拜访🏠:
点击进入博主主页
📌本篇主题📌:定长内存池实现
📅制作日期📅: 2025.06.03
🧭隶属专栏🧭:点击进入所属C++高并发内存池项目专栏
一· 📖高并发内存池概述

- ⾼并发的内存池,他的原型是google的⼀个开源项⽬
tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了⾼效的多线程内存管理,⽤于替代系统的内存分配相关的函数(malloc、free)。
二· 🚀什么是内存池?
🛠️池化技术
-
所谓“池化技术”,就是程序先向系统申请过量的资源,然后⾃⼰管理,
以备不时之需。 -
也就是
提前申请好对应的大内存,以防止每次申请开销过大,导致程序运行效率过慢的问题。 -
“池的分类”:
内存池,连接池,线程池,对象池等。 -
以服务器上的线程池为例,它的主要思想是:先启动若⼲数量的线程,让它们处于睡眠状态,当接收到客⼾端的请求时,唤醒池中某个睡眠的线程,让它来处理客⼾端的请求,当处理完这个请求,线程⼜进⼊睡眠状态。
☀️内存池☀️
-
内存池是指程序预先从操作系统申请⼀块⾜够⼤内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,⽽是直接从内存池中获取。 -
同理,当程序
释放内存的时候,并不真正将内存返回给操作系统,⽽是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。
💡内存池用来解决的问题
- 解决
效率问题以及内存碎片问题。
🚀何为内存碎片
-
内存碎⽚分为
外碎⽚和内碎⽚。 -
外部碎⽚是⼀些空闲的连续内存区域太⼩,这些内存空间不连续,以⾄于合计的内存⾜够,但是不能满⾜⼀些的内存分配申请需求。
如图:
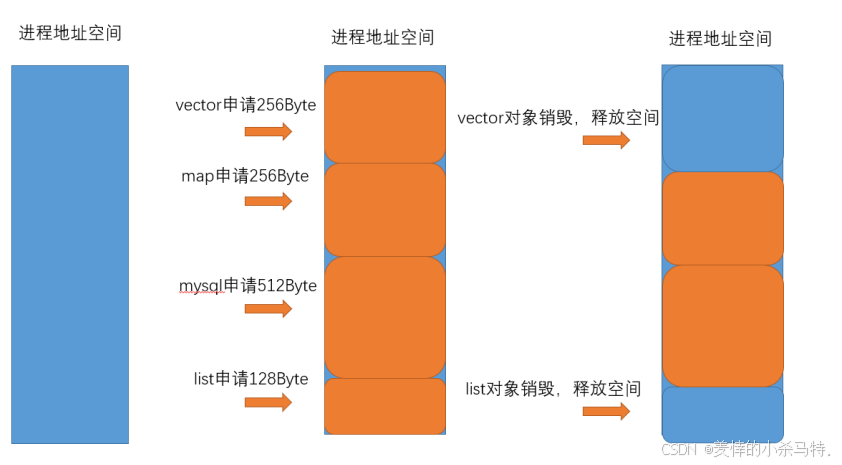
此时,由于
vector和list对象销毁释放的空间不连续,如果来了个更大的对象(虽然有384字节空间,但是申请超过256字节的对象就无法申请了,就是因为这俩块碎片化导致不连续了),那么此时这段空间就无法被正常分配,就是有外部碎片导致!
内部碎⽚是由于⼀些对⻬的需求,导致分配出去的空间中⼀些内存⽆法被利⽤。
🚀 再识malloc
- C/C++中我们要动态申请内存都是通过
malloc去申请内存,但是我们要知道,实际我们不是直接去堆获取内存不是直接去堆获取内存的。
这里可以把malloc理解成一个内存池:
malloc()相当于向操作系统“批发”了⼀块较⼤的内存空间,然后“零售”给程序⽤。当全部“售完”或程序有⼤量的内存需求时,再根据实际需求向操作系统“进货”。
- 对于
malloc实现,不同平台底层实现方法不一样:windows的vs中用的微软自己实现的,linux的gcc⽤的glibc中的ptmalloc。
三· 定长内存池
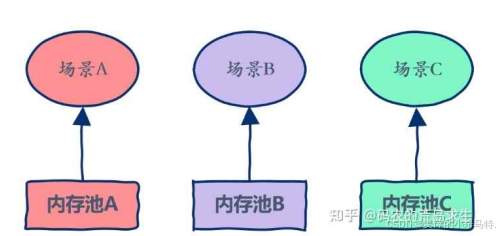
💡何为定长内存池
- 简单理解成就是每次申请的一个对象的长度都是固定的,一种类型的定长内存池只能一直
申请一种类型的对象。
如图:
而我们之前的常使用的malloc是这样的:
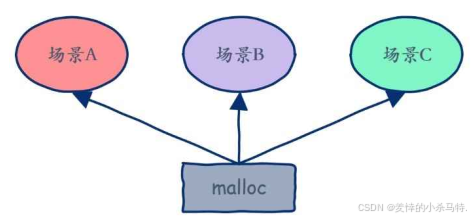
通过对比我们可以发现正是因为一种类型定长内存池只能申请一种类型的对象空间,这就给了这种申请方式很多优点:
-
比如解决了外部碎片问题:因为
定长内存池每次申请释放都是指定相同类型对象大小,而每次申请也是相同对象大小,故外部碎片可以重新被利用。 -
其次就是不用了的空间放在
freelist链表(指定类型对象大小的整数倍)中,等到需要的时候可以及时被利用,就不用再次申请空间,进而导致效率底下问题了。
定长内存池设计
📧设计思路
-
提供
New与Delete接口来代替C++库中的new与delete,即采取底层模拟调用new与delete的底层来实现简单版本的接口。 -
首先对于变量设计的有三个:
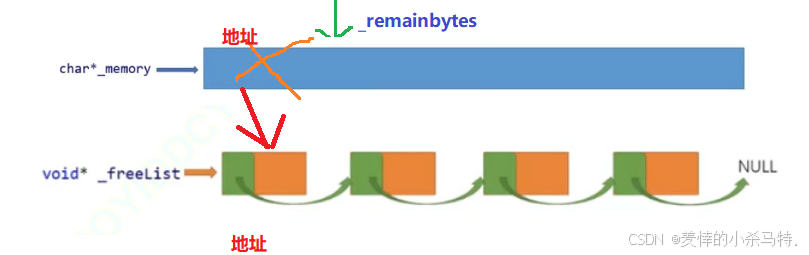
memory(大块未利用的内存首部的指针),remainbytes(大块内存剩余字节数),freelist(被回收的T对象内存块的地址链表)。
🎨对于memory:

这也就是我们malloc出的大块的定长内存块,每次从这里面取T对象大小的块,或者从freelist里面取曾经被释放的接着利用。
🎨对于freelist:

这里我们想要被回收的内存块(也就是首地址)能及时被找到然后再次利用,因此采取把对应回收内存块的首地址用链表形式管理起来;也就是每个内存块里面前4/8个字节保存一下下一个内存块的首地址,这样就连接起来了。
🎨对于remainbytes:

这里就不用多说了,就是大块内存剩余的空间,如果不足了对应一个T对象大小了,就在开一块大的定长内存块,等到原先这块有新的内存块被释放在用这块(也就是freelist里的内存块),随着T对象大小内存块不断增多,就形成了管理多个大块定长内存块,分部分使用的模式。
形象理解一下这个过程:
但是实际并不是这样的:
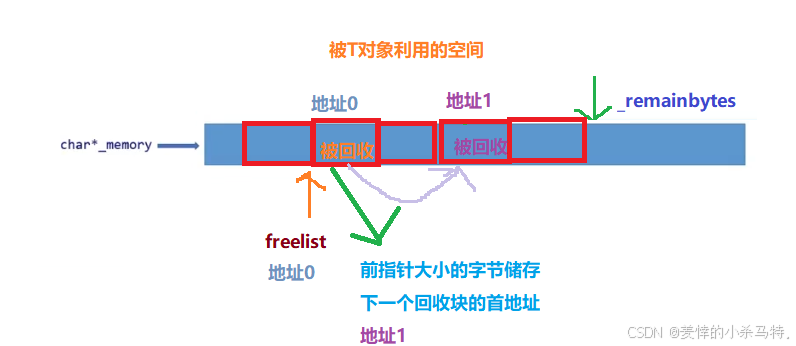
整体都是在这一个开辟的定长内存块上操作的,只不过,我们把它拆开当成链表来理解这个大内存块以及回收的块比较好理解而已。
🛠️Delete接口设计
这里我们只需要把对应的回收的块的地址链表形式保存即可,但是有个问题,就是不同平台地址大小是不同的,有种简单的方式就是进行判断:
//直接判断,进行放入:
if (sizeof(T*) == 4) *(int*)obj = (int)_freelist;
else *(long long*)obj =(long long) _freelist;
_freelist = obj;
当然了这种是比较漏的,下面我们可以利用不同平台指针大小随它自己变化的特点也就是取前指针大小字节进行直接赋值,无需强转的:
*(void**)obj = _freelist;
_freelist = obj;
这里不一定只能是void ** 类型,int ** 等都是可以的,因为它们对应解引用得到的一级指针大小都是对应平台指针大小,也就是说是可以自己适应的。
🛠️Delete 代码:
void Delete(T*obj) {//这里把回收的内存块的首地址保存以链表的形式串起来(每个地址都是拿到一个T类型大小对象)obj->~T();//显示调用析构//下面两种方法进行(因为不同平台下地址大小是不同的,简单的就是直接判断然后强转放入,另一种就是利用不同平台下指针大小随平台变化来存入)://直接判断,进行放入://if (sizeof(T*) == 4) *(int*)obj = (int)_freelist;//else *(long long*)obj =(long long) _freelist;//32为平台一级地址就是4字节,64位就是8字节,二级指针解引用对应的空间放一级指针大小就是对应字节了!*(void**)obj = _freelist;_freelist = obj;
}
🛠️New接口设计
思路:
-
首先先去对应的
freelist里面看看是否有空余的内存块(因为每次只有被释放掉才会用它连接起来,因此只要不为空一定够一个对象大小的)。 -
其次,再去对应的大块内存块是否
remainbytes还够用,如果不够用就新开辟大的定长内存块用,否则就直接用,然后调节对应的memory指针位置以及remainbytes大小即可。 -
但是还有个问题:如果申请的T对象是类似
char,short等少于四个字节呢,那么如果释放后把它挂入freelist里,不就取不到对应的空间来放地址了,因此我们最少也要New对应平台下指针大小空间。
//如果T对象不足对应的平台下的地址的大小,那么后面在内存块中取前4/8个字节的时候就出错了,因此如果不够最小也要满足这个条件size_t objsize = sizeof(T) < sizeof(T*) ? sizeof(T*) : sizeof(T);
- 还有就是:我们模拟的是
new的底层,因此还会需要显示调用定位new初始化一下:
//显示调用T对象的默认构造函数:
new(obj)T();
- 还有个小坑:当写
New的时候,无脑的选择了如果remainbytes不够了,直接VirtualFree,没考虑第一次memory为nullptr就直接释放了的情况,正是因为这个bug,导致了还没申请即崩了,其次就是注意malloc申请的采用free,VirtualAlloc申请的用VirtualFree,因此需要注意!!!
if (!_memory)VirtualFree(_memory, 0, MEM_RELEASE); //这里第一次不能VirtualFree,否则非法访问,释放后面不足T对象大小的空间
🛠️New代码:
下面就写成了这样:
T* New() {//这里如果freelist里面不为空也就是有被回收的内存,那么再次利用的话,拿到对应的地址所对应的连续的内存块一定是>=//一个T对象内存的(指定类型对象大小的整数倍)!T* obj = nullptr;//回收的内存的链表如果有内存先利用:if (_freelist) {void* next = *((void**)_freelist);obj = (T*)_freelist;_freelist = next;}else {//判断是否大块内存中还足够一个T对象大小:if (_remainbytes >= sizeof(T)) {//后面直接用memory即可!}//不足就重新申请:else {if (!_memory)VirtualFree(_memory, 0, MEM_RELEASE); //这里第一次不能VirtualFree,否则非法访问,释放后面不足T对象大小的空间size_t allocbytes = 128 * 1024;char* ptr = (char*)malloc(allocbytes);//直接字节申请if (!ptr) {throw std::bad_alloc();}_memory = ptr; _remainbytes = allocbytes;}obj = (T*)_memory;//如果T对象不足对应的平台下的地址的大小,那么后面在内存块中取前4/8个字节的时候就出错了,因此如果不够最小也要满足这个条件size_t objsize = sizeof(T) < sizeof(T*) ? sizeof(T*) : sizeof(T);_memory += objsize;//这里必须是char*;如果是void*++后就不知道加几个_remainbytes -= objsize;}//显示调用T对象的默认构造函数:new(obj)T();return obj;}
✅ 优化按页申请内存
- 对于使用的64位机器默认一页就是
4KB,我们只需要修改下,每次都按照页交给对应的alloc函数然后自己转化成字节进行申请即可(这里我们按一页8KB算,与后面PageCache的一页8KB相照应)。
下面需要用到一个函数VirtualAlloc(也就是对应windows来说malloc底层调用的函数):
VirtualAlloc是Windows操作系统提供的一个内存管理函数,它允许程序以页面为单位来保留、提交、更改或释放虚拟内存区域。这个函数对于需要精细控制其内存使用的应用程序特别有用。
LPVOID VirtualAlloc(LPVOID lpAddress,SIZE_T dwSize,DWORD flAllocationType,DWORD flProtect
);
📖参数介绍:
1· lpAddress: 指向希望分配的内存区域起始地址的指针。如果此值NULL,操作系统将自动选择一个合适的地址。
2· dwSize: 要分配的内存大小,以字节为单位。
3·flAllocationType: 分配类型标志,可以是以下值之一或组合:
MEM_COMMIT: 为特定的页面区域分配实际物理存储器,并将其标记为可用。MEM_RESERVE: 保留一个区域以备将来使用,但不会分配任何物理存储。MEM_RESET: 表示将要废弃的内容,操作系统可能会丢弃这些内容但不会立即执行此操作。
其他如 MEM_LARGE_PAGES, MEM_PHYSICAL 等高级选项也可能适用。
4· flProtect: 内存保护选项,在内存被提交时生效。常见的选项包括:
PAGE_READONLY: 只读访问。PAGE_READWRITE: 读写访问。PAGE_EXECUTE: 执行访问。PAGE_EXECUTE_READ: 执行和读取访问。PAGE_EXECUTE_READWRITE: 执行、读取和写入访问。
成功时返回分配区域的起始地址;失败时返回 NULL 并可通过 GetLastError 获取详细错误信息。
上面了解下即可,我们就下面修改下按照这个函数申请大块定长内存即可。
#define _Win32#ifdef _Win32
#include<windows.h>
#else
//...
#endifstatic inline void* SystemAlloc(size_t page) {void* ptr = nullptr;
#ifdef _Win32//按页申请一页8KB 对应页数*2^13ptr = VirtualAlloc(0,page << 13, MEM_COMMIT |MEM_RESERVE, PAGE_READWRITE);
#else//linux的brk mmap申请
#endifif (!ptr) throw std::bad_alloc(); return ptr;
}
New按照页申请内存:
size_t page = allocbytes >> 13;
char* ptr = (char*)SystemAlloc(page);//按页申请,malloc底层所调用的!
当然了,对应Linux,它底层malloc实现是调用是brk或者mmap等:
这里我们还是以windows的VirtualAlloc来使用,过多了解可查询资料,AI辅助等。
🛠️析构设计
- 对于
动态开辟的空间需要显示析构释放,Delete函数只是情况了对应T类型对象的一些资源,然而对应空间并没用彻底归还系统,因此搞出显示析构(注意开辟与销毁的接口匹配问题!):
//这里由于申请了空间需要手动写析构:~objectpool() {//注意VirtualAlloc申请的空间要用对应的VirtualFree释放:// // 释放 _freelist 中的所有节点while (_freelist) {void* next = *(void**)_freelist;VirtualFree(_memory, 0, MEM_RELEASE); // 使用 free 释放_freelist = next;}//如果对应的当前剩余的大内存块还有空间也要释放掉:if (!_memory)VirtualFree(_memory,0, MEM_RELEASE);}
📊 定长内存池测试
- 下面我们测试下它的
freelist不为空是否能正常使用,T对象不足地址大小是否会过多申请,remainbytes不足是开辟空间是否正确等:
void test_char() {objectpool<char> op;char *pa = op.New();op.Delete(pa);char* pb = op.New(); op.Delete(pb);
}

- 该机器是64位故指针大小是8字节。

- 发现不足指针大小字节直接按照指针大小申请。
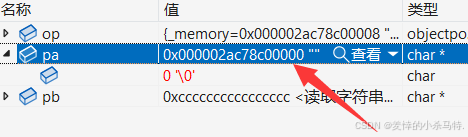
- 这里成功拿到char指针pa的地址。

- 然后释放掉pa(
其实只是清除资源,这块内存块还没有完全还给系统),然后再次为char申请空间,发现直接就拿到freelist里上次pa释放的地址,来当内存块给pb使用了。
因此经过简单测试发现设计的接口无一些异常问题。
🛠️下面测试下这个定长内存池的效率问题:
struct treenode {treenode* _left;treenode* _right;int _val;treenode():_left(nullptr), _right(nullptr),_val(0){//...}~treenode(){_left = nullptr;_right = nullptr;_val = 0;//...}};void test_objpool() {int rounds = 10;//测试轮数int N = 100000;//测试次数//模拟实现定长内存池速度:size_t begin2 = clock();std::vector<treenode*> vtn2;objectpool<treenode> op;for (int i = 0; i < rounds; i++) {for (int j = 0; j < N; j++) {vtn2.push_back(op.New());}for (int j = 0; j < N; j++) {op.Delete(vtn2[j]);}vtn2.clear();}size_t end2 = clock();//C++自带new与delete的速度:size_t begin1 = clock();std::vector<treenode*> vtn1;for (int i = 0; i < rounds; i++) {for (int j = 0; j< N; j++) {vtn1.push_back(new treenode());}for (int j = 0; j < N; j++) {delete vtn1[j];}vtn1 .clear();}size_t end1 = clock();cout << "new cost time:" << end1 - begin1 << endl; cout << "object pool cost time:" << end2 - begin2 << endl;
}
采取多轮多次大量申请然后释放然后再次申请,依次重复,对比C++库中new和delete以及objectpool效率问题:
📊十轮X十万:

📊十轮X一百万:
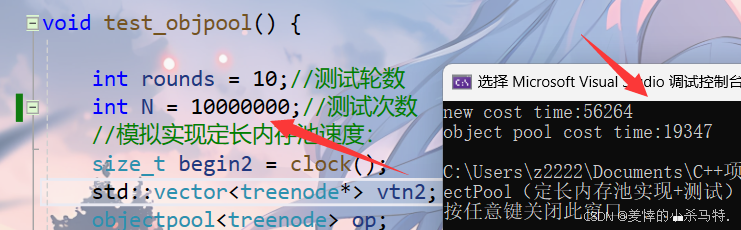
看样子,还是我们实现的定长内存池在比较大的开销面前还是略胜一筹的!
四· 定长内存池总结
-
⚠️因为定长内存池释放不用的T对象空间的时候,没有真正意义上的释放而是把这块空间链入
对应的freelist链表中,下次直接用即可,而类似new就被delete掉了,下次就要申请,花费时间,因此说objectpool在一定意义上提高了效率! -
⚠️但是因为这样的
设计模式,导致每个类型的objectpool只适用于一种类型的对象,这样就不会造成对应的外部碎片问题了,因此也算是优点带来的局限性吧。 -
⚠️其次就是对其他类型对象向系统申请内存有点’‘不公平’',比如对一个类型的
定长内存池大量申请,那么就会存在大量的定长内存块,然后再把资源清空,链入到对应的freelist链表中保存,而此时这个T类型的对象也没用这些空间,别人也无法申请对应的freelist里的空间,这样不就造成了’‘占着茅坑不拉屎’'的行为了,因此不需要了这个可以直接显示析构掉对象。
五· 源码汇总
✨点我急速获取gitee源码✨
六· 本篇小结
- 🚀 本篇文章,学习了
C++高性能内存池的开头最简单的一个"开胃菜"—定长内存池,了解了这种思想的奥妙,以及在自己模拟实现的时候一些细节,遇到的bug等等,耗时很久,收获满满,值得记录下来,留下自己曾走过的足迹!