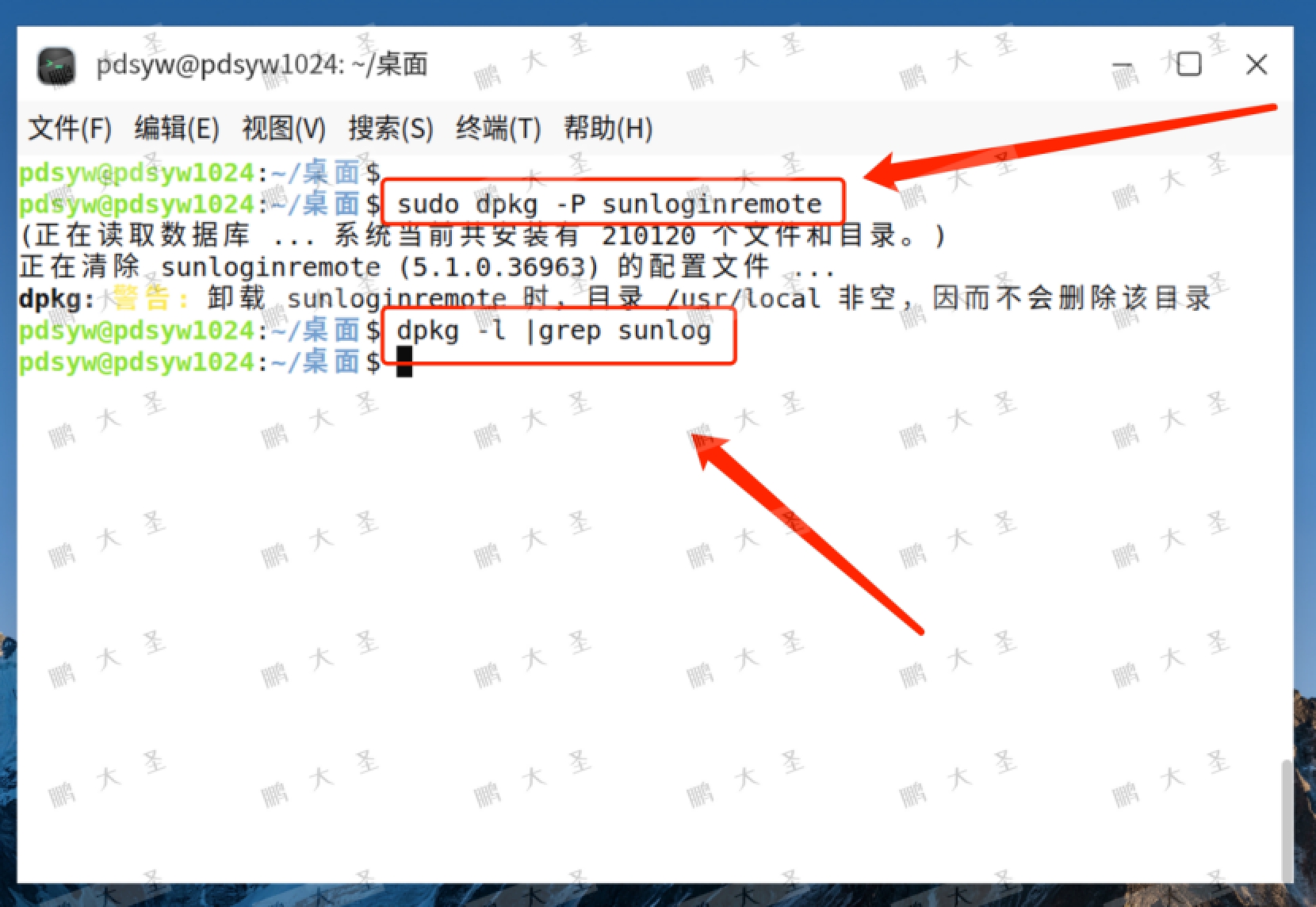
一、前言
最近一个项目需要使用YOLO进行视觉识别,为了识别更准确,采集了大约两万张图片用于制作数据集,从而引发了一个问题,那就是数据集太多了如果人为去框的话根本就不现实。那么,有没有一种办法可以让我们先自己框一小部分数据集用于训练YOLO模型,然后用我们训练出来的模型去框剩余的图片并且生成数据集?其实当然有这样的办法,并且开源的工具有很多,但是我们这次就不使用别的工具,就使用YOLO原生的推理帮我们自动框选数据集。如果你准备好了,那就让我们开始吧!
二、谁适合本次教程
本篇教程需要你具有一定的YOLO基础,至少能够部署YOLO的环境和进行训练。如果你还不知到如何部署YOLO的环境可以看下面的教程:
YOLO环境搭建教程:[AI]小白向的YOLO安装教程-CSDN博客
如果你还不会训练YOLO模型可以看下面的教程:
YOLO训练教程:[AI]YOLO如何训练对象检测模型(详细)_yolo模型-CSDN博客
当你已经对YOLO的环境搭建以及训练非常了解以后就可以进行下面的步骤了。
三、YOLO模型训练
前面已经提到了,我们需要先自行框选一小部分数据集训练一个模型,然后使用这个模型帮我们制作新的数据集,那么现在首要的问题就是我们需要训练一个模型。这里使用YOLOv8框架进行训练,数据集的话这里我直接使用项目中的数据集作为训练数据集,我自己框了60张:


验证数据集准备了20张:

上面的数据集就是自己框选的少量数据集,我们需要使用这些数据集训练模型并且使用训练出的模型去推理新的数据集。
准备好“train”文件夹与“valid”后就可以开始训练了,我这里的“data.yaml”文件内容如下:
train: ./train/images
val: ./valid/images names:0: Tube我这里只有一个对象,所以"data.yaml"比较简单。
训练脚本内容如下:
from ultralytics import YOLO
def train_yolov8():model = YOLO('yolov8n.pt') model.train(data='data.yaml', epochs=5, imgsz=1920, device=0, workers=1, batch=8 )
if __name__ == '__main__':train_yolov8()这里我就选择训练5步,每个文件中的内容代表什么在YOLO的训练教程中讲得已经很清楚了,这里就不多说了。这里的训练步骤大家根据自己的情况调整即可。如果数据集很少建议多训练一点步骤。
所有内容准备好以后“datasets”中内容如下:

这里直接启动训练即可:

训练完成后输出的结果如下:

这里我们也得到了训练后的模型:

后面我们会使用“best.pt”来进行推理剩余的数据集。
四、使用训练后的YOLO模型推理数据集
在上面我们使用少量数据集已经训练好了一个YOLO模型,现在我们就使用这个模型来推理剩余的数据集,这里我有一个名为“train”的文件夹,下面有“images”文件夹和我们之前训练好的模型文件:

在“images”中有我们需要制作数据集的图片,大约有2万张:


这里我们直接在train目录中执行下面的命令:
yolo task=detect mode=predict model=./best.pt source=images/ save_txt=True project=labels name=labels exist_ok=True save=False下面我来解释一下这行命令:
yolo:这就是YOLO的命令行工具,表示我们要使用YOLO。
task=detect:指定我们当前要做的是目标检测任务。
mode=predict:表示要使用这个模型进行推理。
model=./best.pt:是我们模型的路径,因为我就在模型所在路径输入的命令,所以这里的路径是“./”
source=images/:表示要推理的图片所在的目录,这个目录的路径同样是相对于我们命令执行的目录。
save_txt=True:表示需要保存识别到的物品的类别与标签,这个选项对于我们使用YOLO制作数据集非常关键。
project=labels:表示要保存结果的目录的名称。
name=labels:保存的项目名称。
exist_ok=True:表示允许覆盖目标文件夹中的内容。
save=False:表示不保存预测后的图像,因为我们只需要获得每个图像中标签对应的位置,所以推理出来的图像对我们来说没有意义。
输入命令并且回车以后,推理就开始了:

我们等待完成即可。
我们可以看到这里已经推理完成了,并且可以看到标签的输出目录:

最终,我们所有图片的标签被生成到了“train”目录下的“labels\labels\labels”目录下,没错,这里套了三层labels,这里txt文件的数量应该和我们的图片数量是对应的:

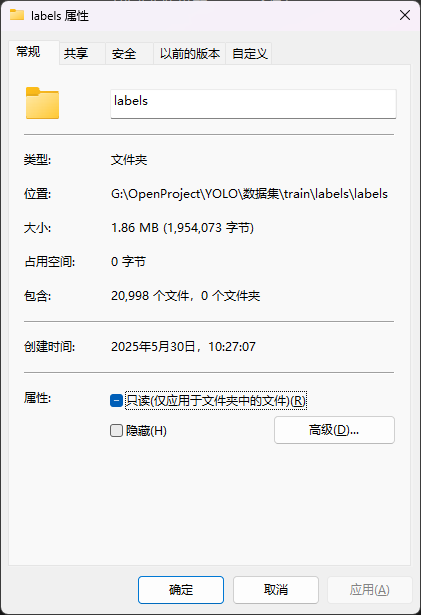
大家将生成出来的txt复制到对应的训练目录即可。
至此,我们使用YOLO自动帮我们框选数据集就完成了。
五、结语
本次教程中,教了大家如何通过少量数据集训练YOLO并且使用训练出来的模型帮我们框选剩余数据集,这样可以为我们节约大量时间和精力,那么最后,感谢大家的观看!