文章目录
- 摘要
- Abstract
- 1. 引言
- 2. Mem0
- 3. graph-based Mem0
- 参考
- 总结
摘要
Mem0是一种针对AI智能体的长时记忆架构,旨在解决大型语言模型固定上下文窗口导致的跨会话连贯性问题。其基础版本采用两阶段处理范式:提取阶段通过结合对话摘要、近期消息序列和新消息对生成提示,利用LLM提取关键记忆集合;更新阶段则通过检索相似记忆并调用LLM决策机制,动态执行添加、更新、删除或无操作四种记忆管理动作,确保知识库的时效性与一致性。在此基础上发展的图结构版本(graph-based Mem0)创新性地采用有向标记图表示记忆,其中节点承载实体类型、嵌入向量及时间戳元数据,边则通过关系三元组刻画实体间关联。该版本通过实体提取器和关系生成器构建结构化图谱,更新时结合语义匹配与冲突检测机制动态维护图谱完整性,并采用双轨检索策略——实体中心法构建关联子图,语义三元组法实现全局相似度匹配——有效支持复杂关系推理。两种架构共同实现了对话信息的动态捕获、结构化组织和精准检索,显著提升了长时对话的连贯性。
Abstract
Mem0 is a long-term memory architecture designed for AI agents to address the issue of cross-session coherence caused by the fixed context window in large language models (LLMs). Its basic version adopts a two-stage processing paradigm: in the extraction stage, it generates prompts by combining conversation summaries, recent message sequences, and new messages, and uses an LLM to extract a set of key memories. In the update stage, it retrieves similar memories and invokes an LLM-based decision mechanism to dynamically perform one of four memory management actions—add, update, delete, or no operation—ensuring the timeliness and consistency of the knowledge base.Building on this, the graph-based version of Mem0 introduces an innovative approach by representing memory as a directed, labeled graph. In this structure, nodes carry entity types, embedding vectors, and timestamp metadata, while edges capture relationships between entities using relation triples. This version constructs a structured knowledge graph via an entity extractor and a relation generator, and maintains its integrity dynamically through semantic matching and conflict detection mechanisms during updates. It also employs a dual-track retrieval strategy: an entity-centric method to construct relevant subgraphs, and a semantic triple-based approach to achieve global similarity matching, both of which support complex relational reasoning.Together, these two architectures enable dynamic capture, structured organization, and precise retrieval of conversational information, significantly enhancing the coherence of long-term dialogues.
1. 引言
人类记忆是智能的基础,对沟通至关重要,使我们能够回忆过去的互动、推断偏好并构建对他人不断发展的心理模型,从而实现跨越长时间(天、周、月)的连贯、上下文丰富的交流。虽然基于大型语言模型(LLM)的AI代理在生成流畅、上下文合适的响应方面取得了显著进展,但它们本质上受到固定上下文窗口的限制,严重限制了它们在长时间互动中保持连贯性的能力。这种限制源于LLM缺乏能够超越其有限上下文窗口的持久记忆机制。
没有持久记忆,AI智能体会忘记用户偏好、重复提问并违背先前确定的事实。即使在医疗、教育和企业支持等高风险领域,这种记忆缺失也会破坏用户体验和信任。虽然像GPT-4o、Claude 3.7 Sonnet和Gemini这样的模型通过扩展上下文长度(128K至数百万token)来应对,但这些改进只是延迟而非解决了根本限制。原因有二:(1) 随着有意义的长期人-AI关系发展,对话历史最终会超过最长的上下文限制;(2) 现实对话很少保持主题连续性,关键信息可能被埋没在大量无关信息中,使得完整上下文方法效率低下。此外,注意力机制在远距离token上会退化,仅提供更长的上下文并不能确保有效检索或利用过去的信息。
为了解决这些挑战,AI智能体必须采用超越静态上下文扩展的记忆系统。一个强大的AI记忆应该能够选择性地存储重要信息、整合相关概念并在需要时检索相关细节——模仿人类的认知过程。通过整合这种机制,我们可以开发出能够保持角色一致性、跟踪用户偏好演变并基于先前交流构建的AI代理。这将把AI从短暂的、健忘的响应者转变为可靠的长期协作者,从根本上重新定义对话智能的未来。本文介绍了Mem0,一种新颖的记忆架构,旨在解决AI系统在跨不同会话的长时间对话中保持连贯推理的根本限制。它动态捕获、组织和检索持续对话中的关键信息。
2. Mem0
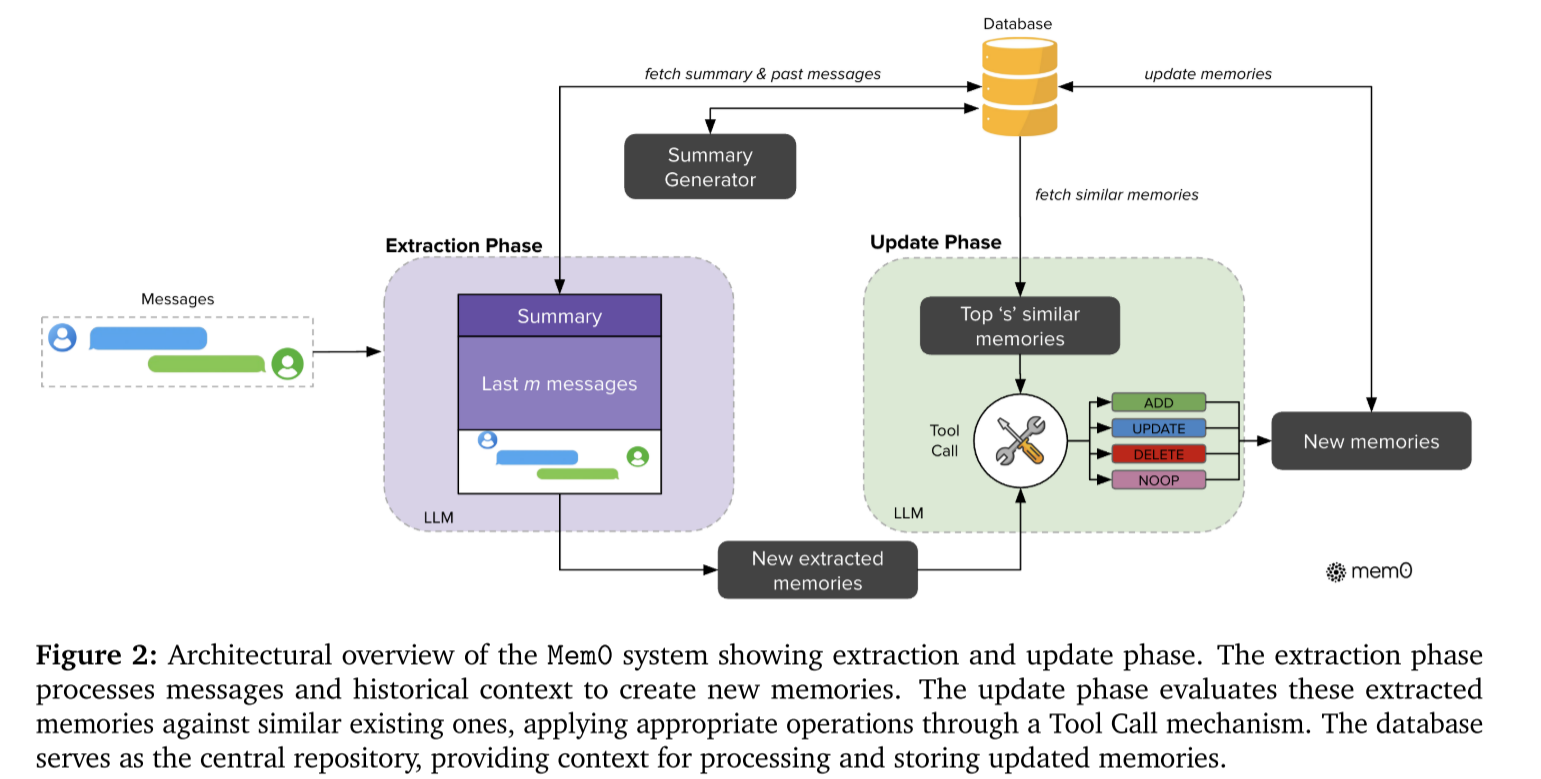
Mem0遵循增量处理范式,该框架由两阶段组成:提取阶段和更新阶段。
提取阶段首先获取新消息对 ( m t − 1 , m t ) (m_{t-1},m_t) (mt−1,mt), m t − 1 m_{t-1} mt−1是用户消息而 m t m_t mt是智能体响应消息,两者构成了一个完整的交互单元。为了获取合适的上下文以提取记忆,还需要一个对话总结 S S S和一系列最近的消息序列 { m t − m , m t − m + 1 , ⋯ , m t − 2 } \{m_{t-m}, m_{t-m+1},\cdots, m_{t-2}\} {mt−m,mt−m+1,⋯,mt−2}。对话总结 S S S由一个异步执行的总结生成模块产生。由于在对话总结 S S S中可能没有包含最近消息的内容,因此需要一系列最近的消息序列来补充这些信息。最后由对话总结 S S S、最近的一系列消息 { m t − m , m t − m + 1 , ⋯ , m t − 2 } \{m_{t-m}, m_{t-m+1},\cdots, m_{t-2}\} {mt−m,mt−m+1,⋯,mt−2}和新消息对 ( m t − 1 , m t ) (m_{t-1}, m_t) (mt−1,mt)构成一个提示 P P P以用于指导大语言模型进行记忆提取 ϕ \phi ϕ,提取后的结果是重要记忆的集合 Ω = { ω 1 , ω 2 , ⋯ , ω n } \Omega=\{\omega_1, \omega_2, \cdots, \omega_n\} Ω={ω1,ω2,⋯,ωn}。
更新阶段将已知的记忆与提取出的记忆进行比较:对于每个提取出的记忆,首先从数据库中检索出前 s s s个语义相似的记忆,然后将该提取出的记忆与检索的前 s s s个记忆送入大语言模型,让大语言模型决定以下四个操作中哪种该执行:1. 当没有语义相等的记忆存在,将提取出的记忆作为新记忆进行添加操作。2. 当存在语义相等的记忆存在,使用提取出的记忆增强已知的记忆。3. 当与已知的记忆冲突时,删除冲突的已知记忆。4. 当提取出的记忆不需要对数据库进行修改时,不进行任何操作。
3. graph-based Mem0
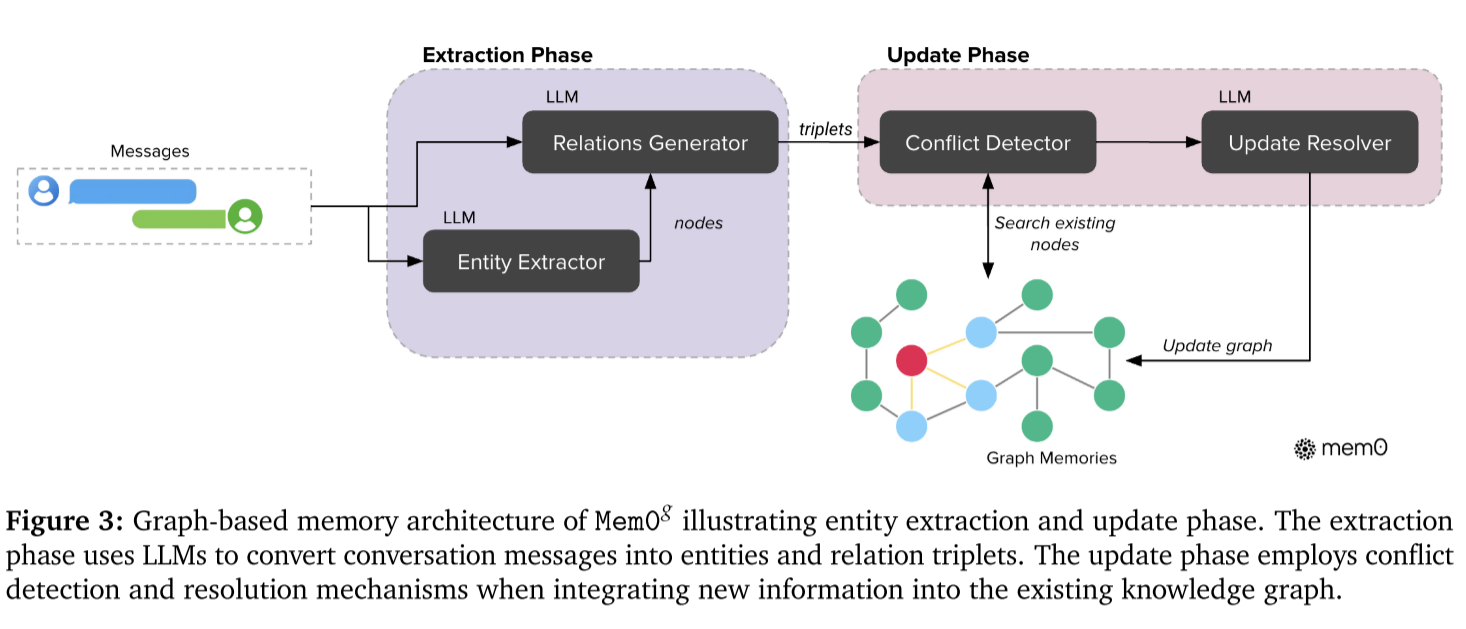
graph-based Mem0与基础的Mem0相比,只是存储的形式从嵌入变为图谱。graph-based Mem0最终输出的结果是一个有向标记图 G = ( V , E , L ) G=(V, E, L) G=(V,E,L),其中节点 V V V代表实体,边 E E E代表实体之间的关系,标记 L L L将语义信息赋值给节点。
每个节点 v ∈ V v\in V v∈V包含三部分信息:1. 实体类型。2. 一个描述实体信息的嵌入向量。3. 包含创建时间戳的元信息。实体之间的关系由一个三元组 ( v s , r , v d ) (v_s, r, v_d) (vs,r,vd)构成,其中 v s v_s vs和 v d v_d vd是起始和结束实体节点, r r r是连接它们的标记边。
提取阶段利用两阶段的管道将文本转换为结构化的图表示:首先,实体提取器从输入文本中提取出一系列实体及其对应的类型。接着,关系生成器生成这些实体之间的关系,得到一系列关系三元组。
更新阶段针对每个关系三元组,首先计算起始和结束节点的嵌入,通过语义相似度查找存在的节点;基于查找到的结果,接着可能创建两个节点,创建一个节点或使用已知的节点;然后执行冲突检测机制,判断新信息是否与已知的关系存在潜在的冲突;最后通过更新解析器判断某些关系是否过时,如果过时,将某些关系标记为无效的,更新该关系三元组到有向标记图。
该框架使用的记忆检索方法如下:实体中心方法首先识别查询中的关键实体,然后利用语义相似度在知识图谱中定位对应节点。该方法系统地探索从这些锚点出发的入向和出向关系,构建一个包含相关上下文信息的全面子图。作为补充,语义三元组方法采用更整体化的视角,将整个查询编码为稠密嵌入向量。该查询表示随后与知识图谱中每个关系三元组的文本编码进行匹配。系统计算查询与所有可用三元组之间的细粒度相似度分数,仅返回超过相关性阈值的结果,并按相似度降序排序。
参考
Prateek Chhikara, Dev Khant, Saket Aryan, and et al. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.
总结
Mem0架构采用增量处理范式,包含提取和更新两阶段。提取阶段处理新消息对时,结合异步生成的对话摘要和近期消息序列构建提示,指导大语言模型提取关键记忆集合。更新阶段通过语义检索比对新增记忆与现有记忆,由大语言模型动态决策执行添加、更新、删除或无操作,确保记忆库的时效性和一致性。其图增强版本(graph-based Mem0)将记忆表示为有向标记图:节点承载实体类型、嵌入向量及元数据,边以三元组形式捕捉实体间关系。该架构通过实体提取器和关系生成器将文本转化为结构化图谱,更新时采用嵌入相似度匹配节点并引入冲突检测机制,通过标记失效处理过时关系。记忆检索融合双模式策略——实体中心法定位节点并构建关联子图,语义三元组法则通过整体嵌入匹配筛选高相关度关系,兼顾精准检索与语义泛化能力。