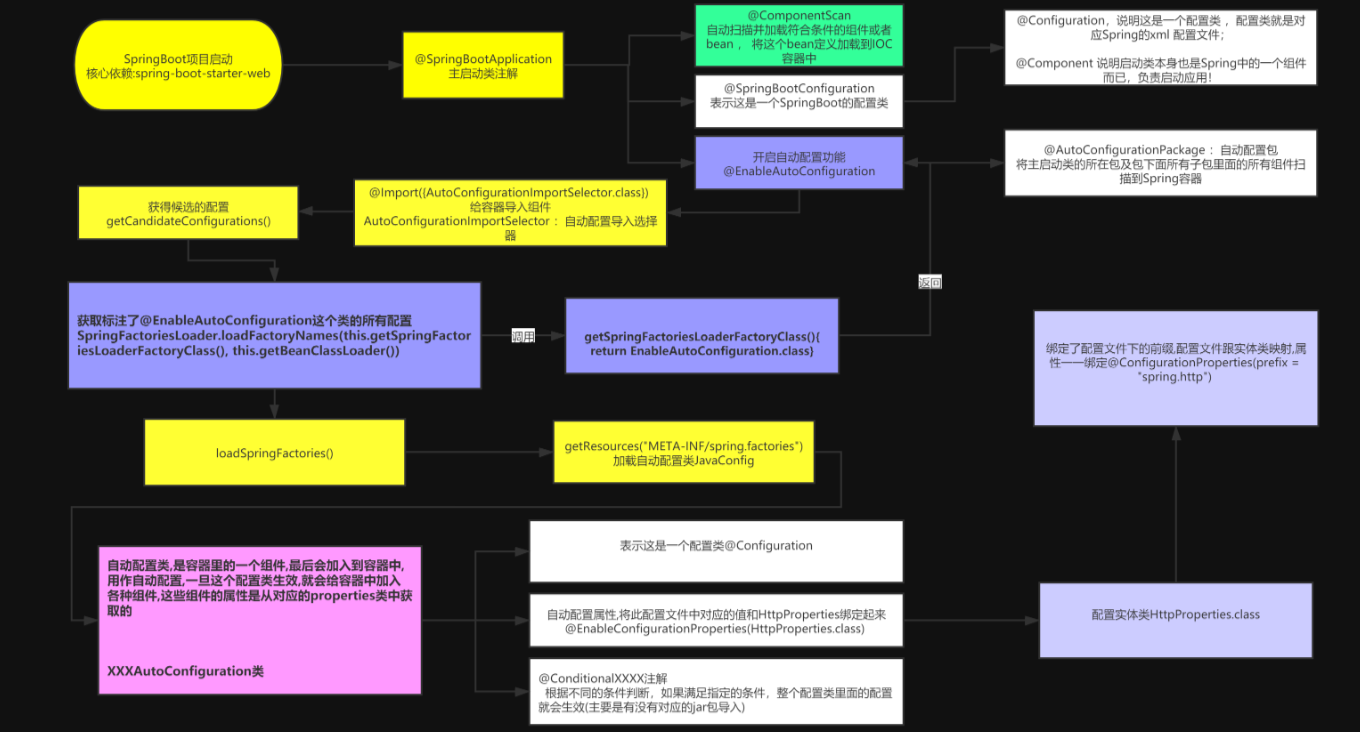
QuickList基本结构
用一句话来说,QuickList是一个双端链表,每一个链表节点中存储的是ZipList,参照下面这张图可以更好地理解QuickList的结构组成:
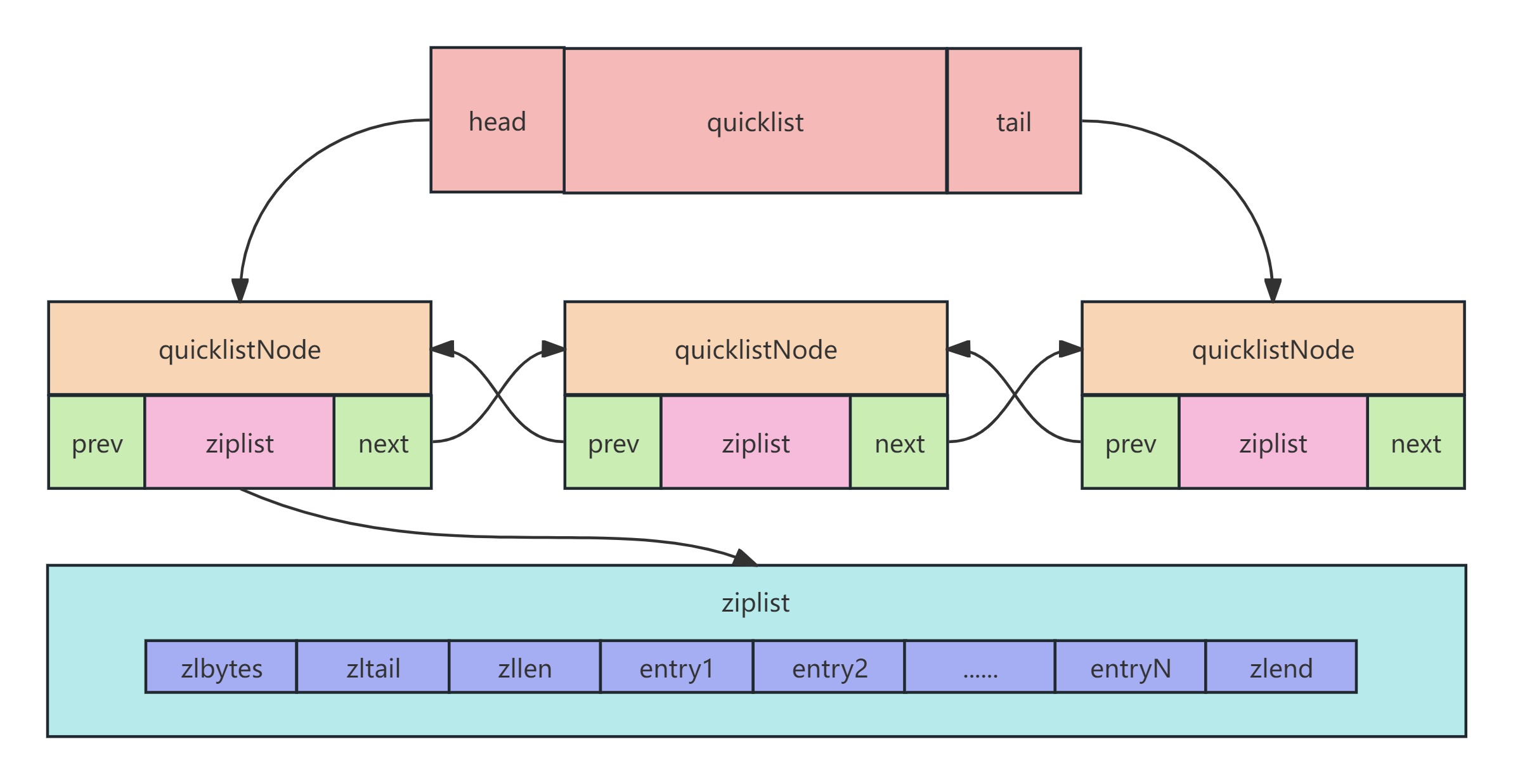
QuickList在Redis6.0中一共定义了6个结构体,分别为:
quicklistNode:定义了一个链表节点,可以理解为QuickList中实际的Node。
quicklistLZF:定义了储存压缩后ZipList的数据结构。
quicklistBookmark:定义了一个可以追加在quicklist尾部的书签,只有在大量节点的多余内存使用量可以忽略不计的情况且确实需要分批迭代它们时才会使用。
quicklist:定义了一个双向链表,可以理解为QuickList的实体。
quicklistIter:定义了一个迭代器。
quicklistEntry:定义了一层封装,对ZipList中的entry概念的封装。
文章只对quicklist和quicklistNode两个重点部分进行详细讲解。
quicklist的定义:
typedef struct quicklist {quicklistNode *head;quicklistNode *tail;unsigned long count;unsigned long len;int fill : QL_FILL_BITS;unsigned int compress : QL_COMP_BITS;unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;head字段:指向头结点(上一个节点)的指针。
tail字段:指向尾节点(下一个节点)的指针。
count字段:所有ZipList数据项个数的总和。
len字段:QuickList中包含的Node个数。
fill字段:存放对ZipList的大小设置,如list-max-ziplist-size参数的值,占16bit。具体规则为:
当数值为负数时,代表以字节数限制单个ZipList的最大长度。
-1~-5:不超过4kb~64kb。
当数值为正数时,代表以entry数目限制单个ZipList的最大长度,指就是具体的数目。
compress字段:存放对节点压缩深度的设置,如list-compress-depth参数的值,占16bit。具体规则为:
0:表示不压缩,zl字段直接指向ZipList;
1:表示QuickList的头尾节点不压缩,其余节点zl字段指向经过压缩后的quicklistLZF;
以此类推,值最大为2^16。
quicklistNode的定义:
typedef struct quicklistNode {struct quicklistNode *prev;struct quicklistNode *next;unsigned char *zl;unsigned int sz;unsigned int count : 16;unsigned int encoding : 2;unsigned int container : 2;unsigned int recompress : 1;unsigned int attempted_compress : 1; unsigned int extra : 10;
} quicklistNode;prev字段:指向链表前一个节点的指针。
next字段:指向链表后一个节点的指针。
zl字段:表示数据指针。如果当前节点的数据没有压缩,那么它指向一个ZipList结构;否则,他指向一个QuickListLZF结构。
sz字段:表示zl字段指向的ZipList结构的总大小(即使ZipList被压缩了,这个sz字段表示的仍然是压缩前ZipList的大小)。
count字段:占用16bit(2Byte),表示ZipList中包含的数据项个数。
encoding字段:表示ZipList是否被压缩,1表示没有被压缩,2表示使用了LZF进行压缩。
container字段:预留字段。(本来的设计是用来表明一个QuickList节点下面是直接存数据,还是使用了ZipList来存数据,或者是使用其他的数据容器来存数据,但在目前的实现中这个值被固定为2,表示使用ZipList来存数据)。
recompress字段:标志位,用于标记数据是否需要重新被压缩。当我们使用lindex这样的命令查看了某一项压缩数据时,需要把数据暂时解压,这个时候recompress字段就被标志位1。
attempted_compress字段:这个值用于Redis的自动化测试程序。
extra字段:其它扩展字段。
为什么引入QuickList?
我们从ZipList存在的三个问题来回答这个问题。
(1)ZipList虽然节省了内存,但是申请内存必须是连续空间,如果内存占用比较多,申请内存效率很低时怎么办?
答:对ZipList的长度和entry大小进行限制。
(2)如果限制了ZipList的长度和entry的大小,那么在要存储大量数据时,超出了ZipList的最佳上限该怎么办?
答:可以创建多个ZipList来分片存储大量数据。
(3)一个比较大的数据在拆分后比较分散,不方便管理和查找,那么多个ZipList之间该如何建立联系?
答:引入双向链表,将每一个ZipList作为节点进行存储即可将多个ZipList串起来。
这样就很自然的将QuickList给引出来了,实际上,在Redis3.2之后就加入了QuickList数据结构。
QuickList小结
看完上文之后,大家会发现QuickList数据结构其实是普通双向链表和ZipList结合的产物,实际上这是在实际存储和性能上对两者进行的一个均衡。QuickList以ZipList作为节点,解决了传统双向链表头尾指针占用内存比例较大的问题;同时控制ZipList的大小,解决了ZipList存储大数据时连续内存申请效率的问题。
QuickList的重点内容就这些啦,大家有什么问题或者勘误可以在评论区留言,笔者看到都会回复的。