文章目录
- 一、引言
- 1.1 监控告警的必要性
- 1.2 监控告警的基本原理
- 1.2.1 指标采集与存储
- 1.2.2 告警规则与触发机制
- 1.2.3 多渠道通知与闭环
- 二、技术选型与架构设计
- 2.1 为什么选择 Prometheus 及其生态
- 2.1.1 Prometheus 优势分析
- 2.1.2 Grafana 可视化能力
- 2.1.3 Alertmanager 灵活告警
- 2.1.4 对比:主流监控告警方案
- 2.2 系统整体架构图与组件说明
- 2.2.1 架构图
- 2.2.2 组件说明
- 2.2.3 项目配置举例
- 三、Prometheus 与 Grafana 配置实践
- 3.1 被监控服务如何暴露采集数据接口
- 3.1.1 /metrics 接口规范与实现方式
- 3.1.2 go-zero 框架的 /metrics 实现
- 3.1.3 采集指标的设计建议
- 3.2 Prometheus 配置详解
- 3.2.1 采集目标配置(scrape_configs)
- 3.2.2 告警规则配置(rule_files)
- 3.2.3 数据持久化与性能优化
- 3.3 Grafana 配置与仪表盘搭建
- 3.3.1 数据源接入 Prometheus
- 3.3.2 常用监控大盘模板
- 3.3.3 自定义告警面板
- 3.4 流程时序图
- 四、Alertmanager 告警系统配置
- 4.1 Alertmanager 的安装与集成
- 4.1.1 Alertmanager 简介
- 4.1.2 安装方式
- 4.1.3 与 Prometheus 集成
- 4.2 告警规则的编写与管理
- 4.2.1 告警规则原理
- 4.2.2 告警规则的管理
- 4.2.3 优缺点对比
- 4.3 告警分级与路由策略
- 4.3.1 路由原理
- 4.3.2 路由配置示例
- 4.3.3 分组与抑制
- 4.4 深入原理与架构分析
- 4.4.1 Alertmanager 工作流程时序图
- 五、告警通知多渠道集成实践(以邮件与短信为例)
- 5.1 邮件告警的配置与实现
- 5.1.1 邮件告警的原理
- 5.1.2 邮件发送流程与架构
- 5.1.3 base 项目邮件发送源码解析
- 5.1.4 优缺点对比
- 5.1.5 邮件告警的最佳实践
- 5.2 短信告警的配置与实现
- 5.2.1 短信告警的原理
- 5.2.2 短信发送流程与架构
- 5.2.3 base 项目短信发送源码解析
- 5.2.4 优缺点对比
- 5.2.5 短信告警的最佳实践
- 5.3 邮件与短信告警的对比与集成建议
- 六、部署使用步骤
- 6.1 被监控服务暴露采集数据接口
- 6.1.1 采集接口标准
- 6.1.2 集成方式
- 6.2 调整配置文件
- 6.2.1 Prometheus 配置
- 6.2.2 Alertmanager 配置
- 6.2.3 base 服务配置
- 6.3 启动监控相关的服务
- 6.3.1 使用 Docker Compose 启动
- 6.3.2 手动启动
- 6.4 查看 Prometheus /targets 页面,各服务的状态
- 6.5 进入 Grafana 管理页面
- 6.6 Grafana 管理页面详细配置
- 6.6.1 增加数据源
- 6.6.2 新增数据看板(Dashboard)
- 6.6.3 导入/导出 Dashboard
- 6.6.4 用户与权限管理
- 6.6.5 其它常用功能
- 6.7 进入 Alertmanager 管理页面
- 6.8 Alertmanager 管理页面使用说明
- 6.9 其它相关功能操作步骤
- 七、常见问题
- 7.1 告警降噪与误报处理
- 7.1.1 告警降噪的必要性
- 7.1.2 降噪策略
- 7.1.3 误报处理
- 7.2 多渠道告警的优先级与兜底策略
- 7.2.1 多渠道集成的必要性
- 7.2.2 优先级与兜底策略
- 7.3 监控系统的高可用与扩展性
- 7.3.1 高可用设计
- 7.3.2 扩展性设计
- 7.4 常见问题与解决方案
- 八、总结与展望
- 8.1 现有方案的优缺点分析
- 8.2 后续优化方向与新技术展望
一、引言
1.1 监控告警的必要性
在现代分布式系统和微服务架构中,服务数量众多、依赖复杂,任何一个环节的异常都可能影响整体业务的可用性。监控与告警系统的核心价值体现在:
- 业务连续性保障:及时发现服务异常,减少故障影响时间,提升系统可用性。
- 故障快速定位与响应:通过自动化告警和丰富的监控指标,第一时间定位问题根因,缩短MTTR(平均修复时间)。
- 自动化运维与降本增效:自动化监控和告警减少人工巡检,提升运维效率,降低人力成本。
对比:传统 vs. 现代监控告警
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 人工巡检 | 简单、无门槛 | 延迟高、易遗漏、不可扩展 | 小型、低频变更系统 |
| 日志轮询 | 可自动化、实现简单 | 误报多、粒度粗、无实时性 | 早期单体应用 |
| SNMP/Nagios | 适合基础设施、网络设备监控 | 配置繁琐、扩展性差 | 传统IT运维 |
| Prometheus | 云原生、自动发现、指标丰富 | 需服务端暴露接口、学习曲线 | 微服务、云原生 |
1.2 监控告警的基本原理
1.2.1 指标采集与存储
监控系统通过采集各服务暴露的指标(如CPU、内存、QPS、错误率等),并将其存储在时序数据库中。以 Prometheus 为例,服务需暴露 /metrics HTTP 接口,Prometheus 定期拉取数据。
1.2.2 告警规则与触发机制
监控系统根据预设的规则(如“CPU使用率>80% 持续5分钟”),实时评估采集到的指标,若满足条件则触发告警。
1.2.3 多渠道通知与闭环
告警触发后,系统可通过邮件、短信、IM机器人等多种渠道通知相关责任人,实现自动化闭环。
二、技术选型与架构设计
2.1 为什么选择 Prometheus 及其生态
2.1.1 Prometheus 优势分析
Prometheus 是云原生时代的事实标准监控系统,具备如下优势:
- 拉模式采集:服务端暴露
/metrics,Prometheus 定期拉取,天然适配动态扩缩容。 - 多维度指标:支持标签(Label)体系,灵活聚合、筛选。
- 强大的查询语言 PromQL:可自定义复杂的聚合、计算、告警规则。
- 生态丰富:与 Grafana、Alertmanager、各种 Exporter 无缝集成。
2.1.2 Grafana 可视化能力
Grafana 是业界最流行的可视化平台,支持多数据源(Prometheus、Elasticsearch等),可自定义仪表盘、告警面板,极大提升监控可观测性。
2.1.3 Alertmanager 灵活告警
Alertmanager 支持多种告警路由、分组、抑制、静默等高级特性,并可通过 Webhook 与自定义服务(如本项目的 base 服务)集成,实现多渠道通知。
2.1.4 对比:主流监控告警方案
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Zabbix | 适合基础设施、图形丰富 | 扩展性差、云原生支持弱 | 传统IT运维 |
| Prometheus+Grafana | 云原生、自动发现、灵活告警 | 需服务端配合、学习曲线 | 微服务、K8s |
| 云厂商监控(如阿里云云监控) | 免运维、集成度高 | 依赖厂商、定制性弱,收费 | 公有云 |
2.2 系统整体架构图与组件说明
2.2.1 架构图
2.2.2 组件说明
- Prometheus:定期拉取各服务
/metrics,存储时序数据,评估告警规则。 - Grafana:连接 Prometheus,展示可视化大盘。
- Alertmanager:接收 Prometheus 告警,路由、分组、抑制,并通过 Webhook 通知 base 服务。
- base 服务:实现邮件、短信、钉钉、企业微信等多渠道通知,作为告警通知的统一出口。
2.2.3 项目配置举例
以 docker-compose.yml 为例,定义了 Prometheus、Grafana、Alertmanager、base 服务的容器编排:
services:prometheus:image: prom/prometheus:latestvolumes:- ./build/prometheus/server/prometheus.yml:/etc/prometheus/prometheus.yml- ./build/prometheus/server/rules.yml:/etc/prometheus/rules.yml- ./data/prometheus/data:/prometheusports:- "8892:9090"networks:- chatgpt-wechat_networkgrafana:image: grafana/grafana:latestports:- "8891:3000"networks:- chatgpt-wechat_networkalertmanager:image: prom/alertmanager:latestvolumes:- ./build/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.ymlports:- "8896:9093"networks:- chatgpt-wechat_networkbase:build: ./baseports:- "8897:8897"networks:- chatgpt-wechat_network
三、Prometheus 与 Grafana 配置实践
3.1 被监控服务如何暴露采集数据接口
3.1.1 /metrics 接口规范与实现方式
Prometheus 采用“拉模式”采集监控数据。每个被监控服务需通过 HTTP 暴露 /metrics 接口,返回 Prometheus 格式的文本数据。例如:
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.000023
go_gc_duration_seconds{quantile="0.25"} 0.000031
...
每一行代表一个指标(Metric),可带有多维标签(Label),便于后续聚合和筛选。
3.1.2 go-zero 框架的 /metrics 实现
在本项目中,所有被监控服务(如 base、knowledge、wellness 等)均基于 go-zero 框架开发。go-zero 内置了 Prometheus 监控能力,开发者无需手动实现 /metrics,只需在服务启动时开启监控配置即可。
go-zero 的原理简述:
- go-zero 在服务启动时自动注册
/metrics路由。 - 内部集成了 Prometheus 官方的 go client(promhttp),自动采集 Go 运行时指标(如 GC、内存、协程数等)。
- 支持自定义业务指标埋点(如 QPS、错误率等)。
项目代码举例:
假设 base 服务的 main.go 片段如下(伪代码):
import ("github.com/zeromicro/go-zero/rest""github.com/zeromicro/go-zero/rest/httpx"
)func main() {server := rest.MustNewServer(config.RestConf)defer server.Stop()server.Start()
}
配置文件示例:
# base/etc/base.yaml
Name: base
Host: 0.0.0.0
Port: 8897
DevServer:Enabled: truePort: 8894MetricsPath: /metricsEnableMetrics: true
这样,Prometheus 就可以通过 http://base:8897/metrics 采集到 base 服务的运行时和业务指标。
3.1.3 采集指标的设计建议
- 运行时指标:如 go_gc_duration_seconds、go_memstats_alloc_bytes、go_goroutines 等,自动采集。
- 业务指标:如接口 QPS、错误率、延迟分布等。go-zero 支持自定义埋点,可通过 prometheus client 库注册自定义指标。
- 标签设计:合理使用 label(如 job、app、env、instance),便于多维度聚合和筛选。
3.2 Prometheus 配置详解
3.2.1 采集目标配置(scrape_configs)
Prometheus 通过 scrape_configs 配置采集目标。以项目中 build/prometheus/server/prometheus.yml 为例:
scrape_configs:- job_name: 'base'metrics_path: '/metrics'static_configs:- targets: [ 'base:8897' ]labels:job: baseapp: baseenv: pro
job_name:采集任务名,便于分组和查询。metrics_path:采集路径,通常为/metrics。targets:目标服务地址(可为容器名:端口)。labels:为采集到的所有指标自动打标签,便于后续聚合。
项目完整配置片段:
scrape_configs:- job_name: 'knowledge'metrics_path: '/metrics'static_configs:- targets: [ 'knowledge:8894' ]labels:job: knowledgeapp: knowledgeenv: pro# ... 其他服务同理
3.2.2 告警规则配置(rule_files)
Prometheus 支持自定义告警规则,规则文件通过 rule_files 引入。例如:
rule_files:- "rules.yml"
rules.yml 示例(项目中的 build/prometheus/server/rules.yml):
groups:- name: examplerules:- alert: ServiceDownexpr: up == 0for: 1mlabels:severity: criticalannotations:summary: "服务 {{ $labels.job }} 已停止"description: "服务 {{ $labels.job }} 在 {{ $labels.instance }} 已停止超过 1 分钟"
expr:PromQL 表达式,up == 0表示服务不可达。for:持续时间,避免瞬时抖动误报。labels/annotations:自定义标签和告警描述。
3.2.3 数据持久化与性能优化
--storage.tsdb.retention.time=15d:数据保留15天。--storage.tsdb.retention.size=10GB:最大占用空间10GB。- 建议将数据目录挂载到独立磁盘,提升读写性能。
docker-compose.yml 配置片段:
volumes:- ./data/prometheus/data:/prometheus
command:- '--storage.tsdb.retention.time=15d'- '--storage.tsdb.retention.size=10GB'
3.3 Grafana 配置与仪表盘搭建
3.3.1 数据源接入 Prometheus
Grafana 通过 Web UI 添加 Prometheus 数据源,配置 Prometheus 服务地址(如 http://prometheus:9090)。
3.3.2 常用监控大盘模板
- 系统资源监控(CPU、内存、磁盘、网络)
- 服务健康状态(up、QPS、错误率)
- 告警面板(当前活跃告警、历史告警趋势)
3.3.3 自定义告警面板
Grafana 支持基于 PromQL 查询自定义图表和告警。例如:
sum(rate(http_requests_total{job="base"}[5m]))
可用于展示 base 服务的 QPS。
3.4 流程时序图
四、Alertmanager 告警系统配置
4.1 Alertmanager 的安装与集成
4.1.1 Alertmanager 简介
Alertmanager 是 Prometheus 官方提供的告警管理组件,负责接收 Prometheus 发送的告警信息,并根据配置进行分组、抑制、路由和通知。它支持多种通知方式,如邮件、短信、钉钉、企业微信等。
4.1.2 安装方式
Alertmanager 支持多种部署方式,常见有二进制包、Docker、Kubernetes 等。以 Docker 为例,项目中的 ./build 目录下通常包含 docker-compose.yml,可直接拉起 Prometheus、Alertmanager、Grafana 等服务。
示例:docker-compose.yml 片段
alertmanager:image: prom/alertmanager:v0.25.0container_name: alertmanagervolumes:- ./alertmanager:/etc/alertmanagerports:- "9093:9093"command:- '--config.file=/etc/alertmanager/alertmanager.yml'
4.1.3 与 Prometheus 集成
Prometheus 通过 alerting 配置将告警推送到 Alertmanager。
示例:prometheus.yml 片段
alerting:alertmanagers:- static_configs:- targets:- 'alertmanager:9093'
优缺点对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 内置告警 | 配置简单,集成度高 | 功能有限,扩展性差 |
| Alertmanager | 支持多渠道、分组、抑制、路由 | 配置复杂,学习成本略高 |
4.2 告警规则的编写与管理
4.2.1 告警规则原理
Prometheus 通过规则文件(如 alert.rules.yml)定义告警条件,定期评估表达式,满足条件时生成告警事件。
示例:alert.rules.yml
groups:- name: service-statusrules:- alert: ServiceDownexpr: up{job="my-service"} == 0for: 1mlabels:severity: criticalannotations:summary: "服务 {{ $labels.instance }} 宕机"description: "{{ $labels.instance }} 已经宕机超过1分钟"
4.2.2 告警规则的管理
- 集中管理:所有规则集中在一个或多个 YAML 文件,便于版本控制。
- 动态加载:Prometheus 支持热加载规则,减少重启带来的监控盲区。
4.2.3 优缺点对比
| 方式 | 优点 | 缺点 |
|---|---|---|
| 静态规则文件 | 易于版本管理,直观 | 变更需 reload,灵活性差 |
| 动态配置 | 灵活,支持自动化 | 复杂度高,易出错 |
4.3 告警分级与路由策略
4.3.1 路由原理
Alertmanager 通过 alertmanager.yml 配置路由树,根据告警标签(如 severity)分发到不同的通知渠道,实现分级告警和多渠道通知。
核心流程图
4.3.2 路由配置示例
示例:alertmanager.yml 片段
route:group_by: ['alertname', 'severity']group_wait: 30sgroup_interval: 5mrepeat_interval: 1hreceiver: 'default'routes:- match:severity: 'critical'receiver: 'mail'- match:severity: 'warning'receiver: 'dingtalk'- match:severity: 'info'receiver: 'wechat'
receivers:- name: 'mail'email_configs:- to: 'ops@example.com'- name: 'dingtalk'webhook_configs:- url: 'http://base:8080/notify/dingtalk'- name: 'wechat'webhook_configs:- url: 'http://base:8080/notify/wechat'
4.3.3 分组与抑制
- 分组:相同类型告警合并,减少通知风暴。
- 抑制:如主机宕机时,自动抑制该主机上的其他服务告警,避免重复告警。
4.4 深入原理与架构分析
4.4.1 Alertmanager 工作流程时序图
五、告警通知多渠道集成实践(以邮件与短信为例)
5.1 邮件告警的配置与实现
5.1.1 邮件告警的原理
邮件告警是最常见的系统告警通知方式之一。其基本原理是:当监控系统(如 Prometheus + Alertmanager)检测到异常后,通过 Webhook 或 SMTP 协议,将告警信息发送到邮件服务,由邮件服务将告警内容推送到指定收件人邮箱。
在本项目中,邮件发送由 base 服务的 EmailSender 组件实现,Alertmanager 通过 webhook 调用 base 服务的邮件接口,base 服务再通过 SMTP 协议发送邮件。
5.1.2 邮件发送流程与架构
核心流程图
5.1.3 base 项目邮件发送源码解析
以 base/infrastructure/integration/mail/email.go 为例,邮件发送的核心流程如下:
- 读取配置(发件人、收件人、SMTP服务器等)
- 构建邮件内容(支持 HTML 格式,主题支持 Base64 编码防止乱码)
- 通过 TLS 连接 SMTP 服务器,进行认证
- 发送邮件内容
关键代码片段说明:
// 构建邮件头
headers["From"] = s.SvcCtx.Config.Email.From
headers["To"] = emailTo
headers["Subject"] = "=?UTF-8?B?" + base64.StdEncoding.EncodeToString([]byte(subject)) + "?="
headers["Content-Type"] = "text/html; charset=UTF-8"// 发送邮件
auth := smtp.PlainAuth("", s.SvcCtx.Config.Email.Username, s.SvcCtx.Config.Email.Password, s.SvcCtx.Config.Email.Host)
conn, err := tls.Dial("tcp", fmt.Sprintf("%s:%d", s.SvcCtx.Config.Email.Host, s.SvcCtx.Config.Email.Port), tlsConfig)
client, err := smtp.NewClient(conn, s.SvcCtx.Config.Email.Host)
client.Auth(auth)
client.Mail(s.SvcCtx.Config.Email.From)
client.Rcpt(emailTo)
w, err := client.Data()
w.Write([]byte(message))
w.Close()
5.1.4 优缺点对比
| 方式 | 优点 | 缺点 |
|---|---|---|
| 邮件告警 | 普及率高,易于追溯,支持富文本 | 可能被忽略,延迟较高,依赖外部邮箱服务 |
5.1.5 邮件告警的最佳实践
- 配置多收件人,避免单点失效
- 邮件内容结构化,便于自动化处理
- 主题和内容中包含环境、时间、告警级别等关键信息
- 配置 SMTP 认证和 TLS,保障安全性
5.2 短信告警的配置与实现
5.2.1 短信告警的原理
短信告警适用于紧急、强提醒场景。其原理是:监控系统触发告警后,通过 webhook 调用 base 服务,base 服务再调用第三方短信平台(如腾讯云短信)API,将告警内容发送到指定手机号。
5.2.2 短信发送流程与架构
核心流程图
5.2.3 base 项目短信发送源码解析
以 base/infrastructure/integration/sms/tencent.go 为例,短信发送的核心流程如下:
- 读取配置(手机号、签名、模板ID、API密钥等)
- 构造请求体,序列化为 JSON
- 设置鉴权头,调用第三方短信平台 API
- 解析响应,判断发送结果
关键代码片段说明:
requestBody := map[string]interface{}{"mobiles": mobiles,"sign_name": s.SvcCtx.Config.MSG.SignName,"template_id": s.SvcCtx.Config.MSG.TemplateId,
}
jsonData, err := json.Marshal(requestBody)
headers := map[string]string{"Content-Type": "application/json","X-Auth-Key": s.SvcCtx.Config.MSG.Key,
}
response, err := util.Post(s.SvcCtx.Config.MSG.Url, jsonData, headers)
json.Unmarshal(response, &result)
if code, ok := result["code"].(float64); ok && code != 0 {return errors.New("message send error")
}
5.2.4 优缺点对比
| 方式 | 优点 | 缺点 |
|---|---|---|
| 短信告警 | 及时性强,强提醒,适合紧急场景 | 成本高,内容有限,依赖第三方平台 |
5.2.5 短信告警的最佳实践
- 只对高优先级、紧急告警发送短信,避免骚扰
- 配置多手机号,支持多运维人员轮值
- 监控短信发送状态,失败时自动重试或切换渠道
- 合理设置短信模板,简明扼要传达关键信息
5.3 邮件与短信告警的对比与集成建议
| 维度 | 邮件告警 | 短信告警 |
|---|---|---|
| 及时性 | 一般 | 高 |
| 成本 | 低 | 高 |
| 内容丰富度 | 高(支持富文本) | 低(仅文本) |
| 适用场景 | 日常、非紧急告警 | 紧急、核心告警 |
| 易用性 | 易于追溯、归档 | 适合即时提醒 |
集成建议:
- 日常告警优先邮件,紧急告警短信+邮件双通道
- 可通过 Alertmanager 路由策略灵活配置不同级别告警的通知方式
六、部署使用步骤
6.1 被监控服务暴露采集数据接口
6.1.1 采集接口标准
被监控服务需暴露 Prometheus 兼容的 HTTP metrics 接口(如 /metrics),输出格式为纯文本,内容为各类监控指标。
示例:
# HELP http_requests_total The total number of HTTP requests.
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1027
6.1.2 集成方式
- Go 服务可用 prometheus/client_golang 集成,go-zero框架默认会集成
- 其它语言均有官方/社区支持
6.2 调整配置文件
6.2.1 Prometheus 配置
编辑 prometheus.yml,添加被监控服务的 scrape 配置:
scrape_configs:- job_name: 'my-service'static_configs:- targets: ['my-service:8080']
6.2.2 Alertmanager 配置
编辑 alertmanager.yml,配置通知路由、接收人等(详见前文第四章)。
6.2.3 base 服务配置
在 base 服务的配置文件(如 etc/base.yaml)中,填写邮件、短信等通知渠道的参数。
6.3 启动监控相关的服务
6.3.1 使用 Docker Compose 启动
在 build 目录下执行:
docker-compose up -d
会自动启动 Prometheus、Alertmanager、Grafana、base 服务等。
6.3.2 手动启动
也可分别进入各服务目录,使用二进制或源码启动。
6.4 查看 Prometheus /targets 页面,各服务的状态
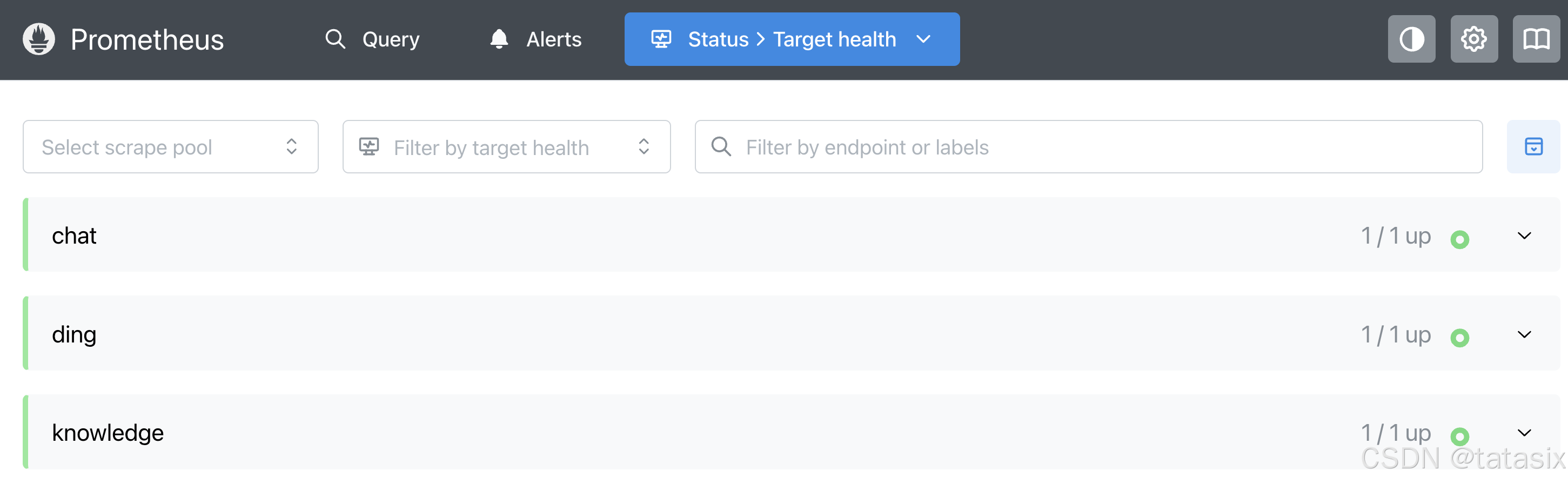
- 浏览器访问 http://localhost:9090/targets
- 检查所有被监控服务的状态是否为“UP”
- 若有异常,检查服务是否暴露
/metrics,网络连通性,配置文件是否正确
6.5 进入 Grafana 管理页面
- 浏览器访问 http://localhost:3000/
- 默认账号密码通常为
admin/admin,首次登录需修改密码
6.6 Grafana 管理页面详细配置
6.6.1 增加数据源
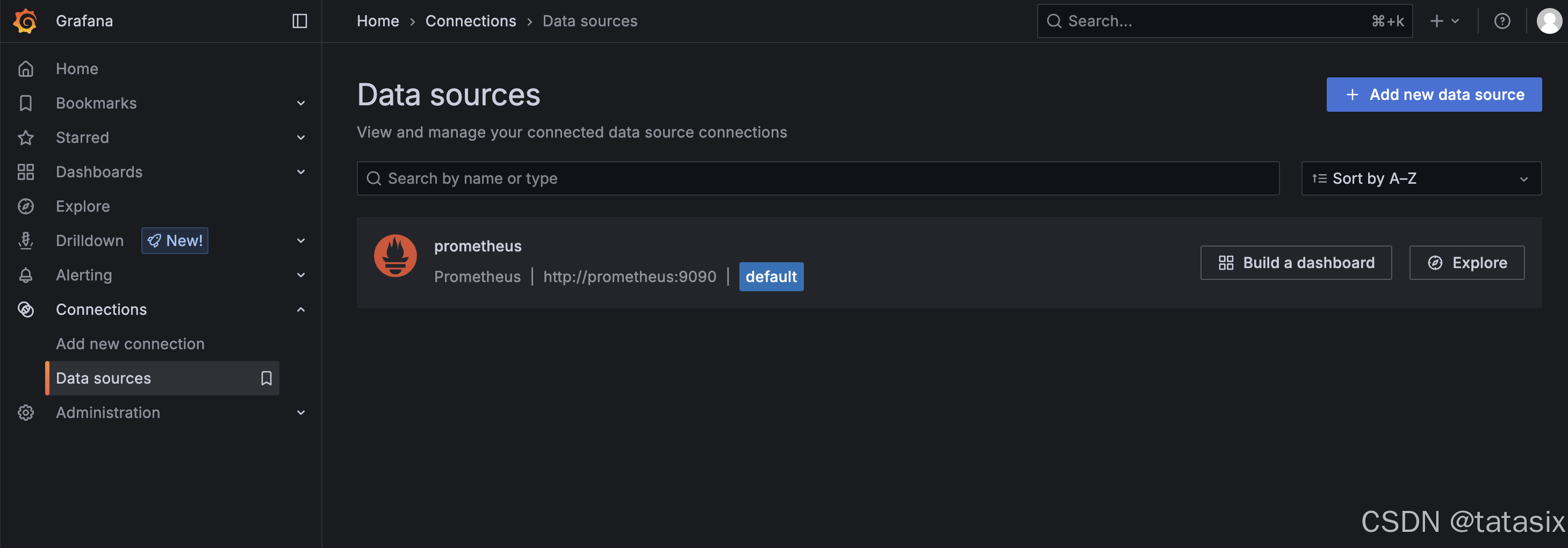
- 进入左侧菜单“Connections”图标 → “Data Sources”
- 点击“Add nw data source”
- 选择“Prometheus”
- 在“URL”中填写 Prometheus 地址(如
http://prometheus:9090) - 点击“Save & Test”确保连接成功
6.6.2 新增数据看板(Dashboard)
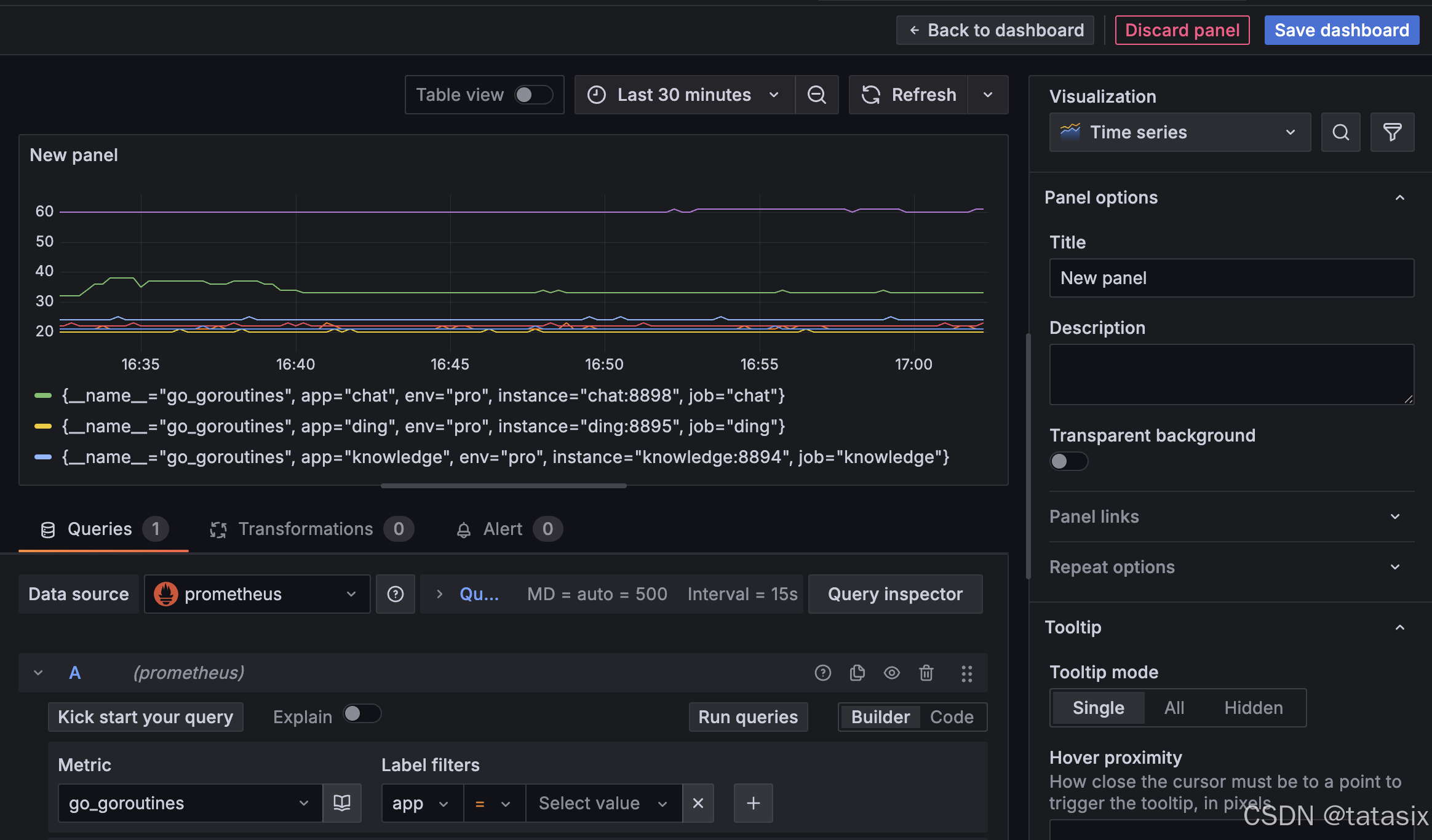
- 左侧菜单点击“Dashboard”
- 点击“new”
- 在“Query”栏选择数Metric,Label 等
- 点击查询,就能看到图片
- 右边可以配置图表类型(折线、柱状、饼图等),设置标题、单位、阈值等
- 点击“Save dashboard”保存面板
- 可通过“Settings”设置 Dashboard 的共享、导出、定时刷新等
6.6.3 导入/导出 Dashboard
- 导入:点击“+” → “Import”,粘贴 JSON 或上传文件
- 导出:Dashboard 页面右上角“设置” → “JSON Model” → “Export”
6.6.4 用户与权限管理
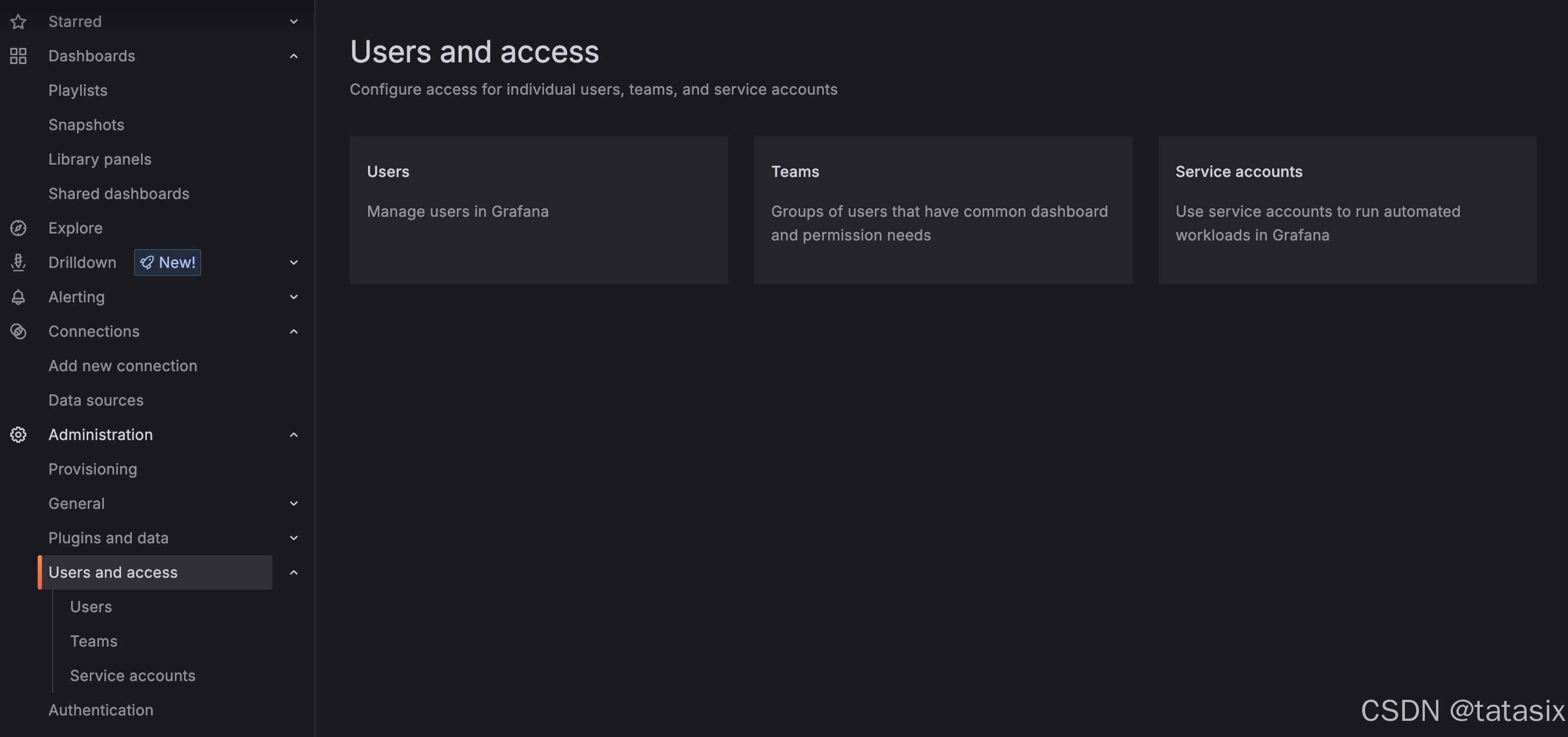
- “Administration” → “Users and access” → ”Users” 可添加/管理用户
- “Configuration” → “Users and access” → “Teams” 可分组管理权限
6.6.5 其它常用功能
- 设置告警规则(Alert):在面板中配置阈值,触发时可联动通知
- 定时快照、邮件报告等
6.7 进入 Alertmanager 管理页面
- 浏览器访问 http://localhost:9093/
- 可查看当前活跃告警、历史告警、分组、路由等信息
6.8 Alertmanager 管理页面使用说明
- Silence(静默):可临时屏蔽某类告警,避免重复通知
- Status:查看 Alertmanager 集群状态、配置加载情况
- Receivers:查看所有通知渠道配置
- 告警详情:点击告警可查看标签、注释、发送历史等
6.9 其它相关功能操作步骤
- Prometheus 查询与调试:在 Prometheus 页面
/query输入 PromQL 查询,实时查看指标数据 - 日志排查:各服务容器/进程日志可用于排查启动、采集、通知等问题
- 配置热加载:Prometheus、Alertmanager 支持 SIGHUP 信号或 API 热加载配置,无需重启
- 备份与恢复:定期备份配置文件、Grafana Dashboard JSON,便于迁移和恢复
七、常见问题
7.1 告警降噪与误报处理
7.1.1 告警降噪的必要性
在实际生产环境中,监控系统如果配置不当,极易出现“告警风暴”——即短时间内大量重复、无效或低价值告警,导致运维人员疲于应付,甚至忽略真正的核心问题。
7.1.2 降噪策略
- 告警分组:通过 Alertmanager 的
group_by、group_wait等参数,将同一类告警合并,减少通知次数。 - 抑制规则:如主机宕机时,自动抑制该主机上其他服务的告警,避免重复提醒。
- 告警级别划分:将告警分为 critical、warning、info 等不同级别,仅对高优先级告警采用强提醒(如短信)。
- 告警恢复通知:配置告警恢复通知,便于追踪问题全生命周期。
流程图:告警降噪处理
7.1.3 误报处理
- 合理设置阈值:避免因短暂波动触发告警,可通过
for参数设置持续时间。 - 定期回顾告警规则:结合历史数据,优化和调整不合理的告警规则。
- 自动化测试告警规则:上线前通过模拟数据验证告警准确性。
7.2 多渠道告警的优先级与兜底策略
7.2.1 多渠道集成的必要性
单一渠道(如仅邮件或仅短信)存在被忽略、服务不可用等风险。多渠道集成可提升告警的可靠性和到达率。
7.2.2 优先级与兜底策略
- 主渠道+备份渠道:如优先短信,短信失败自动切换邮件或钉钉。
- 分级通知:高优先级多渠道并发,低优先级仅邮件。
- 失败重试与告警确认:base 服务可实现通知失败自动重试,或通过接口回调确认告警已被处理。
时序图:多渠道兜底流程
7.3 监控系统的高可用与扩展性
7.3.1 高可用设计
- Prometheus 多实例部署:主备或联邦集群,避免单点故障。
- Alertmanager 集群:支持多节点 HA,状态自动同步。
- base 服务冗余部署:多实例+负载均衡,保障通知服务可用性。
7.3.2 扩展性设计
- 插件化通知渠道:base 服务采用接口抽象,便于后续扩展钉钉、企业微信等新渠道。
- 配置中心与动态热加载:支持在线变更告警规则和通知配置,提升运维效率。
7.4 常见问题与解决方案
| 问题类型 | 现象 | 解决建议 |
|---|---|---|
| 告警延迟 | 邮件/短信到达慢 | 检查网络、SMTP/短信平台状态 |
| 告警丢失 | 未收到告警 | 检查路由配置、收件人、API限流 |
| 误报频发 | 大量无效告警 | 优化规则、增加抑制、调整阈值 |
| 通知失败 | 邮件/短信发送接口报错 | 增加重试、切换备份渠道 |
八、总结与展望
8.1 现有方案的优缺点分析
优点
- 灵活性高:Prometheus+Alertmanager+base 服务架构,支持多种通知渠道,易于扩展。
- 解耦性强:监控、告警、通知分层设计,便于独立维护和升级。
- 自动化程度高:支持自动分组、抑制、分级路由,减少人工干预。
不足
- 配置复杂:多组件协作,初期配置和调优成本较高。
- 依赖外部服务:如邮件、短信平台,需关注其可用性和限流策略。
- 告警泛滥风险:规则设计不当易导致告警风暴,需要持续优化。
8.2 后续优化方向与新技术展望
- 更多通知渠道集成:如钉钉、企业微信、飞书 等,提升多样性和可靠性。
- 智能告警:引入机器学习/异常检测算法,自动识别异常模式,减少误报。
- 自愈与自动化运维:告警触发自动化脚本,实现部分问题的自愈闭环。
- 可观测性一体化:与日志、链路追踪等系统集成,形成全栈可观测平台。
- 可视化与报表:增强告警统计、趋势分析和报表功能,辅助运维决策。
完整项目地址