循环神经网络(RNN)全面教程:从原理到实践
引言
循环神经网络(Recurrent Neural Network, RNN)是处理序列数据的经典神经网络架构,在自然语言处理、语音识别、时间序列预测等领域有着广泛应用。本文将系统介绍RNN的核心概念、常见变体、实现方法以及实际应用,帮助读者全面掌握这一重要技术。
一、RNN基础概念
1. 为什么需要RNN?
传统前馈神经网络的局限性:
- 输入和输出维度固定
- 无法处理可变长度序列
- 不考虑数据的时间/顺序关系
- 难以学习长期依赖
RNN的核心优势:
- 可以处理任意长度序列
- 通过隐藏状态记忆历史信息
- 参数共享(相同权重处理每个时间步)
2. RNN基本结构
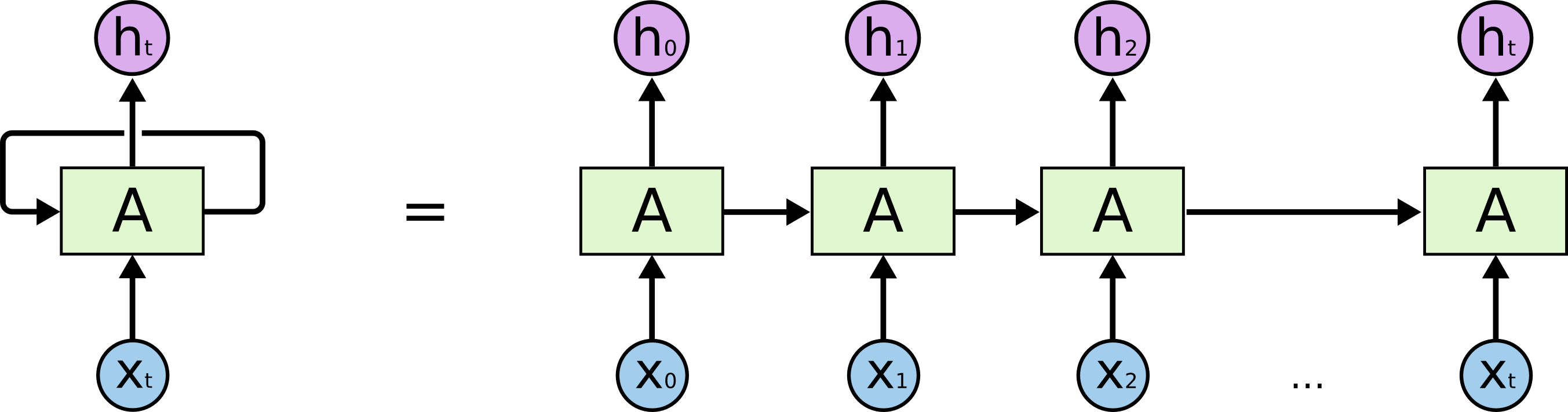
数学表示:
[ h_t = \sigma(W_{hh}h_{t-1} + W_{xh}x_t + b_h) ]
[ y_t = W_{hy}h_t + b_y ]
其中:
- ( x_t ):时间步t的输入
- ( h_t ):时间步t的隐藏状态
- ( y_t ):时间步t的输出
- ( \sigma ):激活函数(通常为tanh或ReLU)
- ( W )和( b ):可学习参数
二、RNN的常见变体
1. 双向RNN (Bi-RNN)
同时考虑过去和未来信息:
[ \overrightarrow{h_t} = \sigma(W_{xh}^\rightarrow x_t + W_{hh}^\rightarrow \overrightarrow{h_{t-1}} + b_h^\rightarrow) ]
[ \overleftarrow{h_t} = \sigma(W_{xh}^\leftarrow x_t + W_{hh}^\leftarrow \overleftarrow{h_{t+1}} + b_h^\leftarrow) ]
[ y_t = W_{hy}[\overrightarrow{h_t}; \overleftarrow{h_t}] + b_y ]
应用场景:需要上下文信息的任务(如命名实体识别)
2. 深度RNN (Deep RNN)
堆叠多个RNN层以增加模型容量:
[ h_t^l = \sigma(W_{hh}^l h_{t-1}^l + W_{xh}^l h_t^{l-1} + b_h^l) ]
3. 长短期记忆网络(LSTM)
解决普通RNN的梯度消失/爆炸问题:
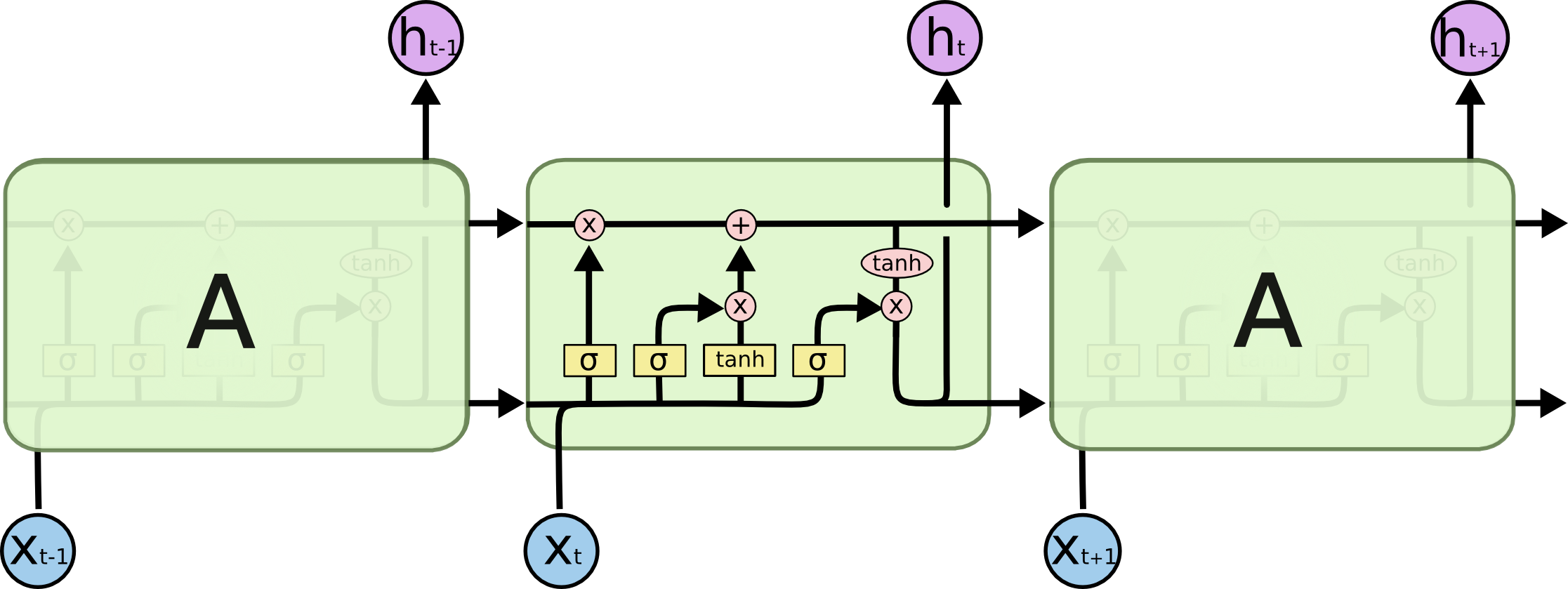
核心组件:
- 遗忘门:决定丢弃哪些信息
- 输入门:决定更新哪些信息
- 输出门:决定输出哪些信息
- 细胞状态:长期记忆载体
4. 门控循环单元(GRU)
LSTM的简化版本:

简化点:
- 合并细胞状态和隐藏状态
- 合并输入门和遗忘门
三、RNN的PyTorch实现
1. 基础RNN实现
import torch
import torch.nn as nnclass SimpleRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleRNN, self).__init__()self.hidden_size = hidden_sizeself.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# 初始化隐藏状态h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)# 前向传播out, _ = self.rnn(x, h0)out = self.fc(out[:, -1, :]) # 只取最后一个时间步return out
2. LSTM实现
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super(LSTMModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)out, _ = self.lstm(x, (h0, c0))out = self.fc(out[:, -1, :])return out
3. 序列标注任务实现
class RNNForSequenceTagging(nn.Module):def __init__(self, vocab_size, embed_size, hidden_size, num_classes):super(RNNForSequenceTagging, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.LSTM(embed_size, hidden_size, bidirectional=True, batch_first=True)self.fc = nn.Linear(hidden_size * 2, num_classes) # 双向需要*2def forward(self, x):x = self.embedding(x)out, _ = self.rnn(x)out = self.fc(out) # 每个时间步都输出return out
四、RNN的训练技巧
1. 梯度裁剪
防止梯度爆炸:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
2. 学习率调整
使用学习率调度器:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
3. 序列批处理
使用pack_padded_sequence处理变长序列:
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence# 假设inputs是填充后的序列,lengths是实际长度
packed_input = pack_padded_sequence(inputs, lengths, batch_first=True, enforce_sorted=False)
packed_output, _ = model(packed_input)
output, _ = pad_packed_sequence(packed_output, batch_first=True)
4. 权重初始化
for name, param in model.named_parameters():if 'weight' in name:nn.init.xavier_normal_(param)elif 'bias' in name:nn.init.constant_(param, 0.0)
五、RNN的典型应用
1. 文本分类
# 数据预处理示例
texts = ["I love this movie", "This is a bad film"]
labels = [1, 0]# 构建词汇表
vocab = {"<PAD>": 0, "<UNK>": 1}
for text in texts:for word in text.lower().split():if word not in vocab:vocab[word] = len(vocab)# 转换为索引序列
sequences = [[vocab.get(word.lower(), vocab["<UNK>"]) for word in text.split()] for text in texts]
2. 时间序列预测
# 创建滑动窗口数据集
def create_dataset(series, lookback=10):X, y = [], []for i in range(len(series)-lookback):X.append(series[i:i+lookback])y.append(series[i+lookback])return torch.FloatTensor(X), torch.FloatTensor(y)
3. 机器翻译
# 编码器-解码器架构示例
class Encoder(nn.Module):def __init__(self, input_size, hidden_size):super(Encoder, self).__init__()self.rnn = nn.LSTM(input_size, hidden_size, batch_first=True)def forward(self, x):_, (hidden, cell) = self.rnn(x)return hidden, cellclass Decoder(nn.Module):def __init__(self, output_size, hidden_size):super(Decoder, self).__init__()self.rnn = nn.LSTM(output_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden, cell):output, (hidden, cell) = self.rnn(x, (hidden, cell))output = self.fc(output)return output, hidden, cell
六、RNN的局限性及解决方案
1. 梯度消失/爆炸问题
解决方案:
- 使用LSTM/GRU
- 梯度裁剪
- 残差连接
- 更好的初始化方法
2. 长程依赖问题
解决方案:
- 跳跃连接
- 自注意力机制(Transformer)
- 时钟工作RNN(Clockwork RNN)
3. 计算效率问题
解决方案:
- 使用CUDA加速
- 优化实现(如cuDNN)
- 模型压缩技术
七、现代RNN的最佳实践
-
数据预处理:
- 标准化/归一化时间序列数据
- 对文本数据进行适当的tokenization
- 考虑使用子词单元(Byte Pair Encoding)
-
模型选择指南:
- 简单任务:普通RNN或GRU
- 复杂长期依赖:LSTM
- 需要双向上下文:Bi-LSTM
- 超长序列:考虑Transformer
-
超参数调优:
- 隐藏层大小:64-1024(根据任务复杂度)
- 层数:1-8层
- Dropout率:0.2-0.5
- 学习率:1e-5到1e-3
-
模型评估:
- 使用适当的序列评估指标(BLEU、ROUGE等)
- 进行彻底的错误分析
- 可视化注意力权重(如有)
结语
尽管Transformer等新架构在某些任务上表现优异,RNN及其变体仍然是处理序列数据的重要工具,特别是在资源受限或需要在线学习的场景中。理解RNN的原理和实现细节,不仅有助于解决实际问题,也为学习更复杂的序列模型奠定了坚实基础。
希望本教程能帮助你全面掌握RNN技术。在实际应用中,建议从简单模型开始,逐步增加复杂度,并通过实验找到最适合你任务的架构和参数设置。