一. 蓝耘元生代 MaaS介绍及简单使用
背景介绍
创新产品定位:
- 蓝耘元生代 MaaS 平台于 2024 年 11 月 28 日推出,非传统智算平台,以资源聚合能力整合上下游资源,为用户提供优质全面服务。
核心模块功能:
- 集成
智算算力调度、AI 协作开发、应用市场三大模块。前者含裸金属与容器调度模式;AI 协作开发分前台、中台、后台,满足不同角色需求;应用市场汇聚多元应用,适配各类场景。
生态构建目标:
- 平台通过以上优势,致力于打造开放
共赢生态,推动人工智能技术在各领域深度应用与发展。
注册使用
- 首先点击链接:
蓝耘平台
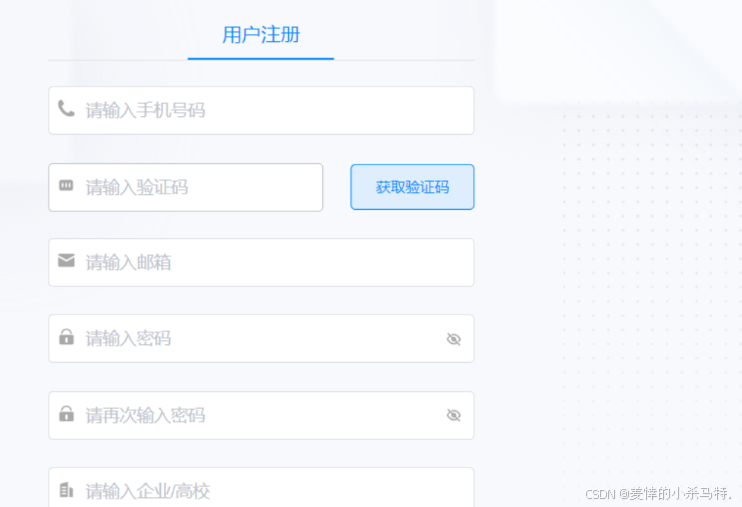
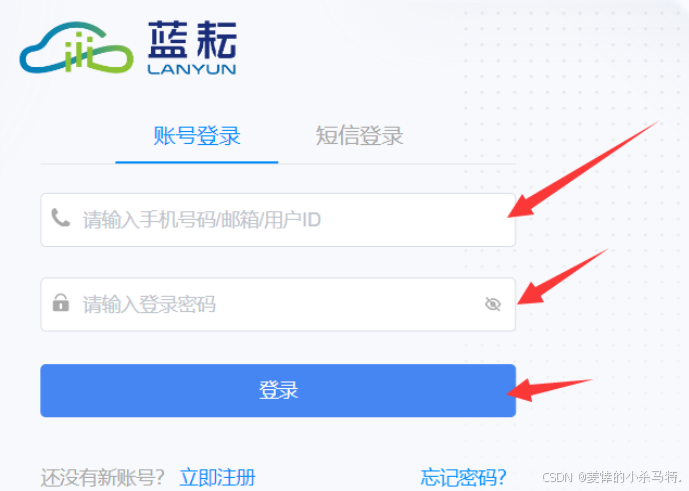
- 然后完成登录
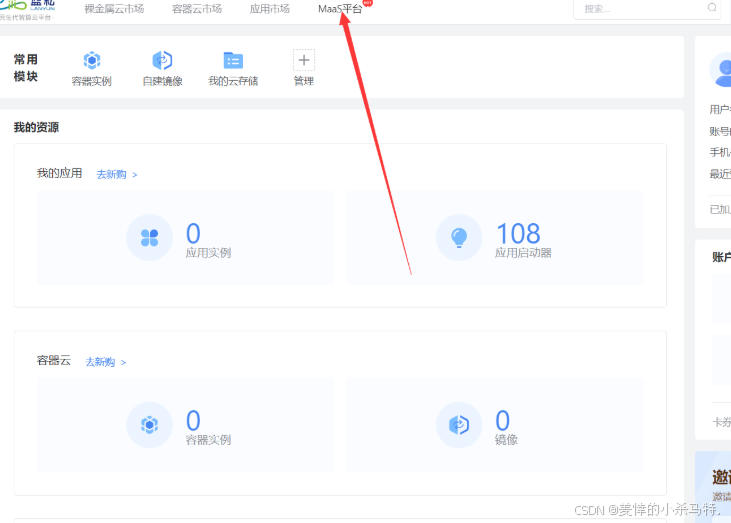
- 进入后来到模型市场:
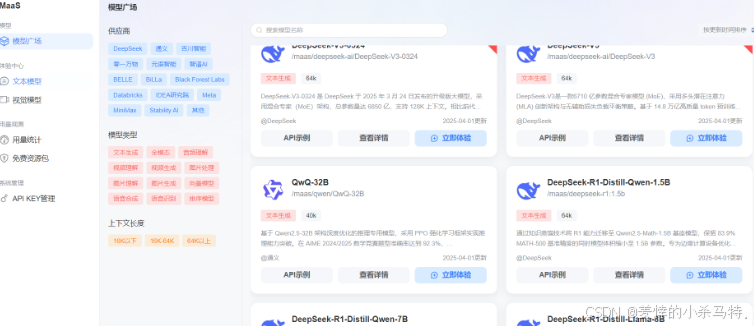
- 视觉文本模型可供选择:
- 对文本模型进行使用:

- 对应视觉模型体验:
- 如API调用也可查看关于API示例:
二.蓝耘平台 API 调用基础
注册与 API Key 获取
-
访问蓝耘元生代 MaaS 平台官网,点击 “注册” 按钮,填写手机号码、验证码、用户名、密码及邮箱等信息完成注册。
-
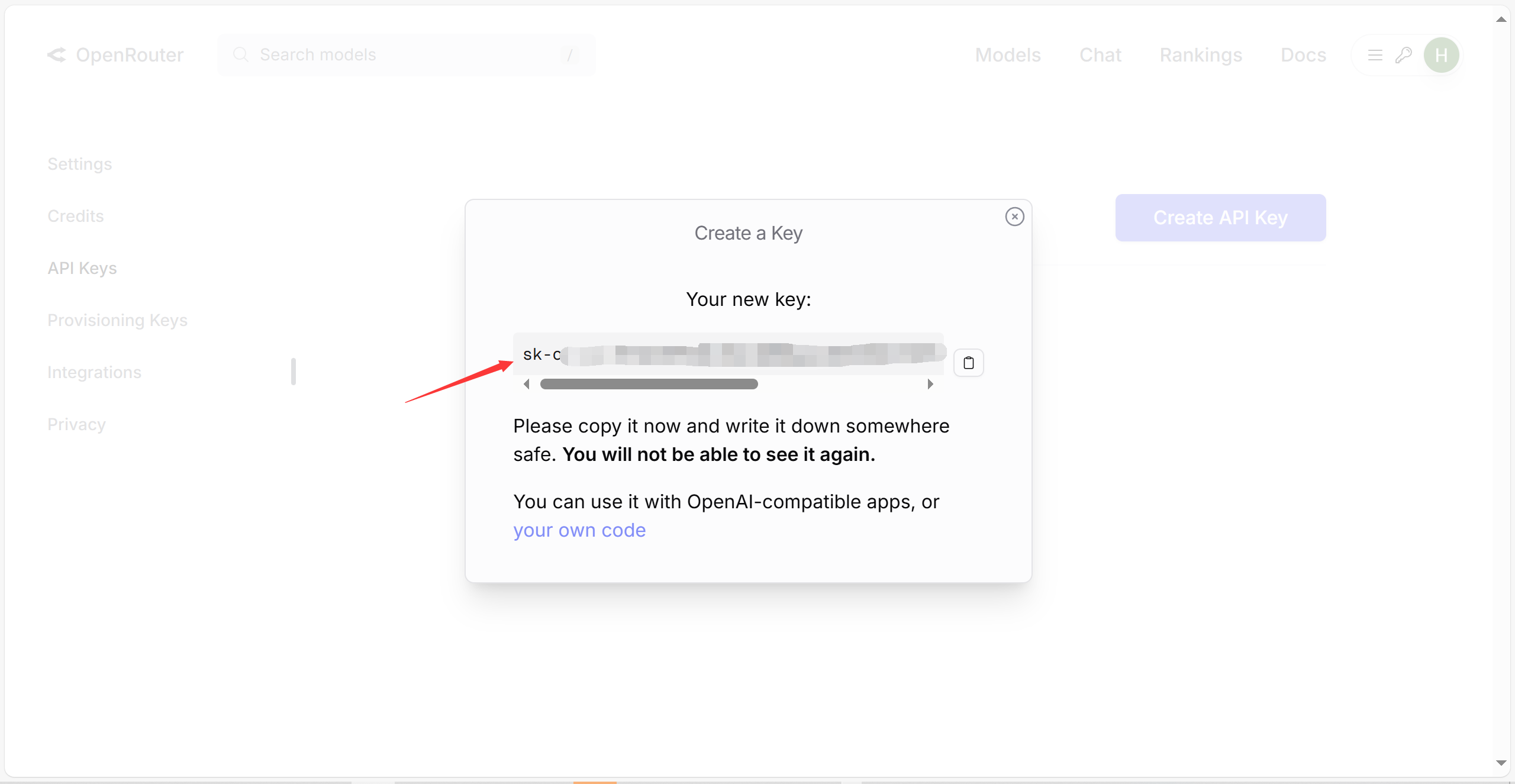
登录后,进入控制台找到 “MaaS 平台” 选项,点击 “创建 API KEY” 获取专属 API Key。
这个 API Key 是调用平台 API 的唯一凭证,务必妥善保管,切勿泄露或公开分享,否则可能导致 Token 资源被恶意使用。
调用方式详解
- Python 以其简洁的语法和丰富的库,成为调用蓝耘平台 API 的常用语言。首先,使用 pip 安装 openai 库,因为蓝耘平台提供 OpenAI 兼容接口:
pip install openai
安装完成后,使用 DeepSeek - R1 模型进行对话的 Python 代码:
from openai import OpenAI
# 构造client,填入你的API Key和蓝耘平台的base_url
client = OpenAI(api_key="sk - xxxxxxxxxxx", base_url="https://maas - api.lanyun.net/v1")
# 发起请求
chat_completion = client.chat.completions.create(model="/maas/deepseek - ai/DeepSeek - R1",messages=({"role": "user", "content": "如何提高Python代码的运行效率"})
)
print(chat_completion.choices[0].message.content)
-
在这段代码中,首先通过OpenAI类创建客户端实例,传入
API Key和平台的基础URL。 -
然后使用client.chat.completions.create方法发起对话请求,指定模型为/maas/deepseek - ai/DeepSeek - R1,并传入用户的问题消息。
-
最后打印模型返回的回答内容。每一次对话请求都会消耗一定数量的 Token,具体消耗数量与模型、输入输出的长度等因素相关 ,
由于平台赠送超千万 Token,开发者有充足资源进行各类对话测试。
如果希望实现流式响应,逐块获取模型的回答,可使用下面的模式:
from openai import OpenAI
client = OpenAI(api_key="sk - xxxxxxxxxxx", base_url="https://maas - api.lanyun.net/v1")
stream = True
chat_completion = client.chat.completions.create(model="/maas/deepseek - ai/DeepSeek - R1",messages=({"role": "user", "content": "介绍一下中国的传统节日"}),stream=stream
)
if stream:for chunk in chat_completion:if hasattr(chunk.choices[0].delta, 'content'):if chunk.choices[0].delta.content:print(chunk.choices[0].delta.content, end="")
-
流式响应能让用户更快看到模型的部分回答,提升交互体验,同时在处理长文本回答时,可避免一次性返回大量数据导致的性能问题。
-
同样消耗 Token,开发者可根据需求灵活选择调用方式。
cURL 命令调用
cURL 是一个强大的命令行工具,也可用于调用蓝耘平台 API。使用 cURL 调用 DeepSeek - R1 模型进行对话的命令:
curl https://maas - api.lanyun.net/v1/chat/completions \-H "Content - Type: application/json" \-H "Authorization: Bearer sk - xxxxxxxxxxx" \-d '{"model": "/maas/deepseek - ai/DeepSeek - R1","messages": [{"role": "user","content": "推荐几本经典的计算机书籍"}]
}'
- 在这个命令中,
https://maas - api.lanyun.net/v1/chat/completions是 API 的端点地址。 -H "Content - Type: application/json"设置请求头,表明请求体数据为 JSON 格式。-H "Authorization: Bearer sk - xxxxxxxxxxx"用于身份验证。sk - xxxxxxxxxxx需替换为实际的API Key。-d后面跟着的JSON格式数据,指定了要使用的模型和用户输入的消息。
通过 cURL 命令,无需依赖特定编程语言环境,就能快速测试 API 接口,每次调用同样会消耗 Token,方便开发者在不同场景下灵活使用。
三.核心应用场景深度实践
高效知识库建立
资料采集与清洗
- 知识库建立的第一步是资料采集,可从公司内部文档、行业报告、学术论文、网络资讯等多渠道获取资料。采集后,使用 Python 的re库(正则表达式库)、pandas库等进行清洗。
- 例如,使用re库去除 HTML 标签:
import re
html_text = "<p>这是一段包含<html>标签的文本</p>"
clean_text = re.sub('<[^<]+?>', '', html_text)
print(clean_text)
- 上面通过re.sub函数,利用正则表达式匹配并删除所有 HTML 标签,得到干净的文本内容。通过类似的清洗操作,去除重复、无效、噪声数据,确保进入知识库的资料质量。
知识抽取与结构化
对于非结构化文本,借助自然语言处理技术进行知识抽取。以spaCy库为例,进行命名实体识别:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "苹果公司成立于1976年,总部位于美国库比蒂诺"
doc = nlp(text)
for ent in doc.ents:print(ent.text, ent.start_char, ent.end_char, ent.label_)
- 上面的代码加载英文语言模型,对文本进行处理后,识别出其中的实体(如 “苹果公司”“1976 年”“美国库比蒂诺”)及其类别(如 “ORG” 组织、“DATE” 日期、“GPE” 地理位置)。将抽取的知识整理成结构化数据,如字典形式:
knowledge_data = {"entity": "苹果公司","attribute": "成立时间","value": "1976年"
}
利用 API 导入知识库
将结构化后的知识通过 API 导入蓝耘平台知识库。
代码如下:
import requests
import json
api_key = "sk - xxxxxxxxxxx"
url = "https://maas - api.lanyun.net/v1/import - knowledge"
headers = {"Content - Type": "application/json","Authorization": "Bearer " + api_key
}
knowledge_list = [{"content": "Python是一种高级编程语言,具有动态类型系统","type": "text","category": "编程语言"},{"content": "蓝耘平台提供强大的AI模型服务","type": "text","category": "平台介绍"}
]
data = {"knowledge": knowledge_list
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:print("知识导入成功")
else:print("知识导入失败,状态码:", response.status_code)
-
先设置 API Key、请求 URL 和请求头。
-
然后将知识数据组织成符合接口要求的 JSON 格式,通过requests.post方法发送 POST 请求。
若返回状态码为 200,则表示知识导入成功,每一次成功的导入操作会根据数据量消耗一定 Token,开发者可利用免费赠送的超千万 Token,轻松完成大规模知识库的搭建 。
智能客服应答系统搭建
系统架构与流程
智能客服系统基于 “前端交互 - 中间逻辑处理 - 后端知识库及模型服务” 三层架构。
- 用户在前端输入问题后,中间逻辑处理层先对问题进行预处理(分词、词性标注等),然后尝试从知识库中检索答案。
- 若未找到匹配答案,则调用
蓝耘平台 API,将问题发送给大语言模型,获取回答后经优化返回给前端展示。
代码实现
下面是简化的 Python 代码,展示智能客服系统调用 API 获取回答的核心逻辑:
from openai import OpenAI
import requests
import json# 知识库查询函数(模拟)
def search_knowledgebase(question):# 这里可编写实际的知识库查询逻辑return Noneapi_key = "sk - xxxxxxxxxxx"
client = OpenAI(api_key=api_key, base_url="https://maas - api.lanyun.net/v1")
question = "平台的免费Token如何使用?"
answer = search_knowledgebase(question)
if answer is None:chat_completion = client.chat.completions.create(model="/maas/deepseek - ai/DeepSeek - R1",messages=({"role": "user", "content": question}))answer = chat_completion.choices[0].message.content
print(answer)
-
先定义了一个模拟的知识库查询函数
search_knowledgebase。 -
若知识库中未找到答案,则调用蓝耘平台 API 获取模型生成的回答。
-
每次调用 API 获取回答都会消耗 Token,
凭借平台赠送的大量 Token,智能客服系统能稳定处理众多用户咨询 。
四.API 工作流调用优化技巧
Token 使用策略
蓝耘平台赠送的超千万 Token 为开发者提供了充足资源。
- 在开发测试阶段,可大量调用 API 进行功能测试和模型效果评估。
- 如对智能客服系统进行多轮问答测试,不断优化模型参数和回答逻辑。在正式上线后,通过缓存高频问题的答案、压缩输入输出数据长度等方式
减少 Token消耗。
例如,使用 Python 的functools.lru_cache装饰器实现函数结果缓存:
import functools
@functools.lru_cache(maxsize=128)
def get_answer_from_api(question):from openai import OpenAIclient = OpenAI(api_key="sk - xxxxxxxxxxx", base_url="https://maas - api.lanyun.net/v1")chat_completion = client.chat.completions.create(model="/maas/deepseek - ai/DeepSeek - R1",messages=({"role": "user", "content": question}))return chat_completion.choices[0].message.content
- 这样,对于相同问题的 API 调用,直接从缓存中获取结果,无需再次消耗 Token,有效节省资源。
参数调优与错误处理
在调用 API 时,根据任务需求合理选择模型和设置参数。
-
如处理短文本分类任务,可选用轻量级模型。
-
对于长文本生成任务,选择更强大的模型。
-
同时,仔细处理 API 调用过程中的错误。当出现错误时,根据返回的错误码和信息进行排查。
-
例如,若返回 “
429 Too Many Requests” 错误码,说明调用频率过高,可通过设置调用间隔或使用队列控制调用频率:
import time
import queue
import threadingq = queue.Queue()def api_call_worker():while True:question = q.get()try:from openai import OpenAIclient = OpenAI(api_key="sk - xxxxxxxxxxx", base_url="https://maas - api.lanyun.net/v1")chat_completion = client.chat.completions.create(model="/maas/deepseek - ai/DeepSeek - R1",messages=({"role": "user", "content": question}))print(chat_completion.choices[0].message.content)except Exception as e:print("API调用错误:", e)finally:q.task_done()time.sleep(1) # 控制调用间隔# 启动线程处理API调用
for _ in range(5):t = threading.Thread(target=api_call_worker)t.daemon = Truet.start()# 向队列中添加问题
q.put("如何优化API调用性能")
q.put("蓝耘平台有哪些特色模型")q.join()
- 利用队列和多线程技术,结合调用间隔设置,有效避免因调用频率过高导致的错误,
合理使用 Token 资源。
蓝耘元生代 MaaS 平台凭借强大的 API 工作流调用能力、丰富的应用场景支持以及超千万免费 Token 的福利,为开发者打开了 AI 应用开发的便捷之门,开发者能够高效构建各类智能应用,加速业务智能化转型。
五.体验感受
- 蓝耘元生代 MaaS 平台以 API 工作流调用为桥梁,为开发者搭建起通向智能应用的高速路。
超千万免费 Token 的慷慨馈赠,更是消除了开发者探索创新的后顾之忧,让每一个创意都有机会落地生根。- 从基础的 API 调用到知识库建立、智能客服搭建,每一行代码的编写、每一个场景的实践,都见证着技术与创意的碰撞。
这不仅是一场技术的实践之旅,更是开发者们突破边界、探索无限可能的征程。相信在蓝耘平台的助力下,会有更多精彩的 AI 应用诞生,持续推动行业变革,为我们的生活与工作带来更多惊喜与便利。
欢迎试用:蓝耘







![[面试精选] 0021. 合并两个有序链表](https://i-blog.csdnimg.cn/img_convert/ccabb314dbe46e97771884b20db1bfa6.jpeg)