在人工智能算法开发领域,TensorFlow与PyTorch作为两大主流框架,分别以静态图的高效性与动态图的灵活性著称。本课程以工程实践为导向,系统化梳理深度学习模型的核心应用场景:通过卷积神经网络(CNN)实现高精度图像分类任务,结合循环神经网络(RNN)解决时序数据预测问题,并基于Transformer架构构建自然语言处理系统。课程内容不仅涵盖模型构建与训练调参的技术细节,还将深入探讨工业场景下的模型压缩、部署优化及跨平台适配方案。通过真实企业级案例的拆解,学习者将掌握从理论推导到工程落地的完整技术链条,同时建立针对不同业务需求的算法选型与性能优化方法论。
TensorFlow与PyTorch框架对比
在深度学习领域,TensorFlow和PyTorch作为两大主流框架,分别代表了不同的开发范式与技术生态。TensorFlow凭借其成熟的静态计算图设计与完善的工业级部署工具链(如TensorFlow Serving和TensorFlow Lite),长期主导着生产环境中的模型落地场景,尤其适合需要跨平台部署的复杂项目。而PyTorch则以动态计算图的灵活性和直观的即时执行模式(Eager Execution)著称,其简洁的API设计与Python原生生态的无缝集成,使其成为学术界和快速原型开发的首选工具。
实际开发中,建议根据项目阶段选择框架:TensorFlow适合需要严格版本控制与生产部署的团队,而PyPyTorch更适配需要频繁调试与算法探索的研究场景。
两者在生态系统支持上的差异同样显著:TensorFlow通过Keras高层API降低了模型构建门槛,同时提供TFX(TensorFlow Extended)等全流程解决方案;PyTorch则通过TorchScript实现模型序列化,并依托ONNX格式强化跨框架兼容性。值得注意的是,随着PyTorch 2.0对编译优化的增强以及TensorFlow 2.x对动态图模式的官方支持,两大框架的功能边界正逐步趋于模糊,开发者需持续关注版本迭代带来的技术红利。
CNN图像识别实战指南
在图像识别领域,卷积神经网络(CNN)凭借其局部感知与权值共享特性,成为处理二维空间数据的首选架构。实战中,开发者需优先构建规范化的数据管道:通过TensorFlow的tf.data模块或PyTorch的Dataset类实现数据加载,结合随机裁剪、归一化及数据增强技术(如旋转、翻转)提升模型泛化能力。模型搭建阶段,可基于TensorFlow的Keras接口快速堆叠卷积层、池化层与全连接层,或利用PyTorch的动态计算图灵活设计残差连接等复杂结构。以经典ResNet为例,通过预训练权重迁移学习可显著加速医疗影像分类等场景的训练效率。训练过程中需关注学习率动态调整策略(如余弦退火)与正则化手段(如Dropout),同时结合混合精度训练与分布式计算优化资源消耗。工业部署环节,建议使用TensorFlow Serving或PyTorch TorchScript将模型转换为轻量化格式,适配边缘设备与云端服务协同推理需求。
RNN时序预测核心原理
循环神经网络(RNN)通过引入时序记忆单元,成为处理序列数据的核心架构。其核心机制在于隐藏状态的循环传递,使网络能够捕捉时间维度上的动态依赖关系。以时间步为处理单元,RNN在每一步接收当前输入与上一步的隐藏状态,通过激活函数生成新的输出和更新后的隐藏状态。这种结构特性使其天然适配时序预测任务,例如股票价格波动分析或气象数据趋势推断。然而,传统RNN存在梯度消失或爆炸问题,导致长序列建模能力受限。为此,LSTM(长短期记忆网络)与GRU(门控循环单元)通过引入门控机制,有效缓解了长期依赖的学习难题。在TensorFlow与PyTorch框架中,开发者可通过内置的RNN模块(如tf.keras.layers.LSTM或torch.nn.GRU)快速构建模型,并通过反向传播算法优化参数。实际应用中,需根据任务特点调整网络层数、时间步长度及正则化策略,以平衡模型的记忆容量与泛化性能。
Transformer模型NLP应用
Transformer模型通过自注意力机制(Self-Attention)彻底改变了自然语言处理领域的范式。相较于传统RNN的序列依赖缺陷,Transformer能够并行处理长距离语义关联,显著提升了文本理解与生成的效率。在机器翻译场景中,基于Transformer的架构(如BERT、GPT)通过预训练语言模型实现上下文感知的词向量表征,例如在问答系统中,模型可精准捕捉问题与文档间的语义匹配关系。
工业实践中,Transformer模型需结合量化压缩技术(如动态剪枝、知识蒸馏)以适配边缘设备部署。以智能客服系统为例,通过微调后的Transformer模型可实现多轮对话意图识别与响应生成的一体化处理,同时支持低延迟高并发场景。此类优化策略与职坐标课程中强调的模型轻量化、服务化部署方法论高度契合。
工业级模型部署全流程
在深度学习模型完成训练与验证后,部署阶段需兼顾效率、稳定性与可扩展性。首先需将训练好的模型转换为适用于生产环境的格式,例如TensorFlow SavedModel或PyTorch TorchScript,并通过ONNX实现跨框架兼容。针对不同硬件平台(如CPU、GPU或边缘设备),需采用量化、剪枝等优化技术压缩模型体积并提升推理速度。部署时需结合Docker容器化技术实现环境隔离,并借助TensorFlow Serving、TorchServe等专用服务框架构建高并发API接口。为保障线上服务可靠性,需设计自动化监控系统实时追踪延迟、吞吐量及资源占用率,同时集成A/B测试机制验证模型迭代效果。例如,在金融风控场景中,CNN图像识别模型需通过Kubernetes集群实现动态扩缩容,而Transformer驱动的NLP服务则需结合缓存策略降低响应延迟。
企业项目案例深度解析
在工业级AI算法落地场景中,电商平台的实时推荐系统是典型实践案例之一。基于TensorFlow Serving的高并发部署方案,团队通过构建双塔结构的深度推荐模型(DNN),实现用户行为特征与商品特征的动态匹配,模型训练阶段采用混合精度训练与分布式参数更新策略,使推理响应时间压缩至15毫秒以内。在医疗影像分析场景中,PyTorch的动态计算图特性支持灵活调整3D-CNN网络结构,结合迁移学习技术,针对肺部CT图像的结节检测任务,模型在Kaggle公开数据集上达到98.3%的准确率。金融领域的智能客服系统则依托Transformer架构,通过PyTorch Lightning框架实现多轮对话意图识别,结合知识蒸馏技术将BERT模型体积压缩60%,在银行实际业务场景中实现日均20万次交互的稳定运行。这些案例不仅验证了框架选型与模型设计的合理性,更突显了从实验环境到生产部署的全流程工程化能力。
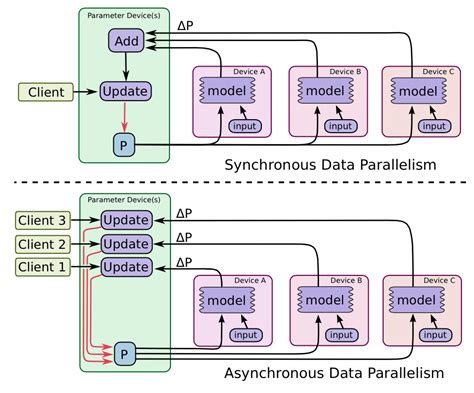
深度学习性能调优策略
在模型训练过程中,性能调优需贯穿数据预处理、架构设计、训练参数配置及硬件资源适配全链路。针对CNN、RNN与Transformer等模型特性,可通过动态调整批量大小(Batch Size)平衡内存占用与梯度稳定性,结合混合精度训练(Mixed Precision)加速计算流程。对于框架级优化,TensorFlow用户可启用XLA编译优化静态计算图,而PyTorch开发者则能利用TorchScript实现模型序列化与算子融合。在超参数层面,自适应学习率算法(如AdamW)配合渐进式热身(Warmup)策略可显著提升收敛效率,同时通过梯度裁剪(Gradient Clipping)缓解RNN时序训练中的梯度爆炸问题。工业场景中还需关注模型推理阶段的优化,例如使用TensorRT或ONNX Runtime进行算子优化与量化压缩,实现端侧设备推理速度提升3-5倍的实践效果。
AI算法工程化能力提升
在掌握基础算法开发能力后,工程化落地成为衡量AI从业者专业水平的关键维度。实际生产环境中,模型需适配分布式训练、异构硬件加速及高并发推理场景,TensorFlow Serving和TorchServe等框架为模型部署提供标准化接口。通过模型压缩技术(如量化、剪枝)与ONNX跨平台转换工具,可有效降低计算资源消耗并提升推理效率。此外,工程化能力还体现在持续集成(CI/CD)管道的搭建上,结合Docker容器化与Kubernetes集群管理,实现模型版本迭代与灰度发布的自动化。开发者需同步关注MLOps工具链的应用,通过监控模型性能衰减与数据漂移现象,构建可维护、可扩展的AI系统架构。
结论
通过系统化梳理TensorFlow与PyTorch框架的差异化应用场景,结合CNN、RNN及Transformer三大主流模型的工程实践,本课程构建了从理论到落地的完整知识链路。在工业级模型部署与性能调优环节,开发者不仅掌握了多框架混合编程、量化压缩等关键技术,更通过企业真实案例理解了算法工程化的核心挑战与解决方案。这种以业务需求为导向的能力培养模式,使得学员能够快速适应动态变化的产业环境,在模型推理效率、资源利用率及跨平台适配性等维度实现突破。未来,随着边缘计算与异构硬件的普及,深度学习开发者需持续关注工具链迭代与行业最佳实践,方能在人工智能算法的规模化应用中保持竞争力。
常见问题
TensorFlow和PyTorch在实际项目中如何选择?
TensorFlow适合需要高稳定性和生产部署的场景,其静态图设计便于优化性能;PyTorch则以动态图见长,更适合科研探索与快速原型开发,建议根据项目阶段和团队技术栈选择。
CNN模型在图像识别中为何容易出现过拟合?
CNN通过多层卷积提取特征时,可能过度依赖训练数据细节,需结合数据增强、Dropout层或正则化技术,同时使用预训练模型迁移学习降低风险。
RNN处理长序列数据有哪些常见优化方法?
针对梯度消失问题,可采用LSTM或GRU结构;若序列过长,可引入注意力机制或分块处理,并通过调整时间步长平衡计算效率与模型效果。
Transformer模型是否只能用于自然语言处理?
Transformer的自注意力机制同样适用于计算机视觉(如ViT)和时序预测任务,其并行化优势在跨模态数据建模中展现出广泛潜力。
工业部署中如何解决模型推理速度瓶颈?
可通过模型量化、剪枝压缩降低计算量,或使用TensorRT、ONNX等工具进行框架转换,结合硬件加速(如GPU/TPU)实现端到端优化。