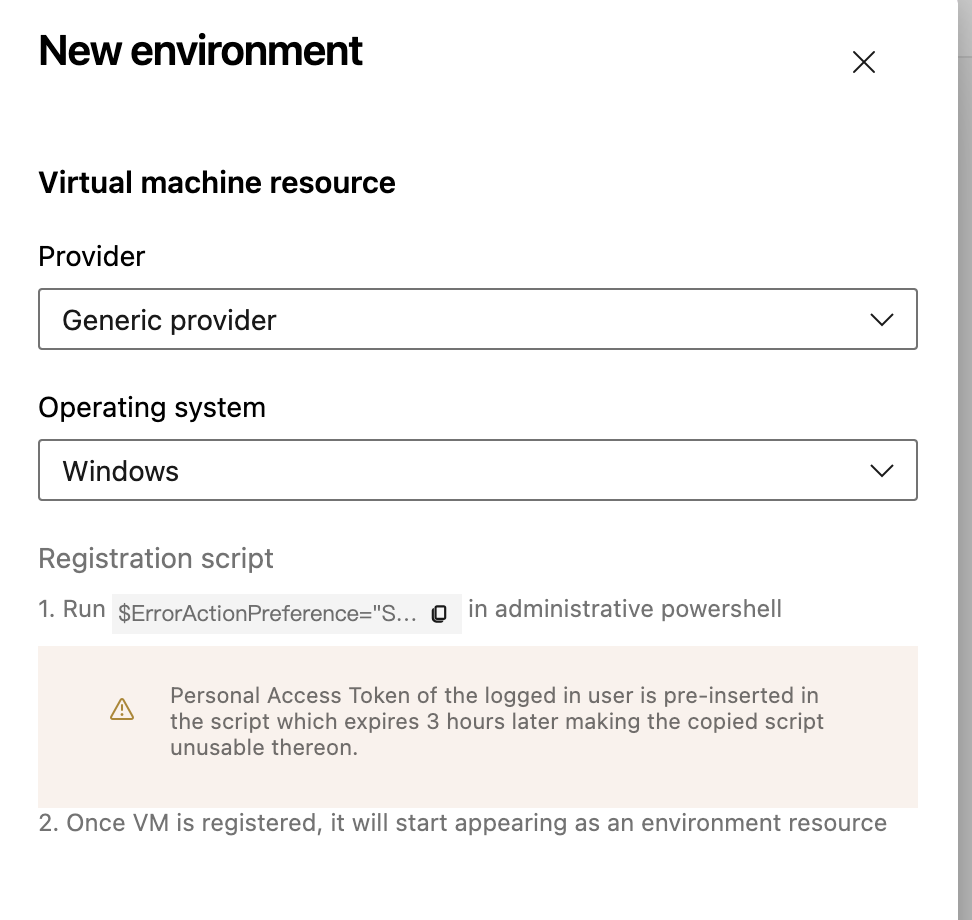
说明:这是一个机器学习实战项目(附带数据+代码+文档),如需数据+代码+文档可以直接到文章最后关注获取。

1.项目背景
随着深度学习技术的迅猛发展,循环神经网络(RNN)及其变体LSTM(Long Short-Term Memory)在处理序列数据方面表现出卓越的能力。LSTM通过其独特的记忆单元和门控机制,能够有效捕捉时间序列中的长期依赖关系,因此被广泛应用于自然语言处理、语音识别、金融预测等分类任务中。然而,LSTM模型在训练过程中同样面临一些挑战,例如对初始权值和阈值敏感、容易陷入局部最优解以及训练时间较长等问题,这些问题可能影响模型的分类性能和实际应用效果。
为了提升LSTM模型的性能,研究者们尝试将智能优化算法引入到模型的训练过程中。粒子群优化算法(PSO)作为一种基于群体智能的全局优化方法,因其简单高效、参数少且易于实现的特点,成为优化神经网络的重要工具之一。然而,传统PSO算法可能存在早熟收敛或搜索效率低下的问题。为此,改进的P-PSO(带压缩因子的粒子群优化算法)应运而生,通过调整粒子的速度更新机制,能够更好地平衡全局探索与局部开发能力,从而为LSTM模型的优化提供更加稳定和高效的解决方案。
本项目旨在结合P-PSO算法与LSTM模型,构建一个高性能的分类模型,用于解决复杂的序列分类任务。通过使用P-PSO优化LSTM模型的初始权值和阈值,提升模型的分类精度和泛化能力,同时加快收敛速度并降低陷入局部最优的风险。该项目不仅具有重要的理论研究价值,还能够在实际场景中广泛应用,如文本情感分类、语音信号分类和时间序列异常检测等领域,为相关行业提供更加智能化的数据分析和决策支持工具。
本项目通过Python实现P-PSO优化算法优化循环神经网络LSTM分类模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因变量 |
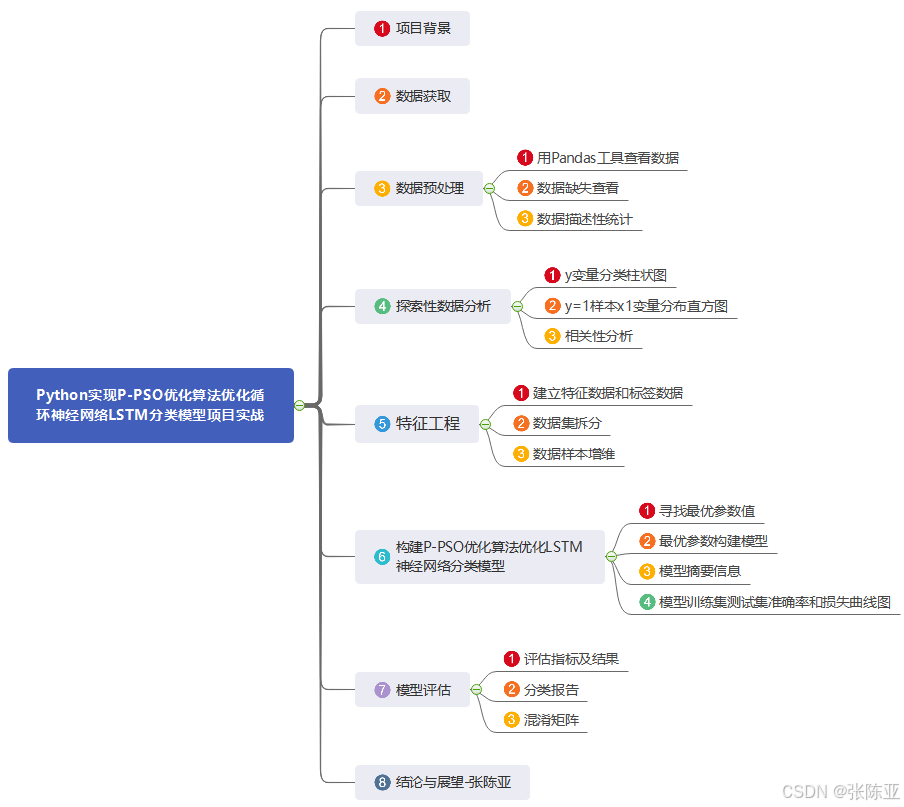
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

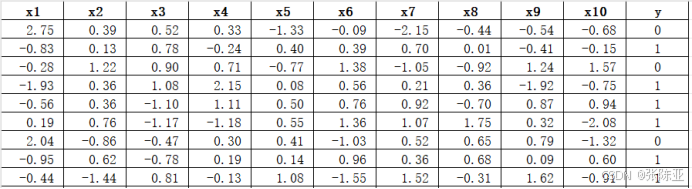
3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

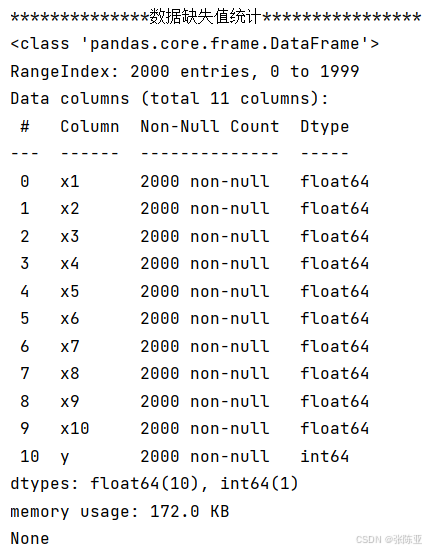
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
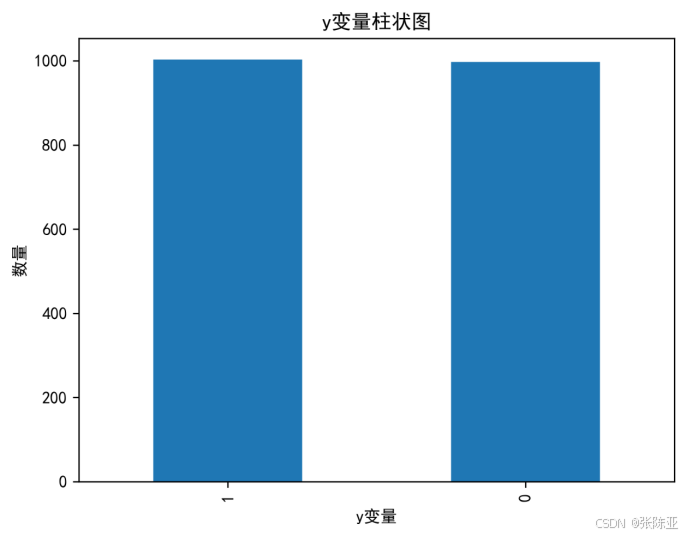
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
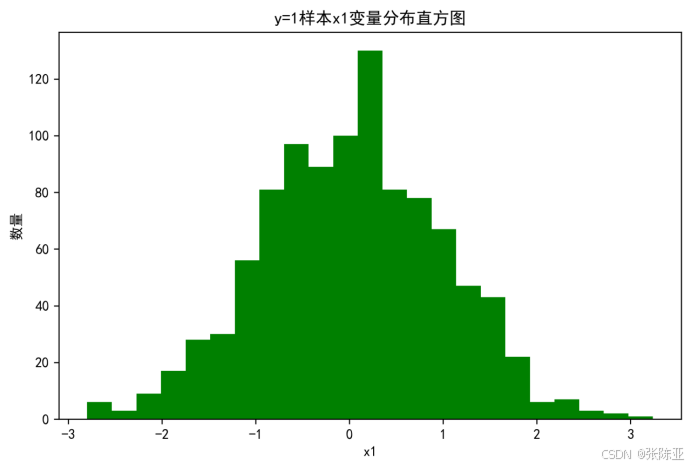
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
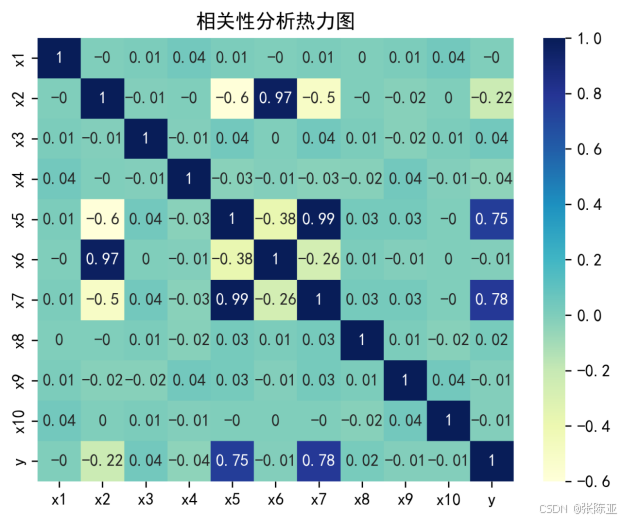
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

5.3 数据样本增维
为满足LSTM建模的需要,对特征样本进行增加一个维度,增维的关键代码如下:

6.构建P-PSO优化算法优化LSTM神经网络分类模型
主要通过Python实现P-PSO优化算法优化LSTM神经网络分类模型算法,用于目标分类。
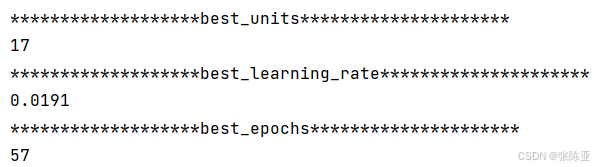
6.1 寻找最优参数值
最优参数值:
6.2 最优参数构建模型
这里通过最优参数构建分类模型。
| 模型名称 | 模型参数 |
| LSTM神经网络分类模型 | units=best_units |
| optimizer = tf.keras.optimizers.Adam(best_learning_rate) | |
| epochs=best_epochs |
6.3 模型摘要信息
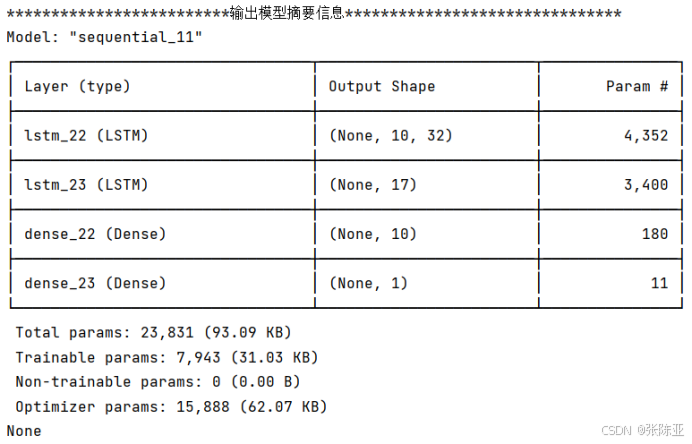
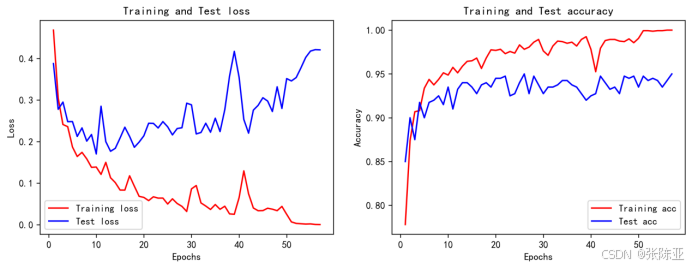
6.4 模型训练集测试集准确率和损失曲线图
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| LSTM神经网络分类模型 | 准确率 | 0.9500 |
| 查准率 | 0.9533 | |
| 查全率 | 0.9533 | |
| F1分值 | 0.9533 | |
从上表可以看出,F1分值为0.9533,说明P-PSO优化算法优化的LSTM神经网络模型效果良好。
关键代码如下:

7.2 分类报告
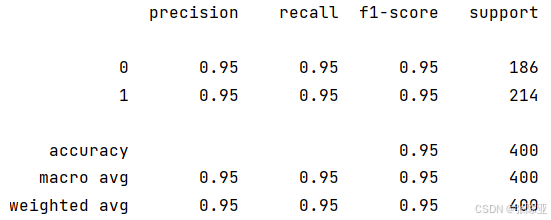
从上图可以看出,分类为0的F1分值为0.95;分类为1的F1分值为0.95。
7.3 混淆矩阵
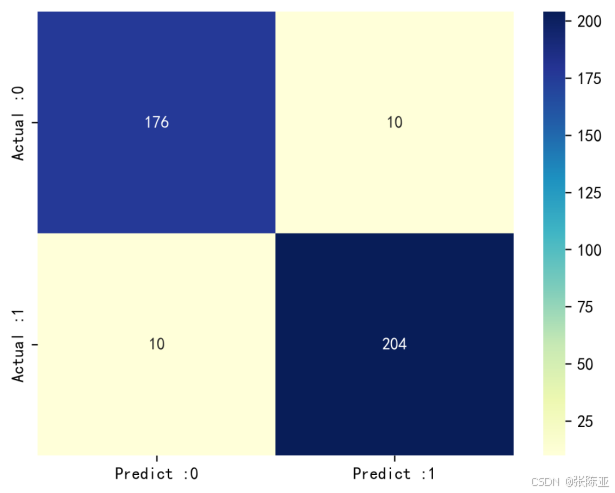
从上图可以看出,实际为0预测不为0的 有10个样本,实际为1预测不为1的 有10个样本,模型效果良好。
8.结论与展望
综上所述,本文采用了通过P-PSO优化算法优化LSTM神经网络分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。