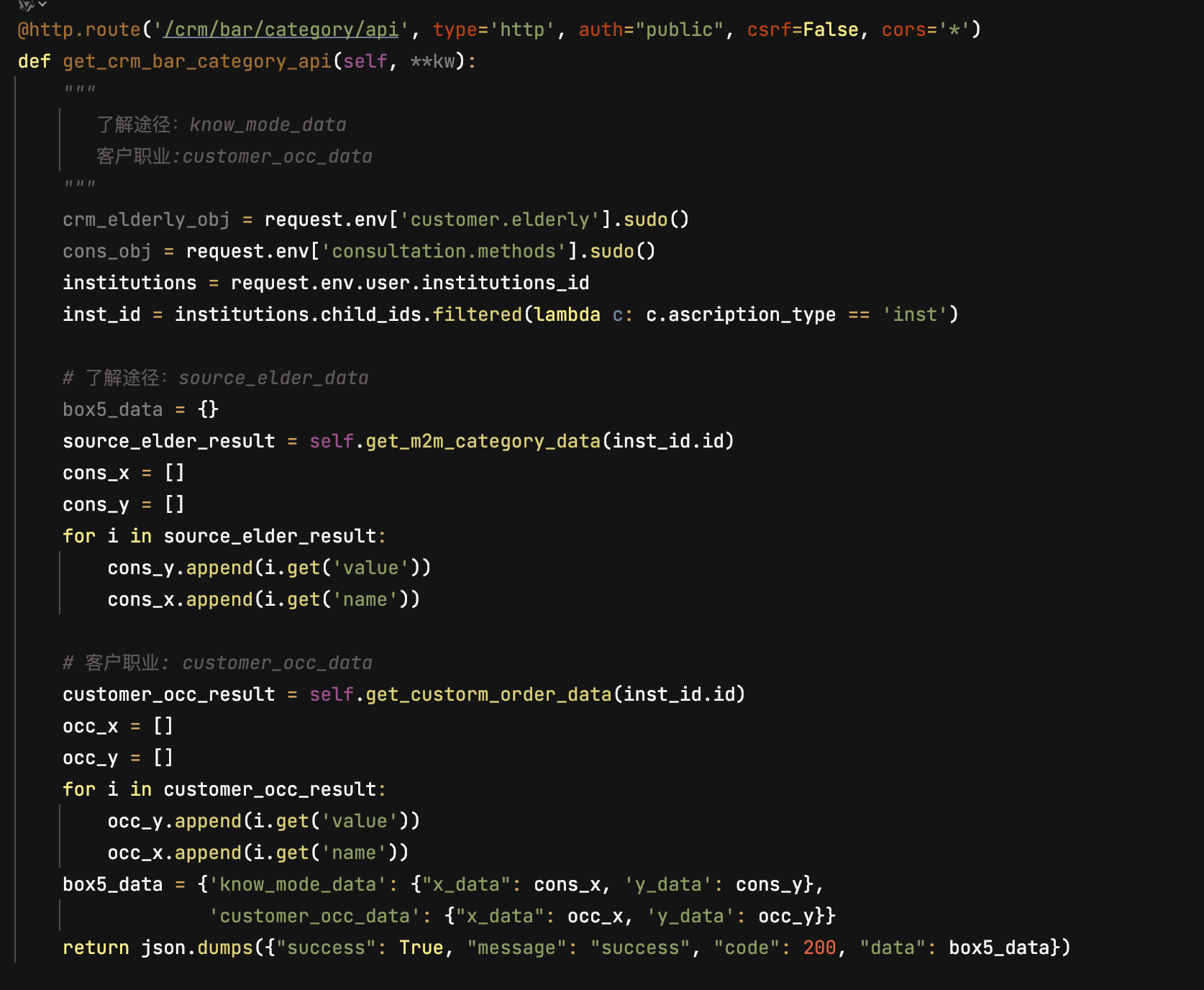
2024年数维杯国际大学生数学建模挑战赛
D题 城市弹性与可持续发展能力评价
原题再现:
中国人口老龄化趋势的加剧和2022年首次出现人口负增长,表明未来一段较长时期内我国人口将呈现下降趋势。这一趋势必将影响许多城市的高质量和可持续发展,特别是二级和三级城市,这些城市的影响可能是多方面的。与此同时,极端全球气候事件的日益频繁和当前的经济衰退将对城市发展的恢复力提出前所未有的挑战。
通过结合网络爬虫和实地调查,我们从58.com获得了城市1和城市2特定日期待售房产的基本信息,如附录1和2所示。此外,附录3和4提供了城市1和城市2特定年份的一些基本服务的POI数据。请使用这些数据对以下四个问题进行具体的优化和建模。
问题(1):考虑到上述数据和可以在互联网上收集的数据,如人口和GDP,您能否对城市1和城市2的不同地区的未来房价进行具体预测,并对这两个城市的现有住房总量进行具体估计?
问题(2):请定量分析城市1和城市2不同部门的服务水平,并提取这两个城市的共同和独特特征,以及各自的优势和劣势。
问题(3):使用附录3和4中的数据,评估两个城市应对极端天气和紧急情况的弹性,并定量评估城市的可持续发展能力。考虑到有限的财政资源的限制,您的模型应明确确定两个城市的具体弱点、未来需要发展的关键领域以及城市的短期和长期投资计划。
问题(4):根据上述分析,起草两个城市的未来发展计划,不超过两页。该计划应明确概述主要投资领域、投资金额和城市智能城市发展水平的预期改进。
整体求解过程概述(摘要)
我国人口老龄化日益严重,未来人口将处于长期下降的趋势。这将对二、三线城市的可持续发展产生深远影响,并对城市弹性提出严重挑战。基于所附数据,建立了城市韧性和可持续发展能力评价的数学模型。
对于问题1,首先对原始数据进行缺失值和离群值处理,然后使用三个回归模型(线性回归、随机森林和梯度提升)来训练数据,以学习特征与目标之间的关系,从而预测房价。结果表明,随机森林模型和梯度提升模型具有较好的预测效果。因此,城市1的住房存量估计为1459933.97,城市2的住房存量估算为834249.01。
对于问题2,首先清理和转换附件中的数据,然后采用K均值聚类方法分析City1和City2中各种设施的地理分布和聚类特征,并将结果可视化。聚类结果揭示了它们的共同和独特特征,并分析了它们的优缺点。研究结果表明,与城市2相比,城市1的地理名称和地址信息、汽车服务、医疗保健服务、零售服务、摩托车设施和科学教育等设施的数量和密度明显更高。
针对问题3,根据服务指数数据,建立了多指标加权城市弹性评价模型。结果表明,City1的整体韧性得分更好,为0.74,而City2的得分为0.67。分析表明,城市1在应急管理资源配置和政府机构覆盖率方面表现突出,但其弱点在于社会支持体系的多样性和基层组织的动员能力。建议加强社区应急设施建设。第二城基层应急资源的分布和可获得性有限,弱点在于社会群体参与度低。建议加强应急保障能力。
针对问题4,在前三个问题的分析和结果的基础上,在综合分析研究城市1和城市2优劣势的基础上。加大对城市现有优势的投资,进一步巩固和扩大其在智慧城市建设中的领先地位;针对不足,致力于通过精准的资本投入,优化自身不足,促进智慧城市发展水平的全面提升。
模型假设:
1.数据完整性和准确性:假设使用的数据准确、完整,并代表研究区域的实际情况。
2.经济发展趋势的一致性:假设该市的经济发展遵循当前趋势,短期内不会出现重大波动或不可预见的政策变化。
问题分析:
问题一的分析
对于问题1,目标是根据提供的房地产销售信息和可以获得的其他相关数据(如人口和GDP数据),预测城市1和城市2的未来房价和现有住房存量。结合58.com网站的物业销售数据、基础服务POI数据和相关经济指标,提出了具体的优化方案和建模方法。通过对不同地区房价的趋势分析,并评估人口和GDP等因素的影响,目的是对这两个城市未来的住房市场动态进行全面预测。
问题二的分析
对于问题2,该任务要求我们定量分析两个城市的服务,提取共同和独特的特征,并确定各自的优势和劣势。首先,我们将清理和标准化附件中提供的数据。然后,我们将应用K-均值聚类方法来分析这些设施的分布、聚集、数量、覆盖和服务类型比例。通过使用可视化技术和表格数据,我们旨在比较这两个城市。
问题三的分析
关于问题3,目标是评估这两个城市在极端天气和紧急情况下的复原力和可持续性。通过分析提供的15个服务指标的数据,初步确定了各指标之间的相关性,以确定对衡量城市韧性和可持续性至关重要的指标。该分析将为城市韧性的进一步评估模型提供理论支持和数据基础。
问题四的分析
本部分基于问题1至问题3的分析结论,针对长春和呼和浩特的具体优势和劣势,确定主要投资方向和资本配置,并预测这些投资带来的智慧城市发展水平的提高。在保持城市现有优势的基础上,重点优化和完善短板区域,实现两市在智慧城市建设中的全面进步。以下内容系统梳理和分析了主要投资领域、预算分配和发展预期。
模型的建立与求解整体论文缩略图


全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:
import pandas as pd
import matplotlib.pyplot as plt
import folium
from geopy.distance import geodesic
import seaborn as sns
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
file_path_1 = r"Appendix 1.xlsx"
file_path_2 = r"Appendix 2.xlsx"
city1_files = { culture data.csv" }
city2_files = { data.csv" }
def load_house_data(file_path): data = pd.read_excel(file_path, sheet_name='Sheet1') return data house_data_1 = load_house_data(file_path_1)
house_data_2 = load_house_data(file_path_2) # 处理缺失值和异常值
def process_missing_and_outliers(data, column_name): print(f"处理前{column_name}缺失值数量:",
data[column_name].isnull().sum()) data[column_name] =
data[column_name].fillna(data[column_name].mean()) # 填充缺失值 Q1, Q3 = data[column_name].quantile([0.25, 0.75]) # 四分位数 IQR = Q3 - Q1 # 四分位距 lower_bound, upper_bound = Q1 - 1.5 * IQR, Q3 + 1.5 * IQR data[column_name] = data[column_name].apply(lambda x: max(min(x,
upper_bound), lower_bound)) print(f"处理后{column_name}缺失值数量:",
data[column_name].isnull().sum()) return data house_data_1 = process_missing_and_outliers(house_data_1, 'Price (USD)')
house_data_2 = process_missing_and_outliers(house_data_2, 'Price (USD)') # 数据分布分析
def plot_distribution(data, column_name, title): plt.figure(figsize=(10, 6)) plt.hist(data[column_name], bins=30, color='#3E92CC',
edgecolor='black', alpha=0.7) plt.title(f"{title}: {column_name}") plt.xlabel(column_name) plt.ylabel('Frequency') plt.grid(axis='y', linestyle='--', alpha=0.7) plt.show() plot_distribution(house_data_1, 'Price (USD)', 'city1-Price')
plot_distribution(house_data_2, 'Price (USD)', 'city2-Price') # 绘制箱型图
def plot_boxplot(data1, data2, column_name, city1_name, city2_name,
title):plt.figure(figsize=(10, 6)) # 合并数据用于绘制 combined_data = [data1[column_name], data2[column_name]] # 绘制箱型图 plt.boxplot(combined_data, patch_artist=True, boxprops=dict(facecolor='#3E92CC', color='black',
alpha=0.7), medianprops=dict(color='red', linewidth=1.5), whiskerprops=dict(color='black', linewidth=1), capprops=dict(color='black', linewidth=1)) # 设置x轴和标题 plt.xticks([1, 2], [city1_name, city2_name], fontsize=12) plt.title(title, fontsize=16) plt.ylabel(column_name, fontsize=12) plt.grid(axis='y', linestyle='--', alpha=0.7) plt.tight_layout() plt.show() # 绘制城市1和城市2的房价箱型图
plot_boxplot(house_data_1, house_data_2, 'Price (USD)', 'City 1', 'City
2', 'Comparison of Price (USD) Between City 1 and City 2') # 加载设施数据
def load_facilities(file_dict): datasets = {} for key, path in file_dict.items(): try: data = pd.read_csv(path) if 'lon_gcj02' in data.columns and 'lat_gcj02' in
data.columns: data['lon_gcj02'] = pd.to_numeric(data['lon_gcj02'],
errors='coerce')data['lat_gcj02'] = pd.to_numeric(data['lat_gcj02'],
errors='coerce') datasets[key] = data.dropna(subset=['lon_gcj02',
'lat_gcj02']) else: print(f"{key} 跳过。") except Exception as e: print(f"加载 {key} {e}") return datasets city1_data = load_facilities(city1_files)
city2_data = load_facilities(city2_files) # 计算房产到设施的最近距离
def calculate_nearest_distance(house_data, facility_data, house_lat_col,
house_lon_col): distances = [] for _, house in house_data.iterrows(): house_location = (house[house_lat_col], house[house_lon_col]) min_distance = facility_data.apply( lambda row: geodesic(house_location, (row['lat_gcj02'],
row['lon_gcj02'])).km, axis=1 ).min() distances.append(min_distance) return distances # 为房产添加设施距离特征
def add_facility_distance_features(house_data, facilities,
house_lat_col, house_lon_col): for facility_type, facility_data in facilities.items(): print(f"计算房产到最近 {facility_type} 的距离...") house_data[f'nearest_{facility_type}_distance'] =
calculate_nearest_distance( house_data, facility_data, house_lat_col, house_lon_col ) add_facility_distance_features(house_data_1, city1_data, 'lat', 'lon')
add_facility_distance_features(house_data_2, city2_data, 'lat', 'lon') # 综合相关性分析(城市1和城市2在同一张图中)
def analyze_feature_correlation_combined(data1, data2, target_col,
city1_name, city2_name):
# 选择数值型列 numeric_cols1 = data1.select_dtypes(include=['float64',
'int64']).columns numeric_cols2 = data2.select_dtypes(include=['float64',
'int64']).columns # 计算相关性 correlation1 =
data1[numeric_cols1].corr()[target_col].sort_values(ascending=False)[1:] correlation2 =
data2[numeric_cols2].corr()[target_col].sort_values(ascending=False)[1:] # 合并列索引 combined_index = list(set(correlation1.index) |
set(correlation2.index)) correlation1 = correlation1.reindex(combined_index, fill_value=0) correlation2 = correlation2.reindex(combined_index, fill_value=0) # 绘制相关性柱状图 x = range(len(combined_index)) plt.figure(figsize=(15, 8)) # 城市1的柱状图 plt.bar(x, correlation1, width=0.4, label=city1_name,
color='#3E92CC', edgecolor='black', alpha=0.7, align='center') # 城市2的柱状图 plt.bar([i + 0.4 for i in x], correlation2, width=0.4,
label=city2_name, color='#F95D6A', edgecolor='black', alpha=0.7, align='center') # 图表美化 plt.title(f"Correlation of Features with {target_col}", fontsize=16) plt.ylabel("Correlation Coefficient", fontsize=12) plt.xlabel("Feature Names", fontsize=12) plt.axhline(0, color='black', linewidth=0.8) # 添加水平线 plt.xticks([i + 0.2 for i in x], combined_index, rotation=45,
ha='right', fontsize=10) # 调整x轴刻度和标签 plt.legend(fontsize=12) plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加网格线,样式统一 plt.tight_layout() # 调整布局防止溢出 plt.show()