分类预测 | Matlab实现CNN-LSTM-Attention高光谱数据分类
目录
- 分类预测 | Matlab实现CNN-LSTM-Attention高光谱数据分类
- 分类效果
- 功能概述
- 程序设计
- 参考资料
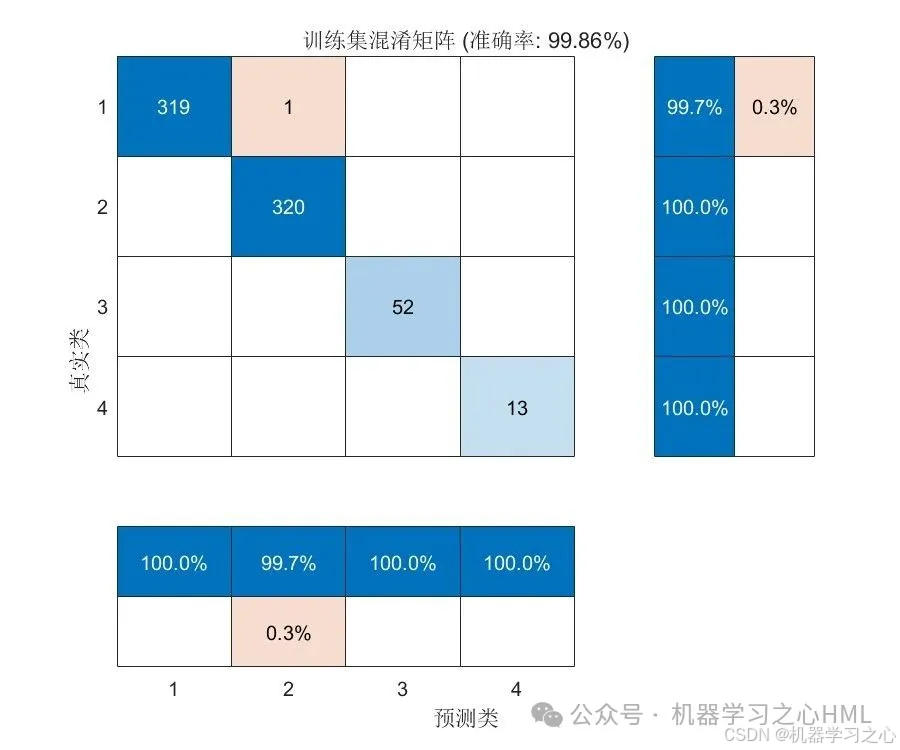
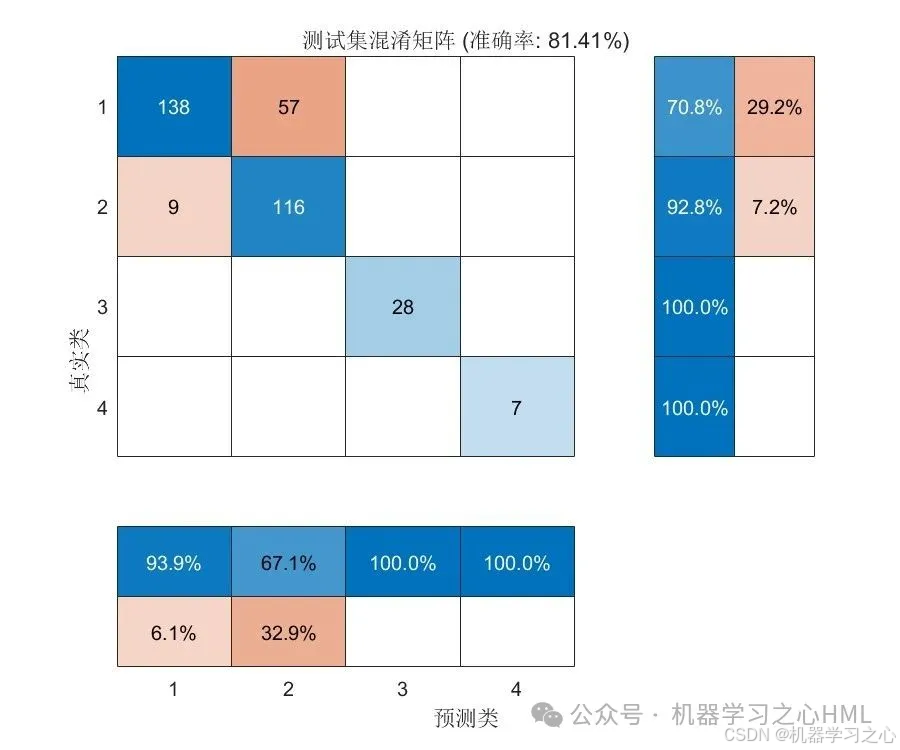
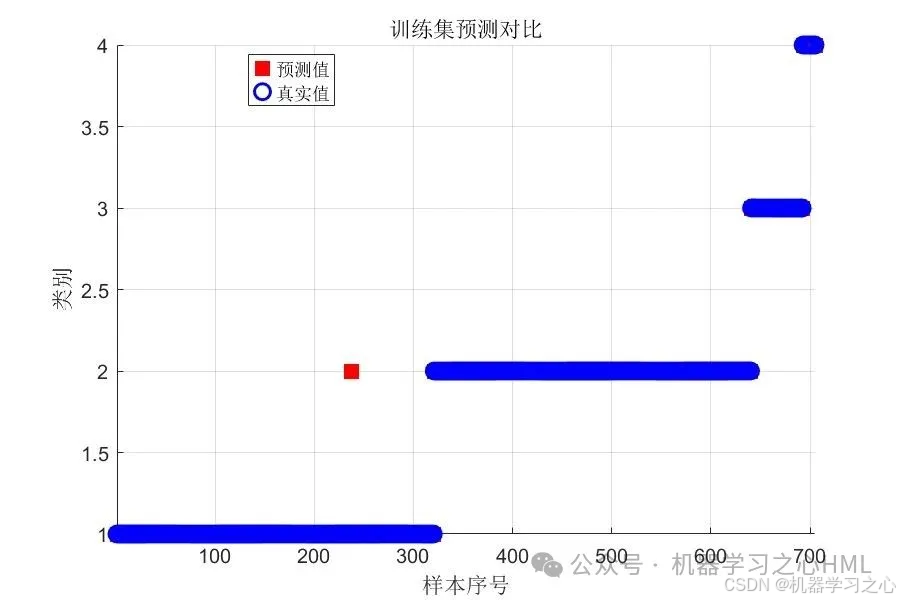
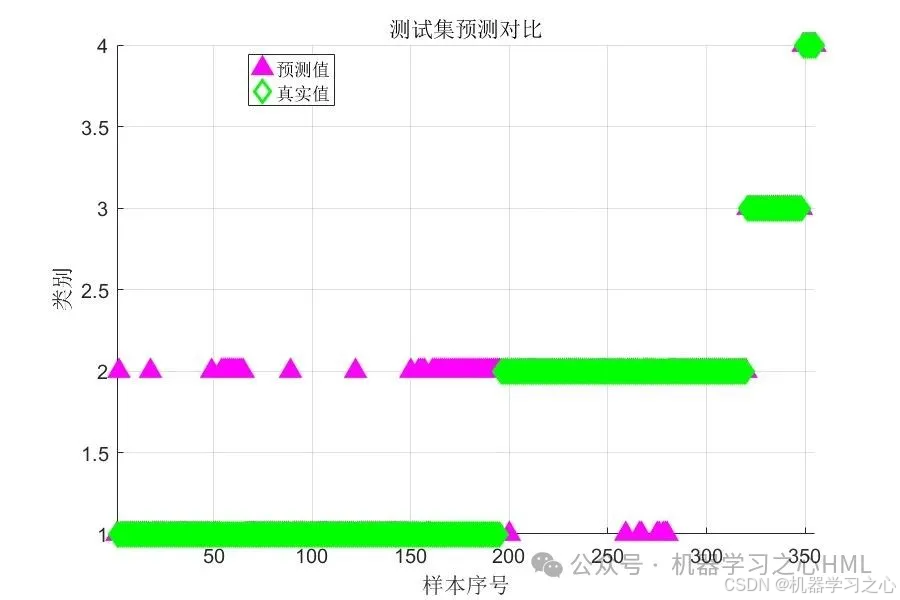
分类效果
功能概述
代码功能
该MATLAB代码实现了一个结合CNN、LSTM和注意力机制的高光谱数据分类模型,核心功能如下:
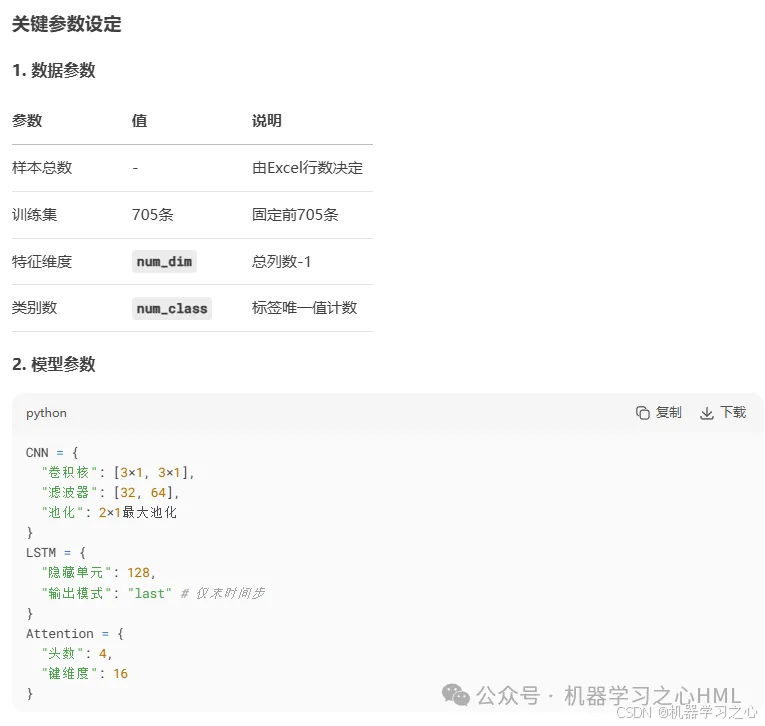
数据预处理
固定划分训练集(前705条)和测试集
特征归一化(mapminmax到[-1,1]区间)
数据重塑为LSTM所需的序列格式(num_dim×1×1的单元数组)
混合模型架构

核心模块
CNN模块:2个卷积层(32/64个滤波器)+ BN + ReLU + 最大池化
LSTM+Attention:128单元LSTM → 多头自注意力层(4头,16键维度)→ Dropout(0.3)
分类头:全连接层 + Softmax
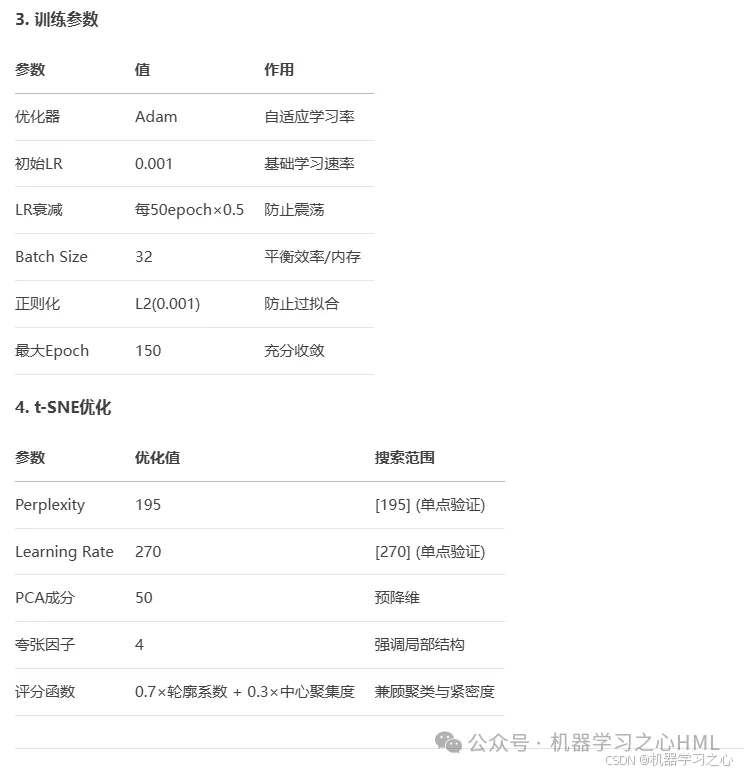
训练与评估
优化器:Adam(初始LR=0.001,分段衰减)
正则化:L2(0.001) + Dropout
评估指标:准确率 + 混淆矩阵 + 预测对比图
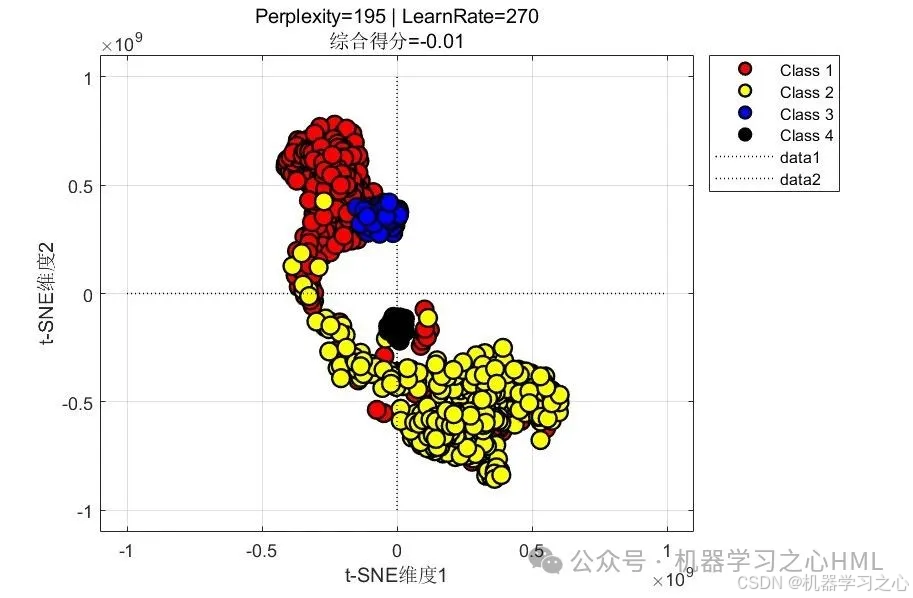
特征可视化:t-SNE降维(优化perplexity/lr)
创新可视化
注意力层特征提取 → PCA(50) → t-SNE(2D)
参数网格搜索(perplexity=195, lr=270)
综合评分 = 0.7×轮廓系数 + 0.3×中心聚集度
技术亮点
混合架构优势
CNN提取局部空间特征 → LSTM捕获时序依赖 → 注意力聚焦关键波段
防过拟合设计
Dropout(0.3) + L2正则化 + 早停机制(验证集监控)
可视化创新
动态参数优化:自动选择最佳t-SNE参数组合
综合评分指标:结合聚类质量(轮廓系数)和特征紧密度(中心聚集)
工程实践
数据泄露防护:使用训练集归一化参数处理测试集
可重复性:rng(0)固定随机种子
高效特征提取:activations()直接获取注意力层输出
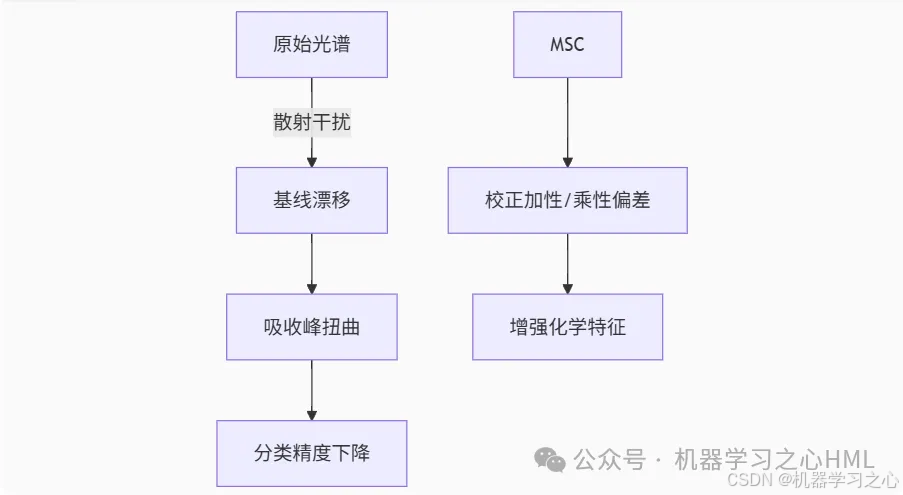
高光谱数据预处理
MSC (Multiplicative Scatter Correction) 是高光谱数据预处理的核心技术(Matlab代码不含此功能),主要用于消除光散射效应:
程序设计
- 完整程序和数据私信博主回复Matlab实现CNN-LSTM-Attention高光谱数据分类。
.rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');
%% 导入数据
res = xlsread('data.xlsx');
.rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
%% 网络架构
layers = [sequenceInputLayer([num_dim 1 1], 'Name','input')sequenceFoldingLayer('Name','fold')% ============== CNN模块 ==============convolution2dLayer([3 1],32, 'Padding','same', 'Name','conv1')batchNormalizationLayer('Name','bn1')reluLayer('Name','relu1')maxPooling2dLayer([2 1], 'Padding','same', 'Name','pool1')convolution2dLayer([3 1],64, 'Padding','same', 'Name','conv2')batchNormalizationLayer('Name','bn2')reluLayer('Name','relu2')maxPooling2dLayer([2 1], 'Padding','same', 'Name','pool2')% ====================================sequenceUnfoldingLayer('Name','unfold')flattenLayer('Name','flatten')% ========== LSTM+注意力模块 ==========lstmLayer(128, 'OutputMode','last', 'Name','lstm') selfAttentionLayer(4,16, 'Name','attention') dropoutLayer(0.3, 'Name','dropout')% ====================================, x, refValue_norm); % 调用SHAP函数
end
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229