@浙大疏锦行
作业:
"""
DAY 39 图像数据与显存
本节主要介绍深度学习中的图像数据处理和显存管理。
"""import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 设置随机种子确保结果可复现
torch.manual_seed(42)#====================== 1. 图像数据的格式 ======================
"""
1.1 图像数据与结构化数据的区别:
- 结构化数据(表格数据)形状:(样本数, 特征数),如(1000, 5)
- 图像数据需要保留空间信息,形状更复杂:(通道数, 高度, 宽度)
1.2 图像数据的两种主要格式:
- 灰度图像:单通道,如MNIST数据集 (1, 28, 28)
- 彩色图像:三通道(RGB),如CIFAR-10数据集 (3, 32, 32)
"""# 定义数据处理步骤
transforms = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 加载CIFAR-10数据集作为示例
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transforms)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')#====================== 2. 模型的定义 ======================
"""
为了演示显存占用,我们定义一个简单的CNN模型
"""class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size=128, num_classes=10):super(MLP, self).__init__()# 展平层:将3×32×32的彩色图像转为一维向量# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072self.flatten = nn.Flatten()# 全连接层self.fc1 = nn.Linear(input_size, hidden_size) # 第一层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]x = self.relu(x) # 激活函数x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]return x#====================== 3. 显存占用分析 ======================
"""
3.1 模型参数与梯度参数
- 每个参数需要存储值和梯度
- 使用float32类型,每个数占4字节
"""
model = MLP()
total_params = sum(p.numel() for p in model.parameters())
print(f"\n模型总参数量:{total_params}")
print(f"参数占用显存:{total_params * 4 / 1024 / 1024:.2f} MB")"""
3.2 优化器参数
- 如Adam优化器会为每个参数存储额外状态(如动量)
- 通常是参数量的2-3倍
"""
optimizer = torch.optim.Adam(model.parameters())
print(f"优化器额外占用显存:{total_params * 8 / 1024 / 1024:.2f} MB")"""
3.3 数据批量所占显存
- 与batch_size成正比
- 需要考虑输入数据和中间特征图
"""
# 计算单个CIFAR-10图像占用
single_image_size = 3 * 32 * 32 * 4 # 通道*高*宽*字节数
print(f"单张图像占用:{single_image_size / 1024:.2f} KB")
print(f"batch_size=4时占用:{single_image_size * 4 / 1024:.2f} KB")
print(f"batch_size=64时占用:{single_image_size * 64 / 1024 / 1024:.2f} MB")"""
3.4 神经元输出中间状态
- 前向传播时的特征图
- 反向传播需要的中间结果
- 通常比输入数据大很多
"""#====================== 4. batch_size与训练的关系 ======================
"""
4.1 batch_size的影响:
- 较大的batch_size:* 计算效率更高* 梯度估计更准确* 需要更多显存* 可能导致泛化性能下降- 较小的batch_size:* 训练更慢* 梯度估计噪声大* 需要更少显存* 可能有更好的泛化性能4.2 选择合适的batch_size:
- 从小值开始(如16)
- 逐渐增加直到接近显存限制
- 通常设置为显存上限的80%
- 需要在训练效率和模型性能之间权衡
"""# 展示一张样例图片
def show_sample_image():sample_idx = torch.randint(0, len(trainset), size=(1,)).item()image, label = trainset[sample_idx]print(f"图片形状: {image.shape}")print(f"类别: {classes[label]}")# 显示图片img = image / 2 + 0.5 # 反标准化npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.title(f'类别: {classes[label]}')plt.show()# 显示样例图片
show_sample_image()"""
总结:
1. 图像数据需要特殊的预处理和格式转换
2. 显存管理是深度学习中的重要问题
3. batch_size的选择需要综合考虑多个因素
4. 合理的显存管理可以提高训练效率
"""Files already downloaded and verified模型总参数量:394634
参数占用显存:1.51 MB
优化器额外占用显存:3.01 MB
单张图像占用:12.00 KB
batch_size=4时占用:48.00 KB
batch_size=64时占用:0.75 MB
图片形状: torch.Size([3, 32, 32])
类别: deer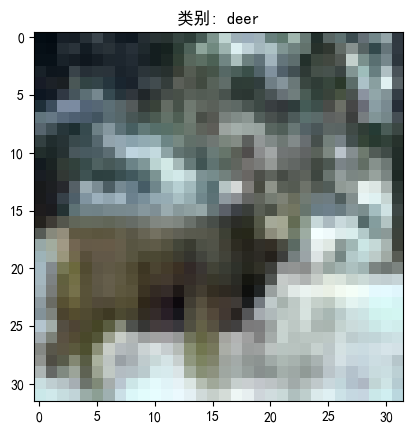
"""
DAY 39 图像数据与显存
本节主要介绍深度学习中的图像数据处理和显存管理。
"""import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from torchvision import datasets
import psutil# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# 设置随机种子确保结果可复现
torch.manual_seed(42)# 内存监控工具
def print_memory_usage():"""打印当前内存和GPU使用情况"""# 系统内存mem = psutil.virtual_memory()print(f"系统内存: 总共 {mem.total/1024/1024:.2f} MB, 已用 {mem.used/1024/1024:.2f} MB, 空闲 {mem.free/1024/1024:.2f} MB")# GPU内存if torch.cuda.is_available():for i in range(torch.cuda.device_count()):mem_allocated = torch.cuda.memory_allocated(i) / 1024 / 1024mem_cached = torch.cuda.memory_reserved(i) / 1024 / 1024props = torch.cuda.get_device_properties(i)print(f"GPU {i}: {props.name}, 总显存 {props.total_memory/1024/1024:.2f} MB, 已分配 {mem_allocated:.2f} MB, 缓存 {mem_cached:.2f} MB")else:print("当前使用CPU,无GPU显存信息")#====================== 1. 图像数据的格式 ======================
"""
1.1 图像数据与结构化数据的区别:
- 结构化数据(表格数据)形状:(样本数, 特征数),如(1000, 5)
- 图像数据需要保留空间信息,形状更复杂:(通道数, 高度, 宽度)
1.2 图像数据的两种主要格式:
- 灰度图像:单通道,如MNIST数据集 (1, 28, 28)
- 彩色图像:三通道(RGB),如CIFAR-10数据集 (3, 32, 32)
"""# 定义MNIST数据预处理(灰度图)
transform_mnist = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 定义CIFAR-10数据预处理(彩色图),用于显存分析示例
transform_cifar = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)) # CIFAR-10标准归一化参数
])# 加载MNIST数据集(用于实际训练)
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform_mnist
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform_mnist
)#====================== 2. 模型的定义 ======================
"""
为了演示显存占用,定义适配不同数据集的MLP模型
"""class MLP(nn.Module):def __init__(self, input_size, hidden_size=128, num_classes=10):super(MLP, self).__init__()self.flatten = nn.Flatten() # 展平层self.fc1 = nn.Linear(input_size, hidden_size) # 隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return x# 根据数据集选择输入尺寸(MNIST为1x28x28=784,CIFAR为3x32x32=3072)
# 此处以MNIST为例定义模型(与加载的数据集匹配)
input_size = 1 * 28 * 28 # MNIST输入尺寸
model = MLP(input_size=input_size)#====================== 3. 显存占用分析 ======================
"""
3.1 模型参数与梯度参数(以MNIST模型为例)
"""
total_params = sum(p.numel() for p in model.parameters())
print(f"\n模型总参数量:{total_params}")
param_memory = total_params * 4 / (1024 * 1024) # float32占4字节,转换为MB
print(f"参数占用显存:{param_memory:.4f} MB")"""
3.2 优化器参数(以Adam为例)
"""
optimizer = torch.optim.Adam(model.parameters())
optimizer_memory = total_params * 8 / (1024 * 1024) # 动量和梯度平方各占4字节
print(f"Adam优化器额外占用显存:{optimizer_memory:.4f} MB")"""
3.3 数据批量显存占用(同时演示MNIST和CIFAR-10)
"""
# MNIST数据占用(单张1x28x28,float32)
mnist_single = 1 * 28 * 28 * 4
print(f"\nMNIST单张图像占用:{mnist_single / 1024:.2f} KB")
batch_sizes = [4, 32, 128]
for bs in batch_sizes:mnist_batch = mnist_single * bs / 1024print(f"MNIST batch_size={bs}时数据占用:{mnist_batch:.2f} KB")"""
3.4 神经元输出中间状态(以MNIST模型、batch_size=32为例)
"""
hidden_size = 128
intermediate_size = 32 * hidden_size * 4 # batch_size×隐藏层维度×4字节
print(f"\n中间层(隐藏层)输出占用:{intermediate_size / 1024:.2f} KB")#====================== 4. 设备分配与内存优化 ======================
"""
尝试将模型移至GPU,若显存不足则使用CPU
"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
try:model = model.to(device)print(f"\n成功将模型移至{device}")print_memory_usage()
except RuntimeError as e:if "out of memory" in str(e):print("\n错误:GPU显存不足,切换至CPU模式")model = model.to("cpu")device = "cpu"else:raise e#====================== 5. batch_size与训练的关系 ======================
"""
4.1 batch_size的影响:
- 较大的batch_size:* 计算效率更高* 梯度估计更准确* 需要更多显存* 可能导致泛化性能下降- 较小的batch_size:* 训练更慢* 梯度估计噪声大* 需要更少显存* 可能有更好的泛化性能4.2 选择策略:从16开始尝试,逐步增加至显存上限的80%
"""# 设置自适应batch_size(根据设备类型调整)
if device == "cuda":# GPU环境尝试较大batch_sizebatch_size = 64
else:# CPU环境使用较小batch_sizebatch_size = 16train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0 # 初始设为0避免多进程内存开销
)#====================== 6. 样例图像展示 ======================
"""
注意:MNIST为灰度图,CIFAR-10为彩色图,展示方式不同
"""
def show_sample_image(dataset, transform=None):"""展示数据集样例图像,支持MNIST和CIFAR-10"""sample_idx = torch.randint(0, len(dataset), size=(1,)).item()image, label = dataset[sample_idx]# 反标准化(仅适用于MNIST)if isinstance(dataset, datasets.MNIST):image = image * transform_mnist.transforms[1].std[0] + transform_mnist.transforms[1].mean[0]plt.imshow(image.squeeze(), cmap='gray')plt.title(f"MNIST 类别: {label}")else:# 假设为CIFAR-10等彩色图if transform:# 恢复归一化image = image * torch.tensor(transform.transforms[1].std) + torch.tensor(transform.transforms[1].mean)plt.imshow(np.transpose(image.numpy(), (1, 2, 0)))plt.title(f"类别: {label}")plt.show()print(f"图像形状: {image.shape},类别: {label}")# 展示MNIST样例(与加载的数据集一致)
print("\n展示MNIST样例图像:")
show_sample_image(train_dataset)#====================== 7. 显存优化总结 ======================
print("\n显存优化关键点:")
print("1. 模型参数与优化器状态是基础占用,Adam比SGD多占用约2倍参数内存")
print("2. 数据批量与batch_size成正比,CIFAR-10单张图像显存是MNIST的约13倍")
print(f"3. 当前配置下,模型+优化器基础占用约 {param_memory + optimizer_memory:.4f} MB")
print(f"4. batch_size={batch_size}时,MNIST数据占用约 {mnist_single * batch_size / 1024:.2f} KB")
print("5. 若出现显存不足,可尝试减小batch_size、使用SGD优化器或启用混合精度训练")模型总参数量:101770
参数占用显存:0.3882 MB
Adam优化器额外占用显存:0.7764 MBMNIST单张图像占用:3.06 KB
MNIST batch_size=4时数据占用:12.25 KB
MNIST batch_size=32时数据占用:98.00 KB
MNIST batch_size=128时数据占用:392.00 KB中间层(隐藏层)输出占用:16.00 KB错误:GPU显存不足,切换至CPU模式展示MNIST样例图像: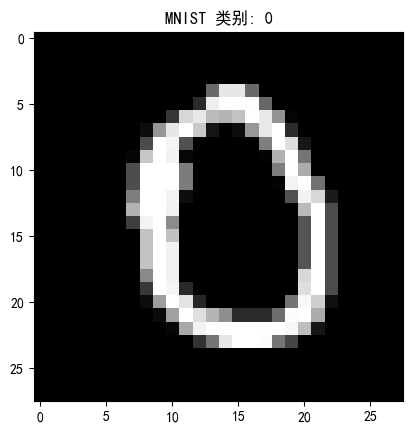
图像形状: torch.Size([1, 28, 28]),类别: 0显存优化关键点:
1. 模型参数与优化器状态是基础占用,Adam比SGD多占用约2倍参数内存
2. 数据批量与batch_size成正比,CIFAR-10单张图像显存是MNIST的约13倍
3. 当前配置下,模型+优化器基础占用约 1.1647 MB
4. batch_size=16时,MNIST数据占用约 49.00 KB
5. 若出现显存不足,可尝试减小batch_size、使用SGD优化器或启用混合精度训练