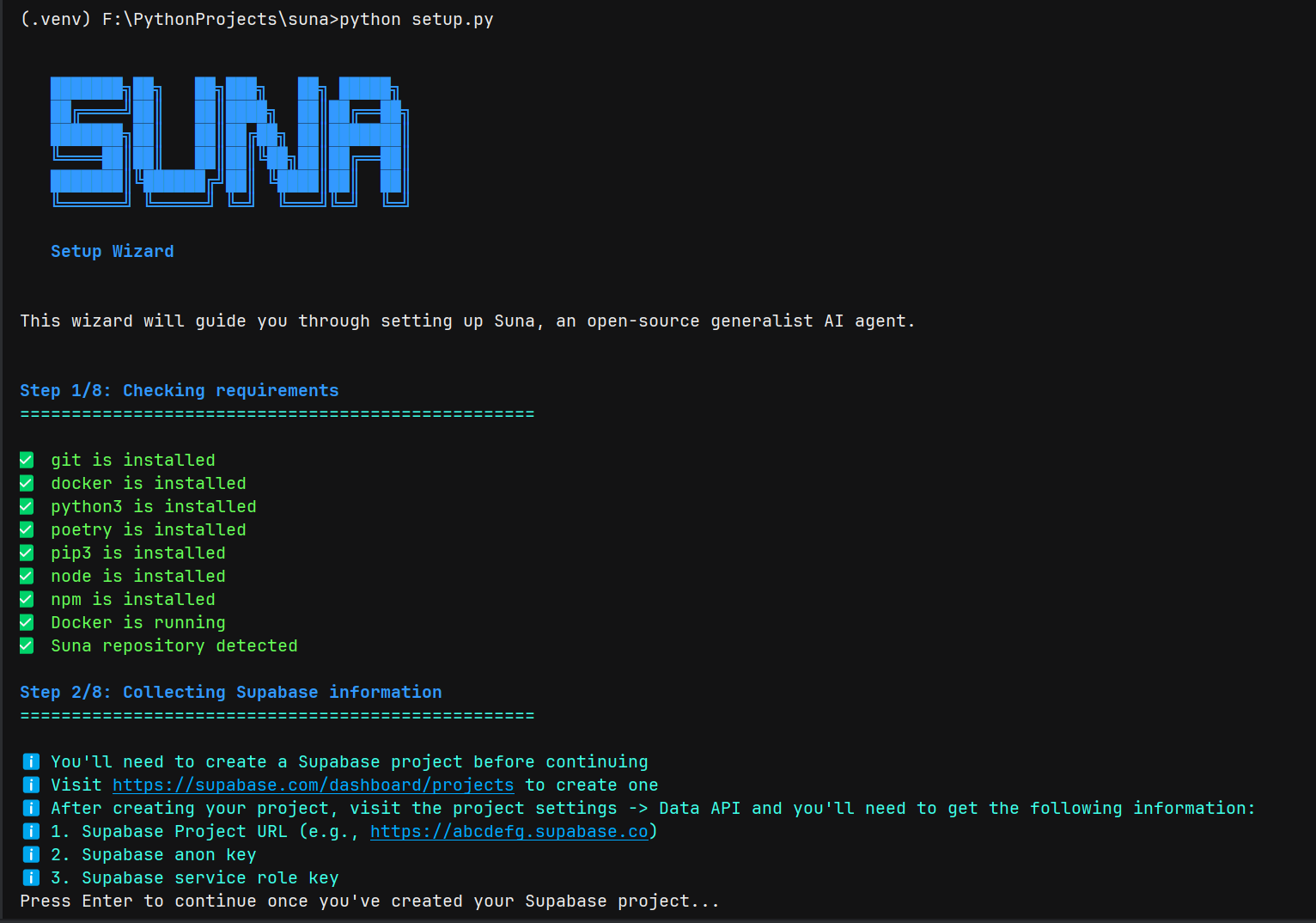
数据读取
import pandas as pd
df = pd.read_csv('D:\my_app\python\python project\data\sample_data.csv')
print(df)
数据保存
import pandas as pd# 创建示例数据
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 35, 28, 22],'City': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou']
}# 创建 DataFrame
df = pd.DataFrame(data)# 指定保存路径和文件名
file_path = r'D:\my_app\python\python project\data\sample_data.csv'# 保存为 CSV 文件
df.to_csv(file_path, index=False)print(f"数据已保存到: {file_path}")
输出首行和输出最后三行
import pandas as pddf = pd.read_csv('D:\my_app\python\python project\data\sample_data.csv')
# print(df.head(1))
print(df.tail(3))
使用 dtypes 检查列类型

import pandas as pddf = pd.read_csv('D:\my_app\python\python project\data\sample_data.csv')print(df.dtypes)
使用 describe() 进行汇总统计(计数、平均值、标准差、最小值、最大值等)。

import pandas as pddf = pd.read_csv('D:\my_app\python\python project\data\sample_data.csv')print(df.describe())

计算平均值
import pandas as pddf = pd.read_csv('D:\my_app\python\python project\data\sample_data.csv')avg_age = df['Age'].mean()
print(f"Average age: {avg_age}")
寻找缺失值
import pandas as pddf = pd.read_csv('D:\my_app\python\python project\data\sample_data.csv')missing_count = df['Age'].isna().sum()
print(f"Missing age values: {missing_count}")
.isna() 是 pandas 中的一个方法,用于检查“年龄”系列中的每个值是否缺失(即 NaN 、 None 或 pandas 中缺失数据的其他表示)。
它返回一个长度相同的新系列,其中如果 df[‘Age’] 中的相应值缺失,则每个元素为 True ,否则为 False 。
df.to_csv() 方法用于将 DataFrame 保存到 CSV 文件。
import pandas as pd# Create DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 35, 28, 22],'City': ['Beijing', 'Shanghai', 'Guangzhou', ' quellesShenzhen', 'Hangzhou']
}
df = pd.DataFrame(data)# Save to CSV
df.to_csv(r'D:\my_app\python\python project\data\sample_data.csv', index=False)
索引
索引loc
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['x', 'y', 'z']}, index=['a', 'b', 'c'])
print(df.loc['a', 'A']) # Select value at index 'a' and column 'A'
print(df.loc[df['A'] > 1, ['B']]) # Filter and select column

第二个输出
索引iloc
iloc :基于整数的位置选择(使用行/列位置)。
数字索引推荐
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['x', 'y', 'z']}, index=['a', 'b', 'c'])print(df.iloc[0, 0]) # First row, first column
print(df.iloc[1:3, 0]) # Rows 1 to 2, first column
Boolean Filtering
df = pd.DataFrame({'Age': [25, 30, 35, 28, 22]})
filtered_df = df[df['Age'] > 30]
print(filtered_df)

Multiple Conditions: Combine with & (and), | (or), and ~ (not), using parentheses
import pandas as pddf = pd.DataFrame({'Age': [25, 30, 35, 28, 22]})
filtered_df = df[(df['Age'] > 25) & (df['Age'] < 35)]
print(filtered_df)

Adding a Column
Adding a Column: Assign a new column or compute from existing ones
import pandas as pddf = pd.DataFrame({'Age': [25, 30, 35, 28, 22]})
df['New_Column'] = df['Age'] + 5
print(df)

删除列的两种方法
import pandas as pddf = pd.DataFrame({'Age': [25, 30, 35, 28, 22]})
df['New_Column'] = df['Age'] + 5
# print(df)
df = df.drop('New_Column', axis=1) # axis=1 for columns
# or
# del df['New_Column']
print(df)
1。df = df.drop('New_Column', axis=1) # axis=1 for columns
axis=0为列,axis=1为行
2.del df['New_Column']
修改列 :直接更新值。
import pandas as pddf = pd.DataFrame({'Age': [25, 30, 35, 28, 22]})
df['Age'] = df['Age'] * 2print(df)

我们将使用 str.startswith() 过滤城市以“S”开头的行。
# Load the CSV file
df = pd.read_csv(r'D:\my_app\python\python project\data\sample_data.csv')
# Filter rows where City starts with 'S'
filtered_df = df[df['City'].str.startswith('S')]
print(filtered_df)
创建一个新列“Senior”(如果年龄 > 30 则为 True,否则为 False)
import pandas as pd# Load the CSV file
df = pd.read_csv(r'D:\my_app\python\python project\data\sample_data.csv')
df['Senior'] = df['Age'] > 30
print(df)

Detecting Missing Values: Use isna() or isnull() to check for missing data.
import pandas as pd
df = pd.DataFrame({'A': [1, None, 3], 'B': ['x', 'y', None]})
print(df.isna())

fillna() :用特定值或方法(例如平均值)填充缺失值。
import pandas as pd
df = pd.DataFrame({'A': [1, None, 3], 'B': ['x', 'y', None]})
df_filled = df.fillna(0) # Replace NaN with 0
print(df_filled)

dropna() :删除缺少值的行或列。
import pandas as pd
df = pd.DataFrame({'A': [1, None, 3], 'B': ['x', 'y', None]})
df_dropped = df.dropna() # Drop rows with any NaN
print(df_dropped)

数据类型转换
astype() :更改列的数据类型(例如,从字符串更改为整数)。
import pandas as pd
df = pd.DataFrame({'A': ['1', '2', '3']})
df['A'] = df['A'].astype(int)
print(df.dtypes)

例子
创建一个 DataFrame,其中 Age 列为字符串(例如,[‘25’, ‘30’, ‘invalid’])。
将年龄转换为整数类型,处理无效值。
检查结果数据类型。
import pandas as pd# Create a DataFrame with an 'Age' column as strings
df = pd.DataFrame({'Age': ['25', '30', 'invalid']})# Convert 'Age' to integer, handling invalid values
df['Age'] = pd.to_numeric(df['Age'], errors='coerce').astype('Int64')# Check the resulting data types
print(df)
print("\nData types:")
print(df.dtypes)
pd.to_numeric 尝试将每个值解析为数字。
errors='coerce' 参数确保无效值(如 'invalid' )转换为 NaN (非数字)而不是引发错误。
此步骤将有效字符串( ‘25’ , ‘30’ )转换为数字(例如, 25.0 , 30.0 ),并将 ‘无效’ 转换为 NaN 。
.astype('Int64') 将结果数值转换为 pandas 的可空整数类型 Int64 。

删除重复项
drop_duplicates() :根据所有或特定列删除重复的行。
import pandas as pd
df = pd.DataFrame({'A': [1, 1, 2], 'B': ['x', 'x', 'y']})
df_unique = df.drop_duplicates()
print(df_unique)

子集参数 :根据特定列删除重复项。
import pandas as pd
df = pd.DataFrame({'A': [1, 1, 2], 'B': ['x', 'x', 'y']})df_unique_subset = df.drop_duplicates(subset=['A'])
print(df_unique_subset)
字符串处理
str 方法 :常用方法包括 str.lower() 、 str.upper() 、 str.replace() 。(大小写替换)
import pandas as pddf = pd.DataFrame({'City': ['Beijing', 'SHANGHAI', 'guangzhou']})
df['City'] = df['City'].str.lower() # Convert to lowercase
df['City'] = df['City'].str.replace('g', 'G') # Replace 'g' with 'G'
print(df)

str.strip() 、 str.contains() 用于清理或过滤。
strip() 方法从列中的每个字符串中删除所有前导(在开始处)或尾随(在结尾处)的空白字符(空格、制表符或换行符)。
规范化文本数据
import pandas as pd# Load data
df = pd.read_csv(r'D:\my_app\python\python project\data\sample_data.csv')# Add missing value and outlier
df.loc[0, 'Age'] = None # Missing value
df.loc[1, 'Age'] = 150 # Outlier# Fill missing values with mean
df['Age'] = df['Age'].fillna(df['Age'].mean())# Drop outliers (Age > 100)
df = df[df['Age'] <= 100]# Convert Age to integer
df['Age'] = df['Age'].astype(int)# Normalize City to lowercase
df['City'] = df['City'].str.lower()# Save cleaned data
df.to_csv(r'D:\my_app\python\python project\data\cleaned_data.csv', index=False)
print(df)
df.loc[0, 'Age'] = None 将索引 0 处的行的 ‘Age’ 值设置为 None ,从而引入缺失值(pandas 将其视为 NaN )。
df.loc[1, 'Age'] = 150 将索引 1 处的行的“Age”值设置为 150 ,引入异常值(异常高的年龄,可能不切实际)。
df['Age'].fillna(df['Age'].mean()) 将“Age”列中的缺失值( NaN )替换为该列中非缺失值的平均值。
df = df[df['Age'] <= 100] 过滤 DataFrame 以仅保留“Age”值小于或等于 100 的行。
df['Age'] = df['Age'].astype(int) 将 ‘Age’ 列转换为标准 Python 整数类型 ( int )。
用平均值填充缺失值后,“年龄”列可能包含浮点数(例如 73.33 )。 .astype(int) 方法会截断小数部分(例如, 73.33 变为 73 )。
注意:此操作假设在 fillna 步骤后,“Age” 中的所有值均不为空,因为 int 不支持 NaN 。(如果保留 NaN 值,则需要使用 Int64 。)

例子
加载更大的数据集(例如,来自 Kaggle 或创建一个具有 20 行以上的数据集)。
使用不同的策略处理缺失值(例如,使用 fillna(method=‘ffill’) 进行正向填充)。
删除重复项并清理文本(例如,使用 str.strip() 删除多余的空格)。
保存并比较原始数据集和清理后的数据集。
import pandas as pd
import numpy as np
import os# Ensure the output directory exists
output_dir = r'D:\my_app\python\python project\data'
os.makedirs(output_dir, exist_ok=True)# Set random seed for reproducibility
np.random.seed(42)# Create synthetic dataset
data = {'Name': [' John Doe ', 'Alice Smith', 'Bob Johnson ', ' Mary Brown', 'John Doe','Tom Wilson ', np.nan, 'Sarah Davis', ' Emma Clark ', 'Michael Lee','John Doe', 'Alice Smith', 'David Kim ', 'Lisa White', np.nan,'Chris Evans', 'Anna Taylor ', 'Mark Chen', ' Jane Doe', 'Tom Wilson','Emily Green', ' Paul Adams ', 'Laura King', 'James Lee', ' Amy Chen '],'Age': [25, 30, np.nan, 45, 25, 35, 28, np.nan, 50, 32,25, 30, 40, np.nan, 27, 33, 29, 60, 45, 35,np.nan, 41, 26, 38, 31],'City': [' New York ', 'Paris ', ' Tokyo', 'London ', 'New York',' Sydney', 'Berlin ', np.nan, ' Tokyo ', 'Paris',' New York', 'Paris', ' Berlin ', 'London', 'Chicago ',np.nan, 'Sydney ', 'Tokyo', ' London', 'Sydney',' Chicago', 'Berlin', ' Paris ', 'Tokyo ', np.nan],'Purchase_Amount': [100.50, 200.75, 150.00, np.nan, 100.50, 300.25, 175.00, 250.00, 400.00, np.nan,100.50, 200.75, 180.00, 220.00, np.nan, 190.00, 310.00, np.nan, 260.00, 300.25,270.00, 230.00, 210.00, np.nan, 320.00]
}# Create original DataFrame
df_original = pd.DataFrame(data)# Create a copy for cleaning
df = df_original.copy()# Check duplicates before cleaning
print("Duplicates in original:", df.duplicated().sum())# Clean text first to ensure duplicates are correctly identified
df['Name'] = df['Name'].str.strip()
df['City'] = df['City'].str.strip()# Remove duplicates
df = df.drop_duplicates()
print("Duplicates after drop:", df.duplicated().sum())# Handle missing values
df['Name'] = df['Name'].ffill()
df['City'] = df['City'].ffill()
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Purchase_Amount'] = df['Purchase_Amount'].fillna(df['Purchase_Amount'].median())# Convert 'Age' to integer
df['Age'] = df['Age'].astype(int)# Save both datasets to the same Excel file in different sheets
output_path = os.path.join(output_dir, 'datasets.xlsx')
with pd.ExcelWriter(output_path, engine='openpyxl') as writer:df_original.to_excel(writer, sheet_name='Original', index=False)df.to_excel(writer, sheet_name='Cleaned', index=False)# Compare datasets
print("\nOriginal Dataset:")
print(df_original)
print("\nCleaned Dataset:")
print(df)
print("\nSummary of Changes:")
print(f"Original shape: {df_original.shape}")
print(f"Cleaned shape: {df.shape}")
print(f"Missing values in original:\n{df_original.isna().sum()}")
print(f"Missing values in cleaned:\n{df.isna().sum()}")